







python用的是3.5版本,用到的模块有urllib,re,json,request,codecs
在极客学院,慕课网,网易云课堂学了差不多一个月的python了,想试试自己写一个爬虫,参考了一下人家的小程序,花了一天时间磕磕碰碰终于码出来了,记录一下学习过程。很多地方还不是很懂,慢慢摸熟。程序的主要功能是爬取腾讯视频里《花千骨》58集的每一集的用户评论(程序每一集只爬了10条,节省点时间)
先放出源代码。
# coding:utf-8
import urllib.request
import json
import re
import requests
import codecs
# request head
head = {'User-Agent': \
'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/43.0.2357.130 Safari/537.36'}
# 查找并返回网页vid,测试用的,实际程序没用到
def find_vid(web_adress):
html_text = urllib.request.urlopen(web_adress).read()
tag1 = re.findall(r'var .+?};', str(html_text))
tag = ''
for eco in tag1:
tag2 = re.findall(r'vid: "(.+?)",', eco)
if not tag2 == []:
tag = tag2[0]
return tag
# 查找并返回网页的comment_id
def find_comment_id(web_adress):
html_text = urllib.request.urlopen(web_adress).read()
tag = re.findall(r'"comment_id":"(\d+)"', str(html_text))
return tag[0]
web_orig = r'http://v.qq.com/detail/q/qviv9yyjn83eyfu.html' # 《花千骨》首页
html_text = urllib.request.urlopen(web_orig).read() # 读取html源代码
# 在html文件中找到58季的vid
tag1 = re.findall(r'<a href=".+?vid=.+?</a>', str(html_text))
tag2 = list()
for i in tag1:
if r'episodeNumber' in i:
tag2.append(i)
vid = list()
for i in tag2:
vid = vid + re.findall(r'vid=(.+?)"', i)
# 把评论存在文档里
file = codecs.open('comment.txt', 'w+','utf-8')
for i in vid:
web_find_comment_id = r'http://ncgi.video.qq.com/fcgi-bin/video_comment_id?otype=json&op=1&vid=' + i
comment_id = find_comment_id(web_find_comment_id)
web_json = 'http://coral.qq.com/article/' + comment_id + '/comment?commentid=0&reqnum=20'
jscontent = requests.get(web_json, headers=head).content
jsDict = json.loads(jscontent.decode())
jsData = jsDict['data']
comments = jsData['commentid']
