







 本文介绍了如何使用Spark的StreamingQueryManager进行流查询的管理,包括添加和移除Listener以获取批次处理详情。重点讨论了StreamingQuery对象的使用,以及通过 StreamingQueryManager 获取和监控流查询状态的方法,如使用lastProgress()和status() API,以及通过附加StreamingQueryListener进行异步监控。
本文介绍了如何使用Spark的StreamingQueryManager进行流查询的管理,包括添加和移除Listener以获取批次处理详情。重点讨论了StreamingQuery对象的使用,以及通过 StreamingQueryManager 获取和监控流查询状态的方法,如使用lastProgress()和status() API,以及通过附加StreamingQueryListener进行异步监控。
管理流查询
流查询的管理操作主要是类是StreamingQueryManager类。该对象可以通过SparkSession获得,预留的主要操作如下:
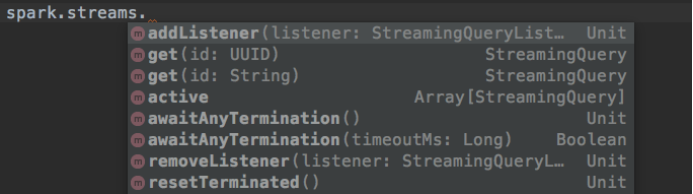
最最重要的就是增加和移除Listener,然后供我们获取每个批次处理的数据具体信息。可以通过listener获取的信息如下:
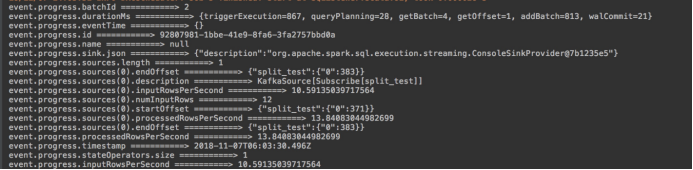
StreamingQuery对象在查询启动的时候被创建,可以用来监控管理查询,该对象也可以按照上面所说的方式通过StreamingQueryManager的get方法来获得,前提是先保存了查询的UUID或者ID。
该类主要有四个实现类(StreamingQueryWrapper,),常用的实现类是StreamingQueryWrapper。

可以使用StreamingQuery对象对流查询做的操作如下:
val query = df.writeStream.format("console").start() // get the query object
query.id // get the unique identifier of the running query that persists across restarts from checkpoint data
query.runId // get the unique id of this run of the query, which will be generated at every start/restart
query.name // get the name of the auto-generated or user-specified name
query.explain() // print detailed explanations of the query
query.stop() // stop the query
query.awaitTermination() // block until query is terminated, with stop() or with error
query.exception // the exception if the query has been terminated with error
query.recentProgress // an array of the most recent progress updates for this query
query.lastProgress // the most recent progress update of this streaming query在同一个sparksession中,可以启动任意数目的查询。他们会以共享集群资源的形式并行执行。可以通过sparkSession.streams()来获取StreamingQueryManager,其可以用来管理当前活跃的查询。
val spark: SparkSession = ...
spark.streams.active // get the list of currently active streaming queries
spark.streams.get(id) // get a query object by its unique id
spark.streams.awaitAnyTermination() // block until any one of them terminates
监控流查询
有两个API用于监控和调试查询 - 以交互方式和异步方式。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3056
3056











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









