






Mellanox ConnectX-6-dx智能网卡 具备流表卸载能力。智能网卡的部署方式兼容当前服务器ovs部署方式。而DPU bluefield 2,其要求ovs从服务器上转移到DPU上,这影响现有上层neutron架构,改造量大。
前置信息
OFED代码版本:Linux InfiniBand Drivers。其中, openvswitch版本为2.17.2,dpdk版本为20.11。
卸载主流程
概述
目前,智能网卡ovs流表卸载有两种方式
- netdev_offload_dpdk卸载。通过用户态网卡驱动进行流表卸载。
- netdev_offload_tc卸载。通过内核态网卡驱动进行流表卸载。tc-flow是一个现有的内核模块。
netdev_offload_dpdk卸载源码分析
ovs-dpdk中的netdev_offload_dpdk的卸载流程,采用 offload_main线程+工作队列的方式进行异步卸载,避免阻塞包转发线程。
流程图
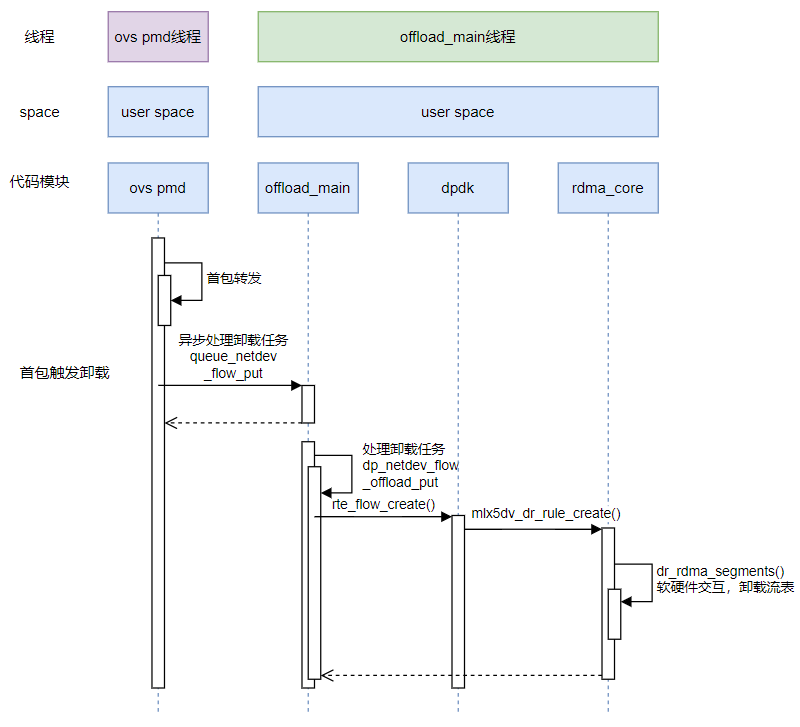
代码分析
主流程
// -------- ovs -----------------
// --- ovs vswitchd 主线程 -----------------
// 首包触发卸载,后续包走datapath转发或硬件转发
dp_netdev_flow_add
dpcls_insert(cls, &flow->cr, &mask); // datapath缓存流转发规则
// 入队 卸载任务队列
queue_netdev_flow_put(pmd, flow, match, actions, actions_len, DP_NETDEV_FLOW_OFFLOAD_OP_ADD);
// --- ovs offload_main 卸载线程 -----
dp_netdev_flow_offload_main // 通过队列+poll的方式,该线程 异步处理 来自ovs主线程的卸载任务队列。
dp_offload_flow(offload);
// netdev offload
dp_netdev_flow_offload_put // 单独的一个线程 dp_netdev_flow_offload_main
netdev_flow_put->flow_ flow_api->flow_put
netdev_offload_dpdk_flow_put
netdev_offload_dpdk_add_flow
netdev_offload_dpdk_action
netdev_offload_dpdk_flow_create
netdev_dpdk_rte_flow_create
// ---- dpdk rte_flow ----------------------
rte_flow_create()
==>mlx5_flow_create // dpdk: drivers/net/mlx5/mlx5_flow.c
mlx5_flow_list_create
flow_idx = flow_list_create(dev, type, attr, items, original_actions,
external, wks, error);
flow_drv_translate(dev, dev_flow,&attr_tx, items_tx.items,
actions_hairpin_tx.actions, error);
fops->translate(dev, dev_flow, attr, items, actions, error);
==>flow_dv_translate(dev, dev_flow, attr, items, actions, error) # 详见下方
flow_drv_validate()
flow_drv_apply(dev, flow, error);
fops->apply(dev, flow, error);
==>flow_dv_apply # 详见下方
// 分析 flow_dv_translate
for (; !actions_end ; actions++) {
// parse action
}
dev_flow->act_flags = action_flags;
