







126、什么是ORM?
答:对象关系映射(Object-Relational Mapping,简称ORM)是一种为了解决程序的面向对象模型与数据库的关系模型互不匹配问题的技术;简单的说,ORM是通过使用描述对象和数据库之间映射的元数据(在Java中可以用XML或者是注解),将程序中的对象自动持久化到关系数据库中或者将关系数据库表中的行转换成Java对象,其本质上就是将数据从一种形式转换到另外一种形式。
127、持久层设计要考虑的问题有哪些?你用过的持久层框架有哪些?
答:所谓”持久”就是将数据保存到可掉电式存储设备中以便今后使用,简单的说,就是将内存中的数据保存到关系型数据库、文件系统、消息队列等提供持久化支持的设备中。持久层就是系统中专注于实现数据持久化的相对独立的层面。
持久层设计的目标包括:
- 数据存储逻辑的分离,提供抽象化的数据访问接口。
- 数据访问底层实现的分离,可以在不修改代码的情况下切换底层实现。
- 资源管理和调度的分离,在数据访问层实现统一的资源调度(如缓存机制)。
- 数据抽象,提供更面向对象的数据操作。
持久层框架有:
- Hibernate
- MyBatis
- TopLink
- Guzz
- jOOQ
- Spring Data
- ActiveJDBC
128、Hibernate中SessionFactory是线程安全的吗?Session是线程安全的吗(两个线程能够共享同一个Session吗)?
答:SessionFactory对应Hibernate的一个数据存储的概念,它是线程安全的,可以被多个线程并发访问。SessionFactory一般只会在启动的时候构建。对于应用程序,最好将SessionFactory通过单例模式进行封装以便于访问。Session是一个轻量级非线程安全的对象(线程间不能共享session),它表示与数据库进行交互的一个工作单元。Session是由SessionFactory创建的,在任务完成之后它会被关闭。Session是持久层服务对外提供的主要接口。Session会延迟获取数据库连接(也就是在需要的时候才会获取)。为了避免创建太多的session,可以使用ThreadLocal将session和当前线程绑定在一起,这样可以让同一个线程获得的总是同一个session。Hibernate 3中SessionFactory的getCurrentSession()方法就可以做到。
129、Hibernate中Session的load和get方法的区别是什么?
答:主要有以下三项区别:
① 如果没有找到符合条件的记录,get方法返回null,load方法抛出异常。
② get方法直接返回实体类对象,load方法返回实体类对象的代理。
③ 在Hibernate 3之前,get方法只在一级缓存中进行数据查找,如果没有找到对应的数据则越过二级缓存,直接发出SQL语句完成数据读取;load方法则可以从二级缓存中获取数据;从Hibernate 3开始,get方法不再是对二级缓存只写不读,它也是可以访问二级缓存的。
说明:对于load()方法Hibernate认为该数据在数据库中一定存在可以放心的使用代理来实现延迟加载,如果没有数据就抛出异常,而通过get()方法获取的数据可以不存在。
130、Session的save()、update()、merge()、lock()、saveOrUpdate()和persist()方法分别是做什么的?有什么区别?
