







1. RDD基础
(1) 概述
RDD其实就是分布式的元素集合。在Spark中,对数据的所有操作不外乎创建RDD,转化RDD以及调用RDD操作进行求值。
Spark 中的 RDD 就是一个不可变的分布式对象集合。每个 RDD 都被分为多个分区,这些分区运行在集群中的不同节点上。RDD 可以包含 Python、Java、Scala 中任意类型的对象,甚至可以包含用户自定义的对象。
(2) 创建RDD
用户可以使用两种方法创建 RDD:
- 读取一个外部数据集。
- 在驱动器程序里分发驱动器程序中的对象集合(比如
list和set)。
在 Python 中使用 textFile() 创建一个字符串的 RDD:
>>> lines = sc.textFile("README.md")
(3) 操作RDD
RDD支持两种类型的操作: 转化操作(transformation) 和行动操作(action)。
转化操作
转化操作会由一个 RDD 生成一个新的 RDD。例如,根据单词匹配情况筛选数据就是一个常见的转化操作。
调用转化操作 filter():
>>> pythonLines = lines.filter(lambda line: "Python" in line)
行动操作
行动操作会对 RDD 计算出一个结果,并把结果返回到驱动器程序中,或把结果存储到外部存储系统(如 HDFS)中。
first() 就是我们之前调用的一个行动操作,它会返回 RDD 的第一个元素。
调用 first() 行动操作:
>>> pythonLines.first()
转化操作和行动操作的区别
转化操作和行动操作的区别在于 Spark 计算 RDD 的方式不同。虽然你可以在任何时候定义新的 RDD,但 Spark 只会惰性计算这些 RDD。它们只有第一次在一个行动操作中用到时,才会真正计算。
注意:
默认情况下,Spark 的 RDD 会在你每次对它们进行行动操作时重新计算。如果想在多个行动操作中重用同一个 RDD,可以使用RDD.persist() 让 Spark 把这个 RDD 缓存下来。在第一次对持久化的 RDD 计算之后,Spark 会把 RDD 的内容保存到内存中(以分区方式存储到集群中的各机器上),这样在之后的行动操作中,就可以重用这些数据了。我们也可以把 RDD 缓存到磁盘上而不是内存中。
在实际操作中,你会经常用 persist() 来把数据的一部分读取到内存中,并反复查询这部分数据。(cache() 与使用默认存储级别调用 persist() 是一样的)
把 RDD 持久化到内存中:
>>> pythonLines.persist
>>> pythonLines.count()
2
>>> pythonLines.first()
u'## Interactive Python Shell'WorkFlow总结
总的来说,每个 Spark 程序或 shell 会话都按如下方式工作。
- (1) 从外部数据创建出输入 RDD。
- (2) 使用诸如
filter()这样的转化操作对 RDD 进行转化,以定义新的 RDD。 - (3) 告诉 Spark 对需要被重用的中间结果 RDD 执行
persist()操作。 - (4) 使用行动操作(例如
count()和first()等)来触发一次并行计算,Spark 会对计算进行优化后再执行。
2. 创建RDD
Spark 提供了两种创建 RDD 的方式:读取外部数据集,以及在驱动器程序中对一个集合进行并行化。
(1) 对集合并行化
创建RDD最简单的方式就是把程序中一个已有的集合(对象)传给SparkContext的parallelize()方法。
Python 写法:
lines = sc.parallelize(["Pandas", "I like it"])
Scala 写法:
val lines = sc.parallelize(List("Pandas", "I like it"))
使用场景:
这种方式在学习 Spark 时非常有用,它让你可以在 shell 中快速创建出自己的 RDD,然后对这些 RDD 进行操作。不过,需要注意的是,除了开发原型和测试时,这种方式用得并不多,毕竟这种方式需要把你的整个数据集先放在一台机器的内存中。