for each in comments:
# print(each['content'].encode('utf-8').decode())
file.write(str(each['content']))
file.write('\n')
file.close()
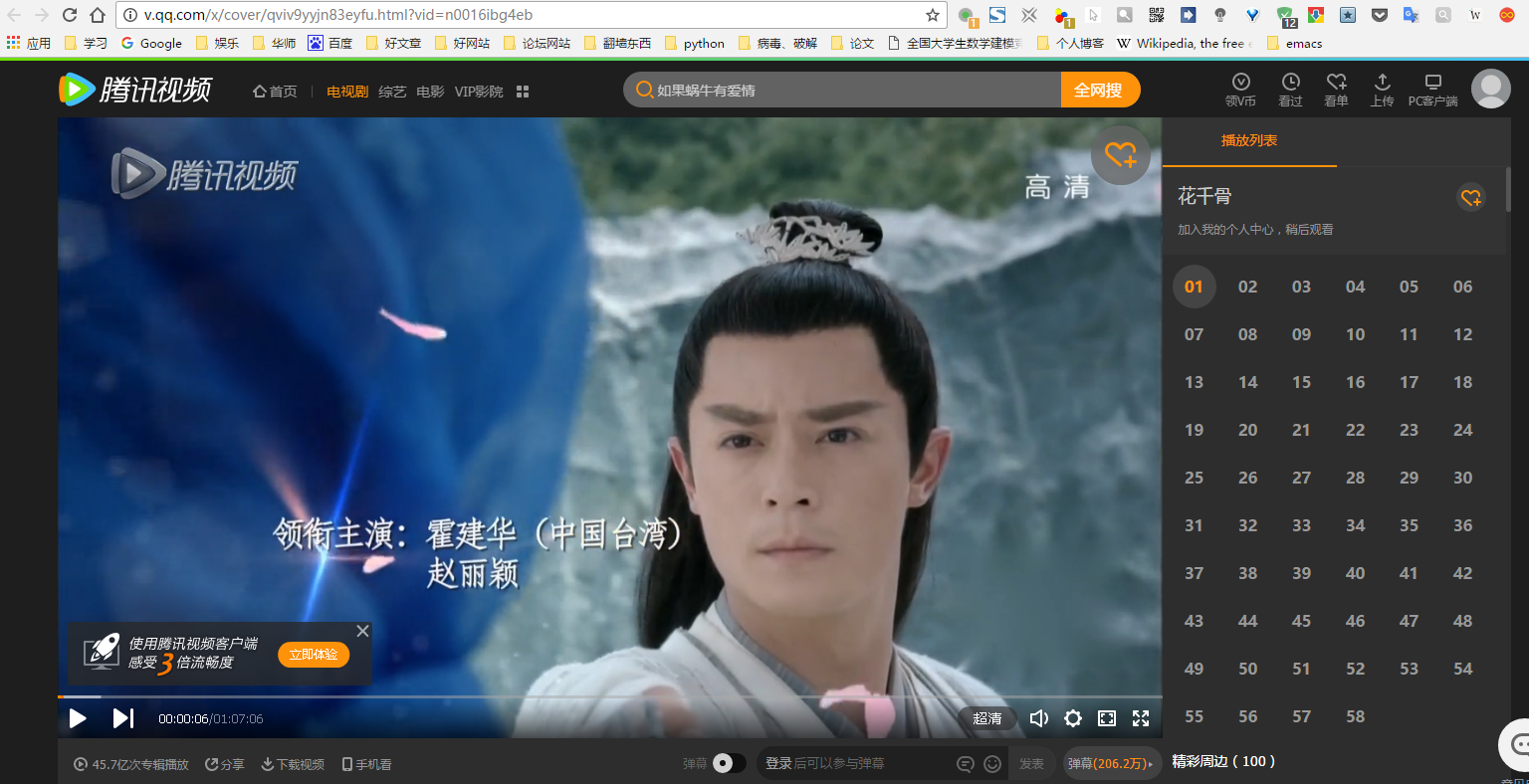
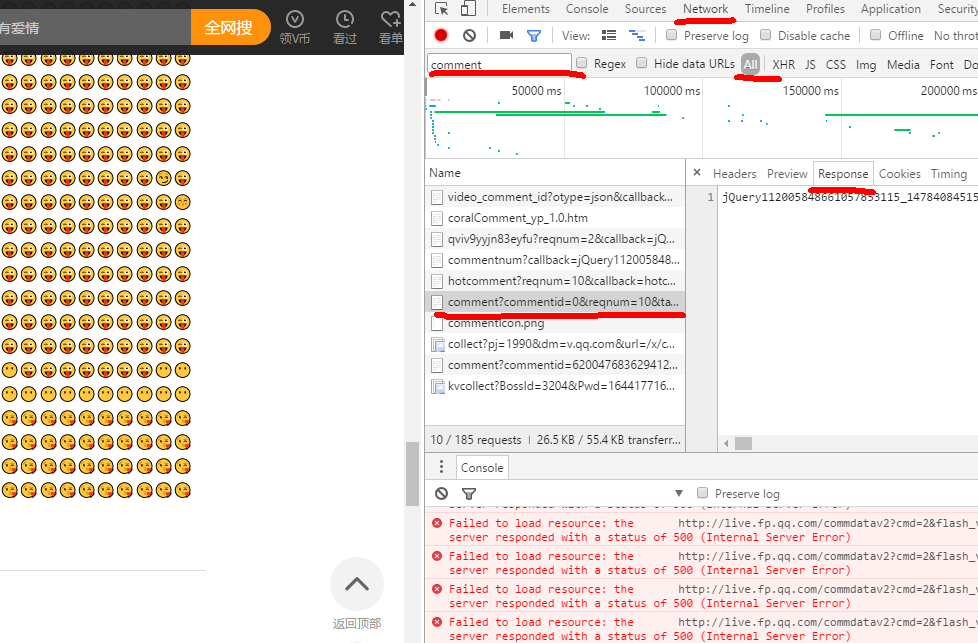
关键的几个按钮已经画出来了。要找comment这个文件是通过下来看下面的评论点击更多的时候会有很多文档加载,一开始要逐个逐个审查才能知道comment这个文档是存放评论的。双击comment文档跳转到存放评论的页面
评论的加载是用了json技术,是动态网页,通过修改后面的reqnum的数字来增加评论,后面的一串代码可以删掉,不影响。去查看《花千骨》首页的html源码是没有显示这些内容的,说明这是json动态网页,爬取动态 网页跟静态网页多了一些步骤。对网页后面的网址进行修改,查看哪些是我们必要的,还没学数据库只能这样一步一步来。
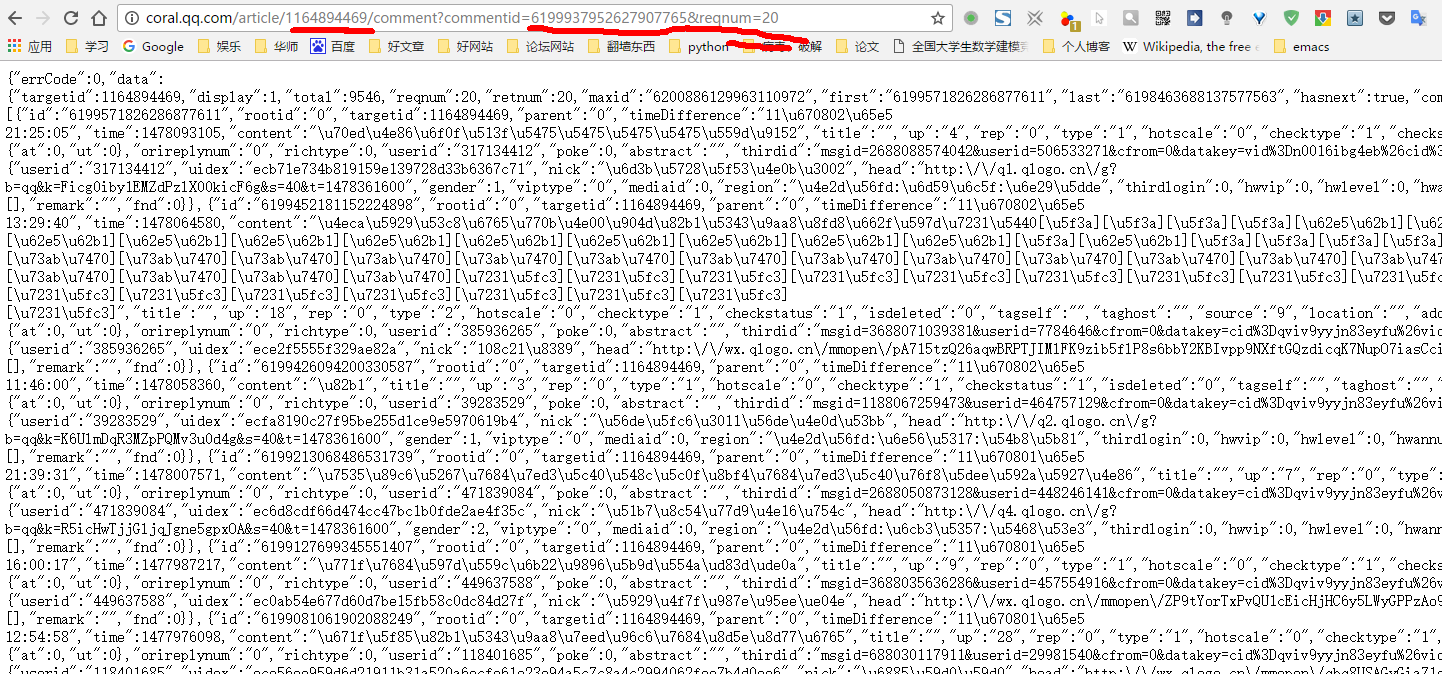
在comment的网址里有两个重要的数字:1164894469, 6199937952627907765。其中经过测试6178065997993949867是随机的,可以改成0,而1410730408是固定的,要从网页中获取。(现阶段做爬虫只能这样逐个审查元素的,毕竟我还没学网页的制作,只能这样摸着墙壁走路了)。爬取动态网页的难点就在这里,怎么才能让程序自动找到这串数字。首先我们可以到首页的源码里面查找一下是否存在这串数字,发现是没有的。但是我们返回到审网页的元素查看那里通过过滤器能找到存放comment_id这个ID的JSON文件。很像我们查找comment的json文件一样。
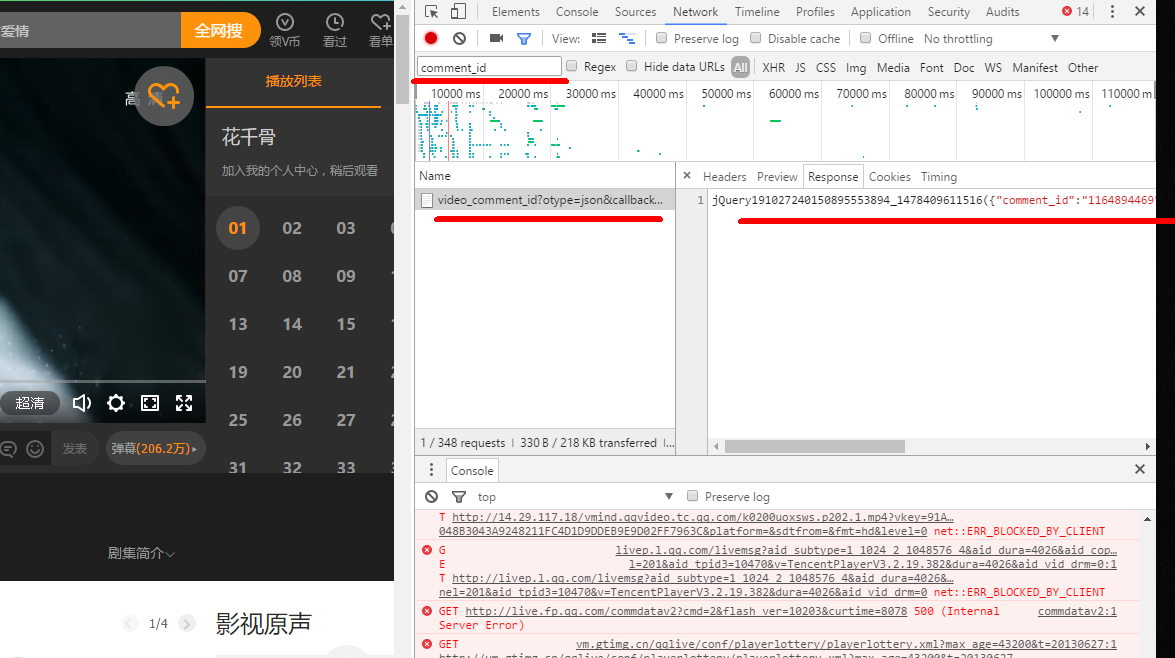
