







1、hadoop简单介绍
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。
Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。
2、hadoop版本说明
hadoop现在分两个版本1.0和2.0(17年1月推出了3.0版本 在这先不介绍)
1.0版本,hadoop有两个核心模块:HDFS+MapReduce
2.0版本,hadoop有三个核心模块:HDFS+Yarn+MapReduce
yarn 是资源协调管理框架。
1.0时hadoop只有一种计算框架。在2.0之后推出yarn后,既可以运行mr,也可以运行Spark,storm等其他框架。
3、Hadoop安装
模式:
1、单机模式,不能使用HDFS,只能使用MR,一般用于测试MR代码
2、伪分布模式,也就是用一台机器,用多个进程模拟多台机器。HDFS和MR都能使用
3、完全分布模式,用多个机器或多个虚拟机来搭建(之后有一节专门来说)
实现步骤:
1、准备一台虚拟机,要求工作内存最低1G,否则有可能出现错误。
2、关闭防火墙(注意,这只是自己用的时候为了简单,在工作中是不能关闭的 只要打开hadoop所需要的几个端口就可,50070、90000、50020等端口。
3、配置主机名hostsname、配置hosts文件,为了之后使用方便
4、配置免密钥登陆,方便之后的登陆跨服务器传文件登陆用
5、安装配置jdk,因为hadoop就是java开发的需要jdk环境
6、最后安装配置hadoop
安装步骤:
1、关闭防火墙:service iptables off 这个指令关闭防火墙之后,重启后防火墙还会开启,执行chkconfig iptables off这个命令之后重启也不会开启了(这个只是自己的虚拟机下使用,生产线上是不能的,当然这些都不是我这个小兵所关心的)。
2、配置hostsname等:
vim /etc/sysconfig/network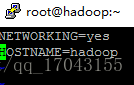
配置hosts 内容 vim /etc/hosts 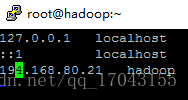
3、配置免密钥登陆:
执行 ssh-keygen 一直回车 ,生成节点的公钥和私钥,生成的文件会放在/root/.ssh的目录下。
然后把公钥发往远程机器,比如发往本机,本机免密钥登陆:ssh-copy-id root@hadoop,此时,hadoop节点就是把收到的hadoop密钥保存在/root/.ssh/authorized_keys这个文件里,这个文件相当于访问的白名单,凡是在此白名单存储的密钥对应的机器,登陆时是免密码登陆的。两个机器分别进行一次则两方登陆时都是免密码的,之后做真分布式hadoop时要进行多个免密钥登陆的。
4、安装配置jdk
在这里就不写了。
5、安装配置hadoop
在这我是用的hadoop安装包进行的安装的。
我的安装包是hadoop-2.7.1的,我会上传的。
执行 tar -zxvf hadoop-2.7.1_64bit.tar.gz,之后解压生成相应的文件。其中由多个目录:
bin目录:命令脚本
etc/hadoop:存放hadoop的配置文件(之后修改配置文件,将在这里进行)
lib目录:hadoop运行的依赖jar包
sbin目录:启动和关闭hadoop命令都在这里
libexec目录:存放的也是hadoop命令,但是一般不适用。
修改配置文件 切换到 etc/hadoop里面修改。
配置hadoop-env.sh
这个文件里写的是hadoop的环境变量,主要修改hadoop的java_home路径。在这里面主要修改export java_home 写成自己jdk的安装目录,export hadoop_conf_dir 写成hadoop的安装目录
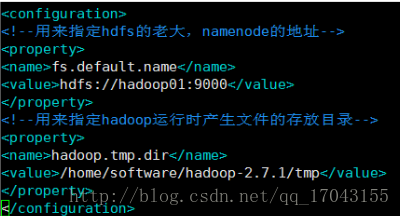
配置core-site.xml
配置如下:
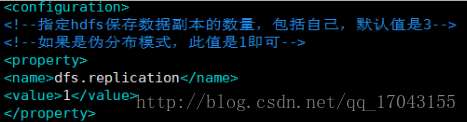
配置hdfs-site.xml
如下:
修改配置mapred-site.xml
这个文件初始时是没有的,有的是模板文件mapred-site.xml.temple 复制这个文件命名为mapred-site.xml 修改就可以了。配置如下: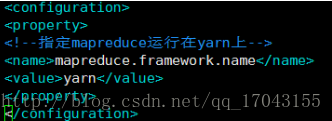
