







文章目录
@EnableProcessing
@EnableBatchProcessing使用了@Import注解引入了BatchConfigurationSelector,这个选择器默认返回的是 SimpleBatchConfiguration配置类
SimpleBatchConfiguration
SimpleBatchConfiguration配置类继承自AbstractBatchConfiguration
先看看父类AbstractBatchConfiguration
AbstractBatchConfiguration
1、自动注入DataSource数据源
2、@Bean定义了JobBuilderFactory
3、@Bean定义了StepBuilderFactory
4、@Bean定义了JobRepository
5、@Bean定义了JobLauncher
6、@Bean定义了JobExplorer
7、@Bean定义了transactionManager
8、引入了JobScope 和 StepScope 这2个域
再来看子类 SimpleBatchConfiguration,这些bean都使用了代理的方式实现了懒加载。
其实 SimpleBatchConfiguration 允许提供1个实现了 BatchConfigurer 接口的bean,该bean需要分别实现对应的方法返回JobRepository、PlatformTransactionManager、JobLauncher、JobExplorer这些对象。
注意到:默认的实现为 DefaultBatchConfigurer,内部完成了真正的SimpleJobLauncher、JobRepository、JobExplorer、transactionManager的初始化。所以在使用时,直接注入这些对象是没问题的,只不过它们表面上都是动态代理的形式。
spring batch的表
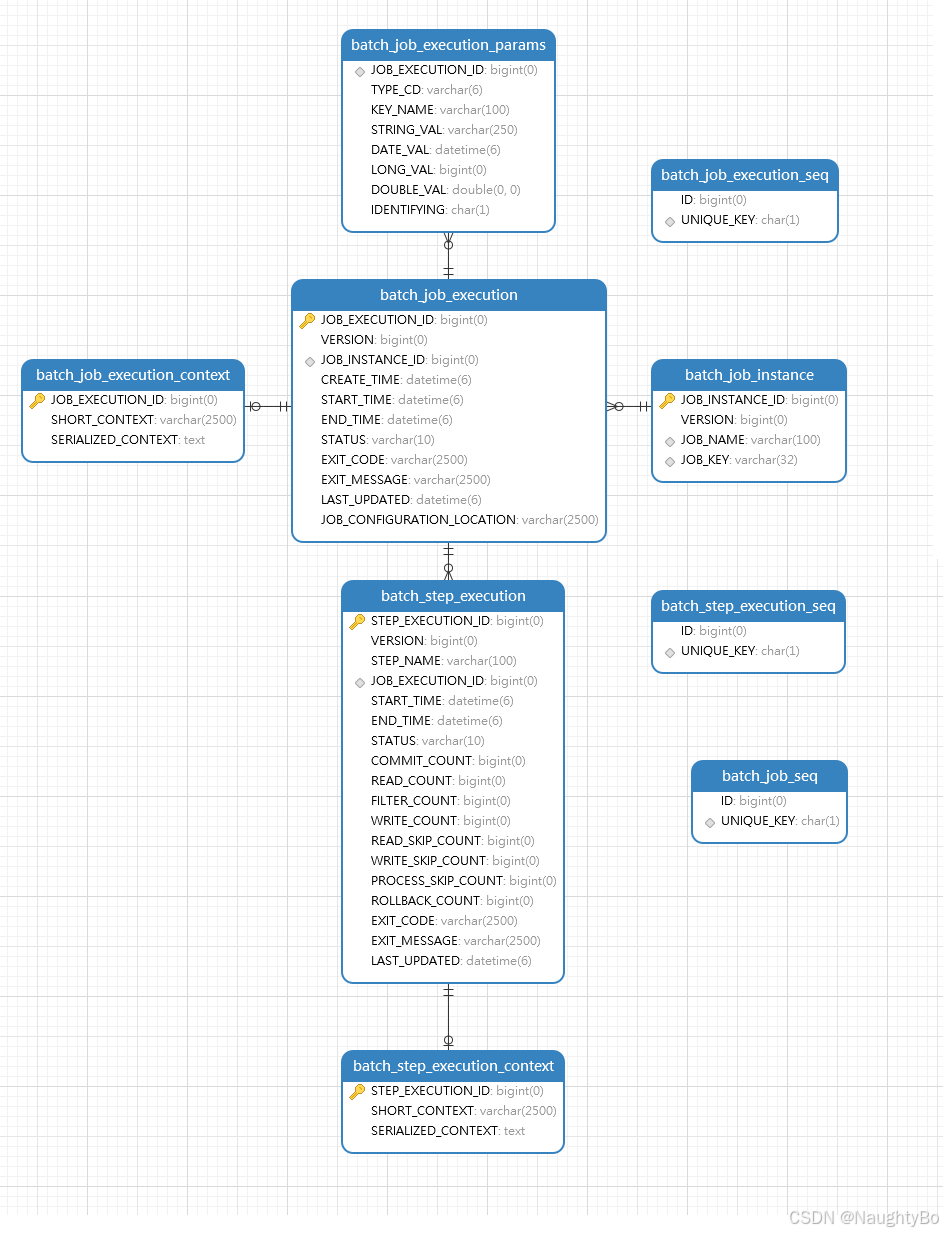
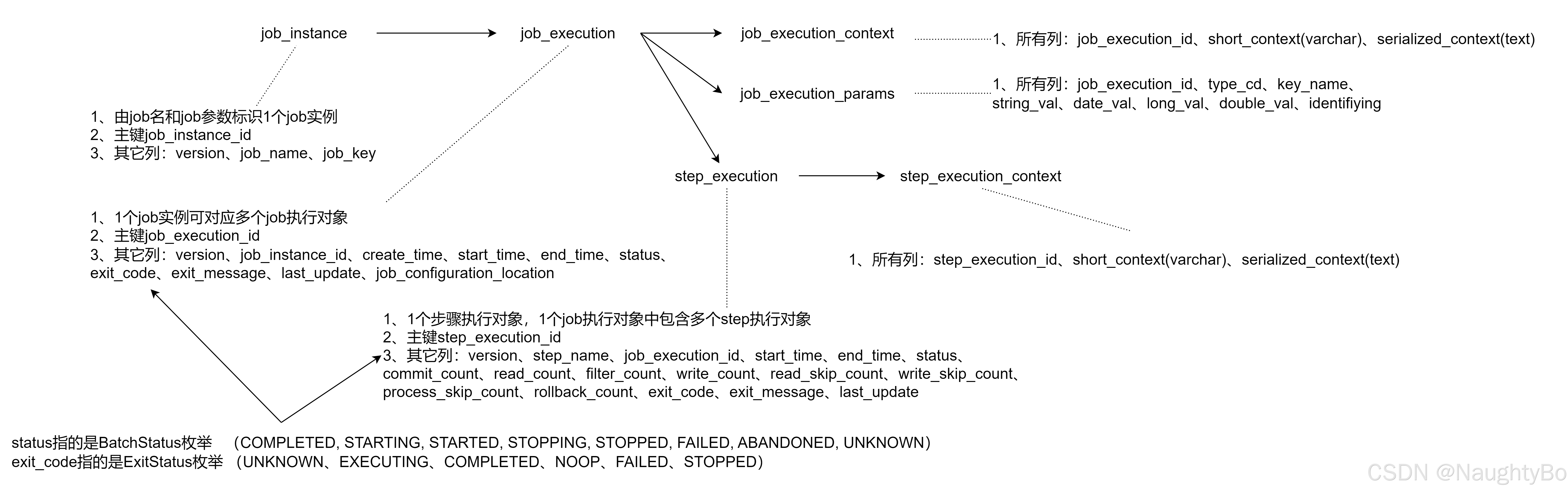
BatchStatus
jobExecution和stepExecution都共用同1个BatchStatus枚举类,它只有下面的对象。
它们的顺序很重要,一般来说:顺序值大的胜出。
public enum BatchStatus {
/**
* The batch job has successfully completed its execution.
*/
COMPLETED,
/**
* Status of a batch job prior to its execution.
*/
STARTING,
/**
* Status of a batch job that is running.
*/
STARTED,
/**
* Status of batch job waiting for a step to complete before stopping the batch job.
*/
STOPPING,
/**
* Status of a batch job that has been stopped by request.
*/
STOPPED,
/**
* Status of a batch job that has failed during its execution.
*/
FAILED,
/**
* Status of a batch job that did not stop properly and can not be restarted.
*/
ABANDONED,
/**
* Status of a batch job that is in an uncertain state.
*/
UNKNOWN;
// 取顺序大的(后面的顺序大)
public BatchStatus upgradeTo(BatchStatus other) {
if (isGreaterThan(STARTED) || other.isGreaterThan(STARTED)) {