答:Hibernate的对象有三种状态:瞬时态(transient)、持久态(persistent)和游离态(detached),如第135题中的图所示。瞬时态的实例可以通过调用save()、persist()或者saveOrUpdate()方法变成持久态;游离态的实例可以通过调用 update()、saveOrUpdate()、lock()或者replicate()变成持久态。save()和persist()将会引发SQL的INSERT语句,而update()或merge()会引发UPDATE语句。save()和update()的区别在于一个是将瞬时态对象变成持久态,一个是将游离态对象变为持久态。merge()方法可以完成save()和update()方法的功能,它的意图是将新的状态合并到已有的持久化对象上或创建新的持久化对象。对于persist()方法,按照官方文档的说明:① persist()方法把一个瞬时态的实例持久化,但是并不保证标识符被立刻填入到持久化实例中,标识符的填入可能被推迟到flush的时间;② persist()方法保证当它在一个事务外部被调用的时候并不触发一个INSERT语句,当需要封装一个长会话流程的时候,persist()方法是很有必要的;③ save()方法不保证第②条,它要返回标识符,所以它会立即执行INSERT语句,不管是在事务内部还是外部。至于lock()方法和update()方法的区别,update()方法是把一个已经更改过的脱管状态的对象变成持久状态;lock()方法是把一个没有更改过的脱管状态的对象变成持久状态。
131、阐述Session加载实体对象的过程。
答:Session加载实体对象的步骤是:
① Session在调用数据库查询功能之前,首先会在一级缓存中通过实体类型和主键进行查找,如果一级缓存查找命中且数据状态合法,则直接返回;
② 如果一级缓存没有命中,接下来Session会在当前NonExists记录(相当于一个查询黑名单,如果出现重复的无效查询可以迅速做出判断,从而提升性能)中进行查找,如果NonExists中存在同样的查询条件,则返回null;
③ 如果一级缓存查询失败则查询二级缓存,如果二级缓存命中则直接返回;
④ 如果之前的查询都未命中,则发出SQL语句,如果查询未发现对应记录则将此次查询添加到Session的NonExists中加以记录,并返回null;
⑤ 根据映射配置和SQL语句得到ResultSet,并创建对应的实体对象;
⑥ 将对象纳入Session(一级缓存)的管理;
⑦ 如果有对应的拦截器,则执行拦截器的onLoad方法;
⑧ 如果开启并设置了要使用二级缓存,则将数据对象纳入二级缓存;
⑨ 返回数据对象。
132、Query接口的list方法和iterate方法有什么区别?
答:
① list()方法无法利用一级缓存和二级缓存(对缓存只写不读),它只能在开启查询缓存的前提下使用查询缓存;iterate()方法可以充分利用缓存,如果目标数据只读或者读取频繁,使用iterate()方法可以减少性能开销。
② list()方法不会引起N+1查询问题,而iterate()方法可能引起N+1查询问题
说明:关于N+1查询问题,可以参考CSDN上的一篇文章《什么是N+1查询》
133、Hibernate如何实现分页查询?
答:通过Hibernate实现分页查询,开发人员只需要提供HQL语句(调用Session的createQuery()方法)或查询条件(调用Session的createCriteria()方法)、设置查询起始行数(调用Query或Criteria接口的setFirstResult()方法)和最大查询行数(调用Query或Criteria接口的setMaxResults()方法),并调用Query或Criteria接口的list()方法,Hibernate会自动生成分页查询的SQL语句。
134、锁机制有什么用?简述Hibernate的悲观锁和乐观锁机制。
答:有些业务逻辑在执行过程中要求对数据进行排他性的访问,于是需要通过一些机制保证在此过程中数据被锁住不会被外界修改,这就是所谓的锁机制。
