






 本文记录了一位大学生通过Python爬虫获取股市数据的全过程,从理解爬虫工作原理、使用Chrome抓包工具分析请求、模拟GET请求到数据清洗与保存,最后将数据写入Excel。爬虫使用requests库,通过分析接口URL和响应内容,成功提取所需数据。
本文记录了一位大学生通过Python爬虫获取股市数据的全过程,从理解爬虫工作原理、使用Chrome抓包工具分析请求、模拟GET请求到数据清洗与保存,最后将数据写入Excel。爬虫使用requests库,通过分析接口URL和响应内容,成功提取所需数据。
前言:这是一篇个人记录的帖子,主要用于记录大学期间做过的一些值得记录的东西,复盘学过的知识和踩过的坑。其实想写这个已经很久了,但是一直在忙别的事情没有写,以至于之前做过的一些东西和学过的一些知识现在已经记不太清了,所以开篇我想选我近期做过的、印象还比较深的、我认为比较有趣的东西记录。完全基于个人兴趣,和个人专业无关,说有意义吧,其实也意义不大,单纯觉得很好玩。其实最开始我是想写一个word文档,专门放在一个文件夹里面,但是因为我的电脑文件实在太乱了,我怕我不小心删了,发到csdn上有几个好处:一是不会误删;二是可以利用这个契机和更多的人交流学习。(屁话说完了,友情提示,我的文章比较外行,都是基于自己的理解说的,专业人士移步)
初识爬虫:
如题,开篇之作我想记录的是近期我做过的一个爬虫程序。当时做这个程序的想法也不是凭空而来的,是在做一个课程大作业的时候,有一个收集数据的环节,我就想能不能用我以前学过的一些东西来实现这个环节。然后顺理成章地就想到python的爬虫库了,这个库我在去年研究TCP/IP协议内容的时候有接触过,但是当时没有实战,只是知道一个理论,等了这么久终于有机会用了。有了这个想法之后我对这个大作业的兴趣直线上升,直接和老师报名最后的展示环节,最后在全班人面前分享我的历程,确实很爽。