return max(this, other);
}
// Both less than or equal to STARTED
if (this == COMPLETED || other == COMPLETED) {
return COMPLETED;
}
return max(this, other);
}
public boolean isGreaterThan(BatchStatus other) {
return this.compareTo(other) > 0;
}
public static BatchStatus max(BatchStatus status1, BatchStatus status2) {
return status1.isGreaterThan(status2) ? status1 : status2;
}
}
ExitStatus
用来表示jobExecution或stepExecution状态的类对象
它还有1个severity的概念,每个对象都有对应的severity(严重程度),如果严重程度相同,那么就比较字母顺序
| exitCode | severity |
|---|---|
| EXECUTING | 1 |
| COMPLETED | 2 |
| NOOP | 3 |
| STOPPED | 4 |
| FAILED | 5 |
| UNKNOWN | 6 |
| 其它自定义的 | 7 |
/**
* Value object used to carry information about the status of a job or step execution.
* <p>
* {@code ExitStatus} is immutable and, therefore, thread-safe.
*
* @author Dave Syer
* @author Mahmoud Ben Hassine
*
*/
public class ExitStatus implements Serializable, Comparable<ExitStatus> {
/**
* 未知状态
* Convenient constant value representing unknown state - assumed to not be
* continuable.
*/
public static final ExitStatus UNKNOWN = new ExitStatus("UNKNOWN");
/**
* 正在执行的状态
* Convenient constant value representing continuable state where processing is still
* taking place, so no further action is required. Used for asynchronous execution
* scenarios where the processing is happening in another thread or process and the
* caller is not required to wait for the result.
*/
public static final ExitStatus EXECUTING = new ExitStatus("EXECUTING");
/**
* 正常处理完成的状态
* Convenient constant value representing finished processing.
*/
public static final ExitStatus COMPLETED = new ExitStatus("COMPLETED");
/**
* 未作任何处理,因为早就完成了 的状态
* Convenient constant value representing a job that did no processing (for example,
* because it was already complete).
