







前言:AI开源社区的变革者
在人工智能技术飞速发展的今天,开源社区已成为推动技术民主化的核心力量。Hugging Face作为这一领域的标杆,不仅重塑了自然语言处理(NLP)的开发范式,更通过开放的模型库和工具生态,让全球开发者能够“站在巨人肩膀上”创新。
截至2025年,Hugging Face平台已托管超过50万个预训练模型和10万个数据集,覆盖文本、图像、音频等多模态领域,成为AI开发者不可或缺的资源库。

一、关于Hugging Face
1.1 简介
Hugging Face(抱脸网)是一个知名的开源库和平台,该平台以其强大的Transformer模型库和易用的API而闻名,为开发者和研究人员提供了丰富的预训练模型、工具和资源。
Hugging Face成立于2016年,总部位于美国纽约市,并在加拿大蒙特利尔、巴黎和旧金山等地设有办事处。最初以聊天机器人业务起家,后因开源工具库Transformers的爆火转型为AI基础设施提供商。
其核心产品包括:
- Transformers库:支持BERT、GPT等模型的统一接口,兼容PyTorch、TensorFlow等框架,实现“3行代码调用SOTA模型”。
- Hugging Face Hub:全球最大的模型共享平台,支持模型、数据集和应用的托管与协作。
- Spaces:一键部署AI应用的开发环境,支持Gradio、Streamlit等交互工具。
- Datasets & Tokenizers:高效处理数据预处理与分词,支持零拷贝读取大规模数据集。
1.2 发展
2016-2018:初创期的探索与转型
- 2016年:Hugging Face推出首款聊天机器人,但因技术局限未达预期;
- 2017年:团队转向NLP基础研究,开始整合Transformer模型;