Hibernate支持悲观锁和乐观锁两种锁机制。悲观锁,顾名思义悲观的认为在数据处理过程中极有可能存在修改数据的并发事务(包括本系统的其他事务或来自外部系统的事务),于是将处理的数据设置为锁定状态。悲观锁必须依赖数据库本身的锁机制才能真正保证数据访问的排他性,关于数据库的锁机制和事务隔离级别在《Java面试题大全(上)》中已经讨论过了。乐观锁,顾名思义,对并发事务持乐观态度(认为对数据的并发操作不会经常性的发生),通过更加宽松的锁机制来解决由于悲观锁排他性的数据访问对系统性能造成的严重影响。最常见的乐观锁是通过数据版本标识来实现的,读取数据时获得数据的版本号,更新数据时将此版本号加1,然后和数据库表对应记录的当前版本号进行比较,如果提交的数据版本号大于数据库中此记录的当前版本号则更新数据,否则认为是过期数据无法更新。Hibernate中通过Session的get()和load()方法从数据库中加载对象时可以通过参数指定使用悲观锁;而乐观锁可以通过给实体类加整型的版本字段再通过XML或@Version注解进行配置。
提示:使用乐观锁会增加了一个版本字段,很明显这需要额外的空间来存储这个版本字段,浪费了空间,但是乐观锁会让系统具有更好的并发性,这是对时间的节省。因此乐观锁也是典型的空间换时间的策略。
135、阐述实体对象的三种状态以及转换关系。
答:最新的Hibernate文档中为Hibernate对象定义了四种状态(原来是三种状态,面试的时候基本上问的也是三种状态),分别是:瞬时态(new, or transient)、持久态(managed, or persistent)、游状态(detached)和移除态(removed,以前Hibernate文档中定义的三种状态中没有移除态),如下图所示,就以前的Hibernate文档中移除态被视为是瞬时态。
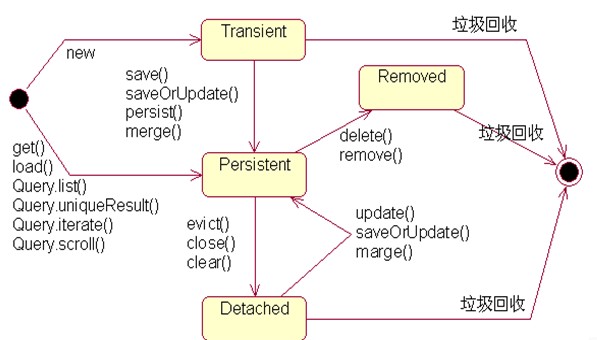
- 瞬时态:当new一个实体对象后,这个对象处于瞬时态,即这个对象只是一个保存临时数据的内存区域,如果没有变量引用这个对象,则会被JVM的垃圾回收机制回收。这个对象所保存的数据与数据库没有任何关系,除非通过Session的save()、saveOrUpdate()、persist()、merge()方法把瞬时态对象与数据库关联,并把数据插入或者更新到数据库,这个对象才转换为持久态对象。
- 持久态:持久态对象的实例在数据库中有对应的记录,并拥有一个持久化标识(ID)。对持久态对象进行delete操作后,数据库中对应的记录将被删除,那么持久态对象与数据库记录不再存在对应关系,持久态对象变成移除态(可以视为瞬时态)。持久态对象被修改变更后,不会马上同步到数据库,直到数据库事务提交。
- 游离态:当Session进行了close()、clear()、evict()或flush()后,实体对象从持久态变成游离态,对象虽然拥有持久和与数据库对应记录一致的标识值,但是因为对象已经从会话中清除掉,对象不在持久化管理之内,所以处于游离态(也叫脱管态)。游离态的对象与临时状态对象是十分相似的,只是它还含有持久化标识。
提示:关于这个问题,在Hibernate的官方文档中有更为详细的解读。
136、如何理解Hibernate的延迟加载机制?在实际应用中,延迟加载与Session关闭的矛盾是如何处理的?
答:延迟加载就是并不是在读取的时候就把数据加载进来,而是等到使用时再加载。Hibernate使用了虚拟代理机制实现延迟加载,我们使用Session的load()方法加载数据或者一对多关联映射在使用延迟加载的情况下从一的一方加载多的一方,得到的都是虚拟代理,简单的说返回给用户的并不是实体本身,而是实体对象的代理。代理对象在用户调用getter方法时才会去数据库加载数据。但加载数据就需要数据库连接。而当我们把会话关闭时,数据库连接就同时关闭了。
延迟加载与session关闭的矛盾一般可以这样处理:
① 关闭延迟加载特性。这种方式操作起来比较简单,因为Hibernate的延迟加载特性是可以通过映射文件或者注解进行配置的,但这种解决方案存在明显的缺陷。首先,出现”no session or session was closed”通常说明系统中已经存在主外键关联,如果去掉延迟加载的话,每次查询的开销都会变得很大。
