








继续上篇AI杂谈(一),今天继续聊聊AI。
AI音乐
目前AI音乐的头部产品有Suno和Udio。具体的使用方法可以看:Suno操作指南 和 Udio操作指北
操作上简单来说就是给出你的需求描述或是歌词就可以生成一首音乐。也可以给一段音频,帮你续写音乐。
Suno具体的技术细节没有公开,但Suno 生成音乐和 GPT 系列模型都属于预训练生成式模型,它们的基本思想有相似之处:
- 预训练阶段
两者都会在大规模数据集上进行预训练。GPT 在文本数据上进行训练,学习语言的语法、语义以及上下文关联;而音乐生成模型(例如 Suno)则会在大量的音乐数据上进行训练,学习旋律、节奏、和声等音乐元素之间的规律。 - 生成机制
无论是文本还是音乐,这些模型在生成内容时都采用类似的“预测下一个单位”的方式。GPT 通过预测下一个单词或子词来生成连贯的文本;音乐生成模型则通过预测下一个音符、节拍或音频 token 来创作音乐,整体上都是一种基于概率的序列生成方法。 - 数据表示与处理的差异
尽管基本原理相似,但它们在数据处理上有明显区别。GPT 的基本单位是文本中的词汇或子词,而音乐生成模型需要处理的则是与音乐相关的特殊符号(如音符、音高、节奏信息)或者直接对音频信号进行建模。因此,在网络架构设计、输入输出的编码方式上,音乐生成模型通常会针对音乐的多维度特性做出相应的优化。
AI音乐方面的优化主要是音乐性,生成的时长,音质的提升,人声的发音咬字等方面。目前的效果已经比较令人满意了。
AI语音合成
常说的AI配音,AI翻唱都属于AI语音合成。此赛道头部产品Eleven Labs。
AI配音
TTS(Text-to-Speech),是一种将文本转换为语音的技术。平时用到的听书软件就是使用的这个技术。
如果已有的TTS音色不能满足我们的需求,就需要用到声音克隆。最低只需要十几秒的语音就可以复刻一个人的说话声音。AI配音的音色还原上已经比较成熟了,目前的优化主要是可以更多的控制语气,情感。
目前我司就有使用GPT-SoVITS来做声音克隆,声音效果还不错,最近也出了v3版本,后面可以跟进一下。
AI翻唱
通过音轨分离工具将人声与原始歌曲分离,再使用人声转换模型将人声转换成另一个人的音色,然后将新的人声轨道与原始作品重新拼接在一起。AI翻唱不改变原音频的语气语调特征,只是替换音色。所以翻唱后的歌曲,还是原歌手的发音方式。
23年的AI孙燕姿就是使用 So-VITS-SVC 实现的。使用操作可以参考:so-vits-svc 4.1 详细使用记录和再探so-vits-svc
AI绘图
相关产品很多,比如Freepik、Stable Diffusion、Flux、Midjourney。它们都用到了Diffusion模型,核心就是前向扩散过程和反向扩散过程。前向扩散过程就是给图片增加噪声,反向扩散过程就是去除图片中的噪声,恢复原始图片。通过学习这两个过程,在生成图片时就会通过逐步去噪的方式去生成数据。这个过程好比是雕刻家雕刻一块毛坯石料。
现在主流的模型用到的是DiT模型(Diffusion in Transformer)是一种结合了Transformer架构和扩散模型的新型生成模型,Transformer在里面的作用就是引导模型关注关键信息。
使用过AI生图的同学应该看过类似下图这种图片逐渐清晰的过程。

对于图生图,一种实现方式(重绘)是先给输入的图片添加噪音,再用相同的方法将这个噪音图降噪成新的图片。另一种(参考)就是将输入的图片作为提示词的一部分,然后将其和文字一起输入到模型中,最后生成新的图片。
AI绘图的提示词特点:
- 多是短语,词语。因为输入的提示词会被编译成一个个的词特征向量。例如"金色沙滩"会同时激活颜色(金色)、材质(沙粒)、场景(海滩)等多个元素。一般不太需要大模型这种有上下文信息的提示词。
- 重要的词放在前面,使用逗号分隔。
目前AI绘图的问题是一些细节不足(稳定性,质感,真实性,空间关系等),且不易修改。早期的语义理解不足的问题目前也好了很多,复杂的指令也可以准确执行。
示例:下图整体而言还不错,但是手部有畸形。

