









1. 索引是什么?
索引是一种特殊的文件(InnoDB数据表上的索引是表空间的一个组成部分),它们包含着对数据表里所有记录的引用指针。
索引是一种数据结构。数据库索引,是数据库管理系统中一个排序的数据结构,以协助快速查询、更新数据库表中数据。索引的实现通常使用B树及其变种B+树。更通俗的说,索引就相当于目录。为了方便查找书中的内容,通过对内容建立索引形成目录。而且索引是一个文件,它是要占据物理空间的。
MySQL索引的建立对于MySQL的高效运行是很重要的,索引可以大大提高MySQL的检索速度。比如我们在查字典的时候,前面都有检索的拼音和偏旁、笔画等,然后找到对应字典页码,这样然后就打开字典的页数就可以知道我们要搜索的某一个key的全部值的信息了。
2.索引的几种类型或分类?
1)从物理结构上可以分为聚集索引和非聚集索引两类:
聚簇索引指索引的键值的逻辑顺序与表中相应行的物理顺序一致,即每张表只能有一个聚簇索引,也就是我们常说的主键索引;
非聚簇索引的逻辑顺序则与数据行的物理顺序不一致。
2)从应用上可以划分为一下几类:
普通索引:MySQL 中的基本索引类型,没有什么限制,允许在定义索引的列中插入重复值和空值,纯粹为了提高查询效率。通过 ALTER TABLE table_name ADD INDEX index_name (column) 创建;
唯一索引:索引列中的值必须是唯一的,但是允许为空值。通过 ALTER TABLE table_name ADD UNIQUE index_name (column) 创建;
主键索引:特殊的唯一索引,也是聚簇索引,不允许有空值,并由数据库帮我们自动创建;
组合索引:组合表中多个字段创建的索引,遵守最左前缀匹配规则;
全文索引:只有在 MyISAM 引擎上才能使用,同时只支持 CHAR、VARCHAR、TEXT 类型字段上使用。
3)从存储结构上来划分:BTree索引(B-Tree或B+Tree索引),Hash索引,full-index全文索引,R-Tree索引。这里所描述的是索引存储时保存的形式,
3.索引的优缺点
优点 :
- 使用索引可以大大加快数据的检索速度(大大减少检索的数据量), 这也是创建索引的最主要的原因。
- 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
-
通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统的性能。
缺点 :
- 创建索引和维护索引需要耗费许多时间。当对表中的数据进行增删改的时候,如果数据有索引,那么索引也需要动态的修改,会降低 SQL 执行效率。
- 索引需要使用物理文件存储,也会耗费一定空间。
4.索引的底层数据结构
Hash索引
基于哈希表实现,只有精确匹配索引所有列的查询才有效,对于每一行数据,存储引擎都会对所有的索引列计算一个哈希码(hash code),并且Hash索引将所有的哈希码存储在索引中,同时在索引表中保存指向每个数据行的指针。
哈希表是键值对的集合,通过键(key)即可快速取出对应的值(value),因此哈希表可以快速检索数据(接近 O(1))。

B-Tree索引(MySQL使用B+Tree)
全称为 多路平衡查找树
B-Tree能加快数据的访问速度,因为存储引擎不再需要进行全表扫描来获取数据,数据分布在各个节点之中。