- 2018年:发布Transformers库1.0,支持BERT等早期预训练模型。
2016年,法国创业者三名创业者Clément Delangue、Julien Chaumond 和 Thomas Wolf 在纽约成立了Hugging Face。

Hugging Face的联合创始人兼CEO克莱门特·德朗格 (Clément Delangue)

现在的Hugging Face部分团队成员
Hugging Face,它的第一个产品是一个聊天机器人。到2017年,Hugging Face聊天机器人拥有了独特的功能,并可以进行高效的对话。团队将其产品定位为为无聊青少年量身打造的个性鲜明的聊天机器人。2018年5月,完成种子融资。通过本轮融资,Hugging Face团队继续专注于以下领域:改进产品;建立一支优秀的工程师团队;深入研发自然语言对话,并撰写了几篇研究论文。虽然当时产品还没有带来可观的收入,但团队对核心价值和技术共享的强调为Hugging Face创造了一个转折点。
2018 年,Hugging Face迎来了关键时刻,Hugging Face的创始人在网上免费分享该应用的部分代码,其中一个重要的开源框架名为Transformers,目前已被下载超过一百万次。GitHub项目获得了上万颗星,这表明开源社区认为它很有价值。微软、谷歌和 Facebook 的研究人员一直在用它做实验,某些公司甚至在生产中使用了它。
Transformers 可用于各种任务,包括文本分类、信息提取、总结、文本生成和对话式人工智能。最终,Hugging Face团队迎来了一个转折点,将公司从一家不太赚钱的AI聊天机器人初创公司转变为未来估值十亿美元的独角兽。
在接下来的几年里,Hugging Face 团队继续专注于产品建设和社区发展,并取得了令人瞩目的成就:
