







Java学习篇(一)| 如何生成分布式全局唯一ID
一、使用场景
全局唯一ID在电商购物、社交网络、金融系统、分布式数据库和缓存、物联网等场景下都尤为重要。
它确保了数据的唯一性、一致性、安全性和高效性,是现代软件开发和系统设计中不可或缺的一部分。
二、常用方法
解决方案根据自己项目需求进行设计调整
1、UUID (尽量不要用)
UUID (Universally Unique Identifier),通用唯一识别码的缩写。UUID是由一组32位数的16进制数字所构成,所以UUID理论上的总数为16^32=2^128,约等于3.4 x 10^38。也就是说若每纳秒产生1兆个UUID,要花100亿年才会将所有UUID用完。 生成的UUID是由 8-4-4-4-12格式的数据组成,其中32个字符和4个连字符’ - ',一般我们使用的时候会将连字符删除 uuid.toString().replaceAll("-","")。
目前UUID的产生方式有5种版本,每个版本的算法不同,应用范围也不同。
- 版本1:
基于时间的UUID这个一般是通过当前时间,随机数,和本地Mac地址来计算出来,可以通过 org.apache.logging.log4j.core.util包中的 UuidUtil.getTimeBasedUuid()来使用或者其他包中工具。由于使用了MAC地址,因此能够确保唯一性,但是同时也暴露了MAC地址,私密性不够好。 - 版本2 :DCE(Distributed Computing Environment)
DCE安全的UUID安全的UUID和基于时间的UUID算法相同,但会把时间戳的前4位置换为POSIX的UID或GID。这个版本的UUID在实际中较少用到。 - 版本3:
基于名字的UUID(MD5)- 版本3 基于名字的UUID通过计算名字和名字空间的MD5散列值得到。这个版本的UUID保证了:相同名字空间中不同名字生成的UUID的唯一性;不同名字空间中的UUID的唯一性;相同名字空间中相同名字的UUID重复生成是相同的。 - 版本4:
随机UUID-根据随机数,或者伪随机数生成UUID。这种UUID产生重复的概率是可以计算出来的,但是重复的可能性可以忽略不计,因此该版本也是被经常使用的版本。JDK中使用的就是这个版本。 - 版本5:
基于名字的UUID(SHA1)- 版本5 和基于名字的UUID算法类似,只是散列值计算使用SHA1(Secure Hash Algorithm 1)算法。
Java中 JDK自带的 UUID产生方式就是版本4根据随机数生成的 UUID 和版本3基于名字的 UUID,有兴趣的可以去看看它的源码。
public static void main(String[] args) {
