







参考翻译:https://blog.csdn.net/weixin_42164269/article/details/80651752
摘要
提出TVNet,一种新的端到端可训练神经网络,直接从数据中学习光流特征。其包含了一个特定的光流解算器,即TV-L1方法,并通过将其优化迭代展开为神经层来初始化。TVNet可以直接使用,无需任何额外的学习。在特征提取时间上,比所有的比较方法都有更好的准确率,同时在特征提取时间上也与最快的方法匹敌。
1、介绍
主要贡献:
- 我们开发了一个新颖的神经网络,通过将TV-L1方法的迭代展开到特定的神经层,从而学习视频中的动作。这个网络被称为TVNet,它是经过很好的初始化而且是端到端可训练的。
- 尽管被初始化为一个特定的TVNet架构,但我们提出的TVNet可以进一步微调,以学习更丰富、更以任务为导向的特征,而不是标准的光流。
- 我们的TVNet比其他动作表示网络(例如,TV-L1 [ 42 ],FlowNet2.0 [ 18 ])和三维的卷积神经网络 [ 36 ],在两个动作识别基准上获得了更好的精度,也就是在UCF101上的72.6%和在HMDB51上95.4%。
2、相关工作
见原文
3、符号和背景
3.1、符号
一个视频序列可以写成三个参数的函数, I t ( x , y ) I_t(x,y) It(x,y),其中x,y指数空间维度,t代表时间维度。Ω表示一帧内的所有像素坐标。函数值 I t ( x , y ) I_t(x,y) It(x,y)对应于第t视频帧中位置x=(x,y)的像素亮度。x点可能会随时间在整个视频帧中移动,而光流则是跟踪相邻帧之间的这种位移。我们用 u t ( x ) = ( u 1 t ( x ) , u 2 t ( x ) ) u^t(x)=(u^t_1(x),u^t_2(x)) ut(x)=(u1t(x),u2t(x))表示点x从时间t到下一帧t+1的位移。在没有歧义的情况下,我们省略了来自 u t ( x ) u_t(x) ut(x)的上标t和/或参数x。
3.2、TV-L1方法
主要公式:
m
i
n
u
(
x
)
,
x
∈
Ω
∑
x
∈
Ω
(
∣
∇
u
1
(
x
)
∣
+
∣
∇
u
2
(
x
)
∣
+
λ
∣
ρ
(
u
(
x
)
)
∣
)
min_{u(x),x∈Ω}\sum_{x∈Ω}(|∇u_1(x)|+|∇u_2(x)|+\lambda|ρ(u(x))|)
minu(x),x∈Ωx∈Ω∑(∣∇u1(x)∣+∣∇u2(x)∣+λ∣ρ(u(x))∣)
其中第一项
∣
∇
u
1
∣
+
∣
∇
u
2
∣
|∇u_1|+|∇u_2|
∣∇u1∣+∣∇u2∣对应平滑条件,第二项
ρ