- Hugging Face 已成为扩展最快的社区和使用最广泛的机器学习平台!平台上有 10 万个预训练模型和 1 万个数据集,涵盖 NLP、语音、时间序列、强化学习、计算机视觉、生物、化学等领域。Hugging Face Hub 已发展成为机器学习构建者开发、协作和部署尖端模型的家园。
- 目前有10000 多家公司使用 Hugging Face来构建机器学习技术,Hugging Face 帮助这些机器学习工程师和数据科学家团队节省了大量时间,加快了机器学习项目的进度。
- Hugging Face还领导着 BigScience,一个专注于研究和构建大语言模型的合作研讨会。这项计划汇集了来自不同领域和背景的1000多名研究人员,BigScience 致力于训练世界上最大的开源多语言模型。
2019-2021:技术爆发与生态构建
-
2019年:
- 推出DistilBERT——首个轻量化BERT变体,计算效率提升40%;
- 开源Hugging Face Hub,建立模型共享社区;
-
2020年:
- 支持PyTorch和TensorFlow双框架,兼容性大幅提升;
- 发布AutoModel系列,实现模型自动适配任务;
-
2021年:
- 完成2.1亿美元C轮融资,估值达28亿美元;
- 推出Hugging Face Spaces,降低模型部署门槛。
2022年至今:商业化与全球化扩张
-
2022年:
- 推出企业级产品Hugging Face Enterprise,提供私有化部署和合规解决方案;
- 收购AI伦理公司Aletheia,强化模型可解释性研究;
-
2023年:
- 发布Llama系列模型(开源大语言模型),挑战闭源巨头如GPT-4;
- 与联合国教科文组织合作,推动多语言AI教育项目。
1.4 特点
开源生态:降低技术门槛
- 模型库的多样性:覆盖文本生成、分类、翻译、多模态等任务,支持从微调到推理的全流程;
