







1、Lambad表达式
我的理解匿名实现类的简写,也可以称为闭包
作用:
- 简化匿名实现类的书写
- 将函数作为方法中的参数来传递(匿名内部类)
例:
类型 变量 = (参数类型 param1, 参数类型 param2 ...)->{实现};
Runnable runnable = () -> System.out.println("创建Runnable");- 小括号()中的内容就是方法的参数列表,其中参数类型是可以省略的,当只有一个参数的时候也可以省略小括号
- 花括号 { } 中的内容就是方法体,当方法提只有一行代码的时候可以省略{},当方法体只有一行代码并且需要返回值时也可以省略return
- 由于Lambda表达式是匿名实现类的简写,是一种特殊的接口,当赋值给一个变量的时候“ ; ” 不能少
Lambda表达式只能引用标记了final的外层局部变量,这就是说不能在lambda内部修改定义在域外的局部变量,否则会编译错误。
可以直接在 lambda 表达式中访问外层的局部变量,lambda 表达式的局部变量可以不用声明为 final,但是必须不可被后面的代码修改(即隐性的具有 final 的语义)
在 Lambda 表达式当中不允许声明一个与局部变量同名的参数或者局部变量。
2、JDK内置函数
Consumer<T> 消费型接口(无返回值,有去无回)
void accept(T t);
Supplier<T> 供给型接口
T get();
Function<T,R> 函数型接口
R apply(T t);
Predicate<T> 断言型接口
boolean test(T t);3、详细
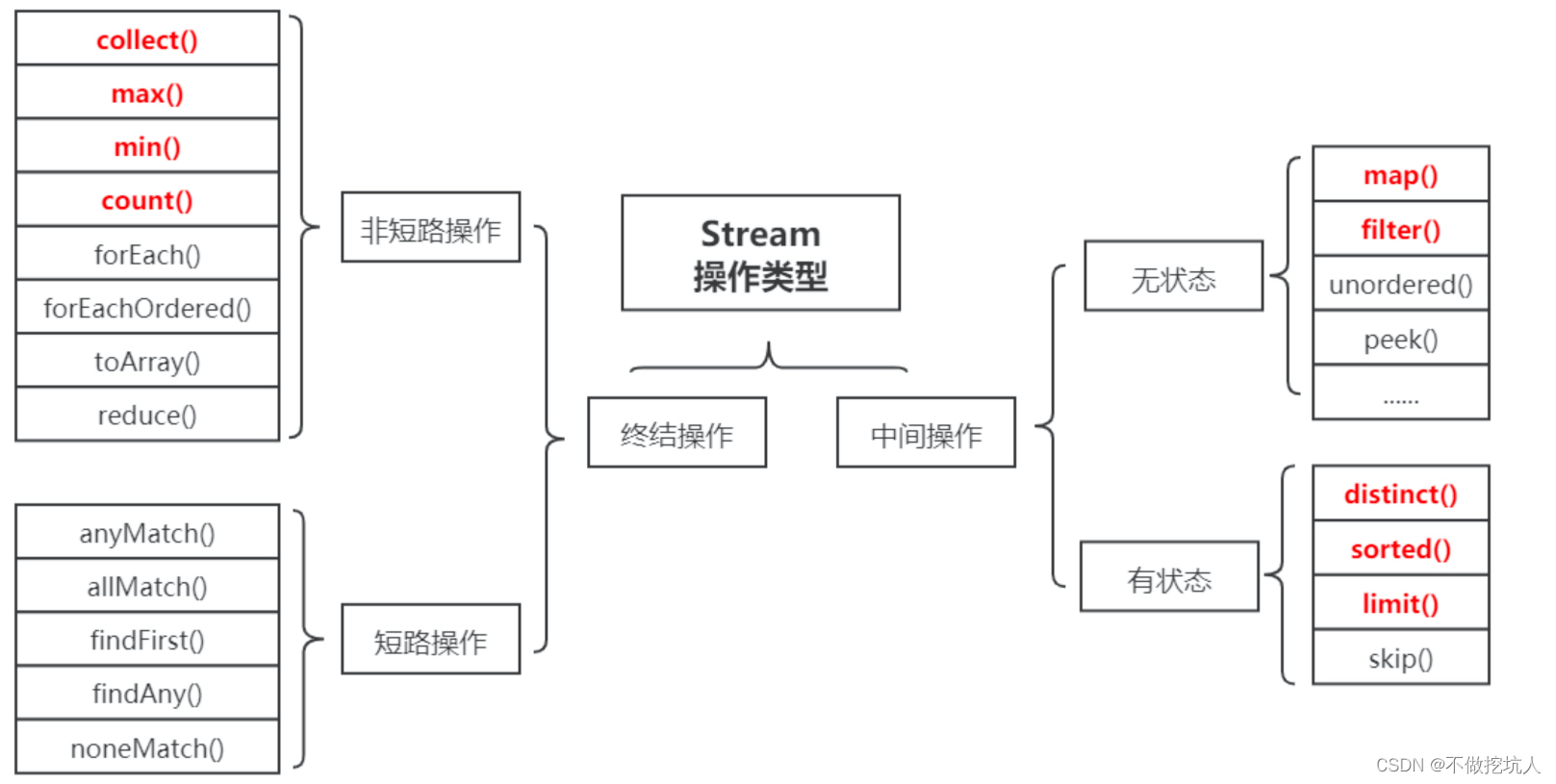
JDK8引入了函数式编程风格,通过流对集合和数组进行处理
主要用到两个类Stream类和Collectors类
Stream有如下三个操作步骤:
创建Stream:从一个数据源,如集合、数组中获取流。
- 中间操作:一个操作的中间链,对数据源的数据进行操作。即返回的是一个Stream
- 终止操作:一个终止操作,执行中间操作链,并产生结果。相反返回具体结果不再是流
要注意的是,对流的操作完成后需要进行关闭操作(或者用JAVA7的try-with-resources)。
中间操作:filter、limit、skip、distinct、map、flagMap、sorted、peek
终止操作:foreach、count、allMatch、anyMatch、noneMatch
- 中间操作是流水线中的数据进行加工的, 它是一个懒操作, 并不会马上执行, 需要等待有终止操作的时候才会执行.
- 终止操作是Stream的启动操作, 当有终止操作的时候, Stream才会真正的开始执行.
(1)终止操作
1、foreach(Consumer<? super T> action) 遍历
// 1、终止操作-foreach(Consumer<? super T> action) 遍历
// personList.forEach(person -> System.out.println(person.getName()));
// personList.forEach(person -> System.out.println(person));
// personList.stream().forEach(System.out::println);
// personList.forEach(System.out::println);
integerList.forEach(i -> {
if(i == 3){
return;
}
System.out.println(i);
});2、count:对Stream进行count操作
long count1 = personList.stream().count();
System.out.println(count1);
long count2 = personList.stream().filter(p -> ('F') == p.getSex()).count();
System.out.println(count2);3、allMatch:检查是否匹配所有元素
boolean b = personList.stream().allMatch(p -> p.getAge()>= 18);4、anyMatch:检查是否至少匹配一个元素
boolean b = personList.stream().anyMatch(p -> "赵八".equals(p.getName()));5、noneMatch:检查是否不匹配所有元素
boolean b = personList.stream().noneMatch(p -> "赵八123".equals(p.getName()));6、findFirst:返回第一个元素
Person person1 = personList.stream().findFirst().get();
Person person2 = personList.stream().findFirst().orElse(null);
// Optional 类的应用7、findAny:返回当前流中的任意元素
Person person1 = personList.stream().findAny().get();
Person person2 = personList.stream().findAny().orElse(null);
// Optional 类的应用8、max:返回流中最大值
Comparator<Integer> comparator = (o1, o2) -> {
if (o1.intValue() == o2.intValue()) {
return 0;
}
if (o1 > o2) {
return 1;
}
return -1;
};
//Integer integer = integerList.stream().max(comparator).get();
Integer integer = integerList.stream().max(Integer::compareTo).get();
System.out.println(integer);
