









ElasticSearch
1、ElasticSearch学习随笔之基础介绍
2、ElasticSearch学习随笔之简单操作
3、ElasticSearch学习随笔之java api 操作
4、ElasticSearch学习随笔之SpringBoot Starter 操作
5、ElasticSearch学习随笔之嵌套操作
6、ElasticSearch学习随笔之分词算法
7、ElasticSearch学习随笔之高级检索
8、ELK技术栈介绍
9、Logstash部署与使用
10、ElasticSearch 7.x 版本使用 BulkProcessor 实现批量添加数据
11、ElasticSearch 8.x 弃用了 High Level REST Client,移除了 Java Transport Client,推荐使用 Elasticsearch Java API
12、ElasticSearch 8.x 使用 snapshot(快照)进行数据迁移
13、ElasticSearch 8.x 版本如何使用 SearchRequestBuilder 检索
14、ElasticSearch 8.x 使用 High Level Client 以 HTTPS 方式链接,SSL 证书、主机名验证器 各是什么,如何忽略
15、ElasticSearch 8.x 创建父子文档,用Join类型字段以及用has_child、has_parent 检索
16、ElasticSearch如何提高写入效率【面试题,面道既学到】
文章目录
〇、前言
目前万千码友们都面临着一个相当严重的问题,那就是大环境不好,不管是在三五成群的同事们去吃饭的路上,还是下班回家路上的闲唠嗑,都离不开这个话题。大环境不好带来的首要问题就是突然噩耗降临,面临着 裁员 和 失业,这不,截止 2024-06-17 我和陪伴三年的平时嘻嘻哈哈的同事们 say goodbye 了。
于是乎,平时里茶余饭后讨论的话题,不管是八卦还是汽车,砍大山【吹牛皮】还是大长腿的,现在只会弱弱地问一句 “最近你有面试吗?”,这似乎是这段时间来听到的最关心和最耐人寻味的一句问候语了!
我也丝毫不敢懈怠,立马更新了简历,也感谢我的领导 check 我们的简历并给予了很好的改进建议,简历完毕,里面 Boss! Boss! Boss!!!,当然也有 猎聘 和 51job 等,这几天 Boss 几乎被戳烂,成为了我手机上最热门的应用了!
总算是有面试了,本以为自己能轻松应对,也对 ElasticSearch 全文检索了如指掌,毕竟之前写了好多ES相关的博客了,但是在面试官面前几乎 裸奔,一个问题就让我醍醐灌顶,ElasticSearch 如何提高写入效率,当场我的大脑也变成了一台高并发的 ES 服务,疯狂检索答案中!
一、ElasticSearch数据写入方式
ElasticSearch 写入数据有好多种方式,HTTP REST API 、ES 客户端、Logstash、Beats、Bulk API、ES River插件 ,这么多种写入方式大致分为 单条写入 和 批量写入 两种,那不管是 单条发送 还是 批量写入,ElasticSearch 都是会先写入 Buffer(缓存) 中,然后再 Flush 和 Commit,最终写入到 磁盘 中,具体更新流程在下面 【如何实现近实时更新数据】细讲。
那如何能高效数据写入呢?
1.1 Bulk API
- 通过 Bulk API 进行批量写入,基于 Java 的 RestHighLevelClient 客户端进行批量写入实现可移步《BulkProcessor 实现批量添加数据》篇 阅。
1.2 Logstash
- 通过 Logstash 管道写入数据,什么是 Logstash 以及如何搭建可移步《Logstash部署与使用》篇 阅。
1.3 其他方式
其他方式等有应用到再做博客分享。
以上是常用的两种数据写入方式,集群方式看下面【ElasticSearch 集群写入流程】。
二、ElasticSearch 如何实现近实时搜索?

官网注释,基于 ElasticSearch 2.x 版本,有些内容可能过时,但是不影响我们学习底层思想。
2.1 近实时搜索(Near real-time search)?
当文档存储在 ElasticSearch 中时,文档就会被索引,并且在接近实时(1秒)内进行搜索,即 近实时搜索,也就是 动态更新索引,怎样在索引不变的前提下实现倒排索引的更新?