B+Tree索引
是B-Tree的改进版本,同时也是数据库索引索引所采用的存储结构。数据都在叶子节点上,并且增加了顺序访问指针,每个叶子节点都指向相邻的叶子节点的地址。
相比B-Tree来说,进行范围查找时只需要查找两个节点,进行遍历即可。而B-Tree需要获取所有节点,相比之下B+Tree效率更高。
B+tree性质:
-
n棵子tree的节点包含n个关键字,不用来保存数据而是保存数据的索引。
-
所有的叶子结点中包含了全部关键字的信息,及指向含这些关键字记录的指针,且叶子结点本身依关键字的大小自小而大顺序链接。
-
所有的非终端结点可以看成是索引部分,结点中仅含其子树中的最大(或最小)关键字。
-
B+ 树中,数据对象的插入和删除仅在叶节点上进行。
-
B+树有2个头指针,一个是树的根节点,一个是最小关键码的叶节点。
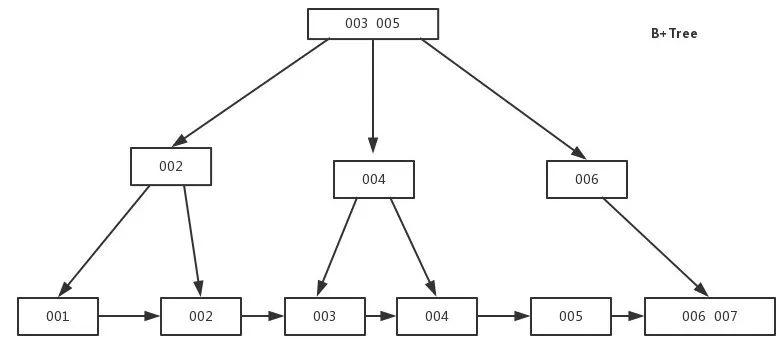
5.聚集索引与非聚集索引
聚集索引
聚集索引即索引结构和数据一起存放的索引。主键索引属于聚集索引。
在 MySQL 中,InnoDB 引擎的表的 .ibd文件就包含了该表的索引和数据,对于 InnoDB 引擎表来说,该表的索引(B+树)的每个非叶子节点存储索引,叶子节点存储索引和索引对应的数据。
聚集索引的优点
聚集索引的查询速度非常的快,因为整个 B+树本身就是一颗多叉平衡树,叶子节点也都是有序的,定位到索引的节点,就相当于定位到了数据。
聚集索引的缺点
- 依赖于有序的数据 :因为 B+树是多路平衡树,如果索引的数据不是有序的,那么就需要在插入时排序,如果数据是整型还好,否则类似于字符串或 UUID 这种又长又难比较的数据,插入或查找的速度肯定比较慢。
- 更新代价大 : 如果对索引列的数据被修改时,那么对应的索引也将会被修改,而且聚集索引的叶子节点还存放着数据,修改代价肯定是较大的,所以对于主键索引来说,主键一般都是不可被修改的。
非聚集索引
非聚集索引即索引结构和数据分开存放的索引。
二级索引属于非聚集索引。
非聚集索引的叶子节点并不一定存放数据的指针,因为二级索引的叶子节点就存放的是主键,根据主键再回表查数据。
非聚集索引的优点
更新代价比聚集索引要小 。非聚集索引的更新代价就没有聚集索引那么大了,非聚集索引的叶子节点是不存放数据的
非聚集索引的缺点
- 跟聚集索引一样,非聚集索引也依赖于有序的数据
- 可能会二次查询(回表) :这应该是非聚集索引最大的缺点了。 当查到索引对应的指针或主键后,可能还需要根据指针或主键再到数据文件或表中查询。
这是 MySQL 的表的文件截图:

聚集索引和非聚集索引:

6.非聚集索引一定回表查询吗(覆盖索引)?
不一定,这涉及到查询语句所要求的字段是否全部命中了索引,如果全部命中了索引,那么就不必再进行回表查询。一个索引包含(覆盖)所有需要查询字段的值,被称之为"覆盖索引"。
举个简单的例子,假设我们在员工表的年龄上建立了索引,那么当进行select score from student where score > 90的查询时,在索引的叶子节点上,已经包含了score 信息,不会再次进行回表查询。
7.什么是最左匹配原则?
最左优先,以最左边为起点任何连续的索引都能匹配上。同时遇到范围查询(>、<、between、like)就会停止匹配。
如建立 (a,b,c,d) 索引,查询条件 b = 2 是匹配不到索引的,但是如果查询条件是 a = 1 and b = 2 或 a=1 又或 b = 2 and a = 1 就可以,因为优化器会自动调整 a,b 的顺序。
再比如 a = 1 and b = 2 and c > 3 and d = 4,其中 d 是用不到索引的,因为 c 是一个范围查询,它之后的字段会停止匹配。

















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