flow_dv_matcher_register(dev, &matcher, &tbl_key, dev_flow, tunnel, attr->group, error)
// 分析 flow_dv_apply
flow_dv_apply
mlx5_flow_os_create_flow(dv_h->matcher->matcher_object,(void *)&dv->value, n,dv->actions, &dh->drv_flow);
*flow = mlx5_glue->dv_create_flow(matcher, match_value,num_actions, actions);
mlx5_glue_dv_create_flow
mlx5dv_dr_rule_create(matcher, match_value, num_actions,(struct mlx5dv_dr_action **)actions);
==>用户态驱动 详见下小节
mlx5dv_dr_rule_create(matcher, match_value, num_actions,(struct mlx5dv_dr_action **)actions);
==>内核态驱动 详见下下小节
__mlx5_glue_dv_create_flow(matcher, match_value,num_actions, actions_attr);
rdma-core走用户态驱动控制硬件
现有mlx网卡的用户态驱动都放在rdma-core中,因为rdma本身就要求使用用户态驱动,绕过内核TCP/IP协议栈(除非是iWARP)。
// --- rdma-core --------
mlx5dv_dr_rule_create(matcher, match_value, num_actions,(struct mlx5dv_dr_action **)actions);
dr_rule_create_rule(matcher, value, num_actions, actions);
dr_rule_create_rule_fdb(rule, ¶m,num_actions, actions);
dr_rule_create_rule_nic(rule, &rule->tx, ©_param,num_actions, actions);
dr_rule_send_update_list(&send_ste_list, dmn, true, nic_rule->lock_index);
dr_rule_handle_one_ste_in_update_list(ste_info,dmn,send_ring_idx);
dr_send_postsend_ste(dmn, ste_info->ste, ste_info->data,ste_info->size,
ste_info->offset,send_ring_idx);
dr_postsend_icm_data(dmn, &send_info, ring_idx);
dr_post_send(send_ring->qp, send_info); // 走rdma通道
/* Write. false, because we delay the post_send_db till the coming READ */
dr_rdma_segments(dr_qp, send_info->remote_addr, send_info->rkey,
&send_info->write, MLX5_OPCODE_RDMA_WRITE, false);
/* Read. true, because we send WRITE + READ together */
dr_rdma_segments(dr_qp, send_info->remote_addr, send_info->rkey,
&send_info->read, MLX5_OPCODE_RDMA_READ, true);
rdma-core走内核态驱动控制硬件(old)
早期网卡没有专门的用户态驱动在用户空间操作硬件。针对这些网卡,mlx在rdma-core用户空间中 封装了一层用户态驱动,其原理是在用户空间通过ioctl/netlink的方式调用 已有的内核驱动。
代码流程如下:
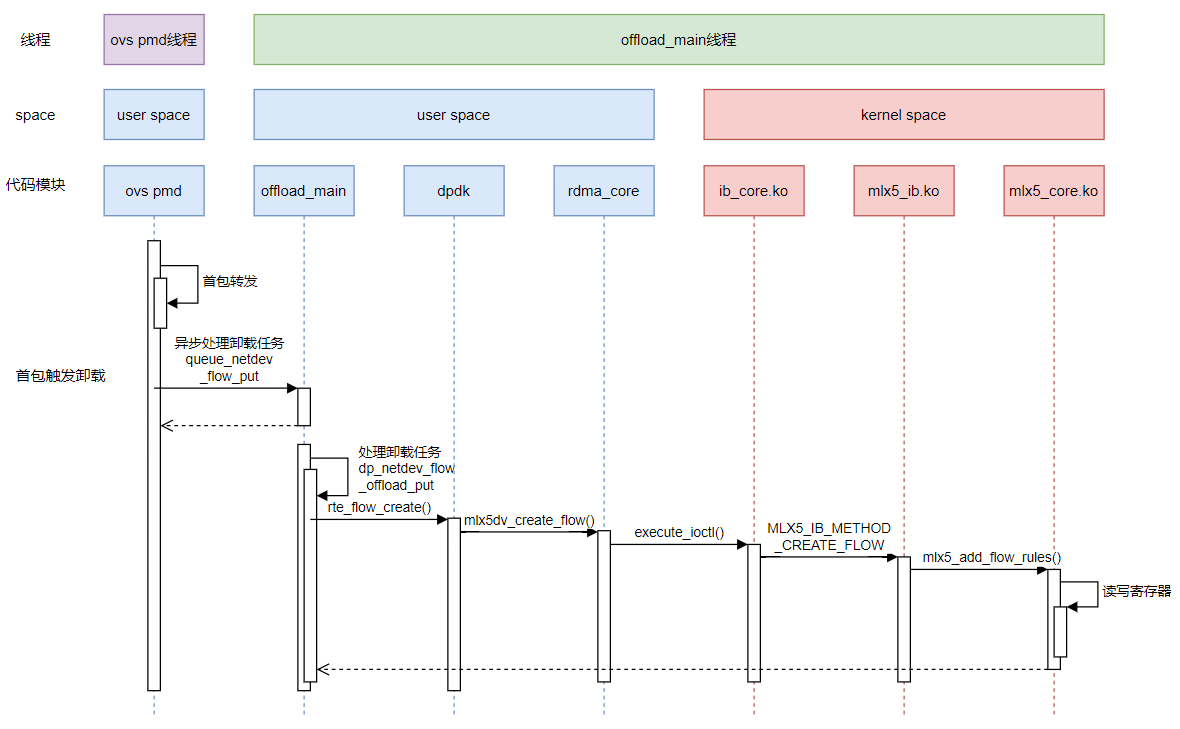
// --- dpdk ---------------