- 社区驱动创新:用户贡献的模型占比超过30%,形成“众包式”技术迭代;
- 文档与教程:提供从入门到进阶的教程,如“5分钟快速入门”和“从零到一构建问答系统”。
技术优势:性能与效率的平衡
- 轻量化与高效推理:
通过知识蒸馏(如DistilBERT)、量化压缩等技术,模型体积可缩小至原模型的1/10,推理速度提升5倍以上; - 多任务适配性:
通过Adapter技术,仅需微调少量参数即可适配新任务,降低计算资源消耗; - 多语言支持:
提供超过100种语言的预训练模型,包括低资源语言(如斯瓦希里语、越南语)。
用户体验:从代码到应用的无缝衔接
-
代码简洁性:
示例代码通常仅需几行即可完成模型加载与推理,如:from transformers import pipeline classifier = pipeline("text-classification", model="bert-base-uncased") result = classifier("Hugging Face is amazing!") print(result) # 输出情感分析结果 -
低代码部署:
Spaces平台允许开发者通过拖拽界面构建Web应用,无需编写后端代码; -
可视化工具:
提供Hugging Face Dashboard,实时监控模型训练过程和性能指标。
伦理与可解释性
- 公平性测试:
提供工具检测模型中的偏见,例如性别、种族或政治倾向的偏差; - 可解释性模块:
集成SHAP、LIME等工具,帮助用户理解模型决策逻辑; - 隐私保护:
支持联邦学习和同态加密技术,确保数据隐私不泄露。
1.5 应用场景
自然语言处理
