







索引
保证数据完整性。
关注索引的两个点:树和有序(树可以定位索引的起点,有序可以定位索引的终点)
- 1.每个表都是一个索引组织表(集群表)
- 以主键来组织的一个表
- 主键索引
- 2.其他索引都是二级索引
- 每个二级索引上都有主键列
- 3.对于每个唯一约束,系统会自动在这个约束上建一个唯一索引!
- 建立外键时,也会自动建立外键索引!
eg:建立一张表:
> create table t2(id int,name varchar(20),bir_th data, constraint primary key (id),constraint unique (name));
#对id列主键约束/id列作为主键,name列作唯一约束
> show create table t2 \G #看t2表建立时的语法
> show index from t2; #显示t2表的索引
> insert into t2 values(1,'skj','2011-11-12');
如果插入的新数据id列或者name列与已有的值相同,就不允许建立!!
> create table t3(id int,name varchar(20),bir_th data, constraint primary key (id),constraint foreign key (name) references t2 (name));
#给新建的t3表的name列建立外键索引,到t2表的name列。给外表t3插入数据时,插入的name列的值必须是主表t2里已经存在的!!
对主表做delete时,外表是有影响的;
对主表update时,外表也是有影响的。
PS:级联删除:
删除主表的数据时,关联的从表数据也删除,则需要在建立外键约束的后面增加on delete cascade 或on delete set null,前者是级联删除,后者是将从表的关联列的值设置为null。
在主表删除一行数据并且从表有对主表的引用时:
- ①restrict:系统不允许这个删除操作。
- ②cascade:顺带着也会删除从表上面引用的那些数据行。
- ③set null:主表删除时,从表上面引用的那些数据行外键值会置空。
- ④no action:主表随便删,对从表不作任何访问。
一般将外键消灭,因为批量导入数据的时候要大量访问主表,而且会锁主表。
索引的功能:提高访问的速度
- 通过索引访问表的特点:
- 1.通过扫描索引,找到我们要访问的行
- 2.需要几行,访问几行
- 全表扫描:
- 1.访问所有的行,使用条件过滤掉不满足条件的行
- 2.过滤的数据,就是额外消耗的资源
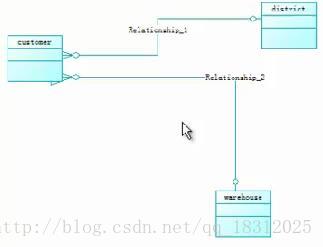
customer表引用了district表(区域表)和warehouse表(仓库):
select c.c_first,c.c_last,c.c_city,o.o_id,o_entry_d
from customer c,orders o
where o.o_d_id=c.c_d_id and o.o_w_id=c.c_w_id and o.o_c_id=c.c_id and c.c_id=1 and c_w_id=1;select …
from 主表,外表
where 主表.主键=外表.外键(主外键关联条件)
and 主表的约束条件 | 外表的约束条件
没加 c_w_id=1 时 SQL的执行计划:

可以看到,走customer表时,没有走索引,而且访问的行巨大,必然执行起来慢。
explain 中id大的先执行,相同的按顺序执行

(因为customer表是三个列作主键索引。而我们只用了一个列,所以,再加一个试试)
加了 c_w_id=1 后:

很明显rows的值变小了很多,再执行,发现执行速度变快了好多!
使用索引的几个最经典的场合
- 1.有where条件(select、update、delete)
- 2.表连接(主键本身有索引,外键本身有索引)
- 3.去除排序
表连接模型
其中一个表上总有严格的约束条件,这个表作为整个SQL的起点
针对这个模型,我们的索引优化规则:
- 1.严格约束条件( where )要走索引
- 2.主外键走索引
多列索引使用规则
- 1.前导列必须被使用,出现在where条件中
- 2.后面的列要起作用,前面的列必须出现在where条件中(空列,5.5和5.6不一样,5.6不害怕有空列)
多列索引的致命弱点
- where… and条件中,中间不能有空列(不然后面的条件不会成为索引条件,而是成为前面条件索引出的表的过滤条件)
- 低效索引执行起来很糟糕,建立的时候尽量将选择性高(cardinality)的列放到前面(5.6)
多表连接书写方法
select …
from …
where 主外键关系 and 限制条件 //交易系统来说,总是访问少量的数据
group by
having
order by
注意:一个sql,先执行from…where !!
作业:写出下面的SQL,审核索引,建立合适的索引
1、某一个用户所有的订单信息
SELECT c.c_first,c.c_last,c.c_cicy,c.c_credit,o.o_id,o.o_entry_id
FROM customer c,orders o
WHERE c.c_id=o.o_c_id AND c.c_d_id=o.o_d_id AND c.c_w_id=o.o_w_id AND c.c_first='5QFf7iBCexBVLSad' AND c.c_last='BARBARBAR';然后explain看执行计划

