







之前我的一篇博客是模拟日志收集到hdfs上面(详情见:http://blog.csdn.net/qq_20641565/article/details/52807776)以及Azkaban的安装(详情见:http://blog.csdn.net/qq_20641565/article/details/52814048),现在用java编写mapreduce程序通过Azkaban进行调度,编写四个简单的mapreduce 程序,这样放到Azkaban上面去调度能较好的体现出依赖关系,其中PersonAvg、ZhenAvg、XianAvg依赖于FormatLog这个job。
ps:其中这几个mapreduce程序的输入输出路径以及调度的时间格式为名字的文件夹(eg:hdfs://lijie:9000/flume/20161013/ 这个20161013文件夹)都是需要从调度的时候传入参数,但是我为了简便直接写死到了程序里面。
图片后面我更换了几张,所以可能有的运行时间不对。
FormatLog:用于格式化搜集到的数据。
PersonAvg:用于统计所有人的平均积蓄
ZhenAvg:用于统计每个镇的个人平均积蓄
XianAvg:用于统计每个县的个人平均积蓄
1.mapreduce程序如下:
FormatLog:
package com.lijie.demo4azkaban.avg;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class FormatLog extends Configured implements Tool {
public static void main(String[] args) throws Exception {
String[] args1 = { "hdfs://lijie:9000/flume/20161013/*",
"hdfs://lijie:9000/flume/format/20161013" };
int run = ToolRunner.run(new Configuration(), new FormatLog(), args1);
System.exit(run);
}
public static class FormatLogMap extends Mapper<LongWritable, Text, Text, Text> {
@Override
protected void map( LongWritable key, Text value,
Mapper<LongWritable, Text, Text, Text>.Context context) throws IOException,
InterruptedException {
String[] split = value.toString().split("\\|");
if (split.length == 2) {
Text valueNew = new Text(split[1].trim());
context.write(new Text(""), valueNew);
}
}
}
@Override
public int run(String[] args) throws Exception {
Configuration conf = new Configuration();
Path dest = new Path(args[args.length - 1]);
FileSystem fs = dest.getFileSystem(conf);
if (fs.isDirectory(dest)) {
fs.delete(dest, true);
}