//获取一个版本4根据随机字节数组的UUID。
UUID uuid = UUID.randomUUID();
System.out.println(uuid.toString().replaceAll("-",""));
//获取一个版本3(基于名称)根据指定的字节数组的UUID。
byte[] nbyte = {1, 2, 3};
UUID uuidFromBytes = UUID.nameUUIDFromBytes(nbyte);
System.out.println(uuidFromBytes.toString().replaceAll("-",""));
}
优点:属于本地解决方案,无网络消耗
缺点:
- 不易于存储:UUID太长,16字节128位,通常以36长度的字符串表示,很多场景不适用
- MAC 地址提供了唯一性的保证,但也带来安全风险,最糟的是它是字符串形式,占用空间大,查询性能低,无法保证趋势递增
- ID作为主键时在特定的环境会存在一些问题,比如做DB主键的场景下,UUID就非常不适用:
- MySQL官方有明确的建议主键要尽量越短越好,36个字符长度的UUID不符合要求
- 对MySQL索引不利:如果作为数据库主键,在InnoDB引擎下,UUID的无序性可能会引起数据位置频繁变动,严重影响性能
2、数据库自增 (用的最多-但不适合做分布式ID)
这种方式也是我们用的最多的方式,通常使用数据库自增,不同数据库自增命令可能不同,
以MySQL为例,直接设置AUTO_INCREMENT就可以使主键自增。
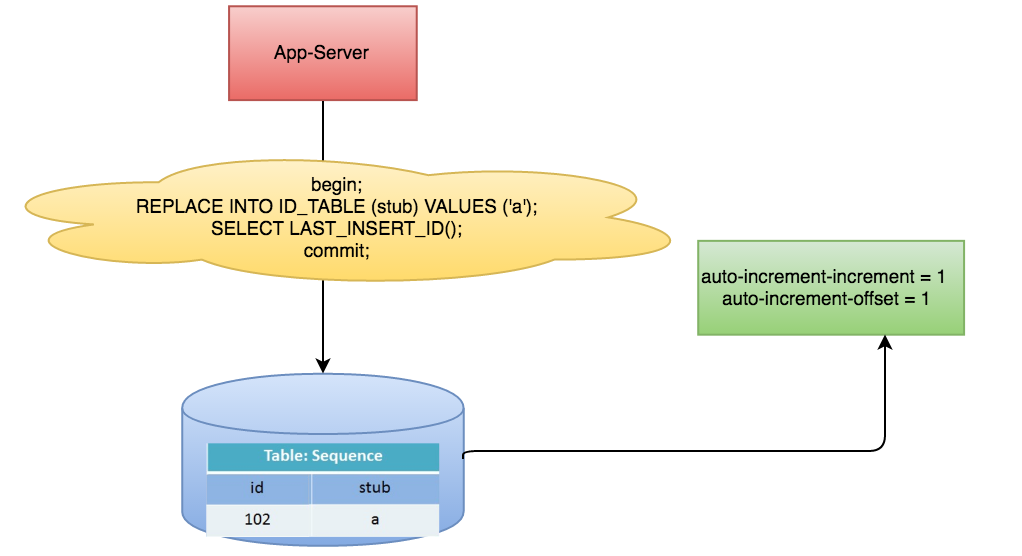
优点:
- 单体项目实现简单,命令即可设置,成本小,有DBA专业维护
- 生成的ID有序,可以实现一些对ID有特殊要求的业务。
缺点:
- 不同数据库语法或实现不同,数据库迁移的时候需要处理
- 在单个数据库或读写分离或一主多从多情况下,只有一个主库可以生成ID,有单点故障的风险
- 在性能达不到要求的情况下比较难以扩展
- 数据迁移或者系统数据合并比较麻烦
- 分库分表时会比较麻烦
- ID发号性能瓶颈限制在单台MySQL的读写性能
3、Redis 生成ID (可用)
1、原因
1、数据库自增ID是有序增长的很容易就被人猜到,比如我现在下一单看到的订单ID为999那么就知道你的系统里最多只有999单,
2、这种自增ID没有意义,而且不同业务的自增ID是重合的,对于信息区分度很低,而且考虑到多业务交互和用户端展示也都是不合适的,想想看要是你在某宝下单,订单ID是999,或者在对接别人订单系统时,给你的订单ID是999是不是很奇怪。
3、当存在分库分表设计时,自增ID的操作就会导致无法实现唯一性
那应该如何通过Redis来设计一个分布式全局唯一ID生成工具?
