







Particle Swarm Optimization
PSO是一种基于种群的随机优化技术,由Eberhart和Kennedy于1995年提出。主要模仿昆虫、兽群、鸟群和鱼群等的集群行为。
以鸟群觅食为例,粒子群算法中有粒子、粒子群、粒子的位置及飞行速度、最优解、粒子的适应度、最优粒子、粒子的个体经验及群体经验,它们可以类比于一只鸟、鸟群、鸟的位置与飞行速度、食物的位置、鸟与食物位置的距离、离食物最近的鸟、鸟的记忆能和学习能力。
| 粒子群优化算法 | 鸟群觅食 |
|---|---|
| 粒子(问题的一个解) | 鸟(个体) |
| 粒子群 | 鸟群(种群) |
| 粒子的位置与飞行速度 | 鸟的位置与飞行速度 |
| 粒子飞行速度的动态调整 | 鸟的飞行动态 |
| 最优解 | 食物位置 |
| 粒子的适应值 | 鸟与食物位置的距离 |
| 最优粒子(当前最好的解) | 距离食物最近的鸟 |
| 粒子群的邻域拓扑 | 鸟群的信息交互途径 |
| 粒子的个体最优经验与邻域最优经验 | 鸟类的记忆能力与学习能力 |
而粒子群优化算法的重要手段就在粒子位置和速度的更新上,通过不断改变粒子速度从而改变粒子位置让粒子群更加接近最优解的位置。速度的更新与位置的更新都有具体的公式:
v i = v i + c 1 ∗ r a n d ( ) ∗ ( p b e s t i − x i ) + c 2 ∗ r a n d ( ) ∗ ( g b e s t i − x i ) v_i=v_i+c_1 *rand()*(pbest_i-x_i)+c_2*rand()*(gbest_i-x_i) vi=vi+c1∗rand()∗(pbesti−xi)+c2∗rand()∗(gbesti−xi)
x i = x i + v i x_i=x_i+v_i xi=xi+vi
其中i表示粒子的id,rand()是生成(0,1)的随机数,v和x表示粒子的速度和位置,c1和c2为自我学习因子和社会学习因子,pbest为粒子自己的最佳历史位置,gbest是社会中粒子的最佳历史位置。本文中社会代之整个种群,gbest指的就是整个种群中最好的个体位置。
算法流程图:
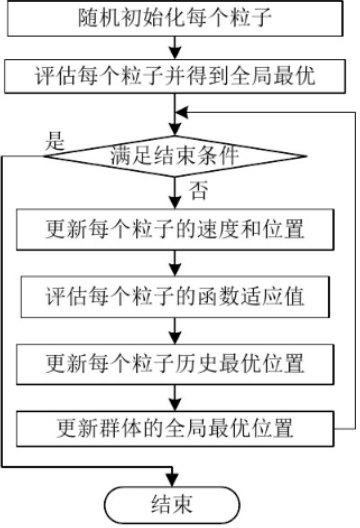
代码实现:
lb,ub分别表示粒子位置的上下限;lv,uv分别表示粒子速度的上下限;n表示种群中粒子个数;D表示粒子的维度;c1和c2表示粒子的自我学习因子和社会学习因子大小;w表示惯性系数;iterator表示迭代次数。
初始化粒子群的速度和位置:
position=lb+(ub-lb)*rand(n,D);
velocity=lv+(uv-lv)*rand(n,D);
定义目标函数,以Rastrigin‘s函数为例:
function f=fun(X) %目标函数
f=20+X(:,1).^2+X(:,2).^2-10*(cos(2*pi.*X(:,1))+cos(2*pi.*X(:,2))); %Rastrigin‘s函数
end
粒子速度更新:
velocity=w.*velocity+c1*rand().*(pbest-position)+c2*rand().*(gbest-position); %更新速度
index=find(velocity>uv | velocity<lv); %速度越界惩罚
velocity(index)=lv+(uv-lv)*rand(1,length(index));
粒子位置更新:
position=position+velocity; %更新位置
完整代码实现(以Rastrigin‘s函数为例):
function [best,gbest]=pso(lb,ub,lv,uv,n,D,c1,c2,w,iterator)
%初始化起始位置和原始速度
position=lb+(ub-lb)*rand(n,D);
velocity=lv+(uv-lv)*rand(n,D);
fit=fun(position);%计算适应度
old_fit=fit; %保留适应度以便更新最优历史
[best,location]=min(fit); %计算全局最优结果
pbest=position; %初始最优历史位置
gbest=position(location,:); %初始化全局最优位置
history=zeros(1,iterator);
history(1)=best; %保留全局的历史最优值
old_best=best;
ite=1; %初始化迭代器
temp=(w-0.1)/iterator;
while ite<iterator
velocity=w.*velocity+c1*rand().*(pbest-position)+c2*rand().*(gbest-position); %更新速度
index=find(velocity>uv | velocity<lv); %速度越界惩罚
velocity(index)=lv+(uv-lv)*rand(1,length(index));
position=position+velocity; %更新位置
fit=fun(position); %重新评估
[best,location]=min(fit);
index=find(fit-old_fit<0); %寻找非负优化粒子
pbest(index,:)=position(index,:); %更新历史最优
if best<old_best
gbest=position(location,:); %更新全局最优位置
end
old_fit=fit; %保存适应度
ite=ite+1;
if best<history(ite-1)
history(ite)=best;
else
history(ite)=history(ite-1);
end
old_best=best;
w=w-temp;
end
best=history(end);
function f=fun(X) %目标函数
f=20+X(:,1).^2+X(:,2).^2-10*(cos(2*pi.*X(:,1))+cos(2*pi.*X(:,2))); %Rastrigin‘s函数
end
plot(history,'linewidth',3);
end
取参数执行:
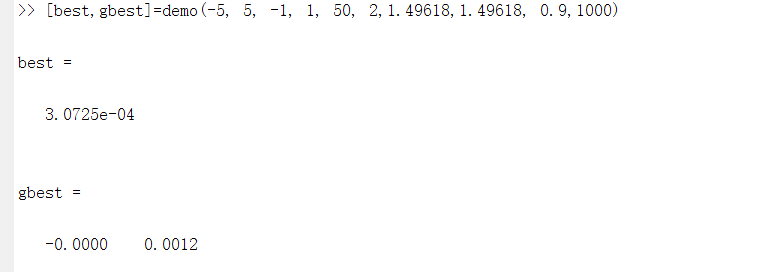
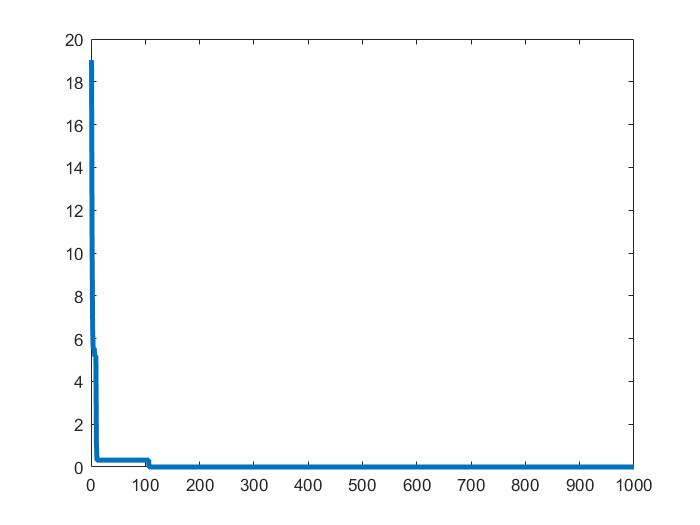


















 701
701

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