Comparator<Person> comparator1 = (person1, person2) -> {
if (person1.getAge().intValue() == person2.getAge()) {
return 0;
}
if (person1.getAge() > person2.getAge()) {
return 1;
}
return -1;
};
Person person1 = personList.stream().max(comparator1).get();
System.out.println(person1);
// Person类实现compareTo方法
Person person2 = personList.stream().max(Person::compareTo).get();
System.out.println(person2);
// Optional 类的应用9、min:返回流中最小值
Integer min = integerList.stream().min(Integer::compare).get();10、reduce:减少,缩小
- 根据指定的计算模型将Stream中的值计算得到一个最终结果
// BinaryOperator<T> extends BiFunction<T,T,T>
// R apply(T t, U u);
// 1、Optional<T> reduce(BinaryOperator<T> accumulator);
// 对Stream中的数据通过累加器accumulator迭代计算,最终得到一个Optional对象
BinaryOperator<Integer> binaryOperator = (a, b) ->{
a += b;
return a;
};
Integer result = integerList.stream().reduce(binaryOperator).get();
System.out.println(result);
// 2、T reduce(T identity, BinaryOperator<T> accumulator);
// 初始值identity,通过累加器accumulator迭代计算Stream中的数据,得到一个跟Stream中数据相同类型的最终结果
Integer reduce = integerList.stream().reduce(100, binaryOperator);
System.out.println(reduce);
// 3、<U> U reduce(U identity, BiFunction<U, ? super T, U> accumulator, BinaryOperator<U> combiner);
// BiFunction的三个泛型类型分别是
// U
// ? super T
// U
// 参考BiFunction函数式接口 R apply(T t, U u);
// 方法定义可以知道,累加器累加器通过类型为 U 和 ? super T 的两个输入值计算得到一个U类型的结果返回。
// 也就是说这种reduce方法,提供一个不同于Stream中数据类型的初始值,通过累加器规则迭代计算Stream中的数据,最终得到一个同初始值同类型的结果
// reduce的第三个参数是在使用parallelStream的reduce操作时,合并各个流结果的
// 由于所有使用并行流 parallelStream 的地方都是使用同一个 Fork-Join 线程池,而线程池线程数仅为 cpu 的核心数。
// 切记,如果对底层不太熟悉的话请不要乱用并行流 parallelStream(尤其是你的服务器核心数比较少的情况下)
List<Integer> integers = new ArrayList<>();
integers.add(100);
Integer reduce1 = integerList.parallelStream().reduce(0, (a, b) -> {
a += b;
return a;
}, (a, b) -> {
a += b;
return a;
});
System.out.println(reduce1);
// Optional 类的应用11、collect -- Collectors.toList()、Collectors.toSet()、Collectors.toMap、Collectors.groupingBy
collect 收集 将流转换为其他形式,接收一个Collectors接口实现 ,用于给Stream中汇总的方法
// 1、toList
List<Person> collect1 = personList.stream().collect(Collectors.toList());
// 2、toSet
Set<Person> collect2 = personList.stream().collect(Collectors.toSet());
// 3、toMap
// 3.1
// Map<String, Person> collect3 = personList.stream().collect(Collectors.toMap(Person::getName, Function.identity()));
// 假如key存在重复值,则会报错Duplicate key xxx, 解决方案是
// 只取后一个key及value:
Map<String, Person> collect31 = personList.stream().collect(Collectors.toMap(Person::getName, Function.identity(), (oldValue,newValue) -> newValue));
// 只取前一个key及value:
Map<String, Person> collect32 = personList.stream().collect(Collectors.toMap(Person::getName, Function.identity(), (oldValue,newValue) -> oldValue));
// 假如存在key重复,两个value可以这样映射到同一个key
