







一、主从复制
1、主从集群的意义
单点故障:发生单点故障后能够快速切换到从机,恢复提供服务,使用哨兵后可实现自动切换,真正实现高可用。
2、主从集群的一致性策略
1)采用的是异步复制--高性能弱一致性
2)扩展知识:cap(具体可以通过NWR来协调平衡,具体文章:https://www.cnblogs.com/captainlucky/p/4720986.html)
cap原理指出,任何分布式系统只可同时满足二点,没法三者兼顾。如果要保证强一致性,则需要进行同步复制,即写操作发生时,主写完成后同步做从机复制操作,如果复制失败,则从机也失败,然后返回客户端写操作失败的结果。从而强一致性损失了可用性(好的响应性能:失败的可能以及同步复制的等待时间损耗,可用性会影响用户体验)。
3、主从复制的具体过程
亦可参考优秀播客:https://www.cnblogs.com/daofaziran/p/10978628.html
1)全量同步
Redis全量复制一般发生在Slave初始化阶段,这时Slave需要将Master上的所有数据都复制一份。具体步骤如下:
- - 从服务器连接主服务器,发送SYNC命令;
- - 主服务器接收到SYNC命名后,开始执行BGSAVE命令生成RDB文件并使用缓冲区记录此后执行的所有写命令;
- - 主服务器BGSAVE执行完后,向所有从服务器发送快照文件,并在发送期间继续记录被执行的写命令;
- - 从服务器收到快照文件后丢弃所有旧数据,载入收到的快照;
- - 主服务器快照发送完毕后开始向从服务器发送缓冲区中的写命令;
- - 从服务器完成对快照的载入,开始接收命令请求,并执行来自主服务器缓冲区的写命令;
2)增量同步
- Redis增量复制是指Slave初始化后开始正常工作时主服务器发生的写操作同步到从服务器的过程。
- 增量复制的过程主要是主服务器每执行一个写命令就会向从服务器发送相同的写命令,从服务器接收并执行收到的写命令。
3)Redis主从复制策略
- -无论如何,首先会尝试进行增量同步;
- -增量同步不成功,要求从机进行全量同步;
4)部分同步机制
版本区别:从redis 2.8版本以前,并不支持部分同步,当主从服务器之间的连接断掉之后,master服务器和slave服务器之间都是进行全量数据同步。但是从redis 2.8开始,即使主从连接中途断掉,也不需要进行全量同步,因为从这个版本开始融入了部分同步的概念。
实现原理:部分同步的实现依赖于在master服务器内存中给每个slave服务器维护了一份同步日志和同步标识,每个slave服务器在跟master服务器进行同步时都会携带自己的同步标识和上次同步的最后位置。当主从连接断掉之后,slave服务器隔断时间
(默认1s)主动尝试和master服务器进行连接,如果从服务器携带的偏移量标识还在master服务器上的同步备份日志中,那么就从slave发送的偏移量开始继续上次的同步操作,如果slave发送的偏移量已经不再master的同步备份日志中(可能由于主从之间断掉的时间比较长或者在断掉的短暂时间内master服务器接收到大量的写操作),则必须进行一次全量更新。在部分同步过程中,master会将本地记录的同步备份日志中记录的指令依次发送给slave服务器从而达到数据一致。
4、主从集群的搭建和使用
1)创建一个测试目录:
cd ~
mkdir test
2)启动多个实例:
cd utils;
./install_server.sh
指定端口6380
service redis_6380 stop
3)拷贝所有配置文件到当前目录下做实验,后面通过指定配置文件方式启动
cd test;
cp /etc/redis/* ./
4)修改配置文件,使得redis日志打到控制台:
vi 6379.config;
daemonize 改为no
注释掉日志文件:#logfile /var/log/redis_6380.log
5)删掉所有实例的持久化数据:
cd /var/lib/redis
rm -f *.rdb
启动实例:redis-server ~/test/6379.conf
6)配置主从关系
查看主从复制配置帮助文档
help slaveof
replicof ip port:跟随哪个redis实例,即把自己作为slave,指定主机;该命令会先清掉本机数据,然后再load主机数据,实现和主机保持数据一致性;
从机挂掉后重启后会增量复制主机数据,因为之前复制主机数据后本地rdb文件中含有主机的标记:./redis-server 6380.conf --replicaof ip port
replicof no one:去除自己从机身份,恢复单机;
repilicof ip port:配置为从机,并指定主机ip和端口号;
masterauth password:如果主机有密码的话,配置密码;
replic-server-stale-data yes:从机启动后复制主机数据期间是否提供服务;
replic-read-only yes:从机是否为只读,即不支持set写命令,只支持get读命令;
repl-diskless-sync no:默认不使用diskless同步方式
repl-diskless-sync-delay 5:无磁盘diskless方式在进行数据传递之前会有一个时间的延迟,以便slave端能够进行到待传送的目标队列中,这个时间默认是5秒。