大作业的内容大致是:自己选择一个感兴趣的企业的某项指标,根据其往期数据再结合课上所学的知识对其未来的走向进行预测,并结合自己所收集到的信息对预测结果进行分析。但是这里只记录得到数据的过程,预测的过程我觉得做的有点烂,最后模型有点过拟合了,后面复盘过,想改一下代码的,但是太懒了。我的选题是股市的预测。
简单说一下python的爬虫库的使用吧,因为不是教学篇,而且我也做不到教学的本事。爬虫的过程其实就是模拟请求的过程,这里涉及到TCP/IP协议的通讯原理。简单来说就是get和post两个请求,比如说我刷新一个网站,过一会他会给我返回一个页面,页面里面有很多信息。刷新网站这个过程就是进行了get/post请求,返回的页面是服务器接收到请求后根据请求的内容给我发送的一些信息,那服务器怎么知道我想要什么内容呢?其实在调用这个get/post请求的时候需要构造一个url,可以理解为一个网址,url里面其实就包含了请求的内容,具体可以去查查这方面的相关内容。爬虫就是模拟这个过程,得到我想要的结果,这个结果可以包括多方面,不一定是获取数据,有时候也有可能是让服务器执行一些操作,具体想看你想实现什么。模拟完请求后其实爬虫就结束了,但是拿到原始内容肯定是不能直接为我们服务的,很多时候我们还要进行内容的筛选和清洗,最终得到我们想要的东西。
下面就以我这个作业为例进行详细说明:
第一步,找到想要的自己想要的数据(最开始不了解的时候总觉得爬虫是万能的,总觉得把代码写完就想要啥有啥,像百度检索似的),这里我用到的信息是《东方财富》这个网站给出的股市详细信息,如图: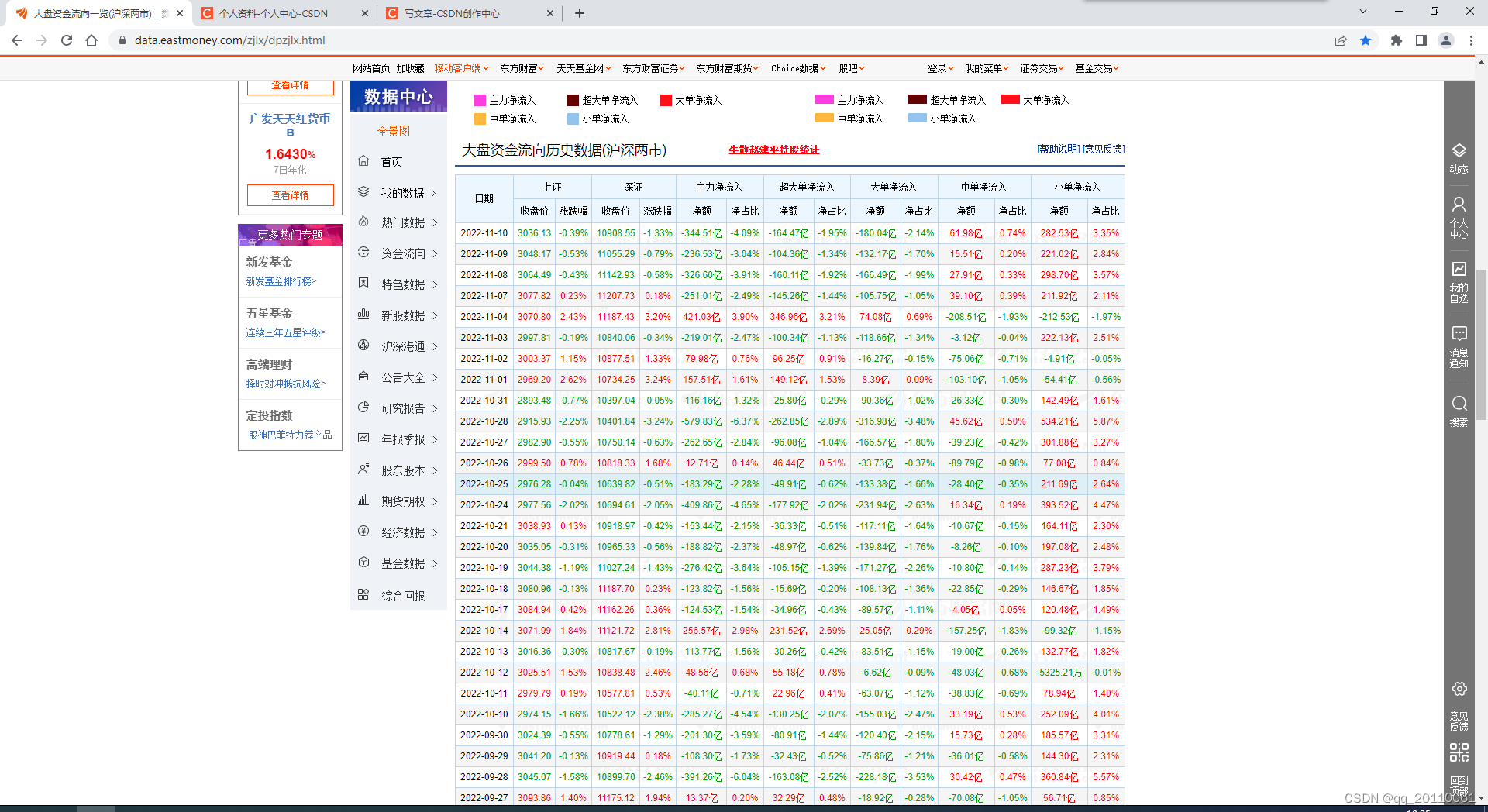
我想要的数据是上证收盘价格和日期这两栏的信息,因为后面我做预测就只需要这些信息,我的想法是把这一栏的信息和日期弄成二维的表放到excel方便阅读和分析。
第二步,进行抓包(抓包简单来说就是截获网页进行的一些请求和返回的内容,前面也提到了爬虫是模拟get/post请求向服务器索要信息的,因此我们先要利用抓包工具,看看网站执行了哪些请求,然后根据请求返回的内容,判断出哪个你想模拟的请求)。这里我用的是chorme自带的抓包工具,按f12可以直接进入,抓到的接口如下:
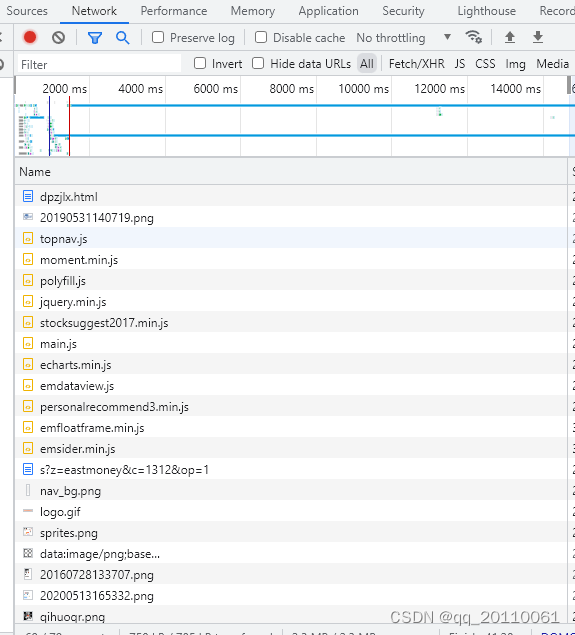
接下来就是对这些请求返回的内容进行分析,上面提到,我想要的内容是上证收盘价格和日期这两栏数据,那么如果服务器返回来的信息如果不加密的话是可以看到的,寻找请求这个过程我就略过了,直接看我找到的请求:
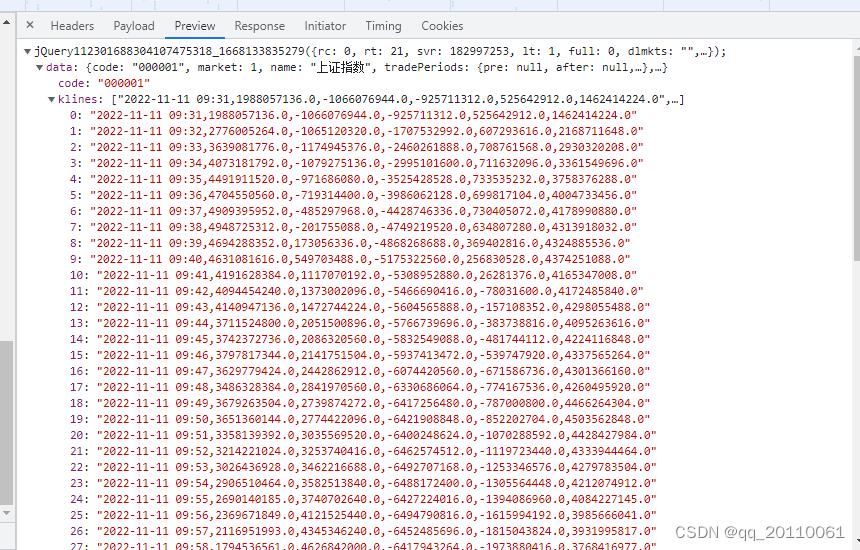
确实很明确了,不存在争议的,就是这个请求,接口是:
![]()
接下来就是调用爬虫的库模拟请求,我用的是python的requests库,也是目前最流行的,用法简单,首先先安装库,在终端上输入以下代码回车即可:
pip install requests
requests库只有一个参数,就是url,接下来要做的事情就是根据接口构造url,这里推荐初学者一个很方便的网站,可以自动帮你构造好接口的url:Convert curl commands to code,只要把接口的curl复制下来粘贴到上面的输入栏,下面的输出栏就是你要模拟请求的代码,直接复制粘贴到程序里面就算完成了,其实这个工具对我来说有点局限,因为我不知道fidder抓包工具怎么复制curl,但是chorme自带的抓包工具就很好实现了,具体的可以去查查教程,这里不详细说明。
结果如图:
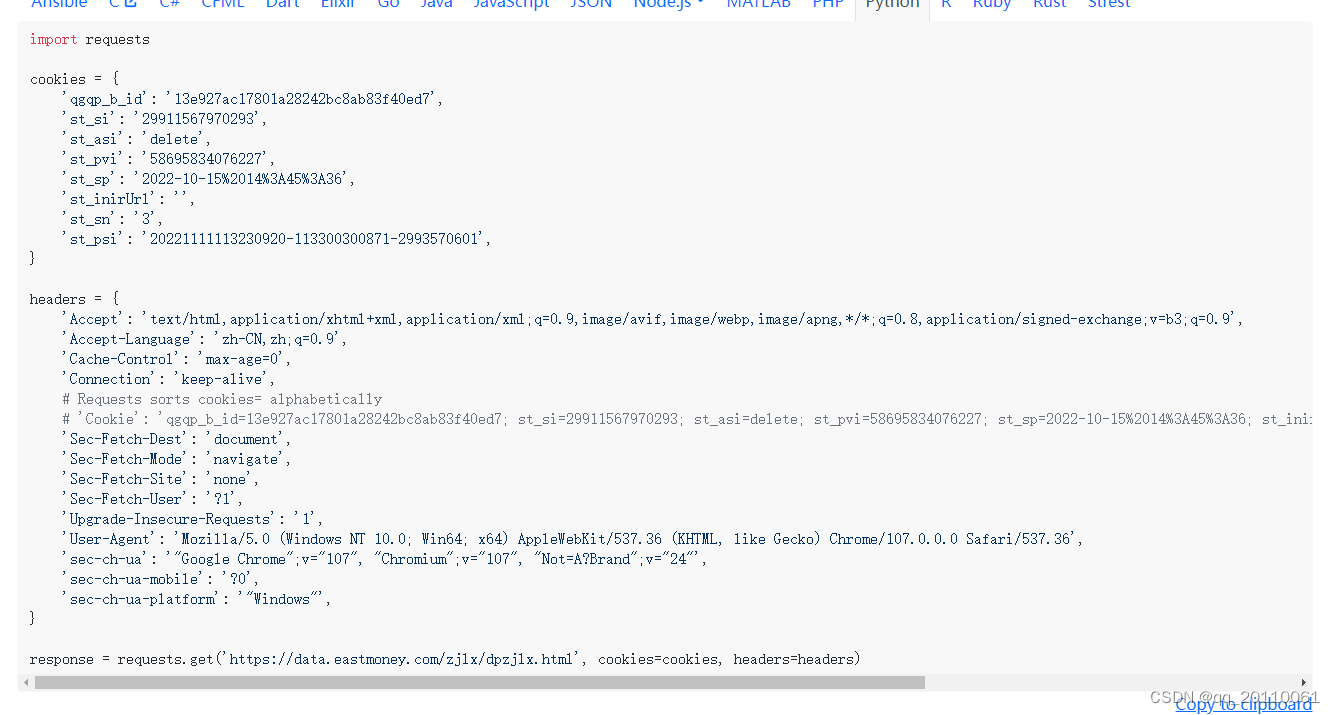
然后将下面代码复制到pycharm上运行就算请求成功了
import requests
cookies = {
'qgqp_b_id': '13e927ac17801a28242bc8ab83f40ed7',
'st_si': '29911567970293',
'st_asi': 'delete',
'st_pvi': '58695834076227',
'st_sp': '2022-10-15%2014%3A45%3A36',