*/
public static final ExitStatus NOOP = new ExitStatus("NOOP");
/**
* 因为错误而失败 的状态
* Convenient constant value representing finished processing with an error.
*/
public static final ExitStatus FAILED = new ExitStatus("FAILED");
/**
* 因为 被中断而停止 的状态
* Convenient constant value representing finished processing with interrupted status.
*/
public static final ExitStatus STOPPED = new ExitStatus("STOPPED");
// 退出码
private final String exitCode;
// 退出的描述
private final String exitDescription;
// 构造方法
public ExitStatus(String exitCode) {
this(exitCode, "");
}
// and操作会将当前ExitStatus与入参ExitStatus比较serverity,值大的胜出,
// 如果值相等,那么按字母顺序比较胜出,并且它们的exitDescription将会拼接
public ExitStatus and(ExitStatus status) {
if (status == null) {
return this;
}
ExitStatus result = addExitDescription(status.exitDescription);
if (compareTo(status) < 0) {
result = result.replaceExitCode(status.exitCode);
}
return result;
}
@Override
public int compareTo(ExitStatus status) {
if (severity(status) > severity(this)) {
return -1;
}
if (severity(status) < severity(this)) {
return 1;
}
return this.getExitCode().compareTo(status.getExitCode());
}
private int severity(ExitStatus status) {
if (status.exitCode.startsWith(EXECUTING.exitCode)) {
return 1;
}
if (status.exitCode.startsWith(COMPLETED.exitCode)) {
return 2;
}
if (status.exitCode.startsWith(NOOP.exitCode)) {
return 3;
}
if (status.exitCode.startsWith(STOPPED.exitCode)) {
return 4;
}
if (status.exitCode.startsWith(FAILED.exitCode)) {
return 5;
}
if (status.exitCode.startsWith(UNKNOWN.exitCode)) {
return 6;
}
return 7;
}
}
JobLauncher

@StepScope&@JobScope
@StepScope本身是1个step的scope域,其对应的Scope实现为StepScope
先看看@StepScope注解,关于@Scope注解的深入了解,可查看@Scope注解的用法及源码分析
@Scope(value = "step", proxyMode = ScopedProxyMode.TARGET_CLASS)
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface StepScope {
}
再看它是如何在运行时,获取到对应的bean的,核心在于getContext这个方法,可以看到核心就是从StepSynchronizationManager中获取,因此,框架必须在获取(解析)前,先存入到StepSynchronizationManager。
private StepContext getContext() {
StepContext context = StepSynchronizationManager.getContext();
if (context == null) {
throw new IllegalStateException("No context holder available for step scope");
}
return context;
}
JobScope也是同样的道理。
Step体系
RepeatTemplate初始化的位置:SimpleStepBuilder#createTasklet(),创建了RepeatTemplate,并且设置了new SimpleCompletionPolicy(chunkSize)给该RepeatTemplate对象,该restTemplate设置给了SimpleChunkProvider以支持循环读取到指定的批量数
TaskExecutorRepeatTemplate初始化的位置:AbstractTaskletStepBuilder#build,判断如果设置了taskExecutor,那么创建的就是TaskExecutorRepeatTemplate,并且使用该taskExecutor,所以taskletStep会使用该taskExecutorRepeatTemplate来做循环操作。因此,多线程的使用位置在此处。
RepeatTemplate
图示关系(RepeatOperations&RepeatStatus&RepeatCallback&RepeatContext&CompletionPolicy)

属性
RepeatListener[] listeners - 监听器属性(这里并不是只是监听器这么简单,而是类似拦截器,它可以改变执行流程)
CompletionPolicy completionPolicy - 完成策略
ExceptionHandler exceptionHandler - 异常处理器
方法
RepeatStatus iterate(RepeatCallback callback)
由于它实现RepeatOperations接口,所以它必须有这个方法,这相当于是个入口。
这个方法的作用就是拿到当前线程的RepeatContext,然后,开始自己的处理,处理之后,恢复原来的RepeatContext
@Override
public RepeatStatus iterate(RepeatCallback callback) {
// 就是从ThreadLocal中去拿绑定在当前线程的RepeatContext,先暂时保存到outer中
RepeatContext outer = RepeatSynchronizationManager.getContext();
// 默认 要继续
RepeatStatus result = RepeatStatus.CONTINUABLE;
try {
// 交给 excuteInternal(callback) 方法去执行
// 1、RepeatCallback具有 doIteration(RepeatContext)方法,并且返回值的类型就是 RepeatStatus
result = executeInternal(callback);
} finally {
// 删掉绑定在当前线程的RepeatContext,恢复之前的RepeatContext
RepeatSynchronizationManager.clear();
if (outer != null) {
RepeatSynchronizationManager.register(outer);
}
}
// 将result 返回
return result;
}
RepeatStatus executeInternal(final RepeatCallback callback)