Map<String, String> map = personList.stream().collect(Collectors.toMap(Person::getName,Person::getCountry,(e1,e2)->e1+","+e2));
// 3.2取对象的属性作为k-v
//Map<String, Integer> collect33 = personList.stream().collect(Collectors.toMap(Person::getName, Person::getAge));
// 防止name重复
Map<String, Integer> collect34 = personList.stream().collect(Collectors.toMap(Person::getName, Person::getAge,(oldValue,newValue)-> newValue));
// 注意:value可以为空字符串但不能为null,否则会报空指针,解决方案:
Map<String, Integer> collect35 = personList.stream().collect(Collectors.toMap(Person::getName, p-> p.getAge() == null ? 0 : p.getAge(),(oldValue, newValue)-> newValue));
// 4、Collectors.groupBy 聚合 -> map(k,List)
Map<String, List<Person>> collect4 = personList.stream().collect(Collectors.groupingBy(Person::getName));
// 5、Collectors.groupBy 聚合统计 -> map(k,count)
Map<String, Long> collect5 = personList.stream().collect(Collectors.groupingBy(Person::getName, Collectors.counting()));
Map<String, Long> collect6 = stringList.stream().collect(Collectors.groupingBy(Function.identity(), Collectors.counting()));
//把List1和List2中id重复的Student对象的name取从list1中出来:
List<Student> list1 = studentList;
List<Student> list2 = Arrays.asList(new Student(1L,"张飞"),new Student(102L,"赵子龙"));
Map<Long, Student> map2 = list2.stream().collect(Collectors.toMap(Student::getId,Function.identity()));
System.out.println(map2);
List<String> list3 = list1.stream()
.map(Student::getId)// Long
.filter(map2::containsKey) //Long
.map(map2::get) // Student
.map(Student::getName)
.collect(Collectors.toList());
System.out.println(list3);// 输出 [张飞]12、Collectors.joining 将数组以指定分隔符组成字符串
String output1 = String.join(",", stringList);
System.out.println(output1);
String output2 = stringList.stream().collect(Collectors.joining(","));
System.out.println(output2);
String[] arr = {"a","b","c"};
String collect = Arrays.stream(arr).collect(Collectors.joining(",", "{", "}"));
System.out.println(collect);
String collect2 = integerList.stream().map(i -> String.valueOf(i * i)).collect(Collectors.joining(","));
System.out.println(collect2);13、mapToInt 转 IntStream 求和
int sumAge = personList.stream().mapToInt(Person::getAge).sum();
System.out.println(sumAge);
IntStream intStream = personList.stream().mapToInt(Person::getAge);
IntSummaryStatistics stats = intStream.summaryStatistics();
System.out.println("age中最大的数 : " + stats.getMax());
System.out.println("age中最小的数 : " + stats.getMin());
System.out.println("age所有数之和 : " + stats.getSum());
System.out.println("age平均数 : " + stats.getAverage());
//BigDecimal decimal = leaderData.stream()
// .map(DailyCollectionRateResponse::getTotalPaidAmount)
// .filter(Objects::nonNull)
// .reduce(BigDecimal::add)
// .orElse(BigDecimal.ZERO);(2)中间操作
1、flter(Predicate<? super T> predicate) 过滤,只要括号内条件的