'st_inirUrl': '',
'st_sn': '3',
'st_psi': '20221111113230920-113300300871-2993570601',
}
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
# Requests sorts cookies= alphabetically
# 'Cookie': 'qgqp_b_id=13e927ac17801a28242bc8ab83f40ed7; st_si=29911567970293; st_asi=delete; st_pvi=58695834076227; st_sp=2022-10-15%2014%3A45%3A36; st_inirUrl=; st_sn=3; st_psi=20221111113230920-113300300871-2993570601',
'Sec-Fetch-Dest': 'document',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'none',
'Sec-Fetch-User': '?1',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36',
'sec-ch-ua': '"Google Chrome";v="107", "Chromium";v="107", "Not=A?Brand";v="24"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
}
response = requests.get('https://data.eastmoney.com/zjlx/dpzjlx.html', cookies=cookies, headers=headers)第三步,将返回的数据保存到文本中方便阅读分析,下面是实现代码:
f = open("股市数据.text",mode="w")
f.write(response.text)返回的数据如下:
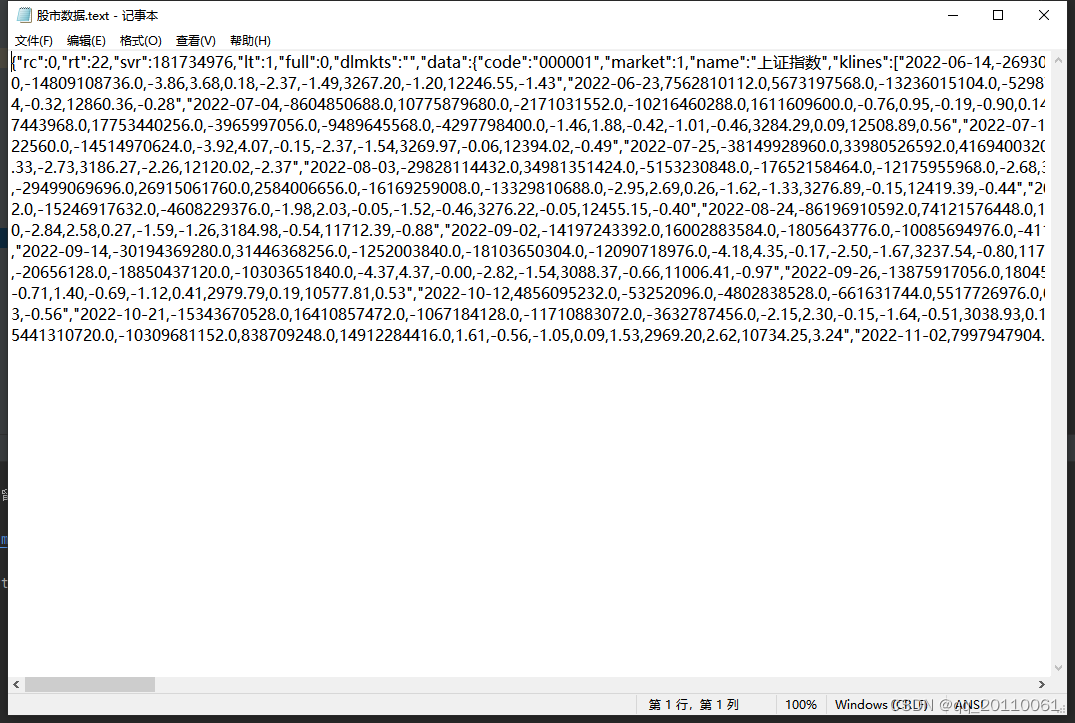
这是一个dict类型的数据(对于dict型数据的数据筛选方法可以查查相关的资料),这里我直接说我的分析的结果:对应网页上看到的直观的数据,我发现我想要的数据在"data"的"klines"里面,因此我只要把这些数据拿下来,然后分割再分割,最后根据日期和上证收盘价格的位置用索引把他们拿出来放到excel里面即可。
第四步,数据清理。首先先将dict里面的数据用resp_dict.get筛选出来放到一个list数据类型中(这个函数的用法具体也可以查资料),然后再split函数将数据进行切分,以","为分割点,然后再存入一个list数据类型中,最后再根据list的索引把日期和上证收盘价格的数据拿出来放到最终的list中,以下为具体代码和每一步分割的结果:
1、
datas = resp_dict.get('data').get('klines')
clear_datas=[]
i=0
while i<len(datas):
clear_datas.append(datas[i])
i=i+1
f = open("股市数据2.text",mode="w")
f.write(str(datas))
2、
mid_datas=[]
j=0
while j<len(clear_datas):
mid_datas.append(clear_datas[j].split(','))
j=j+1
f = open("股市数据3.text",mode="w")
f.write(str(mid_datas))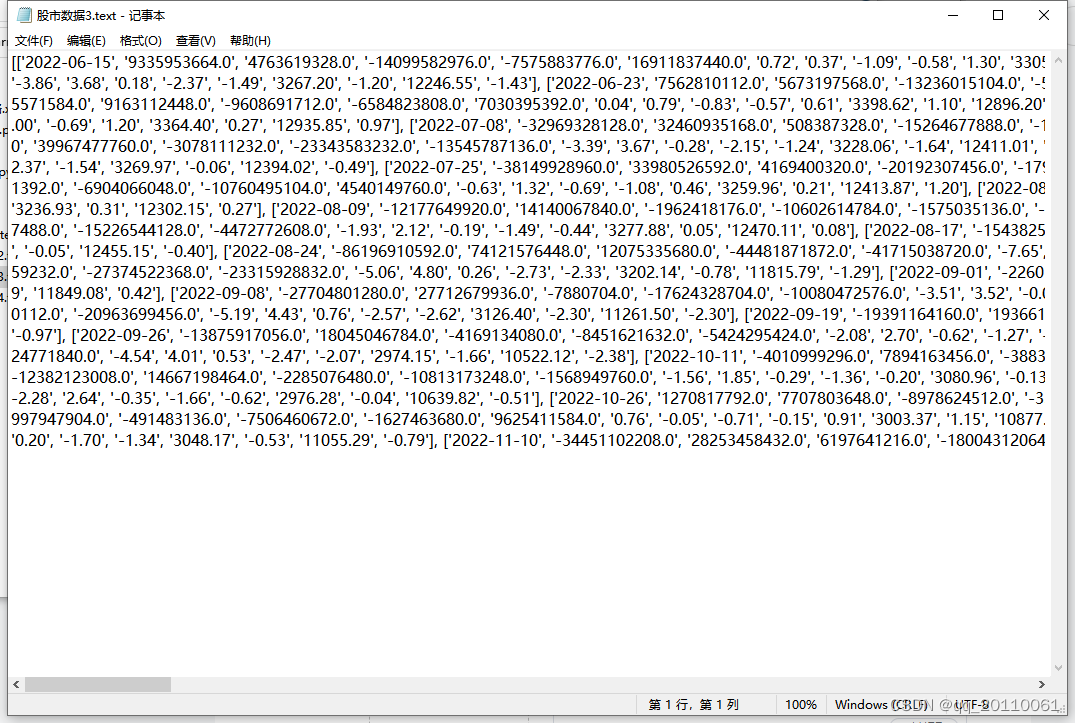
3、
final_datas=[]
k=0
while k<len(mid_datas):