(2) 读取外部数据集
更常用的方式是从外部存储中读取数据来创建 RDD。外部数据集的读取会在后面详细介绍。
不过,我们这里只介绍将文本文件读入为一个存储字符串的 RDD 的方法SparkContext.textFile()。
Python写法:
lines = sc.textFile("/path/README.md")
Scala写法:
val lines = sc.textFile("/path/README.md")
3. RDD操作
RDD 支持两种操作:转化操作和行动操作。
RDD 的转化操作是返回一个新的 RDD 的操作,比如 map() 和 filter() ;而行动操作则是向驱动器程序返回结果或把结果写入外部系统的操作,会触发实际的计算,比如 count() 和 first() 。
Spark 对待转化操作和行动操作的方式很不一样,因此理解你正在进行的操作的类型是很重要的。如果对于一个特定的函数是属于转化操作还是行动操作感到困惑,你可以看看它的返回值类型:转化操作返回的是RDD,而行动操作返回的是其他的数据类型。
(1) 转化操作
RDD 的转化操作是返回新 RDD 的操作。转化出来的 RDD 是惰性求值的,只有在行动操作中用到这些 RDD 时才会被计算。
许多转化操作都是针对各个元素的,也就是说,这些转化操作每次只会操作 RDD 中的一个元素。不过并不是所有的转化操作都是这样的。
filter()
假定我们有一个日志文件 log.txt,内含有若干消息,希望选出其中的错误消息。我们可以使用转化操作filter() 。
Python Code:
inputRDD = sc.textFile("log.txt")
errorsRDD = inputRDD.filter(lambda line: "error" in line)Scala Code:
val inputRDD = sc.textFile("log.txt")
val errorsRDD = inputRDD.filter(line => line.contains("error"))注意: filter() 操作不会改变已有的 inputRDD 中的数据。实际上,该操作会返回一个全新的 RDD。
union()
我们使用另一个转化操作 union() 来打印出包含 error 或 warning 的行。
Python Code:
errorsRDD = inputRDD.filter(lambda line: "error" in line)
warningsRDD = inputRDD.filter(lambda line: "warning" in line)
badLinesRDD = errorsRDD.union(warningsRDD)Scala Code:
val errorsRDD = inputRDD.filter(line => line.contains("error"))
val warningsRDD = inputRDD.filter(line => line.contains("warning"))
val badLinesRDD = errorsRDD.union(warningsRDD)union() 与 filter() 的不同点在于它操作两个 RDD 而不是一个。转化操作可以操作任意数量的输入 RDD。
lineage graph
通过转化操作,你从已有的 RDD 中派生出新的 RDD,Spark 会使用谱系图(lineage graph)来记录这些不同 RDD 之间的依赖关系。Spark 需要用这些信息来按需计算每个 RDD,也可以依靠谱系图在持久化的 RDD 丢失部分数据时恢复所丢失的数据。
Lineage Graph 日志分析过程中创建出的 RDD 谱系图
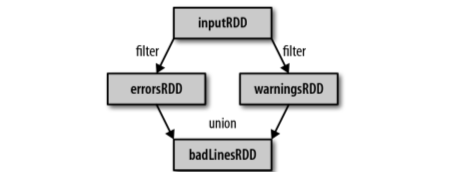
(2) 行动操作
行动操作是第二种类型的 RDD 操作,它们会把最终求得的结果返回到驱动器程序,或者写入外部存储系统中。由于行动操作需要生成实际的输出,它们会强制执行那些求值必须用到的 RDD 的转化操作(转化操作在此才真正执行)。
count(), take()