personList.stream().filter(p -> ('M')==p.getSex()).forEach(System.out::println);2、limit:截断流,使其元素不超过给定对象, 只要前n个
personList.stream().limit(4).forEach(System.out::println);3、skip(n):跳过元素,返回一个扔掉了前n个元素的流,若流中元素不足n个,则返回一个空流,与limit(n)互补
personList.stream().skip(4).forEach(System.out::println);4、distinct:去重
- Stream.distinct()基本类型和String默认是通过流所生成元素的hashCode()和equals()去重
- Stream.distinct() with List of Objects, 去重的的是实例对象
// 1、Integer去重
List<Integer> integers = Arrays.asList(1, 2, 3, 3, 5, 5, 6, 6, 7, 8);
List<Integer> collect1 = integers.stream().distinct().collect(Collectors.toList());
System.out.println(collect1);
// 2、 String去重
List<String> collect2 = stringList.stream().distinct().collect(Collectors.toList());
System.out.println(collect2);
// 3、 Stream.distinct() with List of Objects, 去重的的是实例对象,
// 3.1 全字段去重需要重写equals()和hashCode(),distinct不提供按照属性对对象列表进行去重的直接实现。它是基于hashCode()和equals()工作的。
System.out.println(personList.size());
personList.stream().distinct().forEach(System.out::println);
long count1 = personList.stream().distinct().count();
System.out.println(count1);
// 3.2 部分字段去重
// 如果我们想要按照对象的部分属性去重,我们可以通过其它方法来实现。如下三种代码段所示:
// 3.2.1 filter单属性去重, 原理是用来map
personList.stream().filter(distinctByKey(Person::getName)).forEach(System.out::println);
personList.stream().filter(new Predicate<>() {
final Map<Object, Boolean> seen = new ConcurrentHashMap<>();
@Override
public boolean test(Person t) {
return seen.putIfAbsent(t.getName(), Boolean.TRUE) == null;
}
}).forEach(System.out::println);
personList.stream().collect(Collectors.collectingAndThen(Collectors.toCollection(() -> new TreeSet<>(Comparator.comparing(Person::getName))), ArrayList::new)).forEach(System.out::println);
// 3.2.2多属性去重
personList.stream().collect(Collectors.collectingAndThen(Collectors.toCollection(() -> new TreeSet<>(Comparator.comparing(Person::getName))), ArrayList::new)).forEach(System.out::println);
personList.stream().collect(Collectors.collectingAndThen(Collectors.toCollection(() -> new TreeSet<>(Comparator.comparing(f -> f.getName() + f.getAge()))), ArrayList::new)).forEach(System.out::println);
public static <T> Predicate<T> distinctByKey(Function<? super T, ?> keyExtractor) {
Map<Object, Boolean> seen = new ConcurrentHashMap<>();
return t -> seen.putIfAbsent(keyExtractor.apply(t), Boolean.TRUE) == null;
}5、map: 可以把对象转为其他对象,为每个输入值生成一个输出值
操作采用一个方法,该方法针对输入流中的每个值调用,并生成一个结果值,该结果值返回至stream
List<String> nameList = personList.stream().map(Person::getName).collect(Collectors.toList());
List<Person> collect = personList.stream().map(person -> new Person(person.getName(), person.getAge())).collect(Collectors.toList());
List<Pair> collect = personList.stream().map(p -> new Pair(p.getName(), p.getAge())).collect(Collectors.toList());6、flagMap: 将Map中values中所有的List<AClass>组合成一个List<AClass> 合并流