用户下单调用下单逻辑,先进行业务逻辑处理,然后携带订单ID标识通过分布式全局唯一ID工具获取一个唯一的订单ID,这个订单ID标识就是用于区分业务的,获取到订单ID后将数据组装入库,分布式全局唯一ID工具可以做成一个内嵌的utils,也可以封装成一个独立的jar,还可以做成一个分布式全局唯一ID生成服务供其它业务服务调用。

使用 Redis 计数器实现
Redis的String结构提供了计数器自增功能,类似Java中的原子类,还要优于Java的原子类,
因为Redis是单线程执行的缓存读写本身就是线程安全的,也不用进行原子类的乐观锁操作,
每一次获取分布式全局唯一ID时就将自增序列加1。
# 给key为GENERATEID:NO的value自增1,如果这key不存在则会添加到Redis中并且设置value为1
## GENERATEID:key前缀
## NO:订单ID标识
127.0.0.1:6379> incr GENERATEID:NO
(integer) 1
使用 Redis Hash结构实现
Redis Hash结构中的每一个field也可以进行自增操作,可以用一个Hash结构存储所有的标识信息和自增序列,方便管理,比较适合并发不高的小项目所有服务都是用的一个Redis,如果并发较高就不合适了,毕竟Redis操作普通String结构肯定比操作Hash结构快。
# 给key为GENERATEID,field为no的value自增1,如果这key不存在则会添加到Redis中并且设置value为1
## GENERATEID:分布式全局唯一ID Hash key
## NO:Hash结构中的field
127.0.0.1:6379> hincrby GENERATEID NO 1
(integer) 1
2、通过代码实现分布式全局唯一ID工具 (正式使用)
这里
使用Redis 计数器实现,自增序列以天为单位存储,
在实际业务中,比如生成订单编号组成规则都类似NO1699631999000-1(业务标识key+当前时间戳+自增序列),这个规则可以自己定义,保证最终生成的订单编号不重复即可,不建议直接一个自增序列干到底。
订单编号这类型的数据都是有长度限制的,或者是要求生成20字符的订单编号,如果增长的过长反而不好处理。
3、编写获取工具
@Component
public class RedisGenerateIDUtils {
@Resource
private RedisTemplate<String, Object> redisTemplate;
// key前缀
private String PREFIX = "GENERATEID:";
/**
* 获取全局唯一ID
* @param key 业务标识key
*/
public String generateId(String key) {
// 获取对应业务自增序列
Long incr = getIncr(key);
// 组装最后的结果,这里可以根据需要自己定义,这里是按照业务标识key+当前时间戳+自增序列进行组装
String resultID = key + System.currentTimeMillis() + "-" + incr;
return resultID;
}
/**
* 获取对应业务自增序列
*/
private Long getIncr(String key) {
String cacheKey = getCacheKey(key);
Long increment = 0L;
// 判断Redis中是否存在这个自增序列,如果不存在添加一个序列并且设置一个过期时间
if (!redisTemplate.hasKey(cacheKey)) {
// 这里存在线程安全问题,需要加分布式锁,这里做简单实现
String lockKey = cacheKey + "_LOCK";
// 设置分布式锁
boolean lock = redisTemplate.opsForValue().setIfAbsent(lockKey, 1, 30, TimeUnit.SECONDS);
if (!lock) {
// 如果没有拿到锁进行自旋
return getIncr(key);
}
increment = redisTemplate.opsForValue().increment(cacheKey);
// 我这里设置24小时,可以根据实际情况设置当前时间到当天结束时间的插值
redisTemplate.expire(cacheKey, 24, TimeUnit.HOURS);
// 释放锁
redisTemplate.delete(lockKey);
} else {
increment = redisTemplate.opsForValue().increment(cacheKey);
}
return increment;
}
/**
* 组装缓存key
*/
private String getCacheKey(String key) {
return PREFIX + key + ":" + getYYYYMMDD();
}
/**
* 获取当前YYYYMMDD格式年月日
*/
private String getYYYYMMDD() {
LocalDate currentDate = LocalDate.now();
int year = currentDate.getYear();
int month = currentDate.getMonthValue();
int day = currentDate.getDayOfMonth();
return "" + year + month + day;
}
}
4、测试获取工具
@RunWith(SpringRunner.class)
@SpringBootTest(classes = RedisUniqueIdDemoApplication.class)
class RedisUniqueIdDemoApplicationTests {