② 在session关闭之前先获取需要查询的数据,可以使用工具方法Hibernate.isInitialized()判断对象是否被加载,如果没有被加载则可以使用Hibernate.initialize()方法加载对象。
③ 使用拦截器或过滤器延长Session的生命周期直到视图获得数据。Spring整合Hibernate提供的OpenSessionInViewFilter和OpenSessionInViewInterceptor就是这种做法。
137、举一个多对多关联的例子,并说明如何实现多对多关联映射。
答:例如:商品和订单、学生和课程都是典型的多对多关系。可以在实体类上通过@ManyToMany注解配置多对多关联或者通过映射文件中的和标签配置多对多关联,但是实际项目开发中,很多时候都是将多对多关联映射转换成两个多对一关联映射来实现的。
138、谈一下你对继承映射的理解。
答:继承关系的映射策略有三种:
① 每个继承结构一张表(table per class hierarchy),不管多少个子类都用一张表。
② 每个子类一张表(table per subclass),公共信息放一张表,特有信息放单独的表。
③ 每个具体类一张表(table per concrete class),有多少个子类就有多少张表。
第一种方式属于单表策略,其优点在于查询子类对象的时候无需表连接,查询速度快,适合多态查询;缺点是可能导致表很大。后两种方式属于多表策略,其优点在于数据存储紧凑,其缺点是需要进行连接查询,不适合多态查询。
139、简述Hibernate常见优化策略。
答:这个问题应当挑自己使用过的优化策略回答,常用的有:
① 制定合理的缓存策略(二级缓存、查询缓存)。
② 采用合理的Session管理机制。
③ 尽量使用延迟加载特性。
④ 设定合理的批处理参数。
⑤ 如果可以,选用UUID作为主键生成器。
⑥ 如果可以,选用基于版本号的乐观锁替代悲观锁。
⑦ 在开发过程中, 开启hibernate.show_sql选项查看生成的SQL,从而了解底层的状况;开发完成后关闭此选项。
⑧ 考虑数据库本身的优化,合理的索引、恰当的数据分区策略等都会对持久层的性能带来可观的提升,但这些需要专业的DBA(数据库管理员)提供支持。
140、谈一谈Hibernate的一级缓存、二级缓存和查询缓存。
答:Hibernate的Session提供了一级缓存的功能,默认总是有效的,当应用程序保存持久化实体、修改持久化实体时,Session并不会立即把这种改变提交到数据库,而是缓存在当前的Session中,除非显示调用了Session的flush()方法或通过close()方法关闭Session。通过一级缓存,可以减少程序与数据库的交互,从而提高数据库访问性能。
SessionFactory级别的二级缓存是全局性的,所有的Session可以共享这个二级缓存。不过二级缓存默认是关闭的,需要显示开启并指定需要使用哪种二级缓存实现类(可以使用第三方提供的实现)。一旦开启了二级缓存并设置了需要使用二级缓存的实体类,SessionFactory就会缓存访问过的该实体类的每个对象,除非缓存的数据超出了指定的缓存空间。
一级缓存和二级缓存都是对整个实体进行缓存,不会缓存普通属性,如果希望对普通属性进行缓存,可以使用查询缓存。查询缓存是将HQL或SQL语句以及它们的查询结果作为键值对进行缓存,对于同样的查询可以直接从缓存中获取数据。查询缓存默认也是关闭的,需要显示开启。
141、Hibernate中DetachedCriteria类是做什么的?
答:DetachedCriteria和Criteria的用法基本上是一致的,但Criteria是由Session的createCriteria()方法创建的,也就意味着离开创建它的Session,Criteria就无法使用了。DetachedCriteria不需要Session就可以创建(使用DetachedCriteria.forClass()方法创建),所以通常也称其为离线的Criteria,在需要进行查询操作的时候再和Session绑定(调用其getExecutableCriteria(Session)方法),这也就意味着一个DetachedCriteria可以在需要的时候和不同的Session进行绑定。
142、@OneToMany注解的mappedBy属性有什么作用?
