







 本文介绍了fall2023版本中可扩展哈希表的结构,包括Header页、Directory页和Bucket页的设计与实现,强调了移动构造函数、析构函数和Drop函数在内存管理中的作用,以及如何通过页面卫兵实现并发控制,确保正确释放资源并防止内存泄漏。
本文介绍了fall2023版本中可扩展哈希表的结构,包括Header页、Directory页和Bucket页的设计与实现,强调了移动构造函数、析构函数和Drop函数在内存管理中的作用,以及如何通过页面卫兵实现并发控制,确保正确释放资源并防止内存泄漏。
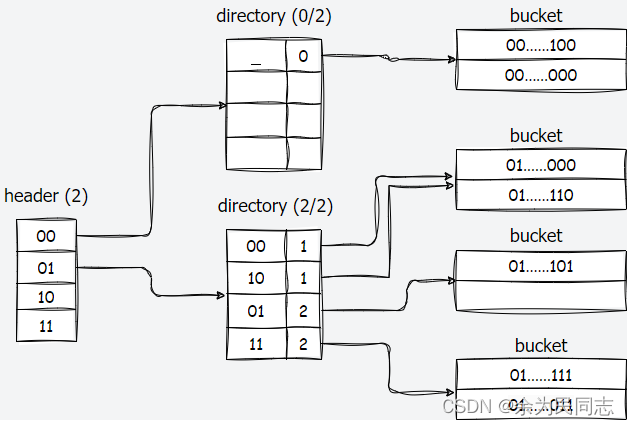
在fall2019的版本中需要实现的hash table的测试代码(hash_table_page_test.cpp、hash_table_test.cpp)已经被注释掉了,所以这里实现的是fall2023版本中的可扩展哈希。引用此前笔记中的内容,展示可扩展哈希的结构:

但是在该项目实现中,需要还有一个header的结构,根据hash值的前2位分配到不同的directory:
读/写页面卫兵
🔗代码链接:https://gitee.com/cnyuyang/bustub/blob/master/src/storage/page/page_guard.cpp
该Task的目的是:如果程序员忘记调用UnpinPage,页面将永远不会被从缓冲池中驱逐出去。导致缓冲池以更少的帧数量运行,因此将有更多的页交换进出磁盘。不仅性能受到影响,BUG也很难被发现。而这个卫兵的作用则是:创建页面卫兵为局部变量,当离开作用域时会自动执行析构函数,在析构函数中便可以调用页面的UnpinPage方法,帮助程序员自动释放资源。
移动构造函数&移动赋值语句
- 移动构造函数
只需要在构造函数中将that中的资源移动到this中:
std::swap(this->bpm_, that.bpm_);
std::swap(this->page_, that.page_);
this->is_dirty_ = that.is_dirty_;
使用: BasicPageGuard a = BasicPageGuard(std::move(b))
- 移动赋值语句
先释放当前对象对Buffer Pool的占用,再将that中的资源移动到this中:
Drop();
std::swap(this->bpm_, that.bpm_);
std::swap(this->page_, that.page_);
this->is_dirty_ = that.is_dirty_;
return *this;
使用: BasicPageGuard a = std::move(b)
在ReadPageGuard/WritePageGuard的移动赋值语句中,除了调用
UnpinPage方法还需要释放自己持有的锁。
析构函数&Drop
析构函数只会调用Drop函数,Drop函数,可能被隐式的调用(析构函数),也可能被显示的调用(直接调用Drop函数)。所以避免重复释放以及空指针异常,先判断自己的资源是否为空,不为空则调用UnpinPage方法:
if (bpm_ != nullptr && page_ != nullptr) {
bpm_->UnpinPage(page_->GetPageId(), is_dirty_);
}
bpm_ = nullptr;
page_ = nullptr;
在
ReadPageGuard/WritePageGuard的Drop函数中,除了调用UnpinPage方法还需要释放自己持有的锁。
UpgradeRead&UpgradeWrite
将BasicPageGuard升级为ReadPageGuard或WritePageGuard。
- 对页面上锁
- 创建
ReadPageGuard/WritePageGuard - 释放本身资源
auto BasicPageGuard::UpgradeRead() -> ReadPageGuard {
if (page_ != nullptr) {
page_->RLatch();
}
auto read_page_guard = ReadPageGuard(bpm_, page_);
bpm_ = nullptr;
page_ = nullptr;
return read_page_guard;
}
可扩展哈希页面实现
Header页实现
🔗代码链接:https://gitee.com/cnyuyang/bustub/blob/master/src/storage/page/extendible_htable_header_page.cpp

这个页面的主要作用,就是根据计算出来的hash值,索引到对应存储页面。该类中的数据包括:
-
directory_page_ids_:保存directory页面的page_id -
max_depth_:header页能处理的最大的深度,决定能索引的directory页面的最大大小。
需要实现的方法:
-
Init:初始化,往directory_page_ids_会用到的区域填充非法page_id-INVALID_PAGE_ID,代表未分配。 -
MaxSize:能索引的directory页面的最大大小。由max_depth_决定,就是max_depth_位数能表示多少数据,及1<<max_depth_。 -
HashToDirectoryIndex:元素的hash值对应的directory在directory_page_ids_数组的下标。就是值的前max_depth_位,及hash >> (sizeof(uint32_t) * 8 - this->max_depth_)。 -
GetDirectoryPageId:获取directory页面的page_id,从数组中查询:directory_page_ids_[directory_idx]。 -
SetDirectoryPageId:设置directory页面的page_id,及设置数组:directory_page_ids_[directory_idx] = directory_page_id。
Directory页实现
🔗代码链接:https://gitee.com/cnyuyang/bustub/blob/master/src/storage/page/extendible_htable_directory_page.cpp