@Resource
private RedisGenerateIDUtils redisGenerateIDUtils;
@Test
public void test() throws InterruptedException {
// 定义一个线程池 设置核心线程数和最大线程数都为100,队列根据需要设置
ThreadPoolExecutor executor = new ThreadPoolExecutor(100, 100, 10, TimeUnit.SECONDS, new LinkedBlockingQueue<>(10000));
CountDownLatch countDownLatch = new CountDownLatch(10000);
long beginTime = System.currentTimeMillis();
// 获取10000个全局唯一ID 看看是否有重复
CopyOnWriteArraySet<String> ids = new CopyOnWriteArraySet<>();
for (int i = 0; i < 10000; i++) {
executor.execute(() -> {
// 获取全局唯一ID
long beginTime02 = System.currentTimeMillis();
String orderNo = redisGenerateIDUtils.generateId("NO");
System.out.println(orderNo);
System.out.println("获取单个ID耗时 time=" + (System.currentTimeMillis() - beginTime02));
if (ids.contains(orderNo)) {
System.out.println("重复ID=" + orderNo);
} else {
ids.add(orderNo);
}
countDownLatch.countDown();
});
}
countDownLatch.await();
// 打印获取到的全局唯一ID集合数量
System.out.println("获取到全局唯一ID count=" + ids.size());
System.out.println("耗时毫秒 time=" + (System.currentTimeMillis() - beginTime));
}
}
知识小贴士:关于countdownlatch
(这是在模拟100个请求并发获取1w个后再结束的操作所涉及的 多线程相关 知识点,和 获取分布式唯一id 没有直接关系哦)
countdownlatch名为信号枪:主要的作用是同步协调在多线程的等待于唤醒问题
我们如果没有CountDownLatch ,那么由于程序是异步的,当异步程序没有执行完时,主线程就已经执行完了,然后我们期望的是分线程全部走完之后,主线程再走,所以我们此时需要使用到CountDownLatch
CountDownLatch 中有两个最重要的方法
- countDown
- await
await 方法 是阻塞方法,我们担心分线程没有执行完时,main线程就先执行,所以使用await可以让main线程阻塞,那么什么时候main线程不再阻塞呢?当CountDownLatch 内部维护的 变量变为0时,就不再阻塞,直接放行,那么什么时候CountDownLatch 维护的变量变为0 呢,我们只需要调用一次countDown ,内部变量就减少1,我们让分线程和变量绑定, 执行完一个分线程就减少一个变量,当分线程全部走完,CountDownLatch 维护的变量就是0,此时await就不再阻塞,统计出来的时间也就是所有分线程执行完后的时间。
5、总结
通过线程池 我们模拟了100个请求同时去获取全局唯一ID是没问题的,
而且获取单个ID耗时在10-20毫秒左右,一般的业务已经完全够用,这个耗时也要看Redis性能和项目配置决定的。
4、雪花算法(SnowFlake)(可用)
1.雪花算法概念
雪花算法(Snowflake)是一种生成唯一ID的算法,主要应用于分布式系统中。它可以在不依赖于数据库等其他存储设施的情况下,生成全局唯一的ID。
雪花算法生成的ID为64位整数(二进制,全是0和1组成),具体的格式如下:

- 1位符号位:
二进制数据中首位表示正负,这里是0不可变- 41位的时间戳:
41位用来标识时间戳,最大值可容纳是2的41次方( 2199023255552 ),换算转成时间的话就是可以用69年(从1970年开始算),所以建议在设置起始时间戳时,请用上线的时间,这样子就可以保证该系统69年的唯一id获取。- 10位的机器位:
机器位最大为10位,一般做法是5位用于机房id的标识,5位用于机器id的标识。这样无论是机房和机器都可以最大容纳2的五次方减1(31)的数量。不过实际使用时可以根据实际情况进行调整,因为机房数量一般也到不了31,就是机器数量到达31的也不多。所以可以根据实际情况来进行调整机器位10个bit的分配。- 12位的随机数:
12位的随机数最大可以表示2的12次方减1的数据(4095)所以也就是说最大我们可以在1ms内产生4095个id(时间戳位是ms),那么1s内就是4095000≈400W。而且这是单台机器上的每秒可产生的不重复id,如果横向扩展机器的话,这个值还会更大。所以12位的随机数位是肯定够用的了,当然真正使用时是不能使用随机数的,而是应该进行整数的自增,这样才能保证不重复。
实际情况下,我们是需要把这个二进制转成十进制来作为id使用的哦
2.雪花算法的缺点
由于Snowflake算法生成的ID包含时间戳等信息,因此在使用时需要保证系统时间的准确性。
如果系统时间发生回拨或者误差较大,可能会导致生成的ID出现重复或者乱序的问题。
方式一:自定义的雪花算法 (该工具类已做了回拨处理)
注意!注意!注意!以下代码亲测过,并有详细的注释解说,直接拿走,不谢!!!
