







.str.contains()
.str.contains()会判断字符是否有包含关系,返回布尔序列,经常用在数据筛选中,它默认支持正则表达式,如果不需要,可以关掉。参数na可以指定对空值的处理方式。
import pandas as pd
import numpy as np
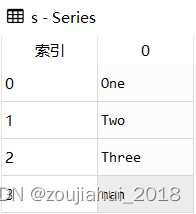
s = pd.Series(['One','Two','Three',np.NaN])
# 是否包含检测
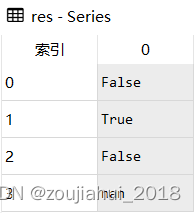
res = s.str.contains('o',regex = False)
import pandas as pd
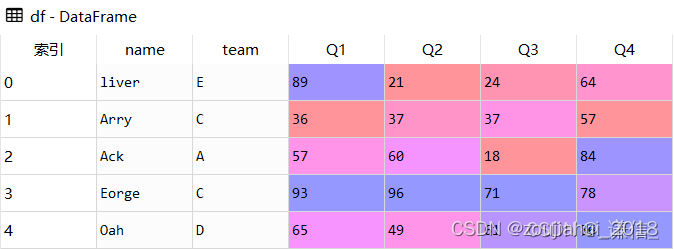
df = pd.DataFrame([['liver','E',89,21,24,64],
['Arry','C',36,37,37,57],
['Ack','A',57,60,18,84],
['Eorge','C',93,96,71,78],
['Oah','D',65,49,61,86]
],
columns = ['name','team','Q1','Q2','Q3','Q4'])
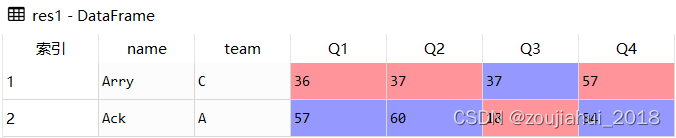
# 名字包含A字母
res1 = df.loc[df.name.str.contains('A')]
# 名字包含A字母或E字母
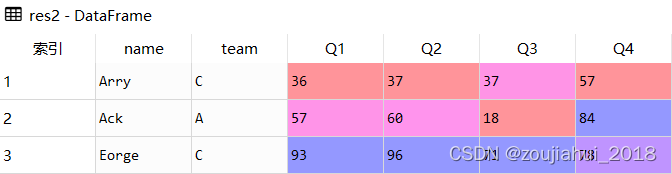
res2 = df.loc[df.name.str.contains('A|E')]
# 忽略大小写
import re
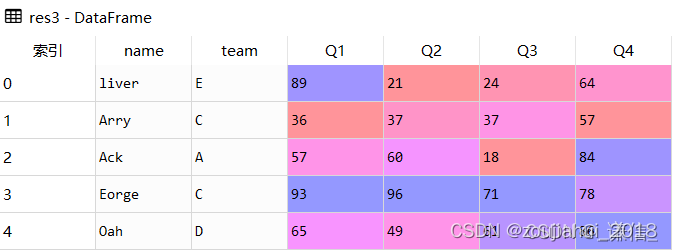
res3 = df.loc[df.name.str.contains('A|E', flags = re.IGNORECASE)]
# 包含数字
res4 = df.loc[df.name.str.contains('\d')]
.str.startswith()和.str.endswith()可以指定是开头还是结尾包含
import pandas as pd
import numpy as np
# 原数据
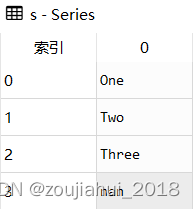
s = pd.Series(['One','Two','Three',np.NaN])
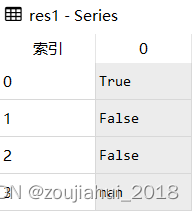
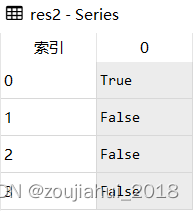
res1 = s.str.startswith('O')
# 对空值的处理
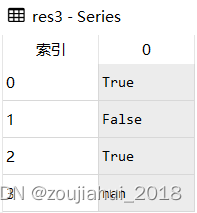
res2 = s.str.startswith('O',na = False)
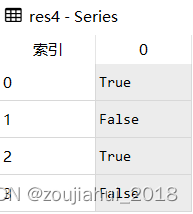
res3 = s.str.endswith('e')
res4 = s.str.endswith('e',na = False)
用.str.match()确定每个字符串是否与正则表达式匹配
import pandas as pd
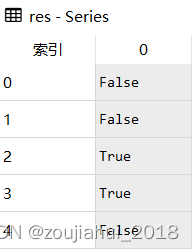
res = pd.Series(['1','2','3a','3b','03c']).str.match(r'[0-9][a-z]')
转载链接:https://blog.csdn.net/Hudas/article/details/122922868

















 820
820

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