发现改善了很多。
2、某一个用户所有的订单详情
3、某一个用户在某个仓库所有的订单以及订单详情
4、某一个地区的用户所有的订单和订单详情
5、某一个商品的库存信息
6、某一商品在某一仓库的商品信息
7、某一个物品在某一仓库的库存信息
8、某一个用户购买某一个商品的订单信息
建索引的前提:列的唯一值(基数 cardinality)数量足够高
在一个列上建立索引的几个必备条件:
- 1.主键,唯一键,外键 必须建立索引。
- 2.列上有where条件。
- 3.列的选择性很高,基数很高,唯一值的数量很高。
- 4.参考执行计划。
MySQL统计信息有哪些
- ①表的行数
- ②索引列的基数
建索引:
alter table customer add index i_customer_first on customer(c_first);处理糟糕的SQL流程
- 1.抓取SQL,格式化SQL(美化),关注from where条件,主外键关系
- 2.看执行计划,主外键关联(!!!),严格限制条件,是否有全表扫描和低效索引
- 3.查看索引建立情况
SQL执行过程
- 1.io:io资源
- 糟糕的SQL
- 2.内存读写:占cpu资源,cpu会高
- 糟糕的SQL
- 3.用户线程空间内排序,分组聚合:io,一般很小
- 配置参数过低
- 4.网络传送:网络资源
糟糕的SQL会导致发生的事情
- 1.全表扫描
- 2.低效索引
多列索引
假如有三个列,按第一个列排序,第一列值相同的按第二列排序,第二列相同的按第三列排序,所以多列索引只有第一列是有序的!索引将选择性高的放到第一列!
多列索引的高效使用
- 1.where条件中必须有多列索引的第一个列;
- 2.尽量将cardinality(基数)高的放到前面,否则索引本身的效率不高,但是不影响表的访问效率;
- 3.索引的where条件必须是and.
多列索引的误区
有时使用a列作为where条件,有时用b列,有时用c列,有时用ac,有时用bc…问:怎样建索引?
错误方法:建立abc索引,这样只是对a做了索引!!
正确做法:ac建一个,bc建一个,c建一个,建立这三个即可。
索引访问表的效率:索引访问的效率+表的访问效率
使用索引去除排序例子
对下面的sql添加了一条索引,大大提高了查询速度:
alter table customer add index (c_id);
使用索引去除排序:
- 1.改写SQL,改写order by 列(与开发商量)
- 2.增加索引,配合 force hints 强制走排序索引
使用索引去除排序的应用场景
- 1.产生极大的数据量的排序,造成严重sort_merge_passes
- 2.不能通过增加sort_buffer_size来解决
- 3.尽量不要使用索引解决排序问题(有坑,可以不进行排序,但是过滤数据时可能会大大降低效率,产生全表扫描),而要使用索引来解决过滤数据的问题
聚合操作
在group by 分组列上怎样来消除分组聚合产生的排序?
答:在分组的列上建立索引,来消除分组聚合产生的排序行为



(重点!难点!)加order by null!!


- use index() #建议走哪个索引
- force index() #强制走哪个索引
- ignore index() #忽略走哪个索引
新建索引列里面,包括主键列。
覆盖索引
覆盖索引是select的数据列只用从索引中就能够取得,不必读取数据行,换句话说查询列要被所建的索引覆盖。