Job job = new Job(conf, "formatLog");
job.setJarByClass(FormatLog.class);
job.setMapperClass(FormatLogMap.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path(args[args.length - 2]));
FileOutputFormat.setOutputPath(job, dest);
return job.waitForCompletion(true) ? 0 : 1;
}
}
PersonAvg:
package com.lijie.demo4azkaban.avg;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class PersonAvg extends Configured implements Tool {
public static void main(String[] args) throws Exception {
String[] args1 = { "hdfs://lijie:9000/flume/format/20161013/*",
"hdfs://lijie:9000/flume/format/20161013/personout" };
int run = ToolRunner.run(new Configuration(), new PersonAvg(), args1);
System.exit(run);
}
@Override
public int run(String[] args) throws Exception {
Configuration conf = new Configuration();
Path dest = new Path(args[1]);
FileSystem fs = dest.getFileSystem(conf);
if (fs.isDirectory(dest)) {
fs.delete(dest, true);
}
Job job = new Job(conf, "personAvg");
job.setJarByClass(PersonAvg.class);
job.setMapperClass(PersonAvgMap.class);
job.setReducerClass(PersonAvgReduce.class);
job.setMapOutputKeyClass(Text.class);//map 输出key类型
job.setMapOutputValueClass(Text.class);//map 输出value类型
job.setOutputKeyClass(Text.class);//输出结果 key类型
job.setOutputValueClass(Text.class);//输出结果 value 类型
FileInputFormat.addInputPath(job, new Path(args[0]));// 输入路径
FileOutputFormat.setOutputPath(job, new Path(args[1]));// 输出路径
return job.waitForCompletion(true) ? 0 : 1;//提交任务
}
public static class PersonAvgMap extends Mapper<LongWritable, Text, Text, Text> {
@Override
protected void map( LongWritable key, Text value,