AI视频
相关产品有Sora,海螺AI,可灵,PiKa等。AI视频相对上面提到的AI绘图等更加复杂,同时也面临类似的问题。甚至对于视频来说,且不说生成速度,长视频下的物理规则,光影,交互,逻辑一致性,主体一致性等都是常见的问题。当然玩法也很多,让图片动起来,换脸,生成短剧。
因为放视频不方便,这里就不举例了。目前大多数的AI视频时长都较短,有时内容东一榔头西一棒槌的。但是同时也潜力巨大,我也很期待这个领域的突破。
另外还有3D模型生成,数字人等领域,因为自己涉及较少,这里就不多介绍了。
一些观点
作者列出了以下几种职业:
• 领导力(人们会依赖自己信任的领导者)
• 导师/教练(人类天生倾向于与真人建立关系)
• 谈判与冲突管理(高风险环境中,人们需要与真人互动)
• 线下社区建设
• 实体世界中的美学与氛围营造
• 道德与伦理判断(法官/政治家)
• 高风险决策制定
• 高信任度咨询
• 需要勇气的判断力(创业者)
这些职业的共同点在于:
- 情感与信任依赖
• 领导力、导师、高信任咨询等职业依赖人类的情感联结与信任,这是AI难以复制的。例如,员工更愿意追随有同理心的领导者,而非算法。 - 高风险环境的人类直觉
• 谈判、冲突管理、高风险决策等场景需要结合经验、直觉和即时情绪解读(如微表情),人类在复杂动态中的灵活应对远超AI。 - 实体世界的不可替代性
• 线下社区建设、美学氛围营造等依赖物理空间的人际互动和感官体验,AI无法替代人类对“真实感”的需求。 - 道德与勇气的权重上升
• 法官、政治家、创业者等角色需承担道德责任和风险后果。AI可提供数据支持,但最终判断需人类权衡价值观与社会影响。
也就是说在 AI 技术广泛应用后,人类独有的软技能和社会属性将成为稀缺资源,相关职业的边际价值将显著提升。AI 擅长效率与逻辑,而人类在情感、伦理、创造力等领域的优势将成为未来职业竞争力的核心。
其他
年后AI领域动作不断,各家都发布了自己的旗舰模型,可以说惊喜连连。尤其是Claude 3.7 Sonnet,之前Claude 3.5 Sonnet效果就非常不错了。
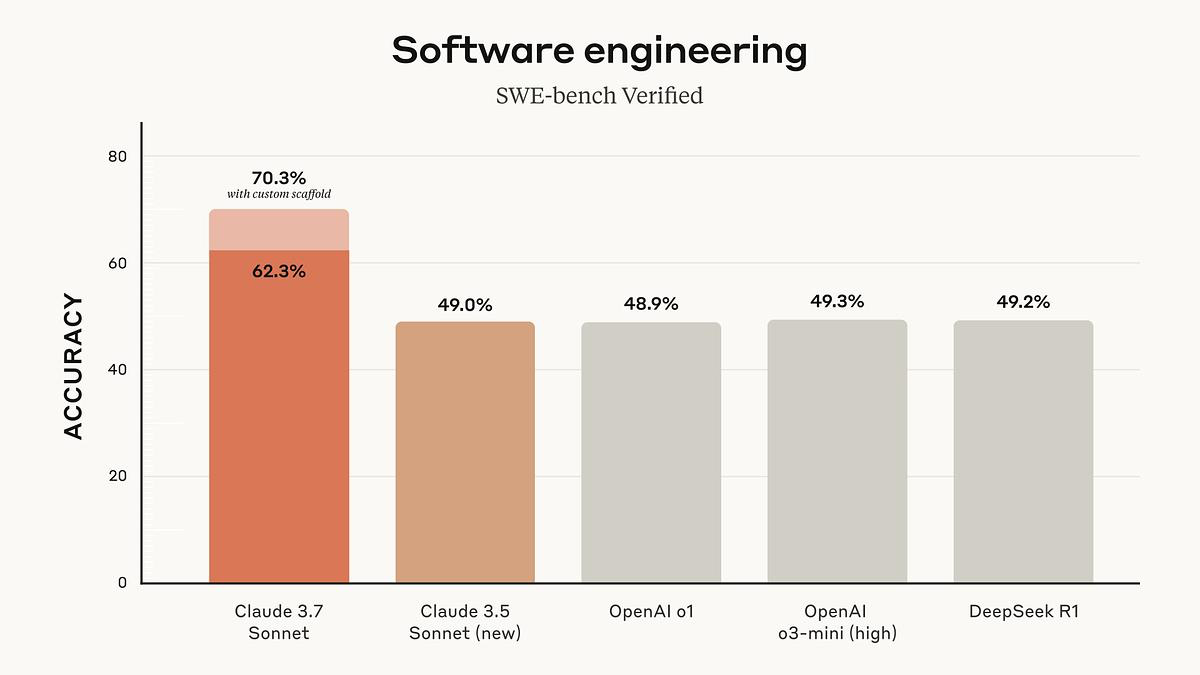
上图中除Claude外,其余都是推理模型,在质量基本一致的情况下,推理模型的速度会慢的多。同时Claude发布时间更早,代码领域目前属于领先的存在。可以说Cursor的成功,离不开Claude 3.5 Sonnet强大的代码能力以及输出速度。
好了,今天就聊这么多,我们有机会在聊。

















 2271
2271

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