我们可能想输出关于 badLinesRDD 的一些信息。为此,需要使用两个行动操作来实现:用 count() 来返回计数结果,用 take() 来收集RDD 中的一些元素。
在 Python 中使用行动操作对错误进行计数:
print "Input had " + badLinesRDD.count() + " concerning lines"
print "Here are 10 examples:"
for line in badLinesRDD.take(10):
print line在 Scala 中使用行动操作对错误进行计数:
println("Input had " + badLinesRDD.count() + " concerning lines")
println("Here are 10 examples:")
badLinesRDD.take(10).foreach(println)在这个例子中,我们在驱动器程序中使用 take() 获取了 RDD 中的少量元素。然后在本地遍历这些元素,并在驱动器端打印出来。
collect()
RDD 还有一个 collect() 函数,可以用来获取整个 RDD 中的数据。如果你的程序把 RDD 筛选到一个很小的规模,并且你想在本地处理这些数据时,就可以使用它。记住,只有当你的整个数据集能在单台机器的内存中放得下时,才能使用 collect() ,因此, collect() 不能用在大规模数据集上。
saveAsTextFile(), saveAsSequenceFile()
你可以使用 saveAsTextFile() 、 saveAsSequenceFile() ,或者任意的其他行动操作来把 RDD 的数据内容以各种自带的格式保存起来。
4. 向Spark传递函数
(1)Python中
传递函数时需要小心的一点是,Python会在你不经意间把函数所在的对象也序列化传出去。当你传递的对象是某个对象的成员,或者包含了对某个对象中一个字段的引用时(例如 self.field ),Spark 就会把整个对象发到工作节点上,这可能比你想传递的东西大得多(见下例)。有时,如果传递的类里面包含 Python 不知道如何序列化传输的对象,也会导致你的程序失败。
你不应该这么做:
class SearchFunctions(object):
def __init__(self, query):
self.query = query
def isMatch(self, s):
return self.query in s
def getMatchesFunctionReference(self, rdd):
# 问题:在"self.isMatch"中引用了整个self
return rdd.filter(self.isMatch)代替的方案是只把你所需要的字段从对象中拿出来放到一个局部变量中,然后传递这个局部变量。
你应该这么做:
class SearchFunctions(object):
def __init__(self, query):
self.query = query
def isMatch(self, s):
return self.query in s
def getMatchesFunctionReference(self, rdd):
isMatch = self.isMatch # 局部变量isMatch
return rdd.filter(isMatch)(2)Scala中
- 在 Scala 中,我们可以把定义的内联函数、方法的引用或静态方法传递给 Spark,就像Scala 的其他函数式 API 一样。
- 我们还要考虑其他一些细节,比如所传递的函数及其引用的数据需要是可序列化的(实现了 Java 的
Serializable接口)。 - 除此以外,与 Python 类似,传递一个对象的方法或者字段时,会包含对整个对象的引用。类似上面对 Python 执行的操作,我们可以把需要的字段放到一个局部变量中,来避免传递包含该字段的整个对象,如下面实例 所示:
class SearchFunctions(val query: String) {
def isMatch(s: String): Boolean = {
s.contains(query)
}