自然语言处理是Hugging Face最核心的应用领域之一。在文本分类、情感分析、命名实体识别、机器翻译、问答系统、文本生成等任务中,Hugging Face的预训练模型都展现出了卓越的性能。例如,使用BERT模型可以对新闻文章进行分类,判断其所属的类别;利用GPT模型可以生成高质量的文本内容,如新闻报道、故事创作等。
计算机视觉
在计算机视觉领域,Hugging Face的模型也被广泛应用于图像分类、目标检测、图像分割、图像生成等任务。例如,Vision Transformer(ViT)模型在图像分类任务中取得了优异的成绩,能够准确地识别图像中的物体类别。同时,Hugging Face还支持一些用于目标检测和图像分割的模型,如Detr、MaskFormer等,为开发者在计算机视觉领域的应用开发提供了丰富的选择。
语音处理
对于语音处理任务,如语音识别、语音合成、语音情感分析等,Hugging Face也提供了相应的模型和工具。例如,Wav2Vec2模型在语音识别任务中表现出色,能够将语音信号准确地转换为文字。这在智能语音助手、语音翻译等应用中具有重要的价值。
生物学与医学
在生物学和医学领域,Hugging Face的模型也被用于生物序列分析、药物发现、医学影像分析等任务。例如,使用Transformer模型对DNA序列进行分析,可以帮助研究人员更好地理解基因的功能和疾病的发生机制。此外,Hugging Face还与一些医疗机构合作,开发用于医学影像诊断的AI模型,辅助医生进行疾病的诊断和治疗。
金融与商业智能
金融机构和企业可以利用Hugging Face的模型进行风险评估、客户情感分析、市场趋势预测等。例如,通过对客户评论和社交媒体数据的情感分析,企业可以了解客户对其产品或服务的满意度,从而制定相应的营销策略。同时,Hugging Face的模型还可以用于金融市场的预测和风险控制,帮助金融机构做出更加科学的决策。
教育与研究