(
u
)
ρ(u)
ρ(u)对应著名的亮度一致性假设[42]。特别的,在它平移到下一帧轻微不同的位置之后,x点的亮度假设保持相同,也就是
I
0
(
x
+
u
)
≈
I
1
(
x
)
I_0(x+u)≈I_1(x)
I0(x+u)≈I1(x)。因此第二项中
ρ
(
u
)
=
I
1
(
x
+
u
)
−
I
0
(
x
)
ρ(u)=I_1(x+u)-I_0(x)
ρ(u)=I1(x+u)−I0(x)为惩罚亮度变化,因为函数
I
1
(
x
+
u
)
I_1(x+u)
I1(x+u)对u是非线性的,Zach等人[42]通过在初始位置u^0的泰勒展开式计算亮度差异 ρ(u),产生
ρ
(
u
)
≈
∇
I
1
(
x
+
u
0
)
(
u
−
u
0
)
+
I
1
(
x
+
u
0
)
−
I
0
(
x
)
ρ(u)≈∇I_1(x+u^0)(u-u^0)+I_1(x+u^0)-I_0(x)
ρ(u)≈∇I1(x+u0)(u−u0)+I1(x+u0)−I0(x)上面给出了原始问题的一阶近似,并将其线性化为更简单的形式。此外,作者还引入了一个辅助变量v来引入原始问题的凸关系:
m
i
n
{
u
,
v
}
∑
x
∈
Ω
(
∣
∇
u
1
(
x
)
∣
+
∣
∇
u
2
(
x
)
∣
+
∣
u
−
v
∣
2
/
2
θ
+
λ
∣
ρ
(
u
(
x
)
)
∣
)
min_{\{u,v\}}\sum_{x∈Ω}(|∇u_1(x)|+|∇u_2(x)|+|u-v|^2/2θ+\lambda|ρ(u(x))|)
min{u,v}x∈Ω∑(∣∇u1(x)∣+∣∇u2(x)∣+∣u−v∣2/2θ+λ∣ρ(u(x))∣)
非常小的θ可以迫使最小化的时候u和v相等。通过迭代更新u和v最小化目标。优化的具体操作展示在算法1,这里
p
1
p_1
p1和
p
2
p_2
p2是对偶的光流向量场。

算法理解1:算法里的核心挑战是逐像素的计算梯度,散度,扭曲。数值估算的细节如下所示
梯度-1. 图
I
1
I_1
I1的梯度是由中心差计算的: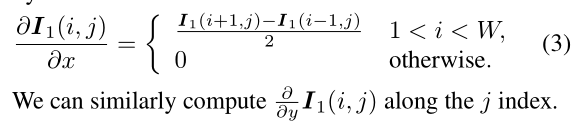
梯度-2. 光流u的每个分量的梯度是通过正向差计算的:
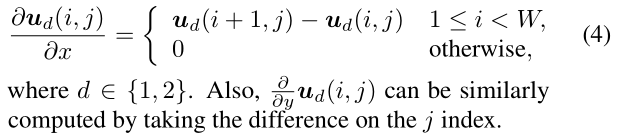
散度. 对偶变量p的散度是通过反向差来计算的:
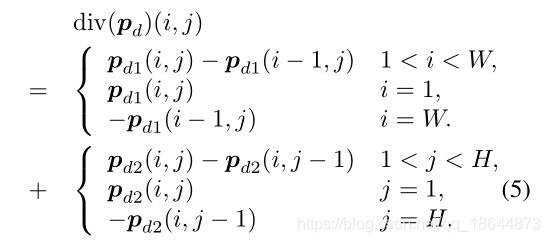
另一个像素级的估计是亮度
I
1
(
x
+
u
0
)
I_1(x+u_0)
I1(x+u0)。它通常是通过在最初的流场
u
0
u_0
u0中通过双线性插值来获得帧
I
1
I_1
I1的扭曲。