yarn是资源协调工具。
修改yarn-site.xml
配置如下: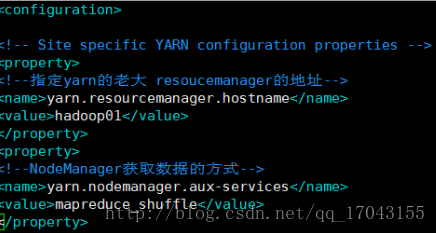
配置slaves文件
(这个文件也是在etc/hadoop里面。
配置hadoop的环境变量 vim /etc/profile 主要是环境变量如图: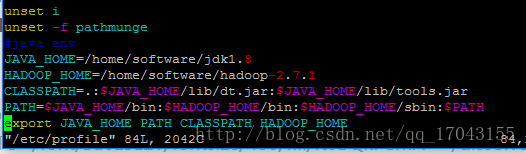
JAVA_HOME=/home/software/jdk1.8
HADOOP_HOME=/home/software/hadoop-2.7.1
CLASSPATH=.:
JAVAHOME/lib/dt.jar:
JAVA_HOME/lib/tools.jar
PATH=
JAVAHOME/bin:
HADOOP_HOME/bin:
HADOOPHOME/sbin:
PATH
export JAVA_HOME PATH CLASSPATH HADOOP_HOME
完成这些配置之后要格式化namenode
出现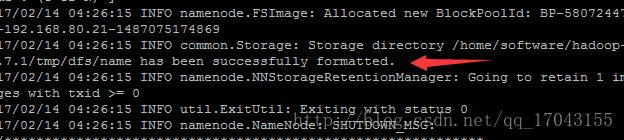
启动hadoop 直接 输入start-all.sh就可以启动所有的服务,也可以单个的启动相应的服务。
启动完后 数据jps检查启动情况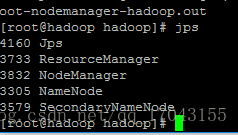
Hadoop常用指令:
1.执行:hadoop fs -mkdir /test 在hdfs的根目录下,创建park目录
2.执行:hadoop fs -ls / 查看hdfs根目录下有哪些目录
3.hadoop fs -put /home/1.txt /test 将linux系统home 目录下的1.txt文档放到hdfs的test目录下
4.hadoop fs -get /test/1.txt /home 把hdfs文件系统下test目录的文档下载到/home目录下
5.hadoop fs -rm /test/文件名 删除test目录下的指定文件
6.hadoop fs -rmdir /test 删除test目录,但是前提目录是没有文件的
7.hadoop fs -rmr /test 删除test目录,无论有无文件都删除
8.hadoop fs -cat /test/1.txt 查看test目录下1.txt文件
9.hadoop fs -tail /test/1.txt 查看test目录下1.txt文件末尾的数据
10.hadoop jar xxx.jar 执行jar包
11.hadoop fs -mv /test /test1 将hdfs上的test目录重名为test1
12.hadoop fs -mv /test/1.txt /test1 将1.txt转移到test1目录下
13.hadoop fs -touch /test/2.txt 创建一个2.txt空文件
14.hadoop fs -getmerge /test /root 将test目录下的所有文件合并成一个文件,并下载到linux 的/root目录下
15.hadoop dfsadmin -safemode leave 离开安全模式
16.hadoop dfsadmin -safemode enter 进入安全模式
17.hadoop dfsadmin -rollEdits 手动执行fsimage 文件和Edis文件合并元数据
18.hadoop dfsadmin -report 查看存活的datanode节点
19.hadoop fsck /test 汇报/test目录健康状况
20.hadoop fsck /test/1.txt -files -blocks -locations -racks 查看1.txt这个文件block信息以及机架信息,元数据信息,包括:文件名,文件大小,文件块数量,文件块编号,文件存储的Datanode信息。
21.hadoop fs -du /test/1.txt 查看hdfs上某个文件的大小,也可以查看制定目录
22.hadoop fs -copyFormLocal /test/1.txt /home 将文件拷贝到本地文件系统
23.hadoop fs -lsr / 递归查看指定目录下的所有文件

















 5733
5733

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