7)注意事项
注意事项:主必须开启持久化,否则如果宕机将导致主机和从机均丢失所有数据;
5、redis高可用的实现
(亦可参考优秀播客:https://www.cnblogs.com/crazymakercircle/p/14285001.html)
1)主机如果宕掉,导致失去写能力;
2)实现方式:哨兵系统(sentinel系统)
3)哨兵系统的三个特性:
- 监控(Monitoring): Sentinel 会不断地检查你的主服务器和从服务器是否运作正常。
- 提醒(Notification): 当被监控的某个 Redis 服务器出现问题时, Sentinel 可以通过 API 向管理员或者其他应用程序发送通知。
- 自动故障迁移(Automatic failover): 当一个主服务器不能正常工作时, Sentinel 会开始一次自动故障迁移操作。
4)哨兵系统配置:
新建26379.conf
26379为该哨兵系统的端口,里面的2为该哨兵系统的投票权重值;mymaster是监控集群的名称,因为一个哨兵可以监控多个集群;

5)哨兵系统启动:
通过--sentinel告诉redis-server这是启动一个哨兵系统而不是redis系统;
![]()
6)哨兵系统优缺点:
- 优点:
- 解决了单机压力和单点故障问题;
- 缺点:
- 故障发现和主从切换需要时间,会导致丢失数据;
- 无法解决主机master的写压力;
- 没有解决redis容量有限问题;
二、分片集群
1、分片集群意义
容量有限:单机容量瓶颈
单机压力:单机吞吐量瓶颈
2、分片集群的集群策略
为了减轻缓存主机压力,需要使用多台主机构建集群(称为分片集群:cluster),cluster集群策略有随机策略、hash策略、一致性hash等。
1)随机策略:数据读写均通过随机算法随机到每台主机上;
缺点:
同一份数据可能三台主机都存有,导致数据冗余;
缓存访问可能刚好随机到一台没有的主机,导致缓存没有命中;
2)hash策略:数据读写均通过hash算法分配到每台主机上,如集群存在3台主机,则hash(key)%3判断应该选择哪一台主机;
缺点:
容错性差:一旦某台主机宕掉或者去掉了某一台主机,就会导致主机所分配的那部分key无法命中;
扩展性差:一旦需要增加或减少集群主机数量,会导致所有的key都要重新计算,变成hash(key)%(n-1)或者hash(key)%(n+1),导致大量的缓存未命中;
3)一致性hash(又称为:hash环、ketama算法):将主机ip进行hash后定位在环上的位置,数据abcd分别通过hash算法后确定在环上的位置,然后顺时针行走找到,第1台遇到的主机就是key所访问的主机;
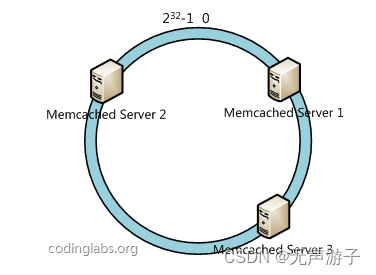
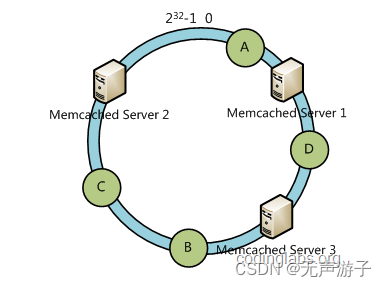
容错性和扩展性分析:
某台主机宕机后,归属于这台机器的那一小段数据会被重新定位到顺时针方向的下一台主机上,容错性较好;
增加或删除一台主机只会影响顺时针方向它前面的一小段数据,扩展性比较好;
缺点及解决方案:
主机在hash环上的位置不均,导致数据倾斜;

