







参考资料:https://blog.csdn.net/androidlushangderen/article/details/42921789
介绍
em算法是一种迭代算法,用于含有隐变量的参数模型的最大似然估计或极大后验概率估计。EM算法,作为一个框架思想,它可以应用在很多领域,比如说数据聚类领域----模糊聚类的处理,待会儿也会给出一个这样的实现例子。
EM算法原理
EM算法从名称上就能看出他可以被分成2个部分,E-Step和M-Step。E-Step叫做期望化步骤,M-Step为最大化步骤。
整体算法的步骤如下所示:
1、初始化分布参数。
2、(E-Step)计算期望E,利用对隐藏变量的现有估计值,计算其最大似然估计值,以此实现期望化的过程。
3、(M-Step)最大化在E-步骤上的最大似然估计值来计算参数的值
4、重复2,3步骤直到收敛。
以上就是EM算法的核心原理,也许您会想,真的这么简单,其实事实是我省略了其中复杂的数据推导的过程,因为如果不理解EM的算法原理,去看其中的数据公式的推导,会让人更加晕的。好,下面给出数据的推导过程,本人数学也不好,于是用了别人的推导过程,人家已经写得非常详细了。
EM算法的推导过程
jensen不等式
在介绍推导过程的时候,需要明白jensen不等式,他是一个关于凸函数的一个定理,直接上公式定义;
如果f是凸函数,X是随机变量,那么

特别地,如果f是严格凸函数,那么 当且仅当
当且仅当 ,也就是说X是常量。
,也就是说X是常量。
这里我们将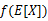 简写为
简写为 。
。
如果用图表示会很清晰:
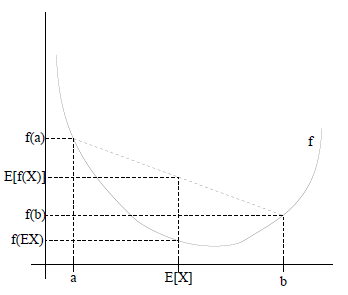
这里需要解释的是E(X)的值为什么是(a+b)/2,因为有0.5 的概率是a,0.5的概率是b,于是他的期望就是a,b的和的中间值了。同理在y轴上的值也是如此。
EM算法的公式表达形式
EM算法转化为公式的表达形式为:
给定的训练样本是 ,样例间独立,我们想找到每个样例隐含的类别z,能使得p(x,z)最大。p(x,z)的最大似然估计如下:
,样例间独立,我们想找到每个样例隐含的类别z,能使得p(x,z)最大。p(x,z)的最大似然估计如下:

然后对这个公式做一点变化,就可以用上jensen不等式了,神奇的一笔来了:
可以由前面阐述的内容得到下面的公式:

(1)到(2)比较直接,就是分子分母同乘以一个相等的函数。(2)到(3)利用了Jensen不等式。对于每一个样例i,让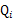 表示该样例隐含变量z的某种分布,
表示该样例隐含变量z的某种分布,![clip_image032[1]](http://images.cnblogs.com/cnblogs_com/jerrylead/201104/201104061616025060.png) 满足的条件是
满足的条件是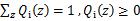 。于是就来到了问题的关键,通过上面的不等式,我们就可以确定式子的下界,然后我们就可以不断的提高此下界达到逼近最后真实值的目的值,那么什么时候达到想到的时候呢,没错,就是这个不等式变成等式的时候,然后再依据之前描述的jensen不等式的说明,当不等式变为等式的时候,当且仅当,也就是说X是常量,推出就是下面的公式:
。于是就来到了问题的关键,通过上面的不等式,我们就可以确定式子的下界,然后我们就可以不断的提高此下界达到逼近最后真实值的目的值,那么什么时候达到想到的时候呢,没错,就是这个不等式变成等式的时候,然后再依据之前描述的jensen不等式的说明,当不等式变为等式的时候,当且仅当,也就是说X是常量,推出就是下面的公式:

再推导下,由于 (因为Q是随机变量z(i)的概率密度函数),则可以得到:分子的和等于c(分子分母都对所有z(i)求和:多个等式分子分母相加不变,这个认为每个样例的两个概率比值都是c)
(因为Q是随机变量z(i)的概率密度函数),则可以得到:分子的和等于c(分子分母都对所有z(i)求和:多个等式分子分母相加不变,这个认为每个样例的两个概率比值都是c) ,再次继续推导;
,再次继续推导;

最后就得出了EM算法的一般过程了:
循环重复直到收敛
(E步)对于每一个i,计算

(M步)计算



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









