









①邻接矩阵
对于有向图中顶点适当地编号,使其邻接矩阵为三角矩阵且主对角元全为零的充分必要条件是该有向图可以进行拓扑排序。
我们想将一个图信息存储起来,我们有两个必须存储的数据,节点信息(a,b,c,d,e)和权值(3,5,4,1,6,7)和节点之间的关系,权值也就是路径。邻接矩阵表示法,用两个数组表示,一个一维数组和一个二维数组,一维数组存储节点信息,二维数组存储节点之间的关系。

②邻接表
图的常用储存结构之一,由表头结点和表结点两部分组成,其中表头结点存储图的各顶点,表结点用单向链表存储表头结点所对应顶点的相邻顶点(也就是表示了图的边)。在有向图里表示表头结点指向其它结点(a->b),无向图则表示与表头结点相邻的所有结点(a—b)。


③基数排序理解
基数排序一般从最低有效位开始即个位开始排序,例如:序列110, 119, 007, 911, 114, 120, 122
第一趟排出110,120,911,122,114,007,119,
第二趟按照次高有效位即十位排序,
第二趟排出007,110,911,114,119,120,122,
基数排序与关键字的位数有关,但也是一种稳定排序。
④散列存储的理解
基本思想:以结点的关键字k为自变量,通过一个确定的函数关系f,计算出对应的函数值,把这个函数值解释为结点的存储地址,将结点存入到f(k)所指示的存储位置上,在查找时再根据要查找的关键字,用同样的函数计算地址,然后到相应的单元中读取。散列法又被成为关键字——地址转换法。
哈希表:用散列法存储的线性表被称为哈希表,使用的函数被称为散列函数或者哈希函数,f(k)被称为散列地址或者哈希地址。通常情况下,散列表的存储空间是一个一维数组,而其哈希地址为数组的下标。
⑤B+、B-和B*树的理解
B- 树
是一种多路搜索树(并不是二叉的):
1. 定义任意非叶子结点最多只有 M 个儿子;且 M>2 ;
2. 根结点的儿子数为 [2, M] ;
3. 除根结点以外的非叶子结点的儿子数为 [M/2, M] ;
4. 每个结点存放至少 M/2-1 (取上整)和至多 M-1 个关键字;(至少 2 个关键字)
5. 非叶子结点的关键字个数 = 指向儿子的指针个数 -1 ;
6. 非叶子结点的关键字: K[1], K[2], …, K[M-1] ;且 K[i] < K[i+1] ;
7. 非叶子结点的指针: P[1], P[2], …, P[M] ;其中 P[1] 指向关键字小于 K[1] 的子树, P[M] 指向关键字大于 K[M-1] 的子树,其它P[i] 指向关键字属于 (K[i-1], K[i]) 的子树;
8. 所有叶子结点位于同一层;
如:( M=3 )

B- 树的搜索,从根结点开始,对结点内的关键字(有序)序列进行二分查找,如果命中则结束,否则进入查询关键字所属范围的儿子结点;重复,直到所对应的儿子指针为空,或已经是叶子结点;
B- 树的特性:
1. 关键字集合分布在整颗树中;
2. 任何一个关键字出现且只出现在一个结点中;
3. 搜索有可能在非叶子结点结束;
4. 其搜索性能等价于在关键字全集内做一次二分查找;
5. 自动层次控制;
由于限制了除根结点以外的非叶子结点,至少含有 M/2 个儿子,确保了结点的至少利用率,其最底搜索性能为:
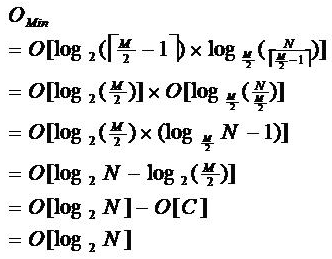
其中, M 为设定的非叶子结点最多子树个数, N 为关键字总数;
所以 B- 树的性能总是等价于二分查找(与 M 值无关),也就没有 B 树平衡的问题;
由于 M/2 的限制,在插入结点时,如果结点已满,需要将结点分裂为两个各占 M/2 的结点;删除结点时,需将两个不足 M/2 的兄弟结点合并;
B+ 树
B+ 树是 B- 树的变体,也是一种多路搜索树:
1. 其定义基本与 B- 树同,除了:
2. 非叶子结点的子树指针与关键字个数相同;
3. 非叶子结点的子树指针 P[i] ,指向关键字值属于 [K[i], K[i+1]) 的子树( B- 树是开区间);
5. 为所有叶子结点增加一个链指针;
6. 所有关键字都在叶子结点出现;
如:( M=3 )