List<Integer> numbers1 = Arrays.asList(1, 2, 3);
List<Integer> numbers2 = Arrays.asList(3, 4);
// 1、flatMap升维度,笛卡尔积
List<int[]> pairs = numbers1.stream().flatMap(x -> numbers2.stream().map(y -> new int[] { x, y })).collect(Collectors.toList());
for (int[] pair : pairs) {
System.out.println(Arrays.toString(pair));
}
// 2、一维度合并
List<String> fun1 = Arrays.asList("one", "two", "three");
List<String> fun2 = Arrays.asList("four", "five", "six");
Stream.of(fun1,fun2).flatMap(List::stream).forEach(System.out::println);7、sorted()排序,默认是按照升序
sorted()--自然升序排序(Comparable), 如何降序 reviersed
// 1、升序
integerList.stream().sorted().forEach(System.out::println);
// 2、降序, 需要自定义comparator
integerList.stream().sorted(Comparator.comparing(Integer::intValue).reversed()).forEach(System.out::println);
// 2、sorted(Comparator com)--定制排序(Comparator)
personList.stream().sorted(Comparator.comparing(Person::getAge)).forEach(System.out::println);
personList.stream().sorted(Comparator.comparing(Person::getAge).reversed()).forEach(System.out::println);
// 先根据age排, 再根据name排
personList.stream().sorted(Comparator.comparing(Person::getAge).thenComparing(Person::getName)).forEach(System.out::println);
personList.stream().sorted(Comparator.comparing(Person::getAge).reversed().thenComparing(Person::getName).reversed()).forEach(System.out::println);8、peek :只打印,不干预
peek的设计初衷就是在流的每个元素恢复运行之前的时候插入一个执行操作. 它不想forEach那样恢复整个流的运行操作. 而是在一个元素上完成操作之后, 它只会将操作顺承到流水线的下一个操作. 它能够将中间变量的值输出到日志. 有效的帮助我们了解流水线的每一步操作的输出值.
List<Integer> list1 = Arrays.asList(4, 7, 9, 11, 12);
list1.stream()
.map(x -> x + 2) // 各项+2
.filter(x -> x % 2 != 0)// 取模不为0的
.limit(2) // 只取前两个
.forEach(System.out::println);
//可以很明显的看出, 一旦调用了forEach操作, 整个流就会恢复运行.并不能很好的帮助我们了解Stream流水线中的每个操作(如:map,filter,limit等)产生的输出.
List<Integer> list2 = Arrays.asList(4, 7, 9, 11, 12);
list2.stream()
.peek(x -> System.out.println("stream: " + x))
.map(x -> x + 2)
.peek(x -> System.out.println("map: " + x))
.filter(x -> x % 2 != 0)
.peek(x -> System.out.println("filter: " + x))
.limit(2)
.peek(x -> System.out.println("limit: " + x))
.collect(Collectors.toList());peek和map的区别
- 使用peek操作流,流中的元素没有改变
- 使用map操作流,流中的元素有改变
注意:peek对一个对象进行操作的时候,对象不变,但是可以改变对象里面的值.如下:
Stream.of(new Person("001",15),new Person("002",16))
.peek(p -> p.setSex('0'))
.forEach(System.out::println);peek方法接收一个Consumer的入参. 了解λ表达式的应该明白 Consumer的实现类应该只有一个方法,该方法返回类型为void. 它只是对Stream中的元素进行某些操作,但是操作之后的数据并不返回到Stream中,所以Stream中的元素还是原来的元素.
map的定义
<R> Stream<R> map(Function<? super T, ? extends R> mapper);
map方法接收一个Function作为入参. Function是有返回值的, 这就表示map对Stream中的元素的操作结果都会返回到Stream中去.














 302
302











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