private RepeatStatus executeInternal(final RepeatCallback callback) {
// 创建1个新的RepeatContext上下文
// 1、就是先从当前线程中获取RepeatContext
// 2、交给completionPolicy#start(context),返回1个新的 RepeatContext(RepeatContext本身就是parent的概念在里面)
// 3、将新的 RepeatContext 绑定到当前线程
RepeatContext context = start();
// 先检查当前RepeatContext#completeOnly这个标记是否为true,
// 如果为true,那就表示完成了,running就是false,下面的while(running)就不执行了,
// 如果为false,那就检查 父RepeatContext#completeOnly的标记,父标记为true,也算true
boolean running = !isMarkedComplete(context);
for (RepeatListener interceptor : listeners) {
// 1、所以第一个 RepeatListener的open方法一定会执行
// 2、在open方法中可以修改context中的标记
interceptor.open(context);
// 如果context此时标记改为true,那么running就为false了
running = running && !isMarkedComplete(context);
// 如果running为false,则结束循环,后续listener不再执行
if (!running)
break;
}
// result 即为 返回值,默认为 继续处理
RepeatStatus result = RepeatStatus.CONTINUABLE;
// 1、此处默认创建1个 RepeatInternalState 对象,它记录了 Throwable 的异常 Set集合
// 2、子类TaskExecutorRepeatTemplate重写了该方法,创建的是 ResultQueueInternalState 对象
RepeatInternalState state = createInternalState(context);
// 获取到 state对象的 throwables 属性
Collection<Throwable> throwables = state.getThrowables();
// deferred 用来存储监听器或异常处理器中发生的异常,目的是和state中的异常区分开来
Collection<Throwable> deferred = new ArrayList<>();
try {
// 当running为 true时,进入循环
while (running) {
// 又给 RepeatListener 1次机会去修改RepeatContext中的completionOnly标记,
// 如果将标记修改为true,则running为false,但仍会将剩下的RepeatListener走完,下方的if条件将不成立
for (int i = 0; i < listeners.length; i++) {
RepeatListener interceptor = listeners[i];
interceptor.before(context);
running = running && !isMarkedComplete(context);
}
// 再次判断running
if (running) {
try {
// 1、核心逻辑执行入口
// 2、第一步:调用 update(context), 默认实现是委托给了completionPolicy.update(context),
// 这个completionPolicy会将RepeatContextSupport#count 属性值 +1
// 这个更新count值也是影响能不能继续循环的关键
// 3、调用:callback.doInIteration(context),并将调用结果直接返回,
// 这说明实际的调用结果 仍然由传进来的RepeatCallback来决定
// 4、子类TaskExecutorRepeatTemplate重写了该方法
result = getNextResult(context, callback, state);
// 倒序遍历所有的RepeatListener,调用它们的 after(repeatContext, result)方法
executeAfterInterceptors(context, result);
}
catch (Throwable throwable) {
// 1、如果上述过程发生异常,则倒序调用 RepeatListener#onError(context, unwrappedThrowable)
// 2、再交给exceptionHandler.handleException(context, unwrappedThrowable)
// 【特别注意】:默认的DefaultExceptionHandler,他会直接将传入的异常,直接抛出,然后被捕捉到,放入到deferred中!!!
// 这会让下面的 !deferred.isEmpty() 判断为 true, 导致running为false,从而结束循环
// 3、如果在前2步处理异常的过程中发生了异常,那么放入deferred中,后续再抛出
doHandle(throwable, context, deferred);
}
// 1、isComplete(context, result) 交给completionPolicy.isComplete(context, result)
// 默认实现为 DefaultResultCompletionPolicy,
// 如果result是RepeatStatus.Continuable那就返回false,因为需要继续嘛
// 如果result是RepeatStatus.FINISHED那就返回true,因为不需要继续了
// 还有个实现 SimpleCompletionPolicy 它除了重用了父类DefaultResultCompletionPolicy的实现外,
// 还会根据 count的数量 和 chunkSize的数量比较
// 2、如果第1个判断返回false,才会走第2个判断,去检查RepeatContext的completeOnly标记完成标记;
// isMarkedComplete(context)
// 先检查当前RepeatContext#completeOnly这个标记是否为true,
// 如果为true,那就表示完成了,running就是false,下面的while(running)就不执行了,
// 如果为false,那就检查 父RepeatContext#completeOnly的标记,父标记为true,也算true
// 3、如果前2个判断都是false,那么进入第3个判断,
// deferred不为空,表示 上面的catch块在doHandle中在处理异常的过程中,发生了异常,
// 这种情况也会把running置为false
if (isComplete(context, result) || isMarkedComplete(context) || !deferred.isEmpty()) {
// running 为 false ,才能跳出这个while(running)循环
running = false;
}
// 如果没有满足上面if的条件,那么又得去执行一遍 result = getNextResult(context, callback, state)
}
}
// 1、waitForResults(state) - 默认返回true,不过,子类TaskExecutorRepeatTemplate重写了该方法
// 2、result.and(boolValue) - 如果boolValue是false的话,直接就是 FINISHED;
// 如果boolValue是true的话,result是什么就是什么
// 3、result不能为null,为null会抛出空指针异常哦!