public class SnowFlakeUtil {
/**
* 初始时间戳,可以根据业务需求更改时间戳
*/
private final long twepoch = 11681452025134L;
/**
* 机器ID所占位数,长度为5位
*/
private final long workerIdBits = 5L;
/**
* 数据标识ID所占位数,长度位5位
*/
private final long datacenterIdBits = 5L;
/**
* 支持的最大机器id,结果是31 (这个移位算法可以很快的计算出几位二进制数所能表示的最大十进制数)
*/
private final long maxWorkerId = -1L ^ (-1L << workerIdBits);
/**
* 支持的最大数据标识id,结果是31
*/
private final long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);
/**
* 序列在id中占的位数
*/
private final long sequenceBits = 12L;
/**
* 工作机器ID向左移12位
*/
private final long workerIdShift = sequenceBits;
/**
* 数据标识id向左移17位(12+5)
*/
private final long dataCenterIdShift = sequenceBits + workerIdBits;
/**
* 时间截向左移22位(5+5+12)
*/
private final long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;
/**
* 序列号最大值; 生成序列的掩码,这里为4095 (0b111111111111=0xfff=4095)
*/
private final long sequenceMask = -1L ^ (-1L << sequenceBits);
/**
* 工作机器ID(0~31),2进制5位 32位减掉1位 31个
*/
private volatile long workerId;
/**
* 数据中心ID(0~31),2进制5位 32位减掉1位 31个
*/
private volatile long datacenterId;
/**
* 毫秒内序列(0~4095),2进制12位 4096 - 1 = 4095个
*/
private volatile long sequence = 0L;
/**
* 上次时间戳,初始值为负数
*/
private volatile long lastTimestamp = -1L;
// ==============================Constructors=====================================
/**
* 有参构造
* @param workerId 工作机器ID(0~31)
* @param datacenterId 数据中心ID(0~31)
* @param sequence 毫秒内序列(0~4095)
*/
public SnowFlakeUtil(long workerId, long datacenterId, long sequence){
// sanity check for workerId
if (workerId > maxWorkerId || workerId < 0) {
throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0",maxWorkerId));
}
if (datacenterId > maxDatacenterId || datacenterId < 0) {
throw new IllegalArgumentException(String.format("datacenter Id can't be greater than %d or less than 0",maxDatacenterId));
}
System.out.printf("worker starting. timestamp left shift %d, datacenter id bits %d, worker id bits %d, sequence bits %d, workerid %d",
timestampLeftShift, datacenterIdBits, workerIdBits, sequenceBits, workerId);
this.workerId = workerId;
this.datacenterId = datacenterId;
this.sequence = sequence;
}
// ==============================Methods==========================================
/**
* 获得下一个ID (该方法是线程安全的)
* 如果一个线程反复获取Synchronized锁,那么synchronized锁将变成偏向锁。
* @return 生成的ID
*/
public synchronized long nextId() {
// 获取当前时间的时间戳,单位(毫秒)
long timestamp = timeGen();
// 获取当前时间戳如果小于上次时间戳,则表示时间戳获取出现异常
if (timestamp < lastTimestamp) {
System.err.printf("当前时间戳不能小于上次时间戳,上次时间戳为: %d.", lastTimestamp);
