







堆
条件:
- 堆是一个完美二叉树;
- 一般实现方式最大堆或最小堆,最大堆指堆中每⼀个节点的值都必须⼤于等于其⼦树中每个节点的值,最小堆相反。
堆的操作
- 添加元素
为了保证堆保持是一个完美二叉树,将新增的元素保存到末尾,然后跟父节点比较,直到实现第二个条件;
- 删除元素
删除最大或做小值时,也就是移除根节点,为了保持完美二叉树,将末尾元素移动到根节点,再向下进行比较找出最大值进行交换,直到实现第二个条件;
堆排序
将原本无须的元素集合排成有序集合;
在堆的操作基础上,进行建堆(添加元素操作),构建一个最大或最小堆,再每次拿出最大或最小值(删除元素操作),从而实现堆排序,构建从大到小或从小到大的有序集合;
堆的应用
一、优先队列
很多语⾔中,都提供了优先级队列的实现,⽐如,Java的PriorityQueue,C++的priority_queue等
场景:高性能定时器
维护一个根据执行时间的最小排序,判断根节点最小的任务时间是否达到,超过或者等于那么就响应定时器,并且从最小堆中移除;例如扫描频次为1秒扫一次,每次只用查看第一个元素是否到达响应时间,不需要遍历任务队列中所有定时任务时间是否需要响应;
二、求TopK
对静态元素求最大K个元素,利用最小堆遍历静态元素,若当前元素大于最小堆根元素则替换根元素;最终遍历结果所剩最小堆的十个元素是最大的十个元素;
三、求中位数
维护一个最大堆跟最小堆;保证俩个堆的个数差不超过2,当超过二时,将根元素移动到元素个数少的堆里;
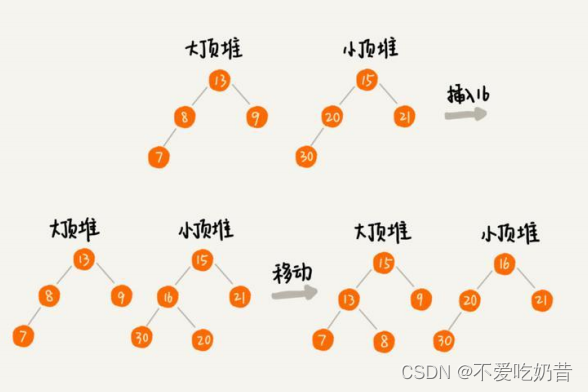
最终中位数存在根元素中;
例子 10亿个搜索关键词的⽇志⽂件,如何快速获取到Top 10最热门的搜索关键词呢
1.先计算10亿条关键词次数;
2.通过最小堆遍历出现次数判断top10的元素;
实现:
- 为了防止内存不能保存10亿个关键词次数;
- 使用散列表将10亿条记录分散到多个区域,再对每个区域的元素求出现次数;也就是遍历2n次算出关键词出现重复次数;
- 最终再遍历一边所有关键词次数,求出Top10的最小堆,即获取到Top 10最热门的搜索关键词;















 4182
4182











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