双击进入到这个文件,能看到里面有我们需要的comment_id就是1164894469。但是这个地址太长了,逐步删除部分内容,只要能显示出我们需要的comment_id就可以了。最终得到http://ncgi.video.qq.com/fcgi-bin/video_comment_id?otype=json&op=3&vid=n0016ibg4eb
这个地址就是最精简的了。经测试op的数字可以改成1,2,3等数字,而vid猜猜意思应该就是video_id的意思,就是视频的id,可以到通过html源码来审查出n0016ibg4eb就是第一集的vid,后面的58集也在html中能找到。
所以现在的思路很清晰了,python通过在花千骨首页的html源代码找出58集视频的vid,然后通过vid找出comment_id,最后就能找到用户评论的json文件了。顺便说说在用户评论的json文件里面评论是在里面的content里,python里面的字典功能能轻松把评论突出出来。
在写爬虫的时候遇到的困难主要是怎么找出comment的json文件,怎么找出comment_id,怎么只把58集的comment选出来(首页里面还有很多视频连接,所有有很多个vid,怎么通过re模块筛选出来我看了html文件对比了很久,以后应该轻松很多了吧。),最后的问就是编码问题了。python的编码问题真的很坑新手,特别是我不知道表情图的编码的存在,不能中文和表情很好地写入到文件里。找了一下资料发现现在是用GB18030的编码,通过codecs这个模块终于顺利地把中文和表情写入到文件里。
记录一下自己第一次写的小小爬虫,准备做语言分析,不知道还有多少坑要爬呢。
希望有大神指教指教。















 3322
3322

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