throw new RuntimeException(String.format("当前时间戳不能小于上次时间戳,生成ID失败. 时间戳差值: %d milliseconds",
lastTimestamp - timestamp));
}
// 获取当前时间戳如果等于上次时间戳(同一毫秒内),则在序列号加一;否则序列号赋值为0,从0开始。
if (lastTimestamp == timestamp) {
/* 逻辑:意思是说一个毫秒内最多只能有4096个数字,无论你传递多少进来,
这个位运算保证始终就是在4096这个范围内,避免你自己传递个sequence超过了4096这个范围 */
// sequence:毫秒内序列(0~4095); sequenceMask: 序列号最大值;
sequence = (sequence + 1) & sequenceMask;
/* 逻辑:当某一毫秒的时间,产生的id数 超过4095,系统会进入等待,直到下一毫秒,系统继续产生ID */
if (sequence == 0) {
timestamp = tilNextMillis(lastTimestamp);
}
} else {
sequence = 0;
}
// 将上次时间戳值刷新(逻辑:记录一下最近一次生成id的时间戳,单位是毫秒)
lastTimestamp = timestamp;
/* 核心逻辑:生成一个64bit的id;
先将当前时间戳左移,放到41 bit那儿;
将机房id左移放到5 bit那儿;
将机器id左移放到5 bit那儿;
将序号放最后12 bit
最后拼接起来成一个64 bit的二进制数字,转换成10进制就是个long型 */
/*
* 返回结果:
* (timestamp - twepoch) << timestampLeftShift) 表示将时间戳减去初始时间戳,再左移相应位数
* (datacenterId << datacenterIdShift) 表示将数据id左移相应位数
* (workerId << workerIdShift) 表示将工作id左移相应位数
* | 是按位或运算符,例如:x | y,只有当x,y不为0的时候结果才为0,其它情况结果都为1。
* 因为个部分只有相应位上的值有意义,其它位上都是0,所以将各部分的值进行 | 运算就能得到最终拼接好的id
*/
return ((timestamp - twepoch) << timestampLeftShift) |
(datacenterId << dataCenterIdShift) |
(workerId << workerIdShift) |
sequence;
}
/**
* 上次时间戳与当前时间戳进行比较
* 逻辑:当某一毫秒的时间,产生的id数 超过4095,系统会进入等待,直到下一毫秒,系统继续产生ID
* @param lastTimestamp 上次时间戳
* @return 若当前时间戳小于等于上次时间戳(时间回拨了),则返回最新当前时间戳; 否则,返回当前时间戳
*/
private long tilNextMillis(long lastTimestamp) {
long timestamp = timeGen();
while (timestamp <= lastTimestamp) {
timestamp = timeGen();
}
return timestamp;
}
/**
* 获取系统时间戳
* @return 当前时间的时间戳 14位
*/
private long timeGen(){
return System.currentTimeMillis();
}
public static void main(String[] args) {
SnowFlakeUtil snowFlakeUtil = new SnowFlakeUtil(1,1,0);
System.out.println(snowFlakeUtil.timeGen());
for (int i = 0; i < 100; i++) {
System.out.println("雪花算法生成第【"+(i+1)+"】个ID:"+ snowFlakeUtil.nextId());
}
}
}
以上代码执行结果:
雪花算法生成第【1】个ID:-5049534853385416704
雪花算法生成第【2】个ID:-5049534853385416703
雪花算法生成第【3】个ID:-5049534853385416702
雪花算法生成第【4】个ID:-5049534853385416701
雪花算法生成第【5】个ID:-5049534853385416700
雪花算法生成第【6】个ID:-5049534853385416699
雪花算法生成第【7】个ID:-5049534853385416698
雪花算法生成第【8】个ID:-5049534853385416697
雪花算法生成第【9】个ID:-5049534853385416696
雪花算法生成第【10】个ID:-5049534853385416695
……
……
…… (之后的结果就不一一展示了)
以上代码在遇到时间回拨的情况下,仍然能够获取到唯一的ID。
在常规的时间回拨场景下(如NTP同步导致的轻微时间调整),这段代码是足够健壮的。
方式二:基于hutool工具类
第一步:引入hutool工具依赖包
<!-- hutool工具类 -->
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.3.1</version>
</dependency>
第二步:Springboot整合具体代码实现