explain 时,最后的那列 useing index 说明使用了覆盖索引!
使用覆盖索引的情形:
select、group by、order by、having、where 的列都在索引里面,不会回表,资源消耗小。
高效使用覆盖索引
同时满足过滤和覆盖索引:where条件中要包括索引的第一个列!(大幅提升性能!)
覆盖索引一个很大的适用场合(技巧)
- 从一个表中取5%以下的数据时,走索引比较好。因为通过索引要回表,效果不好。
- 从一个列非常多的大表中取大量行,但是少数列。走索引会回表,消耗大量资源,全表扫描和走索引类似,消耗大量资源,取少量数据优先走索引。
- 覆盖索引的索引很小,覆盖索引不回表。
索引的功能
- 1.where 条件过滤数据
- 2.表连接
- 3.解决order by
- 4.解决group by
- 5.使用覆盖索引,解决回表和大表的问题
useing where ,usering index condition ,useing index
- (1)useing index 说明使用覆盖索引
- (2)useing where 说明访问了表
注意:一二同时出现,说明使用了覆盖索引,useing where不起作用!
- (3)usering index condition:本来在server层过滤的索引条件,下压到引擎层过滤,引擎优化了对表的访问,提高性能
- (4)icp(index condition pushdown,索引条件下压)的使用场合:
- ①二级索引
- ②where条件中包含二级索引的多个列条件,但一定包含二级索引的前导列
- ③这是5.6新特性,效果明显(不害怕有空列)
select distinct e.c_d_id from customer e;DISTINCT去重,访问全表,删除相同的行,隐含着排序,消耗资源。
解释5.6在多列索引中为什么不害怕中间有空列,5.5版本中害怕有空列。
5.5和5.6多列索引中,5.6不害怕中间有空列,5.5不仅仅害怕空列,还害怕非=号出现在前面的列中。
select * from customer where c_w_id<2 and c_id<5 and c_first like 'ab%';//只能将第一个列压入select * from customer where c_w_id=1 and c_id<5 and c_first like 'ab%';//可以压入两个列5.5中多列索引使用的限制很多,5.6解决了这个问题(icp)
5.5中最好将选择性最强的列放在最前面,但是要注意这个列必须被经常使用到!
索引失效的情况
- 1)没有查询条件,或者查询条件没有建立索引
- 2)在查询条件上没有使用引导列
- 3)查询的数量是大表的大部分,应该是30%以上
- 4)索引本身失效
- 5)查询条件使用函数在索引列上,或者对索引列进行运算,运算包括(+-*/!等)。
explain select * from customer where upper(c_first)='ABC'; #全表扫描
explain select * from customer where c_w_id-1<2;
#全表扫描- 6)对小表查询
- 7)提示不使用索引
- 8)统计数据不真实
- 9)CBO计算走索引花费过大的情况;访问的表过小,使用全表扫描的消耗小于使用索引。
- 10)隐式转换导致索引失效。这一点应当引起重视,也是开发中经常会犯的错误。由于表的字段tu_mdn定义为varchar
- 11)①<> 不等于,特别容易不走索引 ②单独的>,< (有时会用到,有时不会)
- 12)like “% ” 百分号在前
[大于小于like都属于 模糊匹配 ~] - 13)表没分析
- 14)单独引用复合索引里非第一位置的索引列
- 15)字符型字段为数字时在where条件里不添加引号
- 16)对索引列进行运算,需要建立函数索引
- 17)not in,not exist
- 18)当变量采用的是times变量,而表的字段采用的是date变量时,或相反情况
索引失效出现的坑
1、select/delete/update,没有where条件只能全表扫描
往往是误写
delete from customer;
update customer set c_first='abc';2、where条件上没有索引
- show index
- explain
3、多列索引没有被正确使用,因为where条件中没有写前导列(前缀列、引导列)
- 4、通过索引访问的数据量过大,超过30%(主键索引除外,主键不怕访问大数量)
- 5、索引本身失效
- 6、where条件中列名字上不能有任何的计算:函数、+-*/等等,列名字上必须非常干净
explain select * from customer where upper(c_first)='ABC'; #全表扫描
explain select * from customer where c_w_id-1<2;
#全表扫描- 7、提示忽略索引
explain select * from t2 ignore index (i_t2_name) where name like 'xkj'; 8、统计信息
mysql针对应用发送过来的SQL需要进行解析(parse)
解析步骤- 1、将这个SQL所有的执行路径列出来
- 2、挑选一个合适执行路径,这个执行路径的挑选有两种方式
- ①RBO(rule base optimizer),基于规则的挑选方式(对开发的要求较高,对SQL的书写要求较高)