Mapper<LongWritable, Text, Text, Text>.Context context) throws IOException,
InterruptedException {
String[] split = value.toString().split("####");
if (split.length == 4) {
if (null == split[3] || "".equals(split[3])) {
split[3] = "0";
}
context.write(new Text("1"), new Text(split[3]));
}
}
}
public static class PersonAvgReduce extends Reducer<Text, Text, Text, Text> {
private long count = 0;
private double sum = 0;
private double avg = 0;
@Override
protected void reduce( Text key, Iterable<Text> values,
Reducer<Text, Text, Text, Text>.Context context) throws IOException,
InterruptedException {
for (Text text : values) {
count = count + 1;
sum = sum + Double.parseDouble(text.toString().trim());
}
avg = sum / count;
context.write(key, new Text(avg + ""));
}
}
}
ZhenAvg:
package com.lijie.demo4azkaban.avg;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class ZhenAvg extends Configured implements Tool {
public static void main(String[] args) throws Exception {
String[] args1 = { "hdfs://lijie:9000/flume/20161013/*",
"hdfs://lijie:9000/flume/format/20161013/zhenout" };
int run = ToolRunner.run(new Configuration(), new ZhenAvg(), args1);
System.exit(run);
}
@Override
public int run(String[] args) throws Exception {
Configuration conf = new Configuration();
Path dest = new Path(args[1]);
FileSystem fs = dest.getFileSystem(conf);
if (fs.isDirectory(dest)) {
fs.delete(dest, true);
}
Job job = new Job(conf, "ZhenAvg");
job.setJarByClass(ZhenAvg.class);
job.setMapperClass(ZhenAvgMap.class);
job.setReducerClass(ZhenAvgReduce.class);
job.setMapOutputKeyClass(Text.class);//map 输出key类型
job.setMapOutputValueClass(Text.class);//map 输出value类型