import cn.hutool.core.lang.Snowflake;
import cn.hutool.core.net.NetUtil;
import cn.hutool.core.util.IdUtil;
import javax.annotation.PostConstruct;
/**
* SpringtBoot整合雪花算法 (基于hutool工具类)
*/
public class SnowFlakeHutoolTestController {
/**
* 工作机器ID(0~31),2进制5位 32位减掉1位 31个
*/
private long workerId = 0;
/**
* 数据中心ID(0~31),2进制5位 32位减掉1位 31个
*/
private long datacenterId = 1;
/**
* 雪花算法对象
*/
private Snowflake snowFlake = IdUtil.createSnowflake(workerId, datacenterId);
@PostConstruct
public void init() {
try {
// 将网络ip转换成long
workerId = NetUtil.ipv4ToLong(NetUtil.getLocalhostStr());
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 获取雪花ID,默认使用网络IP作为工作机器ID
* @return ID
*/
public synchronized long snowflakeId() {
return this.snowFlake.nextId();
}
/**
* 获取雪花ID
* @param workerId 工作机器ID
* @param datacenterId 数据中心ID
* @return ID
*/
public synchronized long snowflakeId(long workerId, long datacenterId) {
Snowflake snowflake = IdUtil.createSnowflake(workerId, datacenterId);
return snowflake.nextId();
}
public static void main(String[] args) {
SnowFlakeHutoolTestController snowFlakeDemo = new SnowFlakeHutoolTestController();
for (int i = 0; i < 20; i++) {
int finalI = i;
new Thread(() -> {
System.out.println("雪花算法生成第【"+(finalI +1)+"】个ID:"+ snowFlakeDemo.snowflakeId());
}, String.valueOf(i)).start();
}
}
}
以上代码执行结果:
雪花算法生成第【2】个ID:1646777064113700865
雪花算法生成第【5】个ID:1646777064113700868
雪花算法生成第【3】个ID:1646777064113700866
雪花算法生成第【4】个ID:1646777064113700867
雪花算法生成第【1】个ID:1646777064113700864
雪花算法生成第【11】个ID:1646777064113700873
雪花算法生成第【10】个ID:1646777064113700872
雪花算法生成第【8】个ID:1646777064113700871
雪花算法生成第【7】个ID:1646777064113700870
雪花算法生成第【6】个ID:1646777064113700869
雪花算法生成第【16】个ID:1646777064113700877
雪花算法生成第【13】个ID:1646777064113700876
雪花算法生成第【12】个ID:1646777064113700875
雪花算法生成第【9】个ID:1646777064113700874
雪花算法生成第【17】个ID:1646777064113700881
雪花算法生成第【19】个ID:1646777064113700880
雪花算法生成第【15】个ID:1646777064113700879
雪花算法生成第【14】个ID:1646777064113700878
雪花算法生成第【20】个ID:1646777064113700883
雪花算法生成第【18】个ID:1646777064113700882
方式三:使用 百度 Uidgenerator(基于SnowFlake算法改造的)
待记录
方式四:使用 美团Leaf(基于SnowFlake算法改造的)
待记录
三、前端直接使用发生精度丢失
如果前端直接使用服务端生成的long 类型 id,会发生精度丢失的问题,因为 JS 中Number是16位的(指的是十进制的数字)
而雪花算法计算出来最长的数字是19位的,这个时候需要用 String 作为中间转换,输出到前端即可。
参考文章
【1】分布式全局唯一ID生成方案(附源码)
【2】redis实现分布式全局唯一id
【3】使用 Redis 实现生成分布式全局唯一ID(使用SpringBoot环境实现)
【4】分布式Id生成之雪花算法(SnowFlake)
【5】SpringBoot实战:设备唯一ID生成【雪花算法、分布式应用】















 698
698

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