result = result.and(waitForResults(state));
// 处理state中的throwable属性
for (Throwable throwable : throwables) {
// 1、倒序调用 RepeatListener#onError(context, unwrappedThrowable)
// 2、再交给exceptionHandler.handleException(context, unwrappedThrowable)
// 3、如果在前2步处理异常的过程中发生了异常,那么放入deferred中,后续再抛出
doHandle(throwable, context, deferred);
}
// 不保留状态了,help gc
state = null;
}
finally {
try {
// 将deferred中的第1个异常重新抛出
if (!deferred.isEmpty()) {
Throwable throwable = deferred.iterator().next();
rethrow(throwable);
}
}
finally {
try {
// 倒序调用RepeatListener的close(RepeatContext)方法
for (int i = listeners.length; i-- > 0;) {
RepeatListener interceptor = listeners[i];
interceptor.close(context);
}
}
finally {
// 关闭上下文
// 会调用RepeatContextSupport#callbacks属性中的所有Runnable#run方法,
// 其中,发生的异常,将会都记录下来,并将第一个异常抛出
context.close();
}
}
}
return result;
}
TaskExecutorRepeatTemplate
源码理解
spring batch在设置了多线程来实现批处理,它的整体逻辑是这样的:假设数据源有100条数据,每10条数据为1个批次。主线程首先有1个信号量在控制同一时刻,最多允许的并发任务数量,默认为4,也就是说主线程最多提交4个任务同时再跑,假设4个任务都在跑,并且都没有执行完,当主线程准备提交第5个任务时,就会因为获取不到信号量而阻塞。此时,当有任务执行完毕,就会将自己的结果放入1个队列里面,并且归还信号量,从而唤醒主线程,因为已经有1个任务执行完毕了,所以主线程可以继续提交第5个任务了,然后主线程发现队列不为空了,因为有任务将结果给到了队列里面,于是主线程就去处理这个结果,当然,这个结果有可能是告诉主线程接着继续走,也有可能是处理过程中发生异常了(超出容错机制允许的错误限制数),那么如果是继续走,那就继续提交任务,那么如果是发生异常了,那么主线程还得等其它正在执行的任务执行完毕,其它任务有可能成功也有可能也遇到错误,主线程并不关心,反正允许的并发任务量是已经设定号的,等到其它正在并发执行的任务都执行完了,主线程就会从队列中获取最开始失败的任务中年的这个异常,添加到defered中,然后将running改为false,这样主线程就不会再提交任务了,这个step也就执行失败了。
所以,在多线程环境下,其它并发的任务,不会受到失败的任务的影响,但会影响到后续批次任务的执行(后面未添加任务的批次压根就不执行了)
属性
-
int throttleLimit = 4 - 默认为4(最大并发数)
-
TaskExecutor taskExecutor = new SyncTaskExecutor() - 任务执行器(默认是同步的任务执行器,任务直接交给当前线程执行任务的run方法)
相关类
ResultQueueInternalState
-
ResultQueueInternalState继承自RepeatInternalStateSupport,因此状态内部维护了1个throwables的异常集合。
-
final ResultQueue<ResultHolder> results,状态内部还维护了1个队列,队列中放的是ResultHolder类型
- 这个
ResultQueue本质上是1个队列,实现了ResultQueue<ResultHolder>接口,该接口中定义了put/take/isEmpty/expect/isExpecting这些方法 - ResultQueue的实现为
ResultHolderResultQueue类型,内部用到了PriorityBlockingQueue优先队列和Semaphore信号量 - 队列中放的元素类型是
ResultHolder,这里的ResultHolder的实现为ExecutingRunnable
- 这个
ResultHolderResultQueue
属性
-
final BlockingQueue<ResultHolder> results
-
final Semaphore waits
-
final Object lock = new Object() - 用来保护这个count的
-
volatile int count = 0
ResultHolder
这是个接口
- RepeatStatus getResult();