答:@OneToMany用来配置一对多关联映射,但通常情况下,一对多关联映射都由多的一方来维护关联关系,例如学生和班级,应该在学生类中添加班级属性来维持学生和班级的关联关系(在数据库中是由学生表中的外键班级编号来维护学生表和班级表的多对一关系),如果要使用双向关联,在班级类中添加一个容器属性来存放学生,并使用@OneToMany注解进行映射,此时mappedBy属性就非常重要。如果使用XML进行配置,可以用<set>标签的inverse=”true”设置来达到同样的效果。
143、MyBatis中使用#和$书写占位符有什么区别?
答:#将传入的数据都当成一个字符串,会对传入的数据自动加上引号;$将传入的数据直接显示生成在SQL中。注意:使用$占位符可能会导致SQL注射攻击,能用#的地方就不要使用$,写order by子句的时候应该用$而不是#。
144、解释一下MyBatis中命名空间(namespace)的作用。
答:在大型项目中,可能存在大量的SQL语句,这时候为每个SQL语句起一个唯一的标识(ID)就变得并不容易了。为了解决这个问题,在MyBatis中,可以为每个映射文件起一个唯一的命名空间,这样定义在这个映射文件中的每个SQL语句就成了定义在这个命名空间中的一个ID。只要我们能够保证每个命名空间中这个ID是唯一的,即使在不同映射文件中的语句ID相同,也不会再产生冲突了。
145、MyBatis中的动态SQL是什么意思?
答:对于一些复杂的查询,我们可能会指定多个查询条件,但是这些条件可能存在也可能不存在,例如在58同城上面找房子,我们可能会指定面积、楼层和所在位置来查找房源,也可能会指定面积、价格、户型和所在位置来查找房源,此时就需要根据用户指定的条件动态生成SQL语句。如果不使用持久层框架我们可能需要自己拼装SQL语句,还好MyBatis提供了动态SQL的功能来解决这个问题。MyBatis中用于实现动态SQL的元素主要有:
- if
- choose / when / otherwise
- trim
- where
- set
- foreach
下面是映射文件的片段。
|
1
2
3
4
5
6
7
8
9
10
11
12
|
<select id=
"foo"
parameterType=
"Blog"
resultType=
"Blog"
>
select * from t_blog where
1
=
1
<
if
test=
"title != null"
>
and title = #{title}
</
if
>
<
if
test=
"content != null"
>
and content = #{content}
</
if
>
<
if
test=
"owner != null"
>
and owner = #{owner}
</
if
>
</select>
|
当然也可以像下面这些书写。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
<select id=
"foo"
parameterType=
"Blog"
resultType=
"Blog"
>
select * from t_blog where
1
=
1
<choose>
<when test=
"title != null"
>
and title = #{title}
</when>
<when test=
"content != null"
>
and content = #{content}
</when>
<otherwise>
and owner =
"owner1"
</otherwise>
</choose>
</select>
|
再看看下面这个例子。
|
1
2
3
4
5
6
7
|
<select id=
"bar"
resultType=
"Blog"
>
select * from t_blog where id in
<foreach collection=
"array"
index=
"index"
item=
"item"
open=
"("
separator=
","
close=
")"
>
#{item}
</foreach>
</select>
|
146、什么是IoC和DI?DI是如何实现的?
答:IoC叫控制反转,是Inversion of Control的缩写,DI(Dependency Injection)叫依赖注入,是对IoC更简单的诠释。控制反转是把传统上由程序代码直接操控的对象的调用权交给容器,通过容器来实现对象组件的装配和管理。所谓的”控制反转”就是对组件对象控制权的转移,从程序代码本身转移到了外部容器,由容器来创建对象并管理对象之间的依赖关系。IoC体现了好莱坞原则 – “Don’t call me, we will call you”。依赖注入的基本原则是应用组件不应该负责查找资源或者其他依赖的协作对象。配置对象的工作应该由容器负责,查找资源的逻辑应该从应用组件的代码中抽取出来,交给容器来完成。DI是对IoC更准确的描述,即组件之间的依赖关系由容器在运行期决定,形象的来说,即由容器动态的将某种依赖关系注入到组件之中。
举个例子:一个类A需要用到接口B中的方法,那么就需要为类A和接口B建立关联或依赖关系,最原始的方法是在类A中创建一个接口B的实现类C的实例,但这种方法需要开发人员自行维护二者的依赖关系,也就是说当依赖关系发生变动的时候需要修改代码并重新构建整个系统。如果通过一个容器来管理这些对象以及对象的依赖关系,则只需要在类A中定义好用于关联接口B的方法(构造器或setter方法),将类A和接口B的实现类C放入容器中,通过对容器的配置来实现二者的关联。
依赖注入可以通过setter方法注入(设值注入)、构造器注入和接口注入三种方式来实现,Spring支持setter注入和构造器注入,通常使用构造器注入来注入必须的依赖关系,对于可选的依赖关系,则setter注入是更好的选择,setter注入需要类提供无参构造器或者无参的静态工厂方法来创建对象。
147、Spring中Bean的作用域有哪些?