final_datas.append(mid_datas[k][0])
final_datas.append(mid_datas[k][11])
k=k+1
f = open("股市数据4.text",mode="w")
f.write(str(final_datas)) 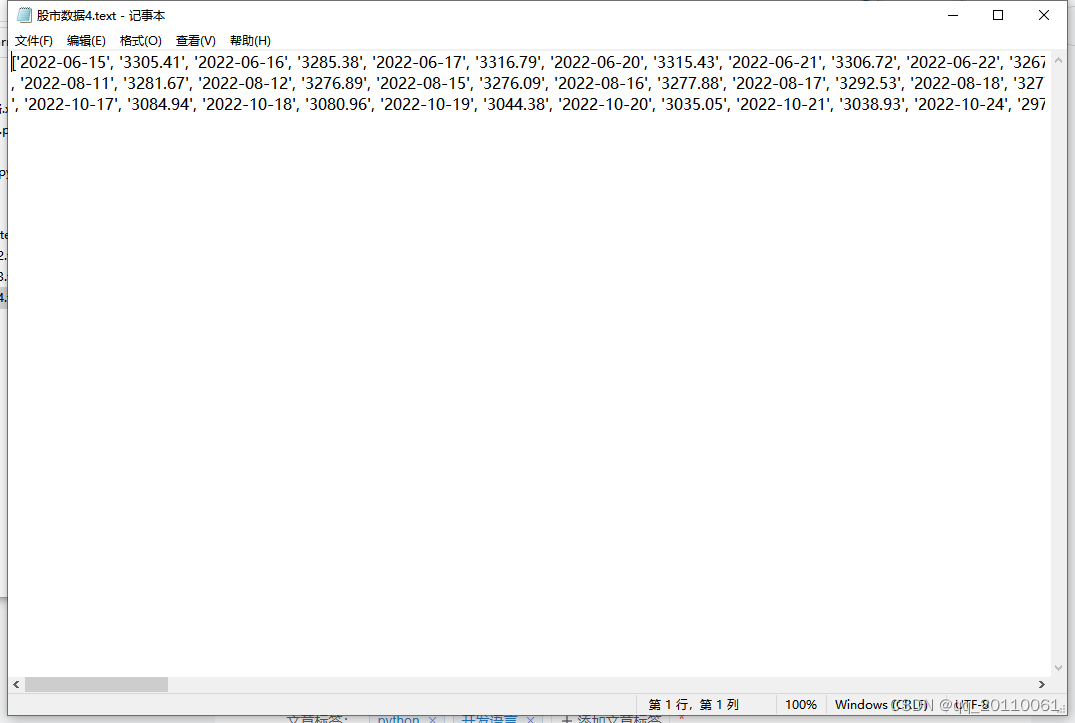
第五步,把text文件里面的数据写入excel中(这步还用教吗?自己不会腾抄是吧😋),实现也比较简单了,用到的是xlwt这个库,还是那句话,不会就查教程,代码如下:
book = xlwt.Workbook(encoding='utf-8',style_compression=0)
sheet = book.add_sheet('股市',cell_overwrite_ok=True)
col = ('日期','收盘价格')
for p in range(0,2):
sheet.write(0,p,col[p])
w=1;e=0
while True:
for l in range(0,2):
sheet.write(w,l,final_datas[e])
e=e+1;
w=w+1
if e>=len(final_datas):
break
savepath=r'C:\Users\xiaojie\PycharmProjects\pythonProject\yuce\excel表格.xls'
book.save(savepath)总结:以上过程都是比较简单的内容(我个人觉得是如果一个完全外行的人看应该是可以得到些灵感和启示的,我的过程和思路还比较清晰,都是一些最基础的爬虫操作),这也是我第一将课外学习的内容用到课程作业上去,对我来说还挺有意义的。其实这段时间也是将爬虫发扬光大,弄了一个很有意思的程序,但是这里不方便展示。
写完了,下班!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