- Throwable getError();
- RepeatContext getContext()
ExecutingRunnable
ExecutingRunnable是TaskExecutorTaskTemplate类中的成员内部类,它实现了 Runnable接口,ResultHolder接口
属性
final RepeatContext context;
final ResultQueue<ResultHolder> queue;
final RepeatCallback callback;
volatile RepeatStatus result;
volatile Throwable error;
方法
在熟悉完相关类后,再来看TaskExecutorRepeatTemplate类中的方法
RepeatInternalState createInternalState(RepeatContext context)
@Override
protected RepeatInternalState createInternalState(RepeatContext context) {
// 创建的实现为 ResultQueueInternalState,传的参数默认是 4
return new ResultQueueInternalState(throttleLimit);
}
RepeatStatus getNextResult(RepeatContext context, RepeatCallback callback, RepeatInternalState state)
@Override
protected RepeatStatus getNextResult(RepeatContext context,
RepeatCallback callback,
RepeatInternalState state) {
//
ExecutingRunnable runnable;
// 获取 ResultQueueInternalState状态 中的 ResultHolderResultQueue队列
ResultQueue<ResultHolder> queue = ((ResultQueueInternalState) state).getResultQueue();
do {
// 1、将 callback 包装为 ExecutingRunnable实例,
// 2、这个ExecutingRunnable实例 会在run方法完成后,会将包含callback的执行结果的ExecutingRunnable 放入到 queue中
runnable = new ExecutingRunnable(callback, context, queue);
// 1、实际上调用 queue.expect()方法
// 2、ResultHolderResultQueue#expect()的实现是
// 先去获取1个信号量对象的许可证(默认4个),
// 等到获取成功之后,拿到lock锁并在同步代码块中 count自增1
runnable.expect();
// 提交任务给线程池处理,runnable的的run方法将在其它线程中执行
taskExecutor.execute(runnable);
// 这说明 提交1个任务,就更新RepeatContextSupport#count
update(context);
// 1、在上面,我们注意到了,在ExecutionRunnable的run方法执行完后,会将ExecutionRunnable自身放入队列中, 这样队列就不会为空了,
// 同时, 这说明队列中拿到的元素,对应的callback#doIteration已经执行过了并且有了结果,
// 2、如果队列还为空,说明刚刚添加进来的任务尚未执行完毕,那么调用isComplete(context)方法看看是否已经完成,
// 如果已经完成,那么不在继续循环
// 如果尚未完成,那么继续循环
// 3、如果 ExecutionRunnable#run方法执行迟迟没有执行完毕,context也没达到完成的要求,
// 那么就会一直走循环,然后就会走 runnable.expect(),
// 从而就需要去拿队列中的信号量对象的许可证, 拿不到就得等待,从而限制一直往线程池中提交ExecutingRunnable任务
// 这样就限制了任务并发的数量,
// 在ExecutionRunnable#run方法执行完后,会将ExecutionRunnable作为this放入到队列中,
// 这样这里就能唤醒等待许可证的线程继续提交任务了。
} while (queue.isEmpty() && !isComplete(context));
// 如果跳出循环,说明 至少在判断的时候,队列不为空 或者 通过context判断出已经完成了。
// 但是,此处会有竞争的情况出现,
// 这里一定会拿到1个 ResultHolder(实际为ExecutingRunnable实例),因为刚刚提交了1个ExecutingRunnable任务
ResultHolder result = queue.take();
// 如果 ExecutingRunnable在执行 callback.doInIteration(context) 的过程中发生了任何异常,