- ②CBO(cost base optimizer),对于开发的要求不高,主要依靠统计信息
===RBO:
select ...
from customer c,orders o,order_line ol
where ...
and c like c.c_first = 'abc'
and o.status like 'valid';①表的连接顺序,按照书写顺序;
②对于有严格限制条件的表,顺序提到最前面;
③对于有多个限制条件的表,第一个表的限制条件为准;
④限制条件优先考虑=,like放在=号的后面
表的连接顺序:o c ol
===对于CBO:
①先根据规则库,过滤掉肯定不行的路径;
②对于可能行的执行路径,计算每一个执行路径的成本;
③选择一个最小的成本的路径作为执行计划。
===cbo解析的时候会用到:
①数据字典
②统计信息:表的行数、索引列的选择性(card)
③(不好的地方)mysql没有记录列值的倾斜程度(列值分布 直方图)(平均每个值占多少行)
=====手工修改rows和card统计信息,引导mysql走索引
①手工收集
analyze table tpcc1000.customer;
②没有手工收集则会自动收集
③自动存储:
innodb_stats_persistent=on
④变化量大的情况下,自动收集
innodb_stats_auto_recalc=on #则是开启了自动收集
innodb_stats_persistent_sample_pages
innodb_stats_sample_pages
⑤手工修改统计信息的rows和card(不建议)
计算一个列上的唯一值的数量以及数值
mysql5.6版本面对数据倾斜:
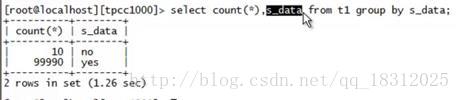
图中,发生了严重的数据倾斜。会宕机。
计算表和索引的大小:
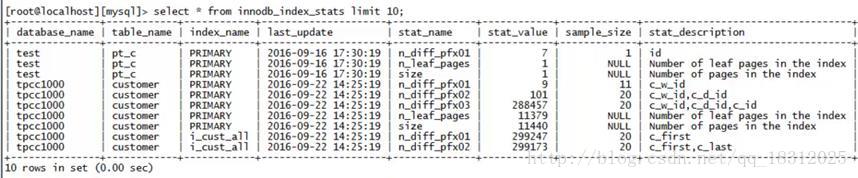
如上图, 对于pt_c 表,stat_name里的size=1代表只占一个数据页;
对于customer表,stat_name 里面的size=11440个数据页,1440*16K =表的大小;
n_leaf_pages是叶子节点,size-n_leaf_pages=树高。
- 9、隐式转换导致索引失效。
这一点应当引起重视,也是开发中经常会犯的错误。
由于表的字段tu_mdn定义为varchar2(20),但在查询时把该字段作为number类型以where条件传给Oracle,这样会导致索引失效。
错误的例子:select * from test where tu_mdn=13333333333;
正确的例子:select * from test where tu_mdn=’13333333333’;数字列,不害怕隐式类型转换
字符列,非常害怕隐式类型转换
explain select * from customer where c_first = 123;易踩的坑:
①存储数字的列被定义成了字符串列
②存储日期时间的列被定义成了字符串列
- 10、
① <>,绝大部分情况下索引失效
explain select * from t1 where s_data <> 'yes';
explain select * from customer where c_id <> 10; ② 单独的>,<,(有时会用到,有时不会)
explain select * from customer where c_id > 10;
explain select * from customer where c_id > 10000;- 11、like “%_” 百分号在前.
explain select * from t1 where s_data like 'no%';not like效果不好,不管是%放在后面还是前面
- 12、表没分析
- 13、not in ,not exist.很多时候不走索引
explain select * from customer where c_id not in (1,2,3,4);
explain select * from customer where c_id in (1,2,3,4);
explain select * from t1 where s_data not in ('yes');
explain select * from t1 where s_data not in ('no');- 14、当变量采用的是times变量,而表的字段采用的是date变量时.或相反情况。
explain select * from orders where o_entry_d = cast('2011-01-01 12:30:30' as time);
explain select * from orders where o_entry_d = cast('2011-01-01 12:30:30' as date);- 15、B-tree索引 is null , is not null,处理的不是很好,因此要注意非空这个坑
explain select * from stock where s_dist_01 is null;
explain select * from stock where s_dist_01 is not null;















 665
665

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