答:在Spring的早期版本中,仅有两个作用域:singleton和prototype,前者表示Bean以单例的方式存在;后者表示每次从容器中调用Bean时,都会返回一个新的实例,prototype通常翻译为原型。
补充:设计模式中的创建型模式中也有一个原型模式,原型模式也是一个常用的模式,例如做一个室内设计软件,所有的素材都在工具箱中,而每次从工具箱中取出的都是素材对象的一个原型,可以通过对象克隆来实现原型模式。
Spring 2.x中针对WebApplicationContext新增了3个作用域,分别是:request(每次HTTP请求都会创建一个新的Bean)、session(同一个HttpSession共享同一个Bean,不同的HttpSession使用不同的Bean)和globalSession(同一个全局Session共享一个Bean)。
说明:单例模式和原型模式都是重要的设计模式。一般情况下,无状态或状态不可变的类适合使用单例模式。在传统开发中,由于DAO持有Connection这个非线程安全对象因而没有使用单例模式;但在Spring环境下,所有DAO类对可以采用单例模式,因为Spring利用AOP和Java API中的ThreadLocal对非线程安全的对象进行了特殊处理。
ThreadLocal为解决多线程程序的并发问题提供了一种新的思路。ThreadLocal,顾名思义是线程的一个本地化对象,当工作于多线程中的对象使用ThreadLocal维护变量时,ThreadLocal为每个使用该变量的线程分配一个独立的变量副本,所以每一个线程都可以独立的改变自己的副本,而不影响其他线程所对应的副本。从线程的角度看,这个变量就像是线程的本地变量。
ThreadLocal类非常简单好用,只有四个方法,能用上的也就是下面三个方法:
- void set(T value):设置当前线程的线程局部变量的值。
- T get():获得当前线程所对应的线程局部变量的值。
- void remove():删除当前线程中线程局部变量的值。
ThreadLocal是如何做到为每一个线程维护一份独立的变量副本的呢?在ThreadLocal类中有一个Map,键为线程对象,值是其线程对应的变量的副本,自己要模拟实现一个ThreadLocal类其实并不困难,代码如下所示:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
import
java.util.Collections;
import
java.util.HashMap;
import
java.util.Map;
public
class
MyThreadLocal<T> {
private
Map<Thread, T> map = Collections.synchronizedMap(
new
HashMap<Thread, T>());
public
void
set(T newValue) {
map.put(Thread.currentThread(), newValue);
}
public
T get() {
return
map.get(Thread.currentThread());
}
public
void
remove() {
map.remove(Thread.currentThread());
}
}
|
148、解释一下什么叫AOP(面向切面编程)?
答:AOP(Aspect-Oriented Programming)指一种程序设计范型,该范型以一种称为切面(aspect)的语言构造为基础,切面是一种新的模块化机制,用来描述分散在对象、类或方法中的横切关注点(crosscutting concern)。
149、你是如何理解”横切关注”这个概念的?
答:”横切关注”是会影响到整个应用程序的关注功能,它跟正常的业务逻辑是正交的,没有必然的联系,但是几乎所有的业务逻辑都会涉及到这些关注功能。通常,事务、日志、安全性等关注就是应用中的横切关注功能。
150、你如何理解AOP中的连接点(Joinpoint)、切点(Pointcut)、增强(Advice)、引介(Introduction)、织入(Weaving)、切面(Aspect)这些概念?
