







简单的敏感词提示功能
1. 需求
公司现在接到通知,部分接口的部分手动输入字段,需要新增敏感词报红提示,敏感词汇现在应该是7000多个左右,需要我们提供一个敏感词校验接口,如果前端输入敏感词,则前端提示出输入的非法敏感词信息,并且分词需要支持自定义字典信息。
2.具体实现
此接口的实现过程也是相对简单,主要是使用java的分词器进行前端输入字符串代码分词,然后使用分词后的结果集与数据库中的数据进行比对,如果比对成功,则证明前端页面字符输入有非法的敏感词汇,返回给前端提示即可,数据库中数据则是在服务启动的时候加载到服务内存中,以hashSet形式进行存储(因为hashSet.contains方法效率比较高)
java版支持三种模式:
- 精确模式:试图将句子最精确地切开,适合文本分析;
- 全模式:把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义;
- 搜索引擎模式:在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词,分的更细
具体的简单实现步骤如下:
- 引入分词器pom坐标
- 添加自定义分词字典文件
- 初始化加载数据库数据,加载自定义分词字典
- 编写判定接口,进行敏感字判定
自定义词典格式要求,词典格式和dict.txt 一样,一个词占一行;每一行分三部分:词语、词频(可省略)、词性(可省略),用空格隔开,顺序不可颠倒。具体词性列表如下所示:
| 参数 | 类型 | 含义解释 |
|---|---|---|
| Ag | 形语素 | 形容词性语素。形容词代码为 a,语素代码g前面置以A。 |
| a | 形容词 | 取英语形容词 adjective 的第1个字母。 |
| ad | 副形词 | 直接作状语的形容词。形容词代码 a和副词代码d并在一起。 |
| an | 名形词 | 具有名词功能的形容词。形容词代码 a和名词代码n并在一起。 |
| b | 区别词 | 取汉字“别”的声母。 |
| c | 连词 | 取英语连词 conjunction的第1个字母。 |
| dg | 副语素 | 副词性语素。副词代码为 d,语素代码g前面置以D。 |
| d | 副词 | 取 adverb的第2个字母,因其第1个字母已用于形容词。 |
| e | 叹词 | 取英语叹词 exclamation的第1个字母。 |
| f | 方位词 | 取汉字“方” |
| g | 语素 | 绝大多数语素都能作为合成词的“词根”,取汉字“根”的声母。 |
| h | 前接成分 | 取英语 head的第1个字母。 |
| i | 成语 | 取英语成语 idiom的第1个字母。 |
| j | 简称略语 | 取汉字“简”的声母。 |
| k | 后接成分 | |
| l | 习用语 | 习用语尚未成为成语,有点“临时性”,取“临”的声母。 |
| m | 数词 | 取英语 numeral的第3个字母,n,u已有他用。 |
| Ng | 名语素 | 名词性语素。名词代码为 n,语素代码g前面置以N。 |
| n | 名词 | 取英语名词 noun的第1个字母。 |
| nr | 人名 | 名词代码 n和“人(ren)”的声母并在一起。 |
| ns | 地名 | 名词代码 n和处所词代码s并在一起。 |
| nt | 机构团体 | “团”的声母为 t,名词代码n和t并在一起。 |
| nz | 其他专名 | “专”的声母的第 1个字母为z,名词代码n和z并在一起。 |
| o | 拟声词 | 取英语拟声词 onomatopoeia的第1个字母。 |
| p | 介词 | 取英语介词 prepositional的第1个字母。 |
| q | 量词 | 取英语 quantity的第1个字母。 |
| r | 代词 | 取英语代词 pronoun 的第2个字母,因p已用于介词。 |
| s | 处所词 | 取英语 space 的第1个字母。 |
| tg | 时语素 | 时间词性语素。时间词代码为 t,在语素的代码g前面置以T。 |
| t | 时间词 | 取英语 time的第1个字母。 |
| u | 助词 | 取英语助词 auxiliary |
| vg | 动语素 | 动词性语素。动词代码为 v。在语素的代码g前面置以V。 |
| v | 动词 | 取英语动词 verb的第一个字母。 |
| vd | 副动词 | 直接作状语的动词。动词和副词的代码并在一起。 |
| vn | 名动词 | 指具有名词功能的动词。动词和名词的代码并在一起。 |
| w | 标点符号 | |
| x | 非语素字 | 非语素字只是一个符号,字母 x通常用于代表未知数、符号。 |
| y | 语气词 | 取汉字“语”的声母。 |
| z | 状态词 | 取汉字“状”的声母的前一个字母。 |
| un | 未知词 | 不可识别词及用户自定义词组。取英文 Unkonwn首两个字母。(非北大标准,CSW分词中定义) |
注意:如果有时候词库已经添加了自定义的分词,但是分词不生效,则可以加大
词频,并且分词模式使用全模式,则可以对
3. 代码部分
-
引入pom信息
<!-- 结巴分词 --> <dependency> <groupId>com.huaban</groupId> <artifactId>jieba-analysis</artifactId> <version>1.0.2</version> </dependency> -
添加自定义分词字典文件
在resources目录下添加新的分词文件

-
初始化加载数据库数据,加载自定义分词字典