def getMatchesFunctionReference(rdd: RDD[String]): RDD[String] = {
// 问题: "isMatch"表示"this.isMatch",因此我们会传递整个"this"对象
rdd.map(isMatch)
}
def getMatchesNoReference(rdd: RDD[String]): RDD[String] = {
// 安全:只把我们需要的字段拿出来放入局部变量中
val query_ = this.query
rdd.map(x => x.split(query_))
}
}如果在 Scala 中出现了 NotSerializableException ,通常问题就在于我们传递了一个不可序列化的类中的函数或字段。记住,传递局部可序列化变量或顶级对象中的函数始终是安全的。(??)
5. 常见的转化操作和行动操作
本节我们会接触 Spark 中大部分常见的转化操作和行动操作。包含特定数据类型的 RDD还支持一些附加操作,例如,数字类型的 RDD 支持统计型函数操作,而键值对形式的RDD 则支持诸如根据键聚合数据的键值对操作。
(1)基本RDD的转化操作
首先来讲讲哪些转化操作受任意数据类型的 RDD 支持。
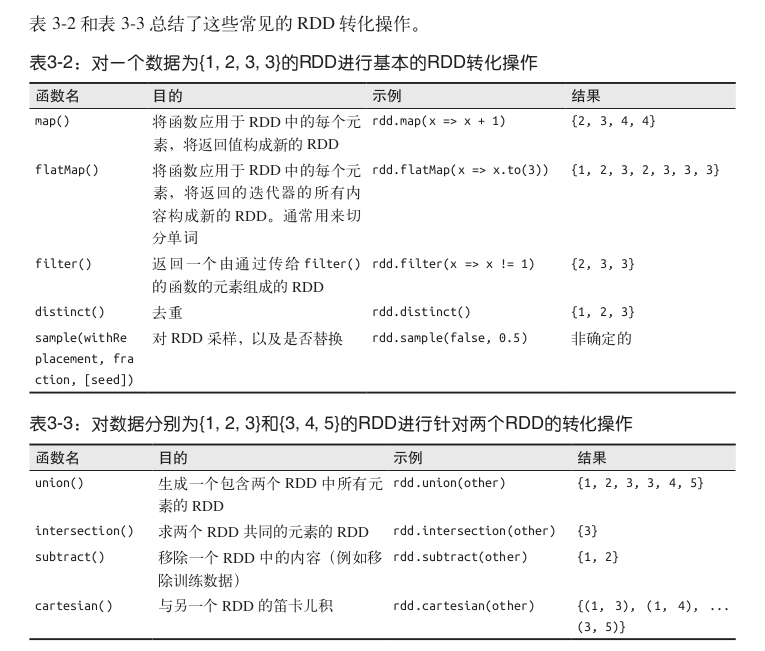
1) 针对各个元素的转化操作
最常使用的是map()和filter(),还有flatMap()。
map()接收一个函数,把这个函数用于 RDD 中的每个元素,将函数的返回结果作为结果RDD 中对应元素的值。map()的返回值类型不需要和输入类型一样。这样如果有一个字符串 RDD,并且我们的map()函数是用来把字符串解析并返回一个Double值的,那么此时我们的输入 RDD 类型就是RDD[String],而输出类型是RDD[Double]。filter()则接收一个函数,并将 RDD 中满足该函数的元素放入新的 RDD 中返回。- 有时候,我们希望对每个输入元素生成多个输出元素。实现该功能的操作叫作
flatMap()。和map()类似,我们提供给flatMap()的函数被分别应用到了输入 RDD 的每个元素上。不过返回的不是一个元素,而是一个返回值序列的迭代器。输出的 RDD 倒不是由迭代器组成的。我们得到的是一个包含各个迭代器可访问的所有元素的 RDD。
map使用(Python):
nums = sc.parallelize([1, 2, 3, 4])
squared = nums.map(lambda x: x * x).collect()
for num in squared:
print "%i " % (num)
map使用(Scala):
val inputRDD = sc.parallelize(List(1, 2, 3, 4))
val resultRDD = inputRDD.map(x => x * x)
println(resultRDD.collect().mkString(","))
flatMap使用(Python):
lines = sc.parallelize(["hello world", "hi"])
words = lines.flatMap(lambda line: line.split(" "))
words.first() # 返回"hello"
flatMap使用(Scala):
val lines = sc.parallelize(List("hello world", "hi"))
val words = lines.flatMap(line => line.split(" "))
words.first() // 返回"hello"2) 伪集合操作
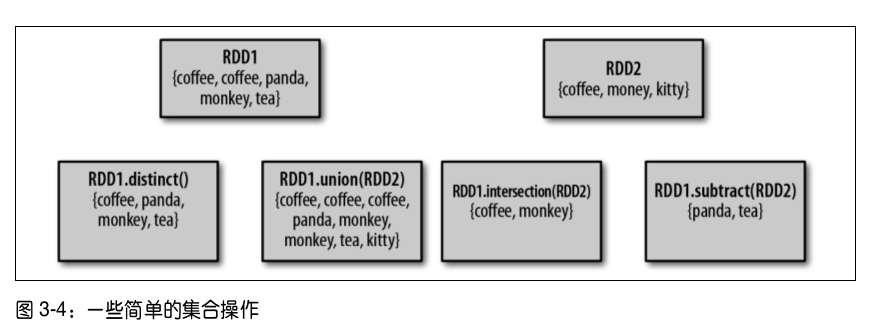
尽管 RDD 本身不是严格意义上的集合,但它也支持许多数学上的集合操作,比如合并和相交操作。注意,这些操作都要求操作的 RDD 是相同数据类型的。
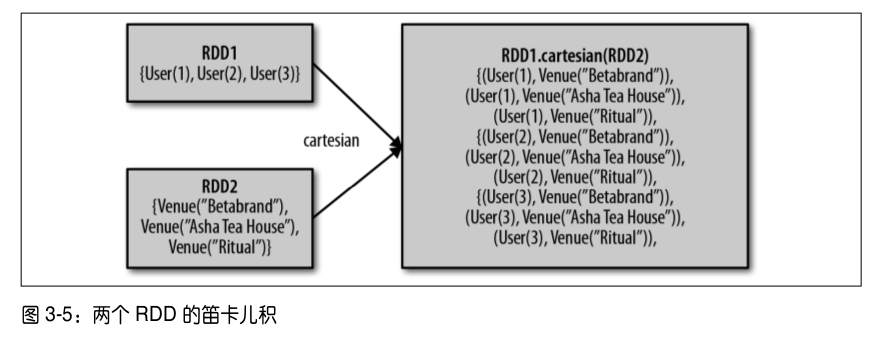