这个页面的主要作用,一方面是索引到存储数据的bucket页面,一方面是维护全局及bucket页面的度。该类存储的数据包括:
-
max_depth_:度可用最大的深度 -
global_depth_:全局的度 -
local_depths_:每个bucket页面的度 -
bucket_page_ids_:保存bucket页面的page_id
需要实现的方法:
-
Init:初始化,local_depths_中填充初始的度(0),bucket_page_ids_中填充初始非法page_id-INVALID_PAGE_ID,代表未分配。 -
MaxSize:返回能最多管理的bucket数量,及1 << max_depth_。 -
Size:当前能管理bucket数量,及1 << global_depth_ -
GetLocalDepth、SetLocalDepth、IncrLocalDepth、DecrLocalDepth:对bucket页面的度的管理,根据数组下标操作local_depths_数组。 -
GetBucketPageId、SetBucketPageId:对bucket页面的page_id的管理,根据数组下标操作bucket_page_ids_数组。 -
GetGlobalDepthMask、HashToBucketIndex:掩码(111…111):global_depth_个1、hash & mark就是要存储的bucket的下标。 -
IncrGlobalDepth:增加全局的度,该函数要实现的是:bucket_page_ids_,local_depths_,数组扩容一倍,内容先复制之前的global_depth_++

拆分满了的
bucket的前置准备
-
GetSplitImageIndex:获取需要被拆分的bucket的,另一个用于存储新bucket的数组索引。及上图中的紫色索引。 -
CanShrink:是否可以收缩,当所有bucket的度,小于全局的度global_depth_是可以收缩。 -
DecrGlobalDepth:减小全局的度,直接global_depth_--。
Bucket页实现
🔗代码链接:https://gitee.com/cnyuyang/bustub/blob/master/src/storage/page/extendible_htable_bucket_page.cpp

该页面用于实际存储key、value的数据,页面中存在的数据包括;
-
size_:当前存储的kv数量。 -
max_size_:能存储最多的kv数量。 -
array_:保存kv的数组
该页面要实现的函数:
-
Lookup:根据key查找value,及遍历array_数组 -
Insert:如果该bucket满了,直接报错。如果key已经存在,直接报错。插在数组的最后。 -
Remove:根据key查找数组中存储的位置,将后面的元素往前移动一个位置。
可扩展哈希实现
🔗代码链接:https://gitee.com/cnyuyang/bustub/blob/master/src/container/disk/hash/disk_extendible_hash_table.cpp
该实现需要使用上面章节实现的各类可持久化页面。相关函数实现:
-
DiskExtendibleHashTable:构造函数,从Buffer Pool中申请一个页面,调用Header页面的初始化接口。 -
GetValue:通过key查找值。一层一层的查找,通过Header页面查找对应的Directory页面,再通过Directory页面查找Bucket页面。最后调用Bucket页面的Lookup函数。中间任意一处没有查找到则认为不存在。

Insert:插入键值对。和GetValue函数类似,一层一层查找到Bucket页面,进行插入。- 若
Directory页面或者Bucket页面此前没有,则新申请页面再进行插入。 - 若
Bucket页面已满,则进行Bucket页面的拆分,再递归调用该函数
- 若

Bucket页面能进行拆分判断条件:
当前
Bucket页面的度比全局的度小,这个时候只需要对Bucket页面的度进行+1操作当前全局的度小于
Directory页面能处理最大的度。这个情况则需要对Directory页面全局的度和Bucket页面的度同时进行+1操作
SplitBucket:该函数为自己新加的,用于桶拆分。因为度的变化已经在Insert函数中做了,所以本函数需要实现申请新桶,替换到新位置,然后进行桶的拆分。将原来桶中的元素重新hash分配。

Remove:移除键值对。和GetValue函数类似,一层一层查找到Bucket页面,进行删除操作。
@Todo 这里没有实现,哈希表的收缩。
并发控制
在Lecture#9 Index Concurrency Control课中学习到,对哈希表的枷锁有两种形式:对page页加锁、对solt槽位枷锁。
方案一:对page页加锁
如下图所示,如果锁的粒度是针对page页进行的。那么线程1获取了整个page页的读锁,线程2获取线程1所在槽位下方的槽位的写锁时候也需要进行等待。

方案二:对solt槽位加锁
如下图所示,线程1只获取A所在槽位的读锁,不会影响线程2获取C所在槽位的写锁。

在本项目中,只要我们的从Buffr Pool中获取、申请页面的使用调用带有Guard的安全函数,按照之前的实现,我们就能实现方案一页面级别的并发控制。















 362
362











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









