






一、联合索引
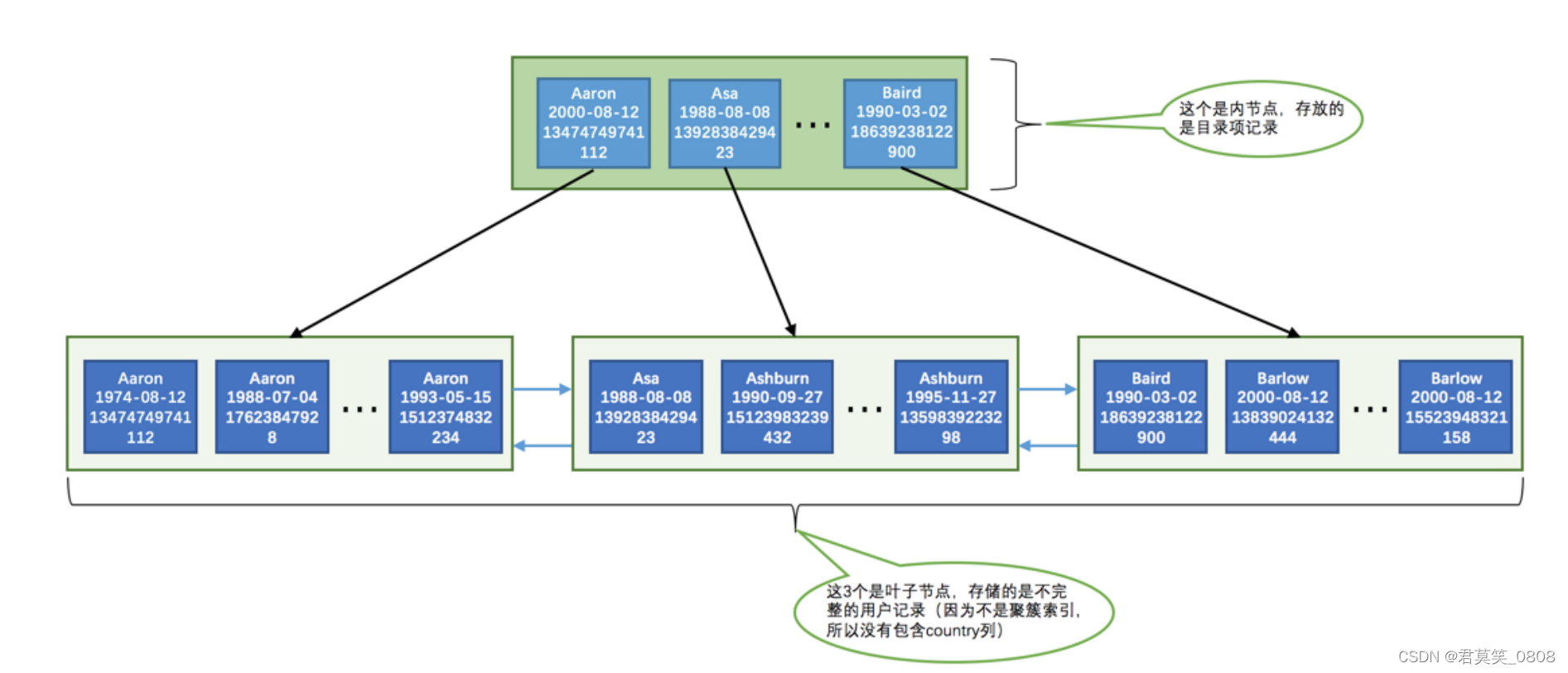
内节点中存储的是 目录项 记录 ,叶子节点中存储的是 用户记录 (由于不是聚簇索引,所以用户记录是不完整的,缺少 country 列的 值)。这个 idx_name_birthday_phone_number 索引对应的 B+ 树中页面和记录的排序方式就是 这样的:
先按照 name 列的值进行排序。
如果 name 列的值相同,则按照 birthday 列的值进行排序。
如果 birthday 列的值也相同,则按照 phone_number 的值进行排序。
二、索引匹配原则
2.1 最左匹配原则
我们想使用联合索引中尽可能多的列,搜索条件中的各个列必须是联合索引中从最左边连续的列。
2.2 匹配范围查询
2.2.1 示例
如果对多个列同时进行范围查找的话,只有对索引最左边的那个 列进行范围查找的时候才能用到 B+ 树索引,比如:
SELECT * FROM person_info WHERE name > 'Asa' AND name < 'Barlow' AND birthday > '1980-01-0 1';查询分成两部分:
1. 通过条件 name > 'Asa' AND name < 'Barlow' 来对 name 进行范围,查找的结果可能有多条 name 值不同的 记录。
2. 对这些 name 值不同的记录继续通过 birthday > '1980-01-01' 条件继续过滤。
只能用到 name 列的部分,而用不到 birthday 列 的部分,因为只有 name 值相同的情况下才能用 birthday 列的值进行排序,而这个查询中通过 name 进行范围查 找的记录中可能并不是按照birthday 列进行排序的,在搜索条件中继续以 birthday 列进行查找时是用不到 这个 B+ 树索引的。
2.2.2 示例:精确匹配某一列并范围匹配另外一列
SELECT * FROM person_info WHERE name = 'Ashburn' AND birthday > '1980-01-01' AND birthday < '2000-12-31' AND phone_number > '15100000000';
这个查询的条件可以分为3个部分:
1. name = 'Ashburn' 对 name 列进行精确查找,当然可以使用 B+ 树索引了。
2. birthday > '1980-01-01' AND birthday < '2000-12-31' ,由于name 列是精确查找,所以通过 name = 'Ashburn' 条件查找后得到的结果的 name 值都是相同的,它们会再按照 birthday 的值进行排序。所以此时 对 birthday 列进行范围查找是可以用到 B+ 树索引。
3. phone_number > '15100000000' ,通过 birthday 的范围查找的记录的 birthday 的值可能不同,所以这个条件无法再利用 B+ 树索引了只能遍历上一步查询得到的记录。