答案是 用更多的索引,通过增加新的补充索引进来,而不是直接重写整个倒排索引,每一个倒排索引都会被轮流查询到,然后对结果进行合并。
点击 【Near real-time search(近实时搜索)】了解更多,细细品味。
2.2 逐段搜索(Per-segment search)?
ElasticSearch 基于 Java 库的 Lucene 引入了逐段搜索的概念。每一段类似于方向索引,在 Lucene 中的 index(索引)意思是 几个段的集合加上一个提交点 ,提交之后会将一个新的段添加到提交点,然后清理缓冲区。
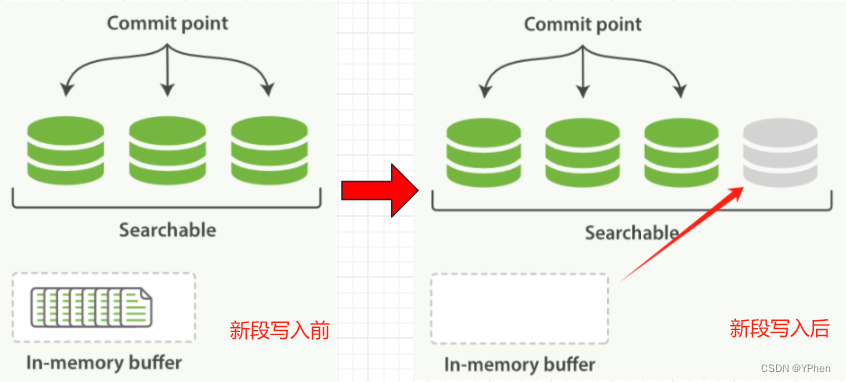
位于 ElasticSearch 和 磁盘之间是文件系统缓存,如上图,图左边是内存索引缓冲区被成功写入新段则如图右边。新段首先写入文件系统缓存性能很快,然后刷新到磁盘则比较消耗性能。不过呢,在缓冲区中的文件是可以其他文件一样打开和读取。
写入和打开新段的过程称为刷新,刷新使自上次刷新以来对索引执行的操作都可用户搜索,可以通过以下方式来控制刷新:
- 配置等待刷新间隔
- 设置 ?refresh 选项
- 调用刷新 API 显式完成刷新(POST _refresh)
默认情况下,ElasticSearch 每秒定时刷新一次索引,但限于过去 30 秒内收到一个或多个搜索请求的索引,这就是 ElasticSearch 近乎实时搜索,文档改变不会立即搜索,但是在一定时间范围内即可见。
2.3 持久化变更(Making Changes Persistent)
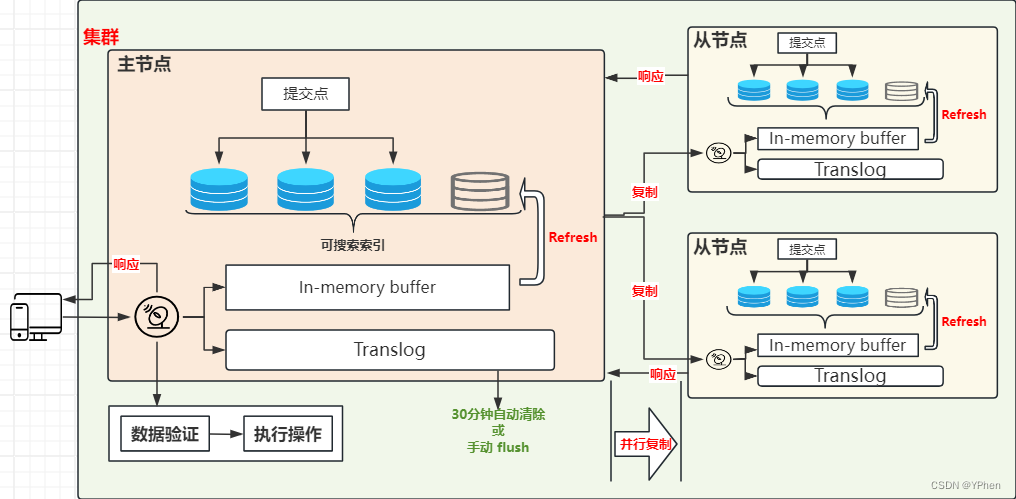