答:
a. 连接点(Joinpoint):程序执行的某个特定位置(如:某个方法调用前、调用后,方法抛出异常后)。一个类或一段程序代码拥有一些具有边界性质的特定点,这些代码中的特定点就是连接点。Spring仅支持方法的连接点。
b. 切点(Pointcut):如果连接点相当于数据中的记录,那么切点相当于查询条件,一个切点可以匹配多个连接点。Spring AOP的规则解析引擎负责解析切点所设定的查询条件,找到对应的连接点。
c. 增强(Advice):增强是织入到目标类连接点上的一段程序代码。Spring提供的增强接口都是带方位名的,如:BeforeAdvice、AfterReturningAdvice、ThrowsAdvice等。很多资料上将增强译为“通知”,这明显是个词不达意的翻译,让很多程序员困惑了许久。
说明: Advice在国内的很多书面资料中都被翻译成”通知”,但是很显然这个翻译无法表达其本质,有少量的读物上将这个词翻译为”增强”,这个翻译是对Advice较为准确的诠释,我们通过AOP将横切关注功能加到原有的业务逻辑上,这就是对原有业务逻辑的一种增强,这种增强可以是前置增强、后置增强、返回后增强、抛异常时增强和包围型增强。
d. 引介(Introduction):引介是一种特殊的增强,它为类添加一些属性和方法。这样,即使一个业务类原本没有实现某个接口,通过引介功能,可以动态的未该业务类添加接口的实现逻辑,让业务类成为这个接口的实现类。
e. 织入(Weaving):织入是将增强添加到目标类具体连接点上的过程,AOP有三种织入方式:①编译期织入:需要特殊的Java编译期(例如AspectJ的ajc);②装载期织入:要求使用特殊的类加载器,在装载类的时候对类进行增强;③运行时织入:在运行时为目标类生成代理实现增强。Spring采用了动态代理的方式实现了运行时织入,而AspectJ采用了编译期织入和装载期织入的方式。
f. 切面(Aspect):切面是由切点和增强(引介)组成的,它包括了对横切关注功能的定义,也包括了对连接点的定义。
补充:代理模式是GoF提出的23种设计模式中最为经典的模式之一,代理模式是对象的结构模式,它给某一个对象提供一个代理对象,并由代理对象控制对原对象的引用。简单的说,代理对象可以完成比原对象更多的职责,当需要为原对象添加横切关注功能时,就可以使用原对象的代理对象。我们在打开Office系列的Word文档时,如果文档中有插图,当文档刚加载时,文档中的插图都只是一个虚框占位符,等用户真正翻到某页要查看该图片时,才会真正加载这张图,这其实就是对代理模式的使用,代替真正图片的虚框就是一个虚拟代理;Hibernate的load方法也是返回一个虚拟代理对象,等用户真正需要访问对象的属性时,才向数据库发出SQL语句获得真实对象。
下面用一个找枪手代考的例子演示代理模式的使用:
|
1
2
3
4
5
6
7
8
9
10
11
12
|
/**
* 参考人员接口
* @author 骆昊
*
*/
public
interface
Candidate {
/**
* 答题
*/
public
void
answerTheQuestions();
}
|
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
/**
* 懒学生
* @author 骆昊
*
*/
public
class
LazyStudent
implements
Candidate {
private
String name;
// 姓名
public
LazyStudent(String name) {
this
.name = name;
}
@Override
public
void
answerTheQuestions() {
// 懒学生只能写出自己的名字不会答题
System.out.println(
"姓名: "
+ name);
}
}
|
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
/**
* 枪手
* @author 骆昊
*
*/
public
class
Gunman
implements
Candidate {
private
Candidate target;
// 被代理对象
public
Gunman(Candidate target) {
this
.target = target;
}
@Override
public
void
answerTheQuestions() {
// 枪手要写上代考的学生的姓名
target.answerTheQuestions();
// 枪手要帮助懒学生答题并交卷
System.out.println(
"奋笔疾书正确答案"
);
System.out.println(
"交卷"
);
}
}
|
|
1
2
3
4
5
6
7
|
public
class
ProxyTest1 {
public
static
void
main(String[] args) {
Candidate c =
new
Gunman(
new
LazyStudent(
"王小二"
));
c.answerTheQuestions();
}
}
|