在教育领域,Hugging Face的工具和资源可以用于开发智能教育系统,如自动批改作业、智能辅导、个性化学习推荐等。研究人员也可以利用Hugging Face的平台进行各种人工智能相关的研究工作,加速研究成果的转化和应用。
二、Huggingface具体介绍
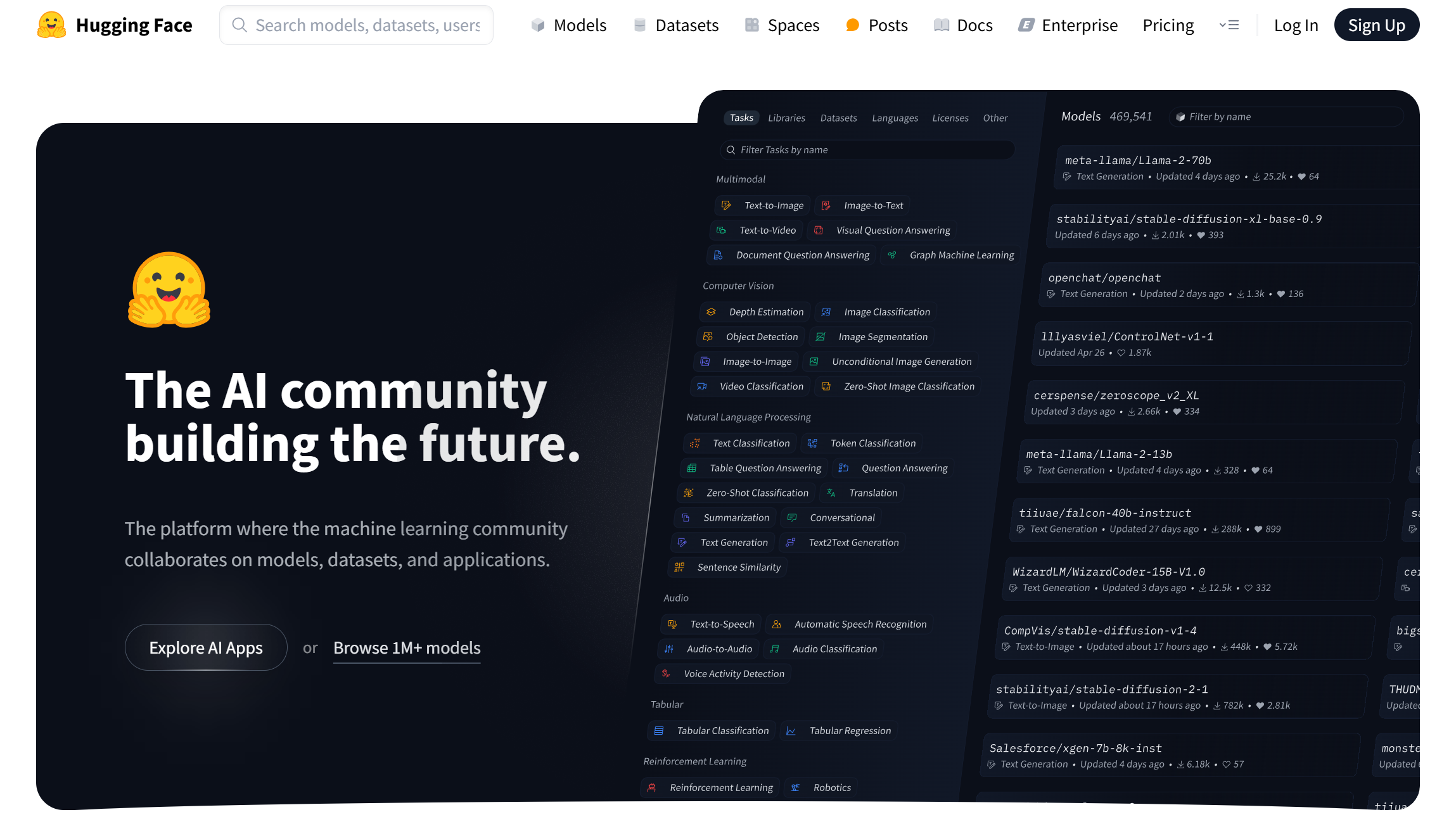
进入Huggingface网站,,如下图所示

其主要包含:
Models(模型),包括各种处理CV和NLP等任务的模型,上面模型都是可以免费获得
Datasets(数据集),包括很多数据集
Spaces(分享空间),包括社区空间下最新的一些有意思的分享,可以理解为huggingface朋友圈
Docs(文档,各种模型算法文档),包括各种模型算法等说明使用文档
Solutions(解决方案,体验等),包括others
Pricing(dddd) ,懂的都懂
2.1 Huggingface的Models
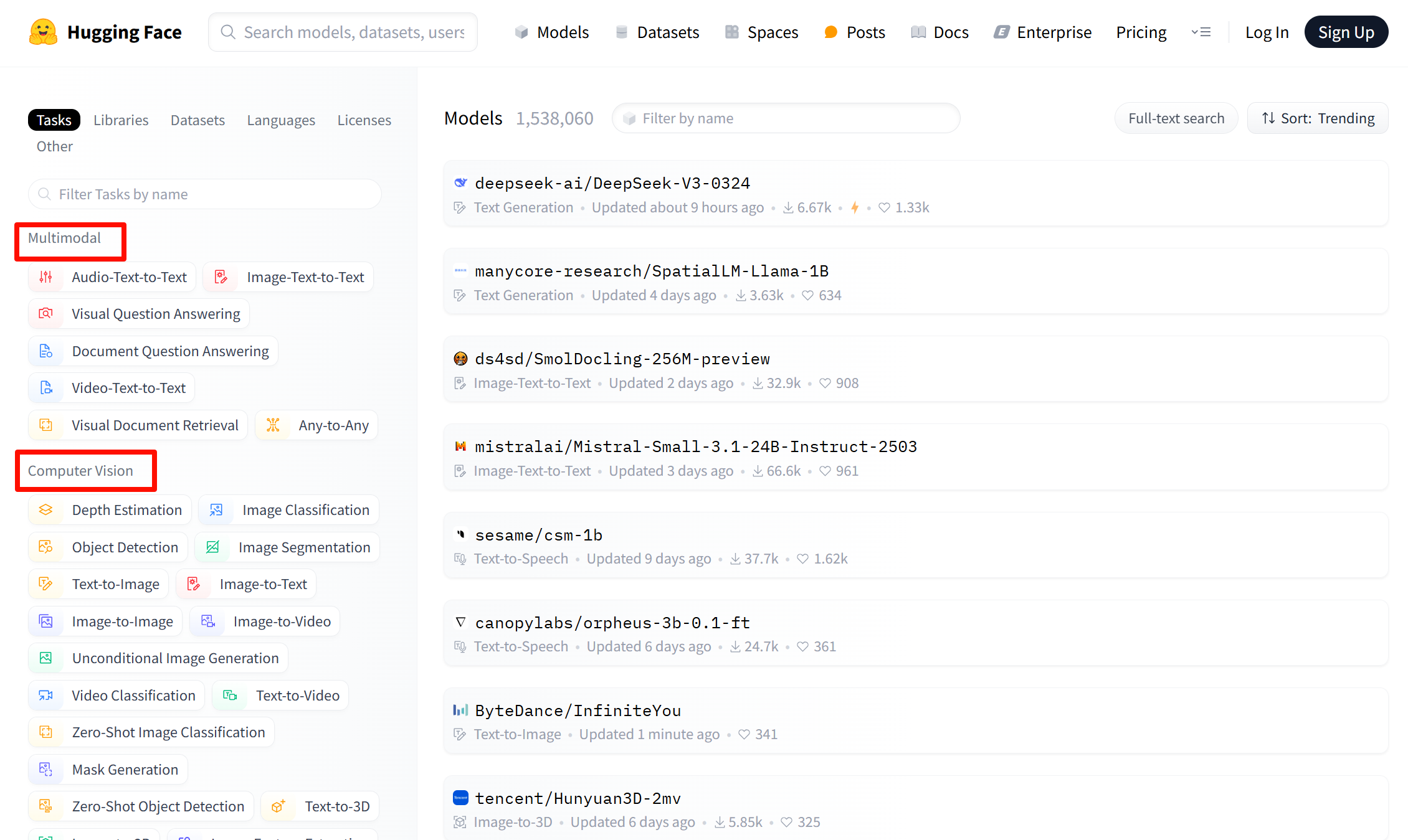
点开Models,可以看到任务,主要包括计算机视觉、自然语言处理、语音处理、多模态、表格处理、强化学习。上百万模型都是开源,免费。。
分别介绍:
Computer Vision(计算机视觉任务) :包括lmage Classification(图像分类),lmage Segmentation(图像分割)、zero-Shot lmage Classification(零样本图像分类)、lmage-to-Image(图像到图像的任务)、Unconditional lmage Generation(无条件图像生成)、Object Detection(目标检测)、Video Classification(视频分类)、Depth Estimation(深度估计,估计拍摄者距离图像各处的距离)
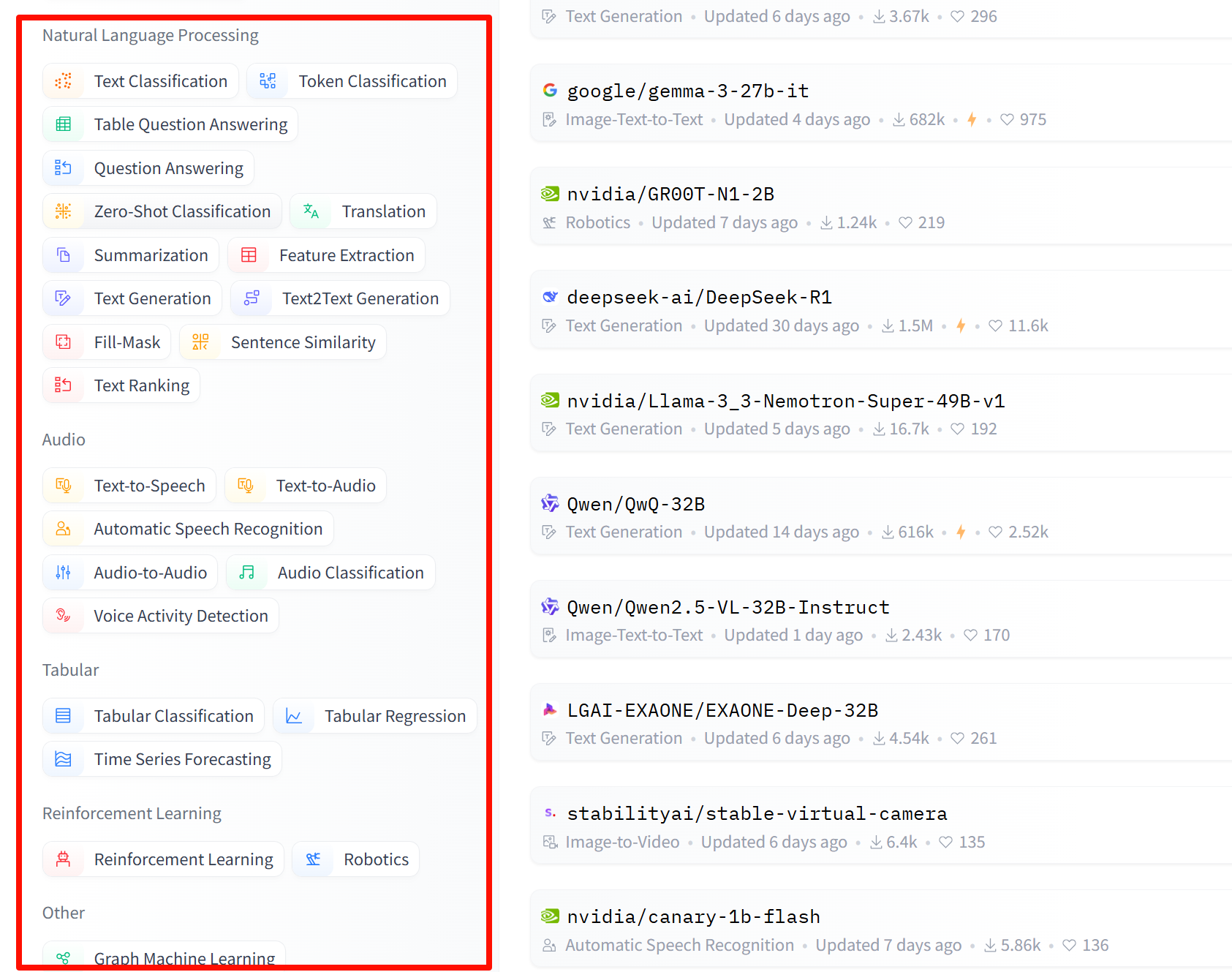