多尺度TV-L1。由于泰勒的展开式被应用于线性化亮度差异,最初的光流场 u 0 u_0 u0应该接近于真实的场u,以确保小的近似误差。为了达到这个目的,近似场 u 0 u_0 u0是由一个多尺度的方案以粗到细的方式得到的。具体地说,在最粗的级别上, u 0 u_0 u0被初始化为0向量,并且算法1的相应输出被应用于下一个级别的初始化。
4、TVNets
TVNet形成的核心思想是模仿TV-L1中的迭代过程,同时将迭代展开到一个层到层的转换中,与神经网络一样。
4.1、网络设计
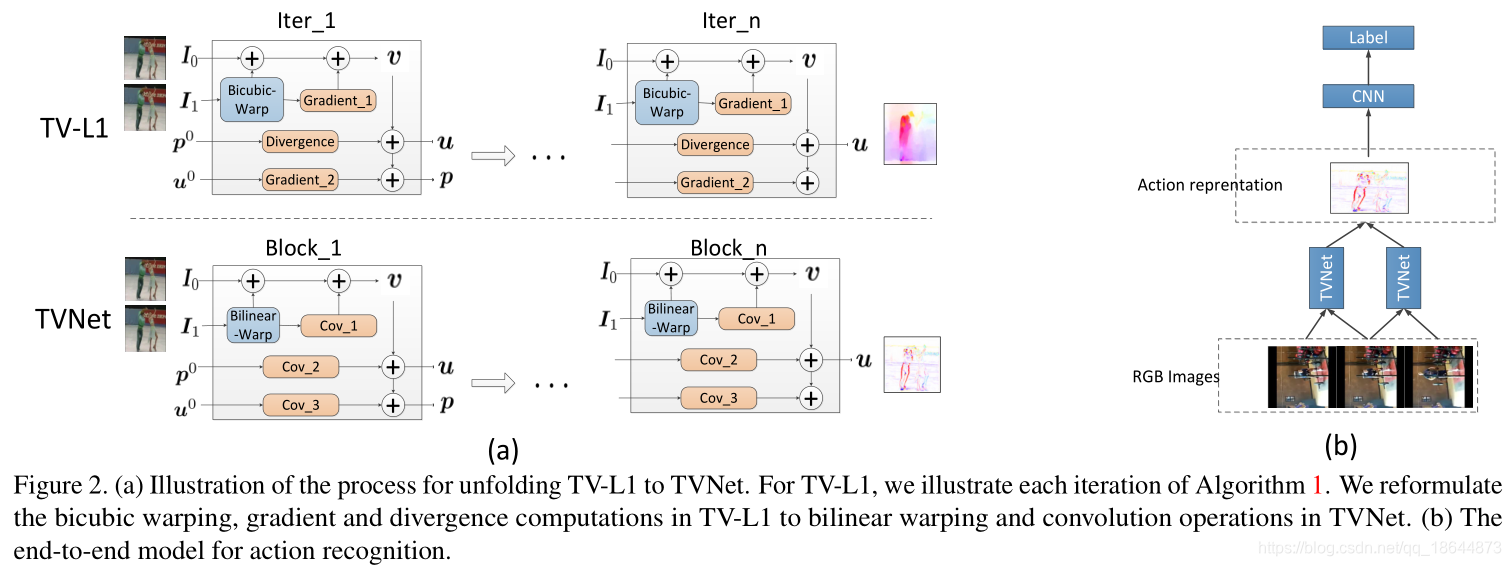
还是看原文吧,后面简述一下…
5、实验
5.2、行为识别
实现细节:正如前面所讨论的,我们的TVNets可以通过一个分类网络连接来建立一个端到端模型来执行动作识别。在我们的实验,我们将BN-Inception network[ 40 ]作为分类模型,由于它的有效性。在初始化过程中,BN-Inception网络通过[39]中引入的跨模技术预先训练了这个网络。
我们从每个视频中抽取6个连续的图像,并为每一对连续的图像提取5个流帧。由此产生的光流的栈被送入了BN-Inception初始网络进行预测。为了训练端到端模型,我们将取样堆栈的批大小设置为128,并将动量设置为0.9,学习率被初始化为0.005。UCF101和HMDB51数据集的学习迭代的最大数量分别被选为18000和7000。在UCF101实验的10000次和16000次迭代之后,我们将学习速率降低了10倍,在HMDB51案例中在4000和6000次迭代后下降。我们只在这个实验中实现了TVNet-50。为了防止过度拟合,我们还进行了corner cropping和scale jittering[ 40 ];TVNets的学习率进一步除以255。
在测试中,从视频的中心和四个角中提取出大量的流场。我们从每个位置抽取25个栈(例如中心和角落),然后水平地翻转,以扩大测试样本。所有取样的片段(总计250个)被喂给了BN-Inception [ 40 ] ,它们的输出是平均预测的。
。。。
6、结论
本文提出了一种新颖的端到端运动表示学习框架,并将其命名为TVNet。特别地,我们将TV-L1方法作为一个神经网络,它以堆叠的帧为输入和输出像流一样的运动特性。对两种视频理解任务的实验结果表明,它在现有的运动表示学习方法上具有优越的性能。在未来,我们将探索更大规模的视频理解任务,以检验端到端运动学习方法的好处。















 2954
2954











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