package cn.git.init; import cn.hutool.core.util.StrUtil; import com.huaban.analysis.jieba.WordDictionary; import lombok.extern.slf4j.Slf4j; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.core.io.ResourceLoader; import org.springframework.stereotype.Component; import org.springframework.util.FileCopyUtils; import javax.annotation.PostConstruct; import java.io.File; import java.io.FileOutputStream; import java.io.IOException; import java.io.InputStream; import java.nio.file.Path; import java.nio.file.Paths; import java.util.HashSet; import java.util.Objects; import java.util.Set; /** * @description: 自定义分词词典加载初始化 * @program: bank-credit-sy * @author: lixuchun * @create: 2024-08-13 */ @Slf4j @Component public class AnalyzerInit { /** * 敏感词集合 */ public static Set<String> sensitiveWordsSet = new HashSet<>(); /** * 自定义词典路径 */ private static final String DICT_PATH = "/dict/custom.dict"; /** * 临时文件名称 */ private static final String TEMP_FILE_NAME = "custom_tmp.dict"; /** * 系统标识win系统 */ private static final String WINDOWS_SYS = "windows"; /** * 系统标识属性 */ private static final String OS_FLAG = "os.name"; @Autowired private ResourceLoader resourceLoader; /** * 初始化加载自定义分词词典 * * idea测试环境可用,linux分词加载自定义字典,需要读取jar包中文件内容,spring boot 打包运行后,无法直接读取,获取Path对象 * 所以复制一份临时文件到本地,再加载 */ @PostConstruct public void analyzerInit() throws IOException { // 判断当前系统为windows系统还是linux系统 String osName = System.getProperty(OS_FLAG); if (osName.toLowerCase().contains(WINDOWS_SYS)) { // 获取自定义词典信息 String dictFilePath = Objects.requireNonNull(getClass().getClassLoader().getResource(DICT_PATH)).getPath(); Path path = Paths.get(new File(dictFilePath).getAbsolutePath()); log.info("开始加载分词词典信息,获取自定义词典路径[{}]", dictFilePath); //加载自定义的词典进词库 WordDictionary.getInstance().loadUserDict(path); log.info("加载自定义词典信息完毕"); /** * 或者 Path path = Paths.get(new File(getClass().getClassLoader().getResource("dict/custom.dict").getPath()).getAbsolutePath()); WordDictionary.getInstance().loadUserDict(path); **/ } else { // linux系统,获取项目运行路径 String workPath = System.getProperty("user.dir"); // 读取配置文件流,并且生成一个临时文件 InputStream dictInputStream = this.getClass().getResourceAsStream(DICT_PATH); File dictTempFile = new File(workPath.concat(StrUtil.SLASH).concat(TEMP_FILE_NAME)); FileCopyUtils.copy(dictInputStream, new FileOutputStream(dictTempFile)); // 加载自定义的词典进词库 WordDictionary.getInstance().loadUserDict(dictTempFile.toPath()); log.info("加载自定义词典信息完毕"); // 自定义字典加载完成,删除临时文件 dictTempFile.delete(); } // 开始加载数据库中敏感词信息,大写字母修改为小写字母,此过程正常应该是在数据库中获取 for (int i = 0; i < 1000000; i++) { if (i == 0) { sensitiveWordsSet.add("傻x"); sensitiveWordsSet.add("牛p"); sensitiveWordsSet.add("先烈的电话"); } else { sensitiveWordsSet.add("傻x" + i); sensitiveWordsSet.add("牛p" + i); } } log.info("数据库中敏感分词加载完毕!"); } } -
编写判定接口,进行敏感字判定
