









MR简介
MapReduce采用"分而治之"的思想,把对大规模数据集的操作,分发给一个主节点管理下的各个分节点共同完成,然后通过整合各个节点的中间结果,得到最终结果。简单地说,MapReduce就是"任务的分解与结果的汇总"。
在Hadoop中,每个MapReduce任务都被初始化为一个Job,每个Job又可以分为两种阶段:map阶段和reduce阶段。这两个阶段分别用两个函数表示,即map函数和reduce函数。map负责把任务分解成多个任务,reduce负责把分解后多任务处理的结果汇总起来。map函数接收一个<key,value>形式的输入,然后同样产生一个<key,value>形式的中间输出,Hadoop函数接收一个如<key,(list of values)>形式的输入,然后对这个value集合进行处理,每个reduce产生0或1个输出,reduce的输出也是<key,value>形式的。

MRv1介绍
MRv1负责数据计算、资源管理。
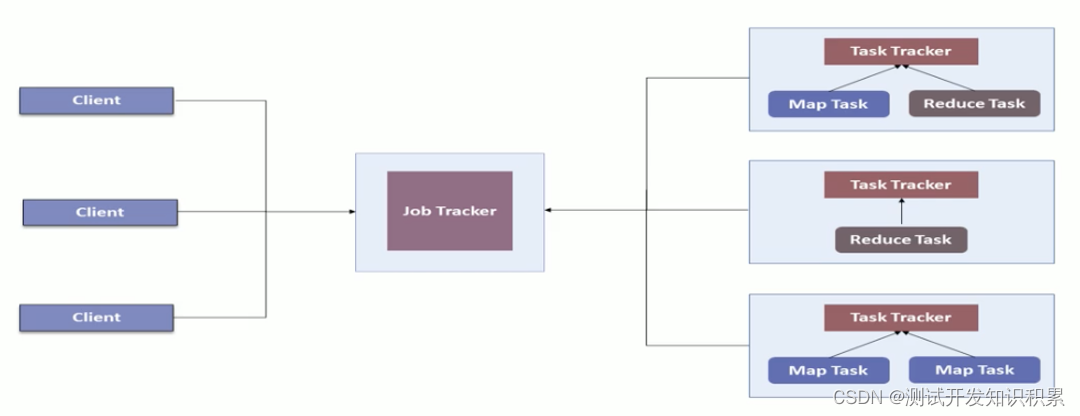
包括运行时环境(一个是JobTracker,负责资源和任务的管理和调度;另一个是TaskTracker,用于执行工作。一个Hadoop集群中只有一台JobTracker。)、编程模型(MapReduce)、数据处理引擎(Map Task和Reduce Task)
MRv2介绍
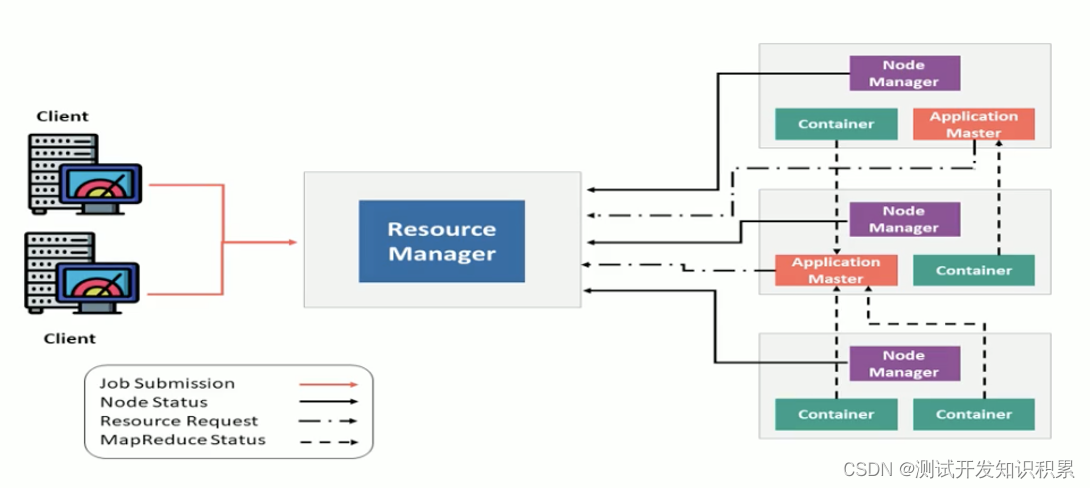
保留了编程模型(MapReduce)和数据处理引擎(Map Task和Reduce Task),运行时环境由YARN负责。
















 1408
1408











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