Natural Language Processing(自然语言处理) :包括Translation(机器翻译)、Fill-Mask(填充掩码,预测句子中被遮掩的词)、Token Classification(词分类)、Sentence Similarity(句子相似度)、Question Answering(问答系统),Summarization(总结,缩句)、Zero-Shot Classification (零样本分类)、Text Classification(文本分类)、Text2Text(文本到文本的生成)、Text Generation(文本生成)、Conversational(聊天)、Table Question Answer(表问答,1.预测表格中被遮掩单词2.数字推理,判断句子是否被表格数据支持)
Audio(语音) :Automatic Speech Recognition(语音识别)、Audio Classification(语音分类)、Text-to-Speech(文本到语音的生成)、Audio-to-Audio(语音到语音的生成)、Voice Activity Detection(声音检测、检测识别出需要的声音部分)
Multimodal(多模态) :Feature Extraction(特征提取)、Text-to-Image(文本到图像)、Visual Question Answering(视觉问答)、Image2Text(图像到文本)、Document Question Answering(文档问答)
Tabular(表格) :Tabular Classification(表分类)、Tabular Regression(表回归)
Reinforcement Learning(强化学习):Reinforcement Learning(强化学习)、Robotics(机器人)
2.2 Huggingface的spaces
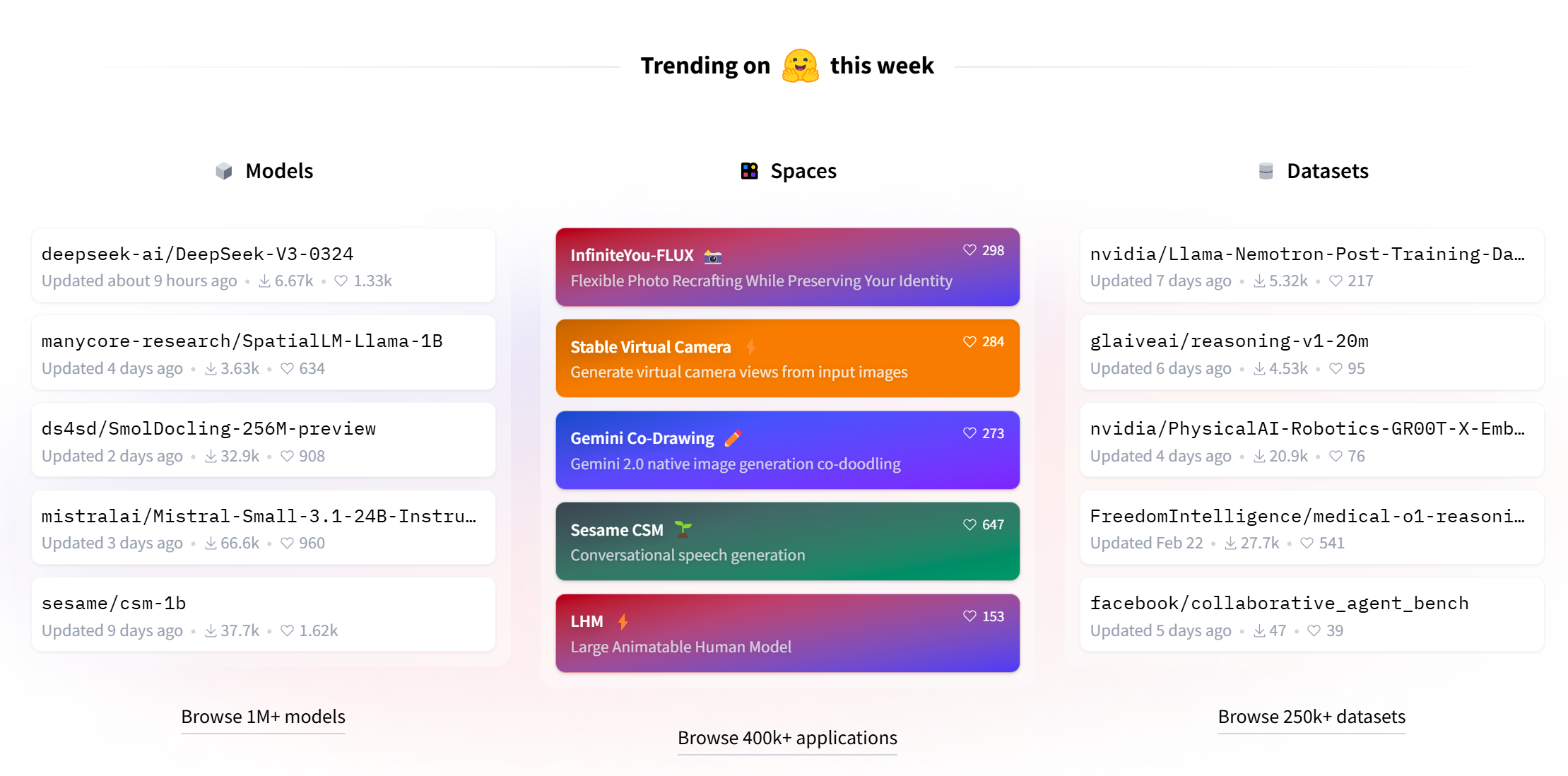
如下图所示,有最近比较火的apps,有很多有意思,有趣的好东西
例如:虚拟试衣应用
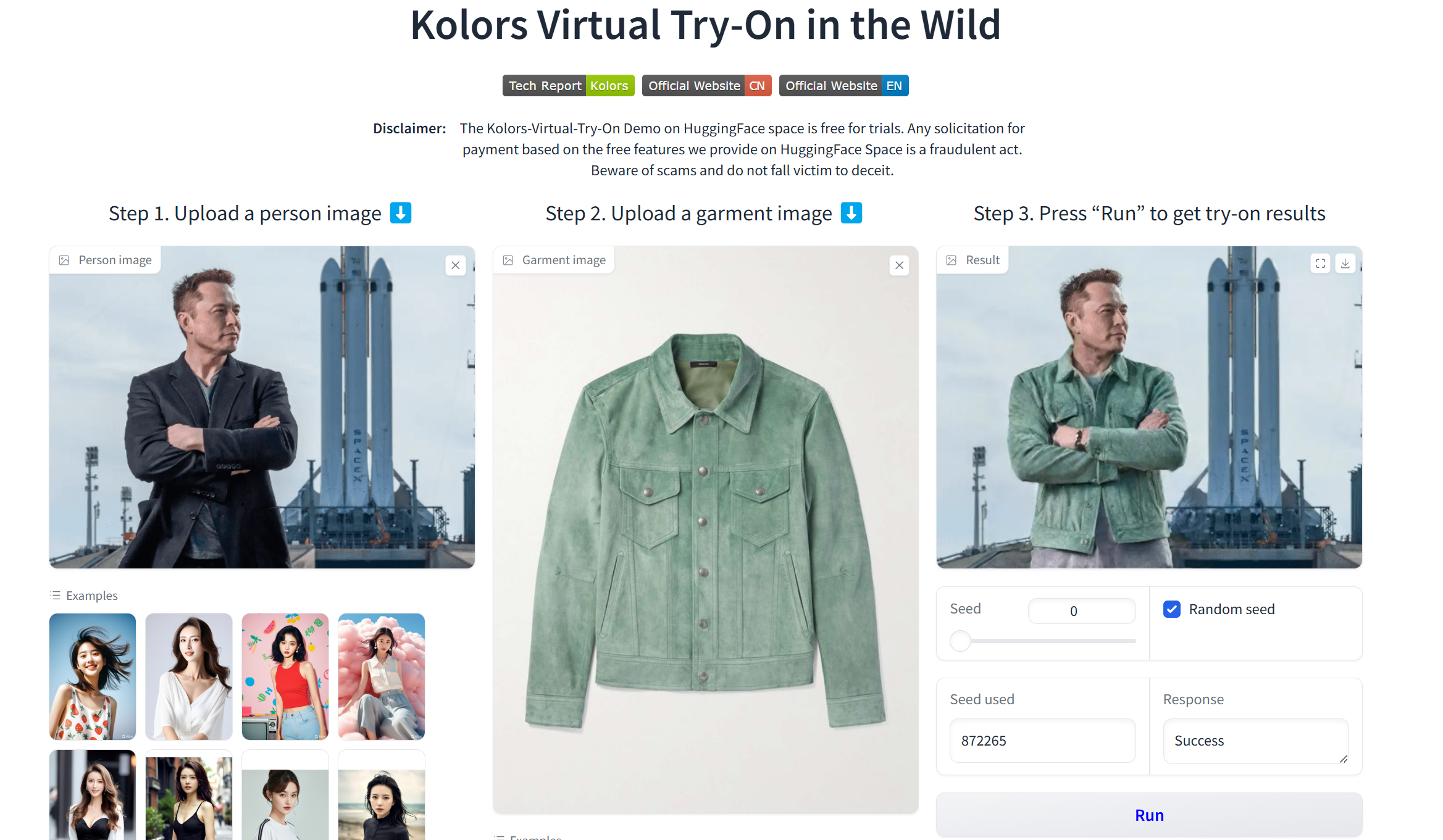
选择一个人,例如马斯克,选择一件工装,点击运行,生成试穿工装的图片。
结束语
Hugging Face的崛起不仅是技术史上的一个注脚,更是一场关于开放协作与民主化创新的革命。通过将尖端NLP模型转化为可访问的工具,它打破了学术界与工业界之间的壁垒,让开发者无需从头构建模型即可快速落地应用。从情感分析到多语言翻译,从科研探索到社会公益,Hugging Face的影响力已渗透到人类生活的方方面面。
展望未来,Hugging Face将继续推动三个方向的突破:
- 模型民主化:通过开源大模型(如Llama系列),降低巨型模型的使用门槛;
- 多模态融合:将文本、图像、音频结合,构建更强大的跨模态理解能力;
- 伦理与可解释性:开发“负责任的AI”工具,确保技术发展符合社会价值观。
对于开发者而言,Hugging Face不仅是工具箱,更是通往AI未来的桥梁。正如其创始人所言:“我们不是在建造一座高墙,而是在搭建一座通向无限可能的阶梯。” 在这个语言与智能交织的时代,Hugging Face的旅程才刚刚开始。
如果你希望深入探索Hugging Face的技术细节,或想获取更多AI领域的实战案例与学习资源,欢迎关注公众号“技海拾贝” 。在这里,我们将持续为你提供NLP模型的深度解析、代码实战教程,以及AI技术的前沿洞察



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