job.setOutputKeyClass(Text.class);//输出结果 key类型
job.setOutputValueClass(Text.class);//输出结果 value 类型
FileInputFormat.addInputPath(job, new Path(args[0]));// 输入路径
FileOutputFormat.setOutputPath(job, new Path(args[1]));// 输出路径
return job.waitForCompletion(true) ? 0 : 1;//提交任务
}
public static class ZhenAvgMap extends Mapper<LongWritable, Text, Text, Text> {
@Override
protected void map( LongWritable key, Text value,
Mapper<LongWritable, Text, Text, Text>.Context context) throws IOException,
InterruptedException {
String[] split = value.toString().split("####");
if (split.length == 4) {
if (null == split[3] || "".equals(split[3])) {
split[3] = "0";
}
context.write(new Text(split[1] + "-" + split[2]), new Text(split[3]));
}
}
}
public static class ZhenAvgReduce extends Reducer<Text, Text, Text, Text> {
private long count = 0;
private double sum = 0;
private double avg = 0;
@Override
protected void reduce( Text key, Iterable<Text> values,
Reducer<Text, Text, Text, Text>.Context context) throws IOException,
InterruptedException {
for (Text text : values) {
count = count + 1;
sum = sum + Double.parseDouble(text.toString().trim());
}
avg = sum / count;
context.write(key, new Text(avg + ""));
}
}
}
XianAvg:
package com.lijie.demo4azkaban.avg;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class XianAvg extends Configured implements Tool {
public static void main(String[] args) throws Exception {
String[] args1 = { "hdfs://lijie:9000/flume/format/20161013/*",
"hdfs://lijie:9000/flume/format/20161013/xianout" };
int run = ToolRunner.run(new Configuration(), new XianAvg(), args1);