package cn.git.analysis; import cn.git.init.AnalyzerInit; import com.alibaba.fastjson.JSONObject; import com.huaban.analysis.jieba.JiebaSegmenter; import com.huaban.analysis.jieba.SegToken; import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RestController; import java.util.ArrayList; import java.util.List; /** * @description: 分词测试controller * @program: bank-credit-sy * @author: lixuchun * @create: 2024-08-13 */ @RestController @RequestMapping("/analyzer") public class AnalyzerController { /** * 分词测试方法 */ @GetMapping("/test") public void test() { // 其中傻X是自定义分词,正常接收到字符串首先去除空格,然后调用分词方法 String[] sentences = new String[] { "傻X上海这是一个伸手不见五指的黑夜。我叫孙悟空咸阳6合彩,十八大我爱北京,党代我爱Python和C++。h动画", "我不喜欢日本和服。", "雷猴回归人间。", "工信处女干事每月经过下属科室都要亲口交党代代24口交换机等技术性器件的安装工作先烈的电话,牛p啊", "结果婚的红X星和尚未结过婚的666" }; // 接吧分词组件 JiebaSegmenter segmenter = new JiebaSegmenter(); // 将语句转换为list List<String> sentenceList = CollUtil.newArrayList(sentences); sentenceList.forEach(sentence -> { // 精确模式 List<String> processWordList = segmenter.sentenceProcess(sentence); List<String> senseWordList = new ArrayList<>(); processWordList.forEach(senseWord -> { if (AnalyzerInit.sensitiveWordsSet.contains(senseWord)) { senseWordList.add(senseWord); } }); System.out.println("精确模式,分词结果 : " + JSONObject.toJSONString(processWordList) + " , 精确模式,敏感词获取 : " + JSONObject.toJSONString(senseWordList)); // 搜索模式 List<SegToken> searchTokenList = segmenter.process(sentence, JiebaSegmenter.SegMode.SEARCH); List<String> searchWordList = searchTokenList.stream().map(token -> token.word).collect(Collectors.toList()); // 敏感词列表 List<String> senseWordSearchList = new ArrayList<>(); searchWordList.forEach(senseWord -> { if (AnalyzerInit.sensitiveWordsSet.contains(senseWord)) { senseWordSearchList.add(senseWord); } }); System.out.println("搜索模式,分词结果 : " + JSONObject.toJSONString(searchWordList) + " , 搜索模式,敏感词获取 : " + JSONObject.toJSONString(senseWordSearchList)); // 全局模式 List<SegToken> indexTokenList = segmenter.process(sentence, JiebaSegmenter.SegMode.INDEX); List<String> indexWordList = indexTokenList.stream().map(token -> token.word).collect(Collectors.toList()); // 敏感词列表 List<String> senseWordAllList = new ArrayList<>(); searchWordList.forEach(senseWord -> { if (AnalyzerInit.sensitiveWordsSet.contains(senseWord)) { senseWordAllList.add(senseWord); } }); System.out.println("全局模式,分词结果 : " + JSONObject.toJSONString(indexWordList) + " , 全局模式,敏感词获取 : " + JSONObject.toJSONString(senseWordAllList)); }); } }
4.测试部分
使用请求简单测试 http://localhost:8080/analyzer/test,获取敏感词信息如下:
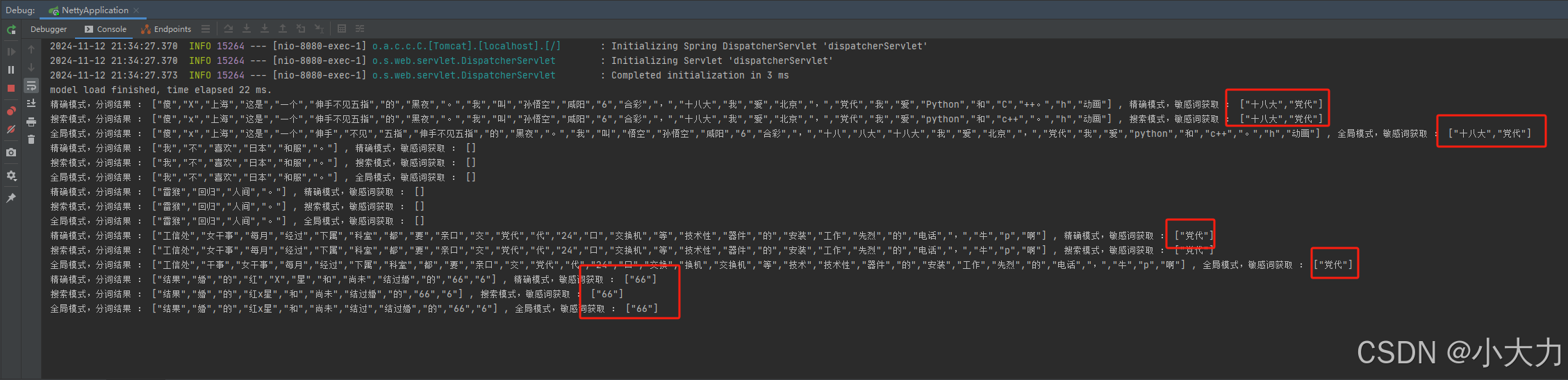
最终发现,
INDEX模式搜索内容最全

















 9639
9639

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