// 则ExecutingRunnable#error属性将不为null, 这里直接将异常抛出
if (result.getError() != null) {
throw result.getError();
}
// 返回ExecutingRunnable#result属性(RepeatStatus类型,即RepeatCallback#doInIteration(RepeatContext)方法调用的返回值)
return result.getResult();
}
boolean waitForResults(RepeatInternalState state)
@Override
protected boolean waitForResults(RepeatInternalState state) {
// 获取状态中的 队列 属性(实际为 ResultHolderResultQueue 类型的队列)
ResultQueue<ResultHolder> queue = ((ResultQueueInternalState) state).getResultQueue();
// 结果为true
boolean result = true;
// 如果队列的count属性 > 0, 这说明 线程中还有任务没有完成
while (queue.isExpecting()) {
ResultHolder future;
try {
// 返回的是 ExecutingRunnable类型
future = queue.take();
}
catch (InterruptedException e) {
Thread.currentThread().interrupt();
throw new RepeatException("InterruptedException while waiting for result.");
}
if (future.getError() != null) {
// callback执行发生了异常
state.getThrowables().add(future.getError());
// 返回false
result = false;
}
else {
// 没有异常的处理
RepeatStatus status = future.getResult();
result = result && canContinue(status);
executeAfterInterceptors(future.getContext(), status);
}
}
// 此时 queue 队列应该是空的,因为 都已经拿完了
Assert.state(queue.isEmpty(), "Future results queue should be empty at end of batch.");
return result;
}
ChunkOrientedTasklet<I>
它是基于Chunk块的Tasklet的实现,将过程分为 读-处理-批量写 这3个步骤。
public class ChunkOrientedTasklet<I> implements Tasklet {
private static final String INPUTS_KEY = "INPUTS";
private final ChunkProcessor<I> chunkProcessor;
private final ChunkProvider<I> chunkProvider;
// 默认true
private boolean buffering = true;
private static Log logger = LogFactory.getLog(ChunkOrientedTasklet.class);
public ChunkOrientedTasklet(ChunkProvider<I> chunkProvider, ChunkProcessor<I> chunkProcessor) {
this.chunkProvider = chunkProvider;
this.chunkProcessor = chunkProcessor;
}
public void setBuffering(boolean buffering) {
this.buffering = buffering;
}
@Nullable
@Override
public RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {
Chunk<I> inputs = (Chunk<I>) chunkContext.getAttribute(INPUTS_KEY);
if (inputs == null) {
// 1、交给ChunkProvider#provide获取到读取的Chunk
// 实际上是交给ItemReader去读取数据
inputs = chunkProvider.provide(contribution);
if (buffering) { // 这个开关用于控制是否缓存到INPUTS属性中
chunkContext.setAttribute(INPUTS_KEY, inputs);