上面提到,ElasticSearch 实现了 近实时搜索,引入了逐段搜索的概念,每次有数据更新是先把数据存在了缓冲区中,是一个索引段,然后把索引段写入到提交点再刷到磁盘中,那如果没有用 fsync 把数据从文件系统缓冲区及时刷到磁盘中,就不能保证在出现异常【比如:断电、服务挂掉、运维 Kill -9】情况下甚至是程序正常退出之后不丢失数据,为了保证 ElasticSearch 能可靠的把变化数据持久化到磁盘,ElasticSearch增加了 translog, 或者叫 事务日志。
通过 translog 来更新数据整体流程如下:
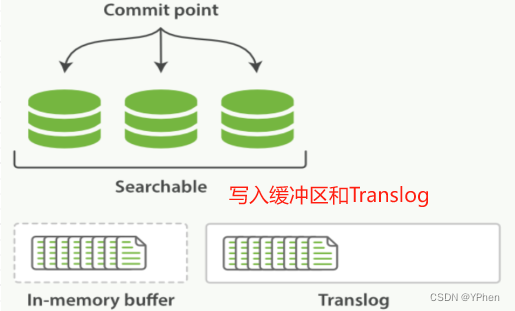
- 一个文档索引写入之后,会先写入到内存缓冲区,并且还会追加到
Translog,如下图 。
- 在刷新(
refresh)完成后,缓存会被清空,但是Translog会保留下来,继续添加文档,还是写入缓冲区中,再次追加到Translog中,如图所示 。
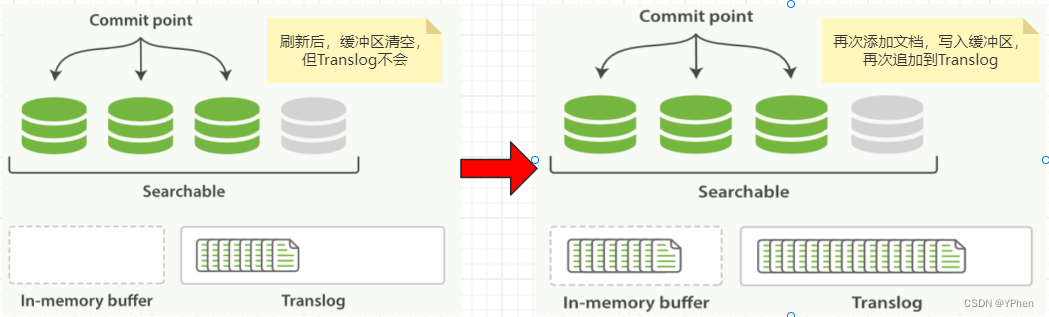
- 刷新(refresh)是从缓冲区(In-memory buffer)刷到一个新的索引段中,分片每秒被刷新一次,且没有
fsync操作 。- 这个段被打开,即可以被搜索 。
- 内存缓冲区被清空 , 但是 Translog 保留,以免异常情况出现。
- 在大刷(
flush)之后,索引段被全量提交,并且清空Translog【清空事务日志】。
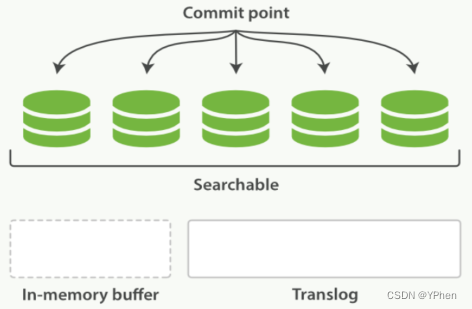
- 每隔一段时间,Translog 变得越来越大,索引被刷新,一个新的 Translog 创建,并且一个全量的提交被执行。
- 所有内存缓冲区的文档写入一个新的段 。
- 缓冲区被清空 。
- 一个提交点写入磁盘 。
- 文件系统缓存通过
fsync被刷新 。- 老的 Translog 被删除 。
Flush API :
在执行一个提交并且截断 Translog 的行为被称为 flush,每 30 分钟被自动刷新(flush),或者在 Translog 太大时也会被刷新,或者也可以 调用 Flush API 来刷新。