distinct(): 我们可以使用RDD.distinct()转化操作来生成一个只包含不同元素的新RDD。不过需要注意,distinct()操作的开销很大,因为它需要将所有数据通过网络进行混洗(shuffle),以确保每个元素都只有一份。union(): 它会返回一个包含两个 RDD 中所有元素的 RDD。与数学中的union()操作不同的是,如果输入的 RDD 中有重复数据,Spark 的union()操作也会包含这些重复数据。intersection(): 返回两个 RDD 中都有的元素。intersection()在 运 行 时 也 会 去 掉 所 有 重 复 的 元 素( 单 个 RDD 内 的 重 复 元 素 也 会 一 起 移 除 )。 尽 管intersection()与union()的概念相似,intersection()的性能却要差很多,因为它需要通过网络混洗数据来发现共有的元素。subtract(): 它接 收 另 一 个 RDD 作 为 参 数, 返 回一个由只存在于第一个 RDD 中而不存在于第二个 RDD 中的所有元素组成的 RDD。和intersection()一样,它也需要数据混洗。cartesian(): 计算两个 RDD 的笛卡儿积。它会返回所有可能的(a, b)对,其中a是源 RDD 中的元素,而b则来自另一个 RDD。笛卡儿积在我们希望考虑所有可能的组合的相似度时比较有用。不过要特别注意的是,求大规模 RDD 的笛卡儿积开销巨大。
图示:
(2)基本RDD的行动操作
下表是一个行动操作的总结:

下面我们详细介绍其中一部分。
reduce(): 它接收一个函数作为参数,这个函数要操作RDD 的两个元素并返回一个同样类型的新元素。一个简单的例子就是函数+,可以用它来对我们的 RDD 进行累加。使用reduce(),可以很方便地计算出 RDD中所有元素的总和、元素的个数,以及其他类型的聚合操作。fold(): 和reduce()类似,接收一个与reduce()接收的函数签名相同的函数,再加上一个“初始值”来作为每个分区第一次调用时的结果。你所提供的初始值应当是你提供的操作的单位元素;也就是说,使用你的函数对这个初始值进行多次计算不会改变结果(例如+对应的0,*对应的1,或拼接操作对应的空列表)。aggregate(): Spark文档中aggregate函数定义如下:def aggregate[U](zeroValue: U)(seqOp: (U, T) ⇒ U, combOp: (U, U) ⇒ U)(implicit arg0: ClassTag[U]): UAggregate the elements of each partition, and then the results for all the partitions, using given combine functions and a neutral “zero value”. This function can return a different result type,
U, than the type of this RDD,T. Thus, we need one operation for merging aTinto anUand one operation for merging twoU’s, as inscala.TraversableOnce. Both of these functions are allowed to modify and return their first argument instead of creating a newUto avoid memory allocation.简单来讲,
seqOp函数在自己单独的分区内将原始RDD中元素类型为T的元素转化为类型U的元素。而comOp参数合并所有分区内类型为U的元素。collect(): 它会将整个 RDD 的内容返回。collect()通常在单元测试中使用,因为此时 RDD 的整个内容不会很大,可以放在内存中。take(n): 返回 RDD 中的 n 个元素,并且尝试只访问尽量少的分区,因此该操作会得到一个不均衡的集合。top(): 如果为数据定义了顺序,就可以使用top()从 RDD 中获取前几个元素。top()会使用数据的默认顺序,但我们也可以提供自己的比较函数,来提取前几个元素。takeSample(withReplacement, num,seed): 在 驱动器程序中对我们的数据进行采样,withReplacement决定是否有放回采样。foreach(): 可以使用foreach()行动操作来对 RDD 中的每个元素进行操作。