System.exit(run);
}
@Override
public int run(String[] args) throws Exception {
Configuration conf = new Configuration();
Path dest = new Path(args[1]);
FileSystem fs = dest.getFileSystem(conf);
if (fs.isDirectory(dest)) {
fs.delete(dest, true);
}
Job job = new Job(conf, "XianAvg");
job.setJarByClass(XianAvg.class);
job.setMapperClass(XianAvgMap.class);
job.setReducerClass(XianAvgReduce.class);
job.setMapOutputKeyClass(Text.class);//map 输出key类型
job.setMapOutputValueClass(Text.class);//map 输出value类型
job.setOutputKeyClass(Text.class);//输出结果 key类型
job.setOutputValueClass(Text.class);//输出结果 value 类型
FileInputFormat.addInputPath(job, new Path(args[0]));// 输入路径
FileOutputFormat.setOutputPath(job, new Path(args[1]));// 输出路径
return job.waitForCompletion(true) ? 0 : 1;//提交任务
}
public static class XianAvgMap extends Mapper<LongWritable, Text, Text, Text> {
@Override
protected void map( LongWritable key, Text value,
Mapper<LongWritable, Text, Text, Text>.Context context) throws IOException,
InterruptedException {
String[] split = value.toString().split("####");
if (split.length == 4) {
if (null == split[3] || "".equals(split[3])) {
split[3] = "0";
}
context.write(new Text(split[1]), new Text(split[3]));
}
}
}
public static class XianAvgReduce extends Reducer<Text, Text, Text, Text> {
private long count = 0;
private double sum = 0;
private double avg = 0;
@Override
protected void reduce( Text key, Iterable<Text> values,
Reducer<Text, Text, Text, Text>.Context context) throws IOException,
InterruptedException {
for (Text text : values) {
count = count + 1;
sum = sum + Double.parseDouble(text.toString().trim());