B+ 的搜索与 B- 树也基本相同,区别是 B+ 树只有达到叶子结点才命中( B- 树可以在非叶子结点命中),其性能也等价于在关键字全集做一次二分查找;
B+ 的特性:
1. 所有关键字都出现在叶子结点的链表中(稠密索引),且链表中的关键字恰好是有序的;
2. 不可能在非叶子结点命中;
3. 非叶子结点相当于是叶子结点的索引(稀疏索引),叶子结点相当于是存储(关键字)数据的数据层;
4. 更适合文件索引系统;
B* 树
是 B+ 树的变体,在 B+ 树的非根和非叶子结点再增加指向兄弟的指针;

B* 树定义了非叶子结点关键字个数至少为 (2/3)*M ,即块的最低使用率为 2/3 (代替 B+ 树的 1/2 );
B+ 树的分裂:当一个结点满时,分配一个新的结点,并将原结点中 1/2 的数据复制到新结点,最后在父结点中增加新结点的指针;B+ 树的分裂只影响原结点和父结点,而不会影响兄弟结点,所以它不需要指向兄弟的指针;
B* 树的分裂:当一个结点满时,如果它的下一个兄弟结点未满,那么将一部分数据移到兄弟结点中,再在原结点插入关键字,最后修改父结点中兄弟结点的关键字(因为兄弟结点的关键字范围改变了);如果兄弟也满了,则在原结点与兄弟结点之间增加新结点,并各复制 1/3 的数据到新结点,最后在父结点增加新结点的指针;所以, B* 树分配新结点的概率比 B+ 树要低,空间使用率更高。
⑥简单变量与形参传值形式
简单变量作为实参时,将把该变量所占内存单元的值传递给形参,实参和形参各占不同的内存单元,传递完后,实参和形参不再有任何联系,所以这种传递方式也叫做单向值传递方式。
⑦广义表
广义表是线性表的扩展,具体定义为n(n>=0)个元素的有限集合。其中元素有以下两种类型:
- 一个原子元素(指不可再分的元素)
- 一个可以再分的元素(或称为一个子表)
如果所有元素都是原子元素,则称为线性表,如果含有子表,则是广义表。n的值是广义表的长度,如果n=0,称广义表为空表。
常见的广义表为:
A=(); B=(()); C=(alb); D=(A,B,C); E=(a,E)
广义表中含有元素的个数称为广义表的长度,广义表中含有的括号对数称为广义表的深度。
从上述定义和例子可推出列表的3个重要结论:
- 列表的元素可以是子表,而子表的元素还可以是子子表…由此,列表是一个多层次的结构。
- 列表可为其他列表所共享。如列表D可以直接引用其他列表。
- 列表可以是一个递归的表,即列表也可以是其本身的一个子表。
⑧有向树
有向树的概念是恰有一个顶点入度为0,其余顶点入度为1。
⑨比较次数与初始元素顺序无关的排序算法
这种说法也即是最好、最坏情况的时间复杂度一样的算法,有:
选择排序O(n^2)
堆排序O(nlogn)
归并排序O(nlogn)
基数排序O(tn)
⑩AOE与AOV
定义:在一个表示工程的有向图中,用顶点表示活动,用弧表示活动之间的优先关系,这样的有向图为顶点表示活动的网,我们称为AOV网(Activity On Vertex Network),AOV网中的弧表示活动之间的某种约束关系。AOV网中不存在回路(即无环的有向图)。
定义:在一个表示工程的带权有向图中,用顶点表示事件,用弧表示活动,用弧上的权值表示活动持续的时间,这种有向图的弧表示活动的网,我们称为AOE网(Activity On Edge Network).AOE网中没有入度的顶点称为始点或源点,没有出度的顶点叫做终点或汇点。















 2144
2144











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