例子:
用reduce累计求和(Python):
sum = rdd.reduce(lambda x, y: x + y)用reduce累计求和(Scala):
val sum = rdd.reduce((x, y) => x + y)
用aggregate求和,统计,平均(Python):
sumCount = nums.aggregate((0, 0),
(lambda acc, value: (acc[0] + value, acc[1] + 1),
(lambda acc1, acc2: (acc1[0] + acc2[0], acc1[1] + acc2[1]))))
return sumCount[0] / float(sumCount[1])用aggregate求和,统计,平均(Scala):
scala> val nums = sc.parallelize(List(1, 2, 3, 4, 5))
scala> val sumCount = nums.aggregate((0,0))(
(acc, value) => (acc._1+value, acc._2+1),
(acc1, acc2) => (acc1._1+acc2._1, acc1._2+acc2._2))
sumCount: (Int, Int) = (15,5)
scala> val average = sumCount._1/sumCount._2
average: Int = 3(3)在不同类型RDD间转换
有些函数只能用于特定类型的 RDD,比如 mean() 和 variance() 只能用在数值 RDD 上,而 join() 只能用在键值对 RDD 上。
在 Scala 中,将 RDD 转为有特定函数的 RDD(比如在RDD[Double] 上进行数值操作)是由隐式转换来自动处理的。我们需要加上import org.apache.spark.SparkContext._ 来使用这些隐式转换。
这些隐式转换可以隐式地将一个 RDD 转为各种封装类,比如 DoubleRDDFunctions(数值数据的 RDD)和 PairRDDFunctions (键值对 RDD),这样我们就有了诸如 mean() 和variance() 之类的额外的函数。隐式转换虽然强大,但是会让阅读代码的人感到困惑。
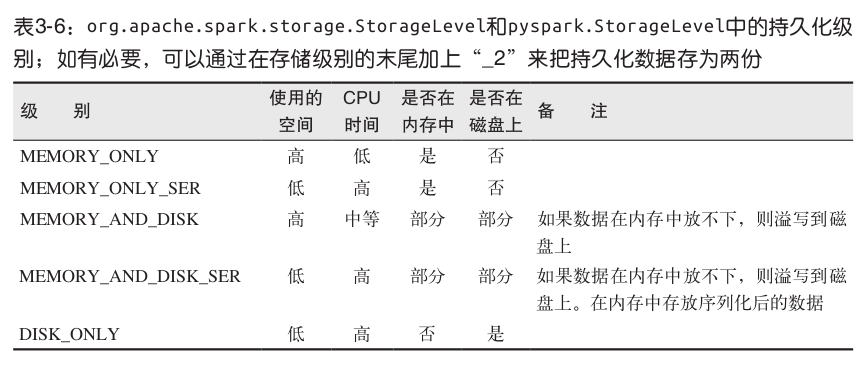
6. 持久化(缓存)
出于不同的目的,我们可以为 RDD 选择不同的持久化级别(如表 3-6 所示):
Example (Scala):
val result = input.map(x => x * x)
result.persist(StorageLevel.DISK_ONLY)
println(result.count())
println(result.collect().mkString(","))注意: 我们在第一次对这个 RDD 调用行动操作前就调用了 persist() 方法。 persist() 调用本身不会触发强制求值。
如果要缓存的数据太多,内存中放不下,Spark 会自动利用最近最少使用(LRU)的缓存策略把最老的分区从内存中移除。
- 对于仅把数据存放在内存中的缓存级别,下一次要用到已经被移除的分区时,这些分区就需要重新计算。
- 但是对于使用内存与磁盘的缓存级别的分区来说,被移除的分区都会写入磁盘。
不论哪一种情况,都不必担心你的作业因为缓存了太多数据而被打断。不过,缓存不必要的数据会导致有用的数据被移出内存,带来更多重算的时间开销。
RDD 还有一个方法叫作 unpersist() ,调用该方法可以手动把持久化的 RDD 从缓存中移除。
Ref:
《Spark快速大数据分析》















 5438
5438

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