}
}
// 2、交给ChunkProcessor#process处理批量读取到的数据
// 实际上是交给ItemProcessor处理后,再交给ItemWriter写入
chunkProcessor.process(contribution, inputs);
// 留给子类扩展使用
chunkProvider.postProcess(contribution, inputs);
// 该属性用于 阻止移除 chunkContext中的 INPUTS 属性
if (inputs.isBusy()) {
logger.debug("Inputs still busy");
return RepeatStatus.CONTINUABLE;
}
// 移除 chunkContext中的 INPUTS 属性
chunkContext.removeAttribute(INPUTS_KEY);
// 标记 chunkContext#complete 为true,处理完毕
chunkContext.setComplete();
if (logger.isDebugEnabled()) {
logger.debug("Inputs not busy, ended: " + inputs.isEnd());
}
// chunk#end表示 是否已读完数据,如果未读完数据,表示还要继续;如果读完了数据,就返回完成了
return RepeatStatus.continueIf(!inputs.isEnd());
}
}
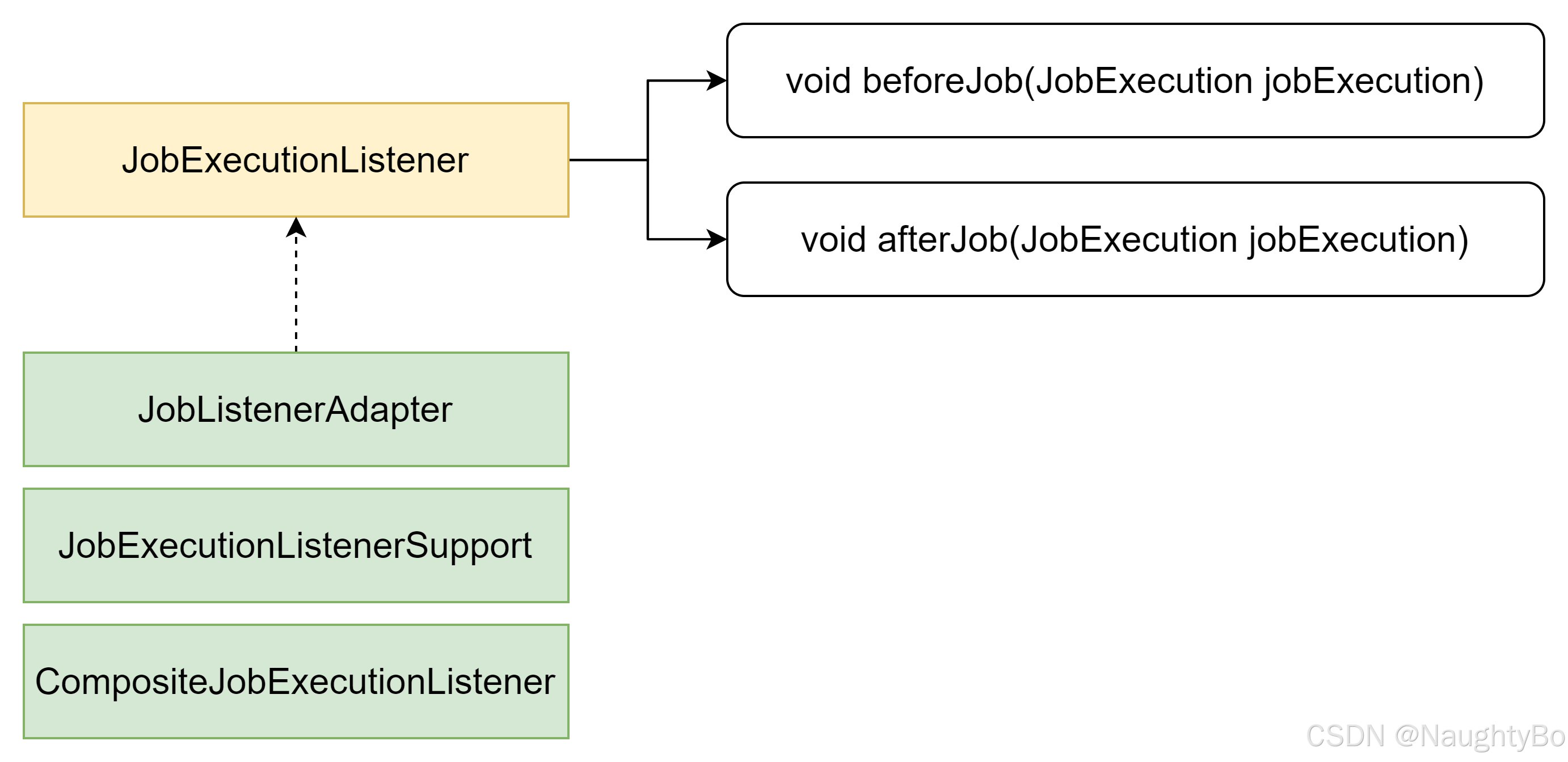
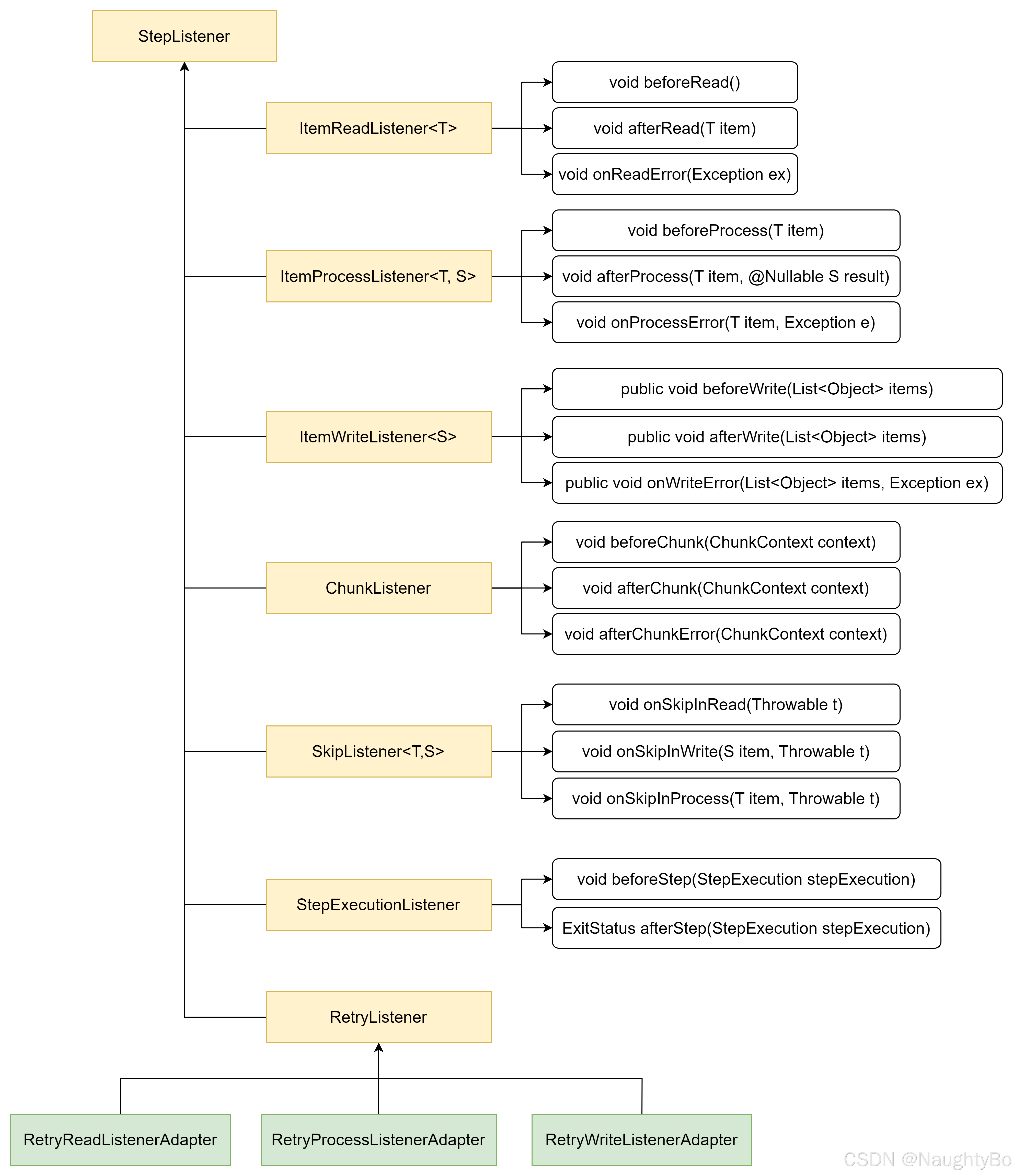
监听器种类
容错机制
【spring batch容错机制】
skipLimit 代表可以跳过的数据数量
- 假设skipLimit为1,并且报错只出现在processor中,61,62,63,64,65,其中62,64会报错,
则会61,然后62报错,然后又从61开始,此时跳过62,然后63,然后64报错,这个时候还检测不到错误。
又从61开始,跳过62,然后63,此时就检测到64要跳过,超过了要跳过的数量,此时会抛出异常
- 假设skipLimit为2,并且报错只出现在writer中,并且writer中第3次及以后只要写就会报错,
则1,2,3,4,5正常,6,7,8,9,10正常,此时:11,12,13,14,15,
此时到了第3次,第一次writer尝试写入11,12,13,14,15,此时报错,然后就会将这个chunk中的每1个item都会依次先交给Procesor处理,再交给writer去写入。
先处理11,再写入writer报错,然后处理12,写入报错,此时已经报了2次错了,写入报错,此时已经报了2次错了,相当于跳过2次了,然后处理13,写入又报错,此时已经相当于要跳过3次,这个step就失败了
- 假设skipLimit为1,并且报错只出现在reader中,并且读取出来的item为11时会报错,
则1,2,3、4,5正常,6,7,8,9,10正常,此时读到11,报错,由于skipLimit为1,所以跳过,直接读12,13,14,15,16 为1个批次。
- 假设skipLimit为1 ,并且报错只出现在reader中,并且读取出来的item为11,13时会报错,
则1,2,3,4,5正常,6,7,8,9、10正常,此时读到11,报错,由于skipLimit为1,所以跳过,直接读12,正常,然后读13报错;由于skipLimit为1,只能跳过1个,所以这个step就失败了
- 假设skipLimit为1 ,并且报错只出现在reader中,并且读取出来的item为11,13时会报错,
则1,2,3,4,5正常,6,7,8,9,10正常、此时读到11,报错,由于skipLimit为2,所以跳过,直接读12,正常,然后读13报错、由于skipLimit为2,又跳过1个。然后读到14,15,16,17,
所以这个批次就是 12,14,15,16,17
- 假设skipLimit为3,并且报错只出现在reader和processor中,开且reader中11,13会报错,processor中62,64会报错,
则11,12,13,14,15,中由于11和13会报错,但是skipLimit为3,所以允许这2个错误,所以12,14,15,16,17会组成1个批次,
然后读取到58,59,60,61,62为1个批次,处理58正常,处理59正常,处理60正常,处理61正常,处理62时报错
于是,又从58开始处理正常,处理59正常,处理60正常,处理61正常,62在这个批次中直接被跳过,此时已经跳过3次了,
下一批读取到63、64,65,66,67,处理63正常,处理64时报错,于是又从63开始处理正常,在处理64之前,发现前面已经跳过3次了,现在又要跳过64,已经超出能跳过的上限。因此抛出异常,step就失败了
- skipLimit 表示的是所有chunk处理中允许因异常而跳过的item的数量

















 1019
1019

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