通过虚拟节点机制,即对每一个服务节点计算多个哈希,每个计算结果位置都放置一个此服务节点,称为虚拟节点。具体做法可以在服务器ip或主机名的后面增加编号来实现,然后增加一个虚拟节点到真实主机的映射关系;
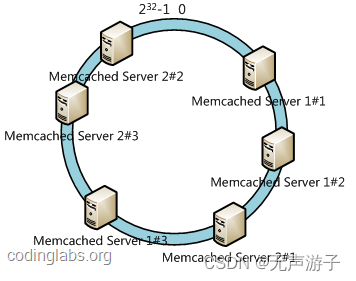
上述内容整理自博客:
http://blog.codinglabs.org/articles/consistent-hashing.html
3、分片集群的实现方式
1)redis代理
代理客户端的各种分片逻辑,简化客户端工作;
Twemproxy代理工具:
- 是由Twitter开源的redis分片代理,安装配置使用见下面文章:https://www.cnblogs.com/gomysql/p/4413922.html
- 默认代理memcache,要代理redis需要修改配置为true
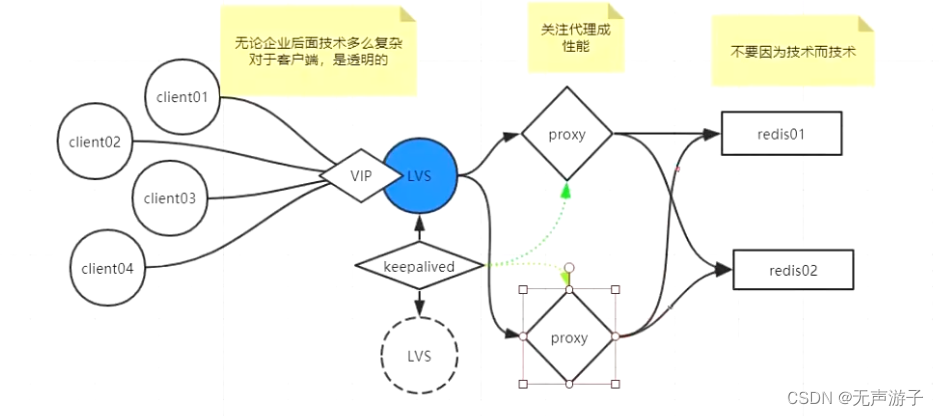
predixy代理工具:
功能强大
predixy既支持Redis Sentinel也支持Redis Cluster,支持hashTag
使用可以通过GitHub查看使用方法:README.MD
如下图所示,predixy的配置文件中配置了3个哨兵(这3个哨兵都监听了ooxx和xxoo这两组主从复制集群)和两组主从集群。这个时候该代理是不支持多键操作和事务的(就算使用了hashTag),因为后面是多组集群;如果配置文件里面去掉一组Group,则predixy代理会智能的发现只有一组主从复制集群会变得支持多键操作和事务。

2)redis自带集群:
无主模型(去中心化),客户端可以访问集群任意主机,然后每台主机都配置有映射表,如果访问key不在本台主机则查询映射关系返回应该访问的正确主机;

4、redis自带cluster集群的搭建
1)配置文件方式
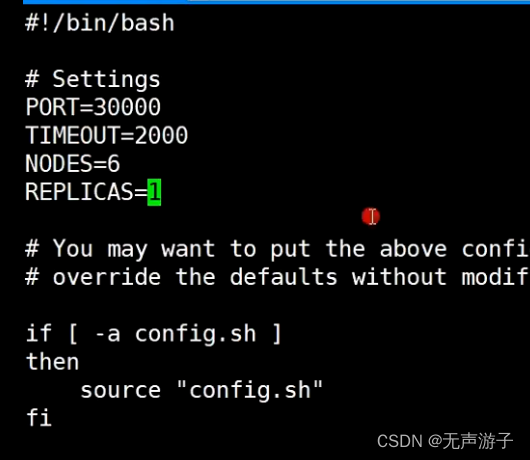
查看utils下面的可执行脚本:create-cluster,里面的NODES表示有多少个节点,REPLICAS表示每台主机配置多少个从,比如图中即是表示:3主3从共6个节点;
然后通过sh create-cluster start启动所有实例;
通过sh create-cluster create分配所有hash槽并创建集群;
2)命令行方式
直接通过客户端创建:redis-cli --cluster create 127.001.01:30001 127.001.01:30002 127.001.01:30003 127.001.01:30004 --cluster-replicas 1
上述命令表示创建2主2从集群
5、redis自带cluster集群的常用操作
1)查看集群信息可以通过:
redis-cli --cluster info 127.0.0.1:30001
redis-cli --cluster check 127.0.0.1:30001
2)查看hash槽位分配:

客户端连接的时候需要通过集群方式连接,因为普通方式连接客户端不会自动跳转:

6、分片集群带来的问题及解决对策
问题:
由于数据分治,导致聚合操作和事务操作很难实现;
官方文档表述:

解决对策:
为了实现多key操作,redis把该问题交给hash tag哈希标签;具有相同hash tag的键会被分配到同一个hash槽里面,以实现可以使用多key操作,哈希标签通过{}来定义,如{user}#1和{user}#2这两个key会被保证能分配到同一个hash 槽位。
redis在分片集群的合并操作上为了维护性能没有做妥协,而是将责任转移到客户端,即是:如果你可能需要对若干个键做合并运算,则一开始定义键的时候就带上hash tag来定义,一开始就存入到相同节点;
















 2220
2220

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