说明:从JDK 1.3开始,Java提供了动态代理技术,允许开发者在运行时创建接口的代理实例,主要包括Proxy类和InvocationHandler接口。下面的例子使用动态代理为ArrayList编写一个代理,在添加和删除元素时,在控制台打印添加或删除的元素以及ArrayList的大小:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
import
java.lang.reflect.InvocationHandler;
import
java.lang.reflect.Method;
import
java.util.List;
public
class
ListProxy<T>
implements
InvocationHandler {
private
List<T> target;
public
ListProxy(List<T> target) {
this
.target = target;
}
@Override
public
Object invoke(Object proxy, Method method, Object[] args)
throws
Throwable {
Object retVal =
null
;
System.out.println(
"["
+ method.getName() +
": "
+ args[
0
] +
"]"
);
retVal = method.invoke(target, args);
System.out.println(
"[size="
+ target.size() +
"]"
);
return
retVal;
}
}
|
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
import
java.lang.reflect.Proxy;
import
java.util.ArrayList;
import
java.util.List;
public
class
ProxyTest2 {
@SuppressWarnings
(
"unchecked"
)
public
static
void
main(String[] args) {
List<String> list =
new
ArrayList<String>();
Class<?> clazz = list.getClass();
ListProxy<String> myProxy =
new
ListProxy<String>(list);
List<String> newList = (List<String>)
Proxy.newProxyInstance(clazz.getClassLoader(),
clazz.getInterfaces(), myProxy);
newList.add(
"apple"
);
newList.add(
"banana"
);
newList.add(
"orange"
);
newList.remove(
"banana"
);
}
}
|
说明:使用Java的动态代理有一个局限性就是代理的类必须要实现接口,虽然面向接口编程是每个优秀的Java程序都知道的规则,但现实往往不尽如人意,对于没有实现接口的类如何为其生成代理呢?继承!继承是最经典的扩展已有代码能力的手段,虽然继承常常被初学者滥用,但继承也常常被进阶的程序员忽视。CGLib采用非常底层的字节码生成技术,通过为一个类创建子类来生成代理,它弥补了Java动态代理的不足,因此Spring中动态代理和CGLib都是创建代理的重要手段,对于实现了接口的类就用动态代理为其生成代理类,而没有实现接口的类就用CGLib通过继承的方式为其创建代理。
151、Spring中自动装配的方式有哪些?
答:
- no:不进行自动装配,手动设置Bean的依赖关系。
- byName:根据Bean的名字进行自动装配。
- byType:根据Bean的类型进行自动装配。
- constructor:类似于byType,不过是应用于构造器的参数,如果正好有一个Bean与构造器的参数类型相同则可以自动装配,否则会导致错误。
- autodetect:如果有默认的构造器,则通过constructor的方式进行自动装配,否则使用byType的方式进行自动装配。
说明:自动装配没有自定义装配方式那么精确,而且不能自动装配简单属性(基本类型、字符串等),在使用时应注意。
152、Spring中如何使用注解来配置Bean?有哪些相关的注解?
答:首先需要在Spring配置文件中增加如下配置:
|
1
|
<context:component-scan base-
package
=
"org.example"
/>
|
然后可以用@Component、@Controller、@Service、@Repository注解来标注需要由Spring IoC容器进行对象托管的类。这几个注解没有本质区别,只不过@Controller通常用于控制器,@Service通常用于业务逻辑类,@Repository通常用于仓储类(例如我们的DAO实现类),普通的类用@Component来标注。















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