#刷新索引
POST /index_name/_flush
#刷新所有的索引并且等待所有的刷新在返回前完成
POST /_flush?wait_for_ongoing
注意:基本上我们很少用手动刷新操作,通常情况下,自动刷新就足够了,除非写入数据量庞大并且写入频率不稳定。
点击 【Making Changes Persistent】了解更多,细细品味。
2.4 段合并(Segment Merging)
到这里,我们都知道了 ElasticSearch 的 近实时搜索 特性,那同时也会面临着一个问题,ElasticSearch 自动每秒会创建一个新的 段,那就会导致一段时间内会有产生大量的 段。每个段会消耗文件句柄、内存和CPU的运行周期,而且每次搜索都会轮流搜索每个段,所以段的暴增会使数据更新变慢,搜索变慢。
ElasticSearch 通过后台段合并 来解决由于短时间内段暴增而导致的性能问题,小的段合并成大的段,大的段再次合并为更大的段,段合并的同时会把那些旧的已删除的文档清除掉。
- 段合并 是 ElasticSearch 后台进行的,并不需要我们过多的去关注,在 ElasticSearch 进行索引和搜索时会自动进行,这个流程如图所示。
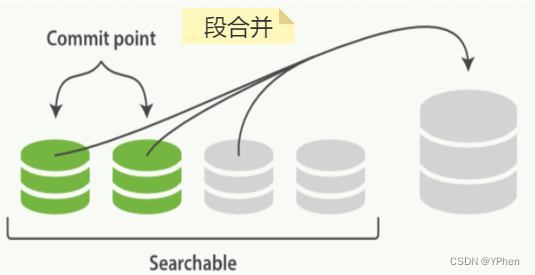
- 当索引的时候,刷新(refresh)操作会创建新的段并打开以提供搜索服务。
- 段合并会选择一些大小相似的段,在后台将小段们合并为一个大段,并且这并不会影响索引和搜索。
- 段删除 是在 段合并 完成之后进行的,一旦段合并结束,老的段就会被删除,看图理解。
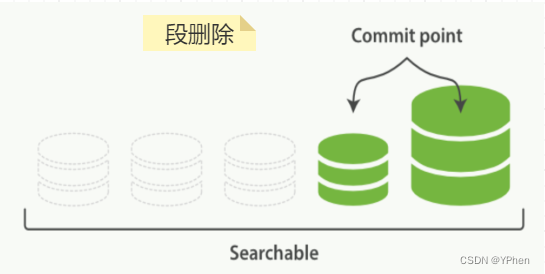
- 合并比较大的段会消耗大量的 IO、CPU 资源,如果频繁一直合并的话会影响搜索性能,所以 ElasticSearch 在默认情况下会对合并进行资源限制,以保证搜索有足够的资源。