}
avg = sum / count;
context.write(key, new Text(avg + ""));
}
}
}
2.在Azkaban上面创建一个project:
3.编辑Azkaban工作流脚本(格式需要为unix的)
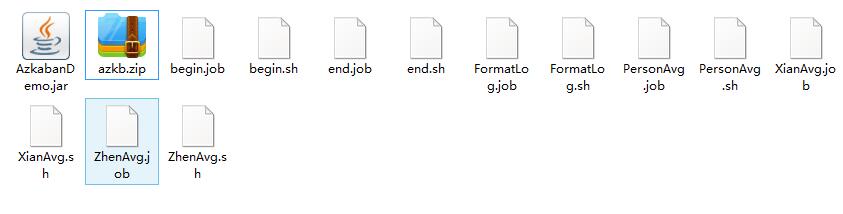
举一个例子(AzkabanDemo.jar是上面mr程序打的jar包,com.lijie.demo4azkaban.avg.FormatLog是具体的类名):
FormatLog.sh:
#!/bin/bash
hadoop jar AzkabanDemo.jar com.lijie.demo4azkaban.avg.FormatLogFormatLog.job:
type=command
command=sh ./FormatLog.sh
dependencies=begin3.打包上面Azkaban的脚本文件为zip包上传到project上面(依赖的名字不要写错包括大小写,上传的时候会校验依赖的)。
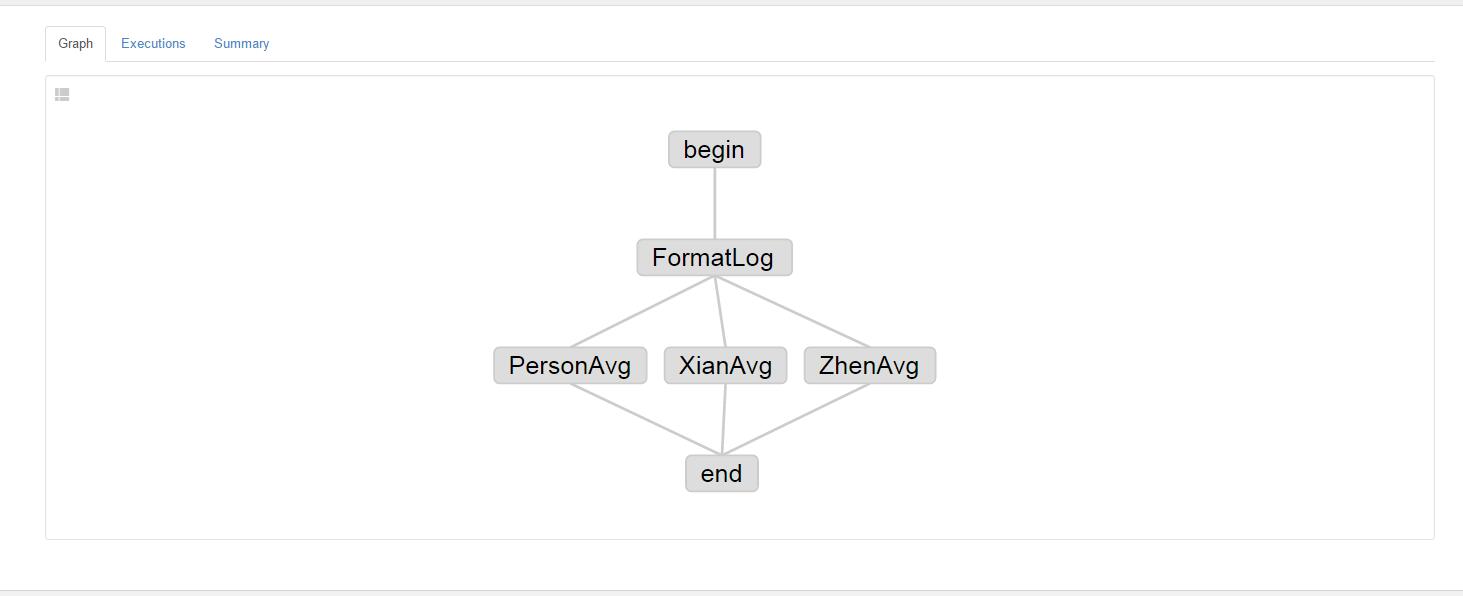
4.查看上传的任务依赖
5.通过Azkaban执行job(点击下图的execute)
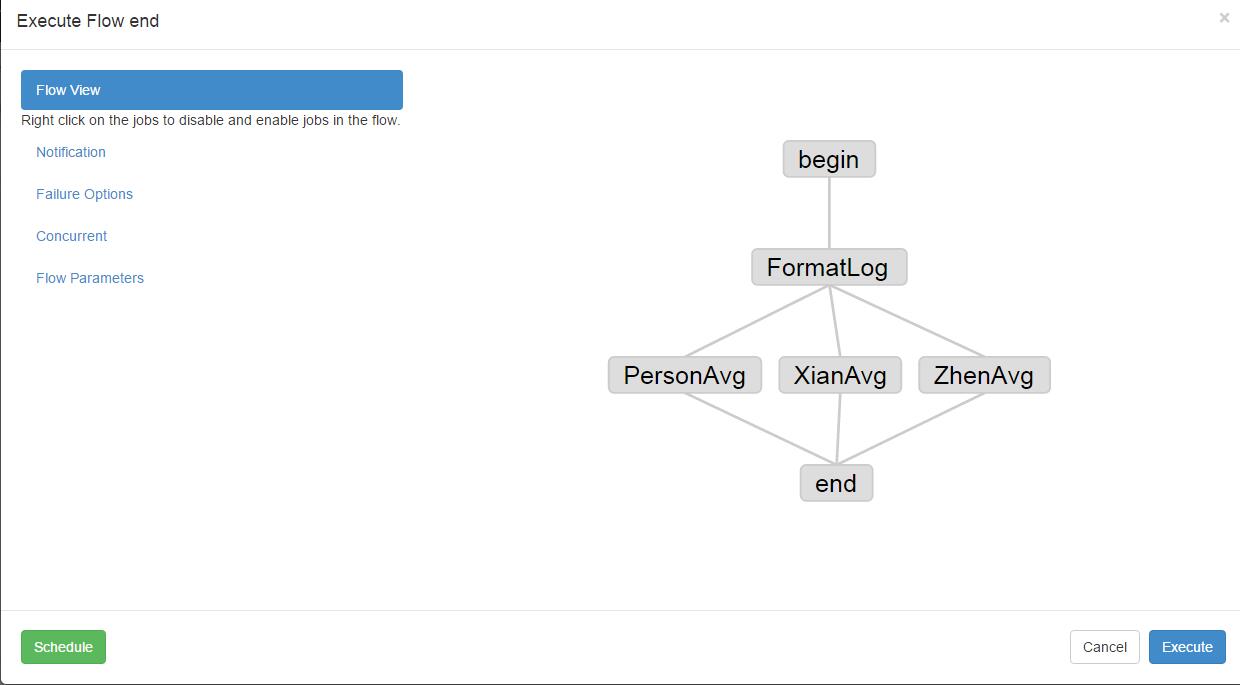
可以查看执行流(蓝色为running,绿色为执行成功,红色为失败):
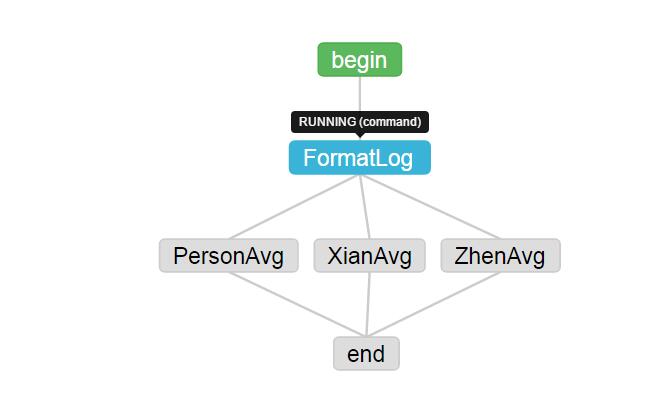
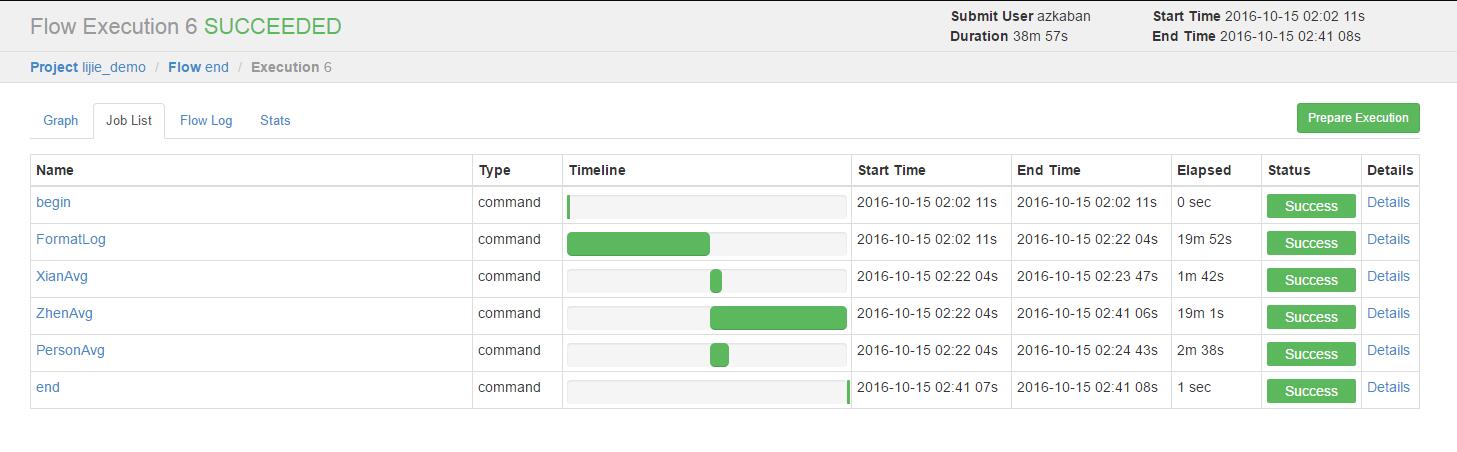
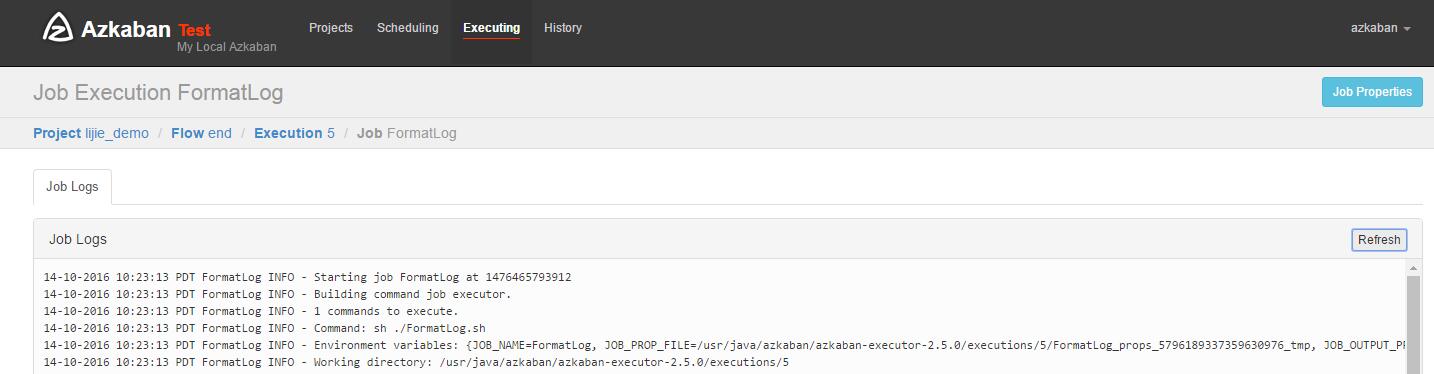
可以查看job list以及详细日志:
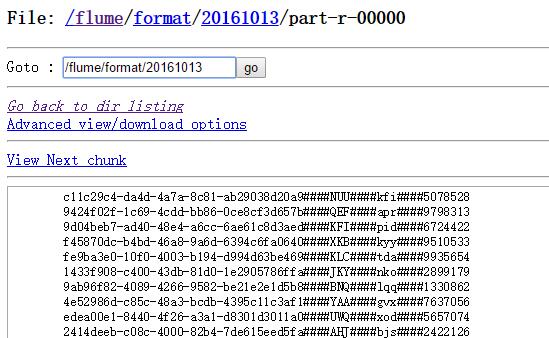
6.程序执行完成之后通过浏览器访问hdfs查看结果:
FormatLog执行完之后(格式化搜集到的数据):
PersonAvg执行完之后(所有人的平均积蓄):
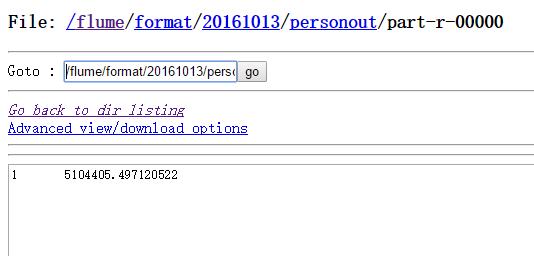
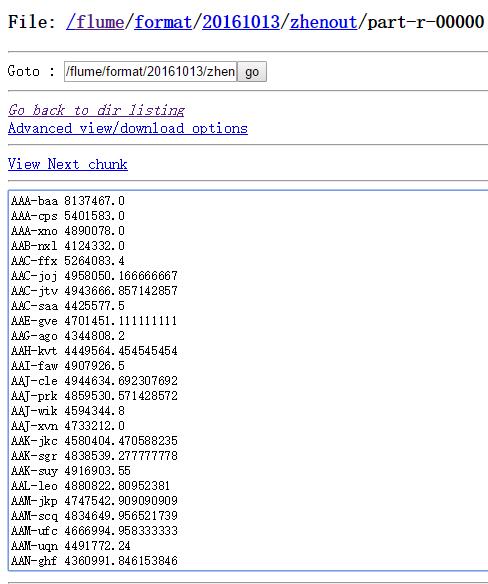
ZhenAvg执行完之后(每个镇的个人平均积蓄):
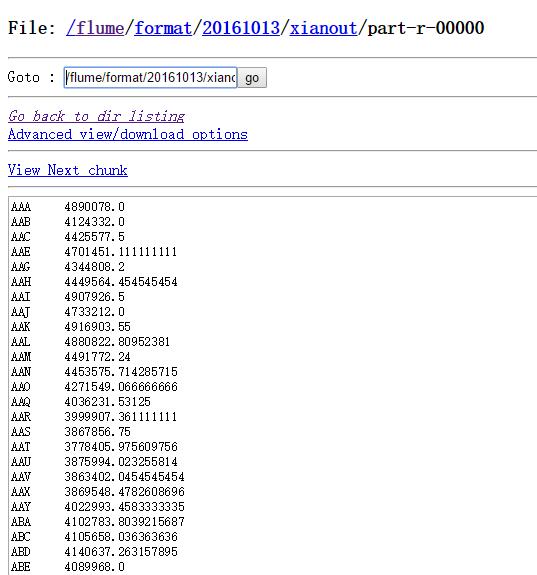
XianAvg执行完之后(每个县的个人平均积蓄):
注意:
期间遇到问题报错ipc.Client: Retrying connect to server: 0.0.0.0/0.0.0.0:10020. Already tried,发现是jobhistory服务没有启动,系统连接默认配置的0.0.0.0:10020地址导致连接失败需要在mapred-site.xml里面添加:
<property>
<name>mapreduce.jobhistory.address</name>
<value>lijie:10020</value>
</property>重启集群,然后还要在namenode节点启动jobhistory服务
[root@lijie sbin]# ./mr-jobhistory-daemon.sh start historyserver
starting historyserver, logging to /usr/java/hadoop/logs/mapred-root-historyserver-djt.out














 791
791

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