4. 同理,下边的查询也是可能用到这个 idx_name_birthday_phone_number 联合索引的: SELECT * FROM person_info WHERE name = 'Ashburn' AND birthday = '1980-01-01' AND AND phone _number > '15100000000';
三 order 排序与分组
3.1 能使用到索引
按照最左匹配原则,也能使用到索引
3.2 不能使用到索引
1、ASC、DESC混用
2、WHERE子句中出现非排序使用到的索引列
3、排序列包含非同一个索引的列
4、排序列使用了复杂的表达式
3.3 group by 分组 :需要满足最左匹配原则
SELECT name, birthday, phone_number, COUNT(*) FROM person_info GROUP BY name, birthday, ph one_number;
1. 先把记录按照 name 值进行分组,所有 name 值相同的记录划分为一组。
2. 将每个 name 值相同的分组里的记录再按照 birthday 的值进行分组,将 birthday 值相同的记录放到一个小 分组里,所以看起来就像在一个大分组里又化分了好多小分组。
3. 再将上一步中产生的小分组按照 phone_number 的值分成更小的分组,所以整体上看起来就像是先把记录分 成一个大分组,然后把 大分组 分成若干个 小分组 ,然后把若干个 小分组 再细分成更多的 小小分组 。
四 如何建立索引
1、只为用于搜索、排序或分组的列创建索引
2、考虑列的基数
列的值种类越多越适合建立索引
3、索引列的类型尽量小
数据类型越小,在查询时进行的比较操作越快(这是CPU层次的东东)
数据类型越小,索引占用的存储空间就越少,在一个数据页内就可以放下更多的记录,从而减少磁盘 I/O 带来的性能损耗,也就意味着可以把更多的数据页缓存在内存中,从而加快读写效率。
4、索引字符串值的前缀
5、让索引列在比较表达式中单独出现
6、主键插入顺序
7、冗余和重复索引
五 总结
1. B+ 树索引在空间和时间上都有代价,所以没事儿别瞎建索引。
2. B+ 树索引适用于下边这些情况:
全值匹配
匹配左边的列
匹配范围值
精确匹配某一列并范围匹配另外一列
用于排序
用于分组
3. 在使用索引时需要注意下边这些事项:
只为用于搜索、排序或分组的列创建索引
为列的基数大的列创建索引
索引列的类型尽量小
可以只对字符串值的前缀建立索引
只有索引列在比较表达式中单独出现才可以适用索引
为了尽可能少的让 聚簇索引 发生页面分裂和记录移位的情况,让主键AUTO_INCREMENT。
定位并删除表中的重复和冗余索引
尽量使用 覆盖索引 进行查询,避免 回表 带来的性能损耗。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