三、ElasticSearch 集群写入流程
一般企业内数据实时要求比较高,并且数据量庞大,每小时近千万数据量进来,那单机版的ElasticSearch 肯定是难以支持的,必定是基于高效的集群模式的,下面是 ElasticSearch 官网提供的一张图,清晰明了。
3.1 集群副本
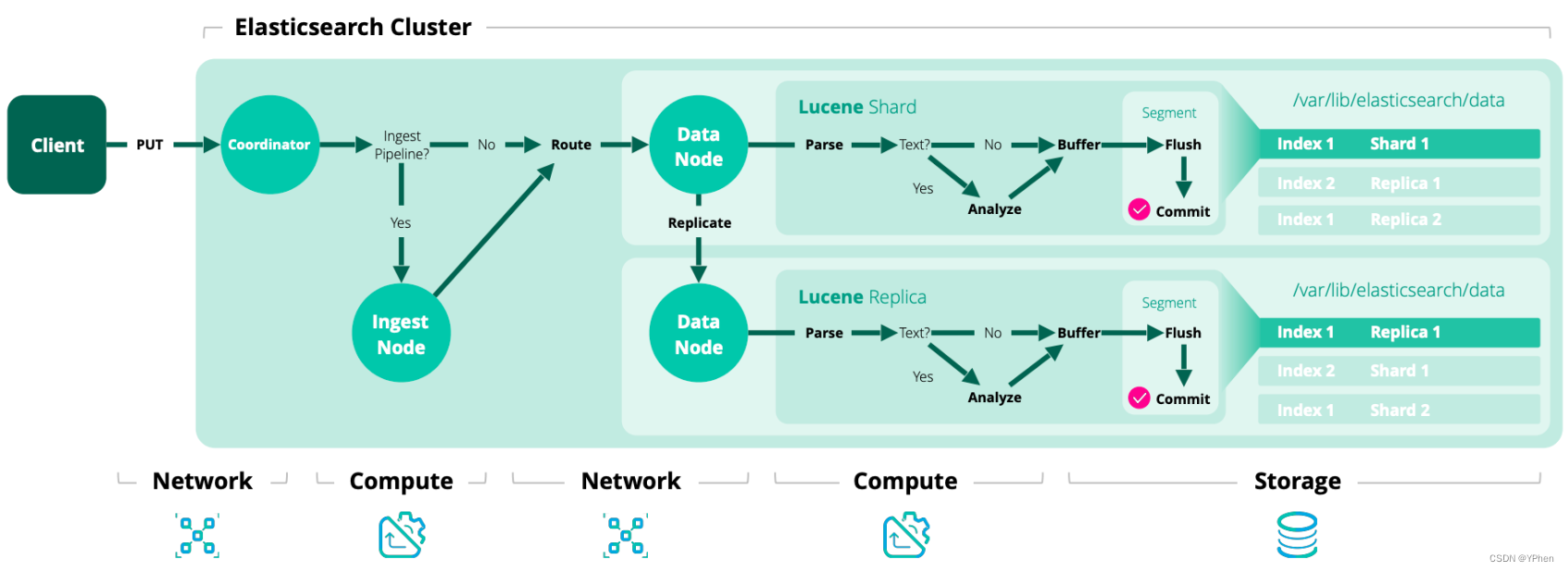
在 ElasticSearch 中每个索引都被划分为多个碎片,每个碎片可以有多个副本,这些副本称之为复制组,那么在添加删除文档则必须要保持同步,否则从一个副本中搜索的结果和从其他副本搜索的结果截然不同,保持副本同步并提供读取操作的过程称之为 数据副本模型 (Data replication model.)。
ElasticSearch 的数据复制模型是基于主备份(Primary-backup)模型,该模型基于复制组中作为主碎片的副本,其他副本称为副本碎片。主碎片是索引操作的入口,负责验证并且确保数据是正确的,一旦主碎片接受索引操作,则主碎片还要负责该操作复制到其他副本。
因为副本可以脱机,所以主副本(主节点)不需要将主副本复制到所有副本,那 ElasticSearch 维护了一个有效副本的列表,被保证已经处理了所有向用户确认的索引和删除操作。
3.2 副本复制流程
主节点的复制流程如下:
- 验证接收到的数据结构无效则拒接写入(Eg:schema不符合) 。
- 在本节点执行操作,即索引或者删除相关文档,也会验证字段和内容,并在需要时拒接写入(Eg:关键字值过长)。
- 把操作转发到当前可同步的每个副本中(多个副本并行操作)。
- 等所有副本成功执行了操作并响应了主节点,主节点才会确认操作成功并返回客户端结果。
注:每个副本也会在本地执行索引操作,也会有一个副本自己的副本。
四、ElasticSearch 写入慢如何优化呢?
4.1 ChatGPT
- 调整 Bulk 请求大小:将大量写入操作合并成一个 Bulk 请求发送到 ElasticSearch。适当增加每个 Bulk 请求中的文档数量可以减少通信开销,提高写入效率,但是要注意不能将 Bulk 请求设置过大,以免超出 ElasticSearch 节点处理能力。
- 优化 Mapping:在大量数据写入之前,确保索引的 mapping 合理,避免使用动态 Mapping,这样可以减少 ElasticSearch 工作量。
- 考虑使用 Refresh Interval:默认情况下,ElasticSearch 在索引数据后会自动刷新,使新写入的数据可搜索。但是如果写入操作很频繁,可以考虑减少刷新操作,以提高写入性能。
- 考虑水平扩展:单个ElasticSearch 无法满足需求,可以考虑通过水平扩展集群来提高写入效率。
- 使用异步写入:考虑使用异步写入方式,将写入操作提交到队列中由后台线程处理。
- 关闭索引刷新:在批量写入之前,可以暂时关闭索引自动刷新功能,等数据批量写入之后再手动执行刷新操作。
4.2 Kimi 给我的答案
- 客户端策略
- 预定义索引映射(Mapping):预先定义好映射可避免 ElasticSearch 写入时动态推断字段类型,提高效率。
- Bulk API:批量操作减少网络开销。
- 并行化:水平扩展,将数据分布到多个工作进程中并行写入。
- 响应过滤:使用 filter_path 参数减少 ElasticSearch 返回响应体大小,减少网络传输时间。
- 保存前汇总:对于频繁更新的操作,可以先在内存中聚合再写入。
- 索引策略
- 调整 Refresh Interval:增加 refresh 间隔可以减少索引过程中的资源消耗,但可能会稍微影响搜索的实时性。
- 使用自动生成的 ID:让 Elasticsearch 自动生成 ID 可以避免检查唯一性,提高写入速度。
- 禁用副本:在批量索引作业期间禁用副本可以提高索引速度,之后再启用副本以保证数据的高可用性。
- 节点策略
- 调整 Indexing Buffer Size:根据需要调整索引缓冲区的大小,以优化内存使用。
- 优化 Translog:调整事务日志的大小,可以在磁盘上创建更大的段,减少刷新操作的频率。
- 操作系统和服务器策略
- 禁用交换(Swapping):确保 Elasticsearch 节点的内存足够,避免因为内存不足而触发交换,影响性能。
- 优化文件系统缓存:确保有足够的 RAM 用于文件系统缓存,以提高 I/O 性能。
- 选择合适的存储类型:使用 SSD 而不是传统的旋转磁盘,或者使用高性能的网络存储解决方案。
- 硬件升级
- 升级硬件:如果硬件性能成为瓶颈,考虑升级服务器硬件,如使用更快的 CPU、更多的 RAM 或 SSD。
- 集群架构
- 合理分配分片:确保分片均匀分布在集群中,避免某些节点负载过高。
- 使用合适的副本策略:根据需要调整副本数量,以平衡写入性能和数据的高可用性。
- 其他策略
- 监控和调优 JVM:确保 JVM 配置得当,避免长时间的 Full GC。
- 合理设计分词器:不合理的分词器设计可能会导致 CPU 计算过多和过度分词,影响写入性能。
五、小结
数据库排行:https://db-engines.com/en/ranking/search+engine
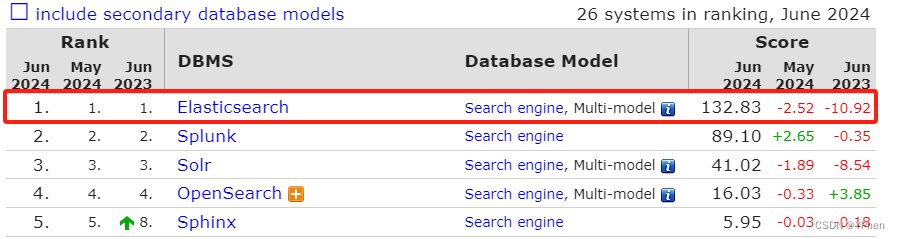
ElasticSearch 是目前最流行的、企业级搜索最多的全文搜索引擎,高效的全文检索和近实时的数据更新,这无疑成为企业级应用开发时首选的搜索引擎。在互联网发展如此迅速的时代,对从事 IT 行业的我们来说,不仅要掌握其使用方式,更要了解其核心思想以及如何优化,ElasticSearch 搜索是快,但是正对于互联网项目或者电商这种对高并发、高可用、高可扩展 的应用来说,单机版是很难维持的,必须使用集群方式来提高效率。
但是话说回来,每个项目都独有自己的业务场景和对服务的要求不同,所以我们必须要很清晰的了解其内部原理和根据不同的业务场景来针对性的优化,才能在其位上做到 及格。
参考文献
- ElasticSearch官网:https://www.elastic.co/guide/en/elasticsearch/reference/current/docs-replication.html
- ElasticSearch官方中文网:https://www.elastic.co/guide/cn/elasticsearch/guide/current/dynamic-indices.html
- DB-Engines Ranking:https://db-engines.com/en/ranking/search+engine
- 协助 AI:ChatGPT、Kimi
点击【YPhen聊码】同步更新,欢迎━(`∀´)ノ亻!来聊!!!















 1049
1049











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