mlx5_glue_dv_create_flow()
__mlx5_glue_dv_create_flow(matcher, match_value,num_actions, actions_attr);
// --- rdma mlx5dv_create_flow in rdma-core providers/mlx5/verbs.c ---
dvops->create_flow(flow_matcher,match_value,num_actions,actions_attr,NULL);
_mlx5dv_create_flow
fill_attr_in_uint32(cmd,MLX5_IB_ATTR_CREATE_FLOW_FLAGS,MLX5_IB_ATTR_CREATE_FLOW_FLAGS_DEFAULT_MISS);
execute_ioctl(flow_matcher->context, cmd); // call kernel ioctl
// --- kernel space -- mlx5_ib.ko mlx_core.ko -------------
// ib_core dispatch message to mlx5_ib
UVERBS_HANDLER(MLX5_IB_METHOD_CREATE_FLOW) // drivers/infiniband/hw/mlx5/fs.c
get_dests
uverbs_get_flags32
uverbs_get_flags64(&flags, attrs_bundle, idx, allowed_bits);
raw_fs_rule_add(dev, fs_matcher, &flow_context, &flow_act,counter_id, cmd_in, inlen, dest_id, dest_type);
_create_raw_flow_rule
mlx5_add_flow_rules(ft, spec,flow_act, dst, dst_num); // drivers/net/ethernet/mellanox/mlx5/core/fs_core.c
rule = add_rule_fg(g, spec, flow_act, dest, dest_num, fte);
handle = add_rule_fte(fte, fg, dest, dest_num,old_action != flow_act->action);
root->cmds->update_fte(root, ft, fg, modify_mask, fte)
mlx5_cmd_update_fte
mlx5_cmd_set_fte(dev, opmod, modify_mask, ft, fg->id, fte);
mlx5_cmd_exec(dev, in, inlen, out, sizeof(out));
mlx5_cmd_do(dev, in, in_size, out, out_size);
cmd_exec(dev, in, in_size, out, out_size, NULL, NULL, false);
cmd_work_handler
lay = get_inst(cmd, ent->idx);
return cmd->cmd_buf + (idx << cmd->log_stride);
memset(lay, 0, sizeof(*lay));
memcpy(lay->in, ent->in->first.data, sizeof(lay->in));
lay->status_own = CMD_OWNER_HW; // transfer ownership to hardware
iowrite32be(1 << ent->idx, &dev->iseg->cmd_dbell);
// polling reg for completion
mlx5_cmd_comp_handler(dev, 1ULL << ent->idx, ent->ret == -ETIMEDOUT ?
MLX5_CMD_COMP_TYPE_FORCED : MLX5_CMD_COMP_TYPE_POLLING);
netdev_offload_tc卸载源码分析
netdev_offload_tc内核卸载是通过tc-flow模块。
流程图
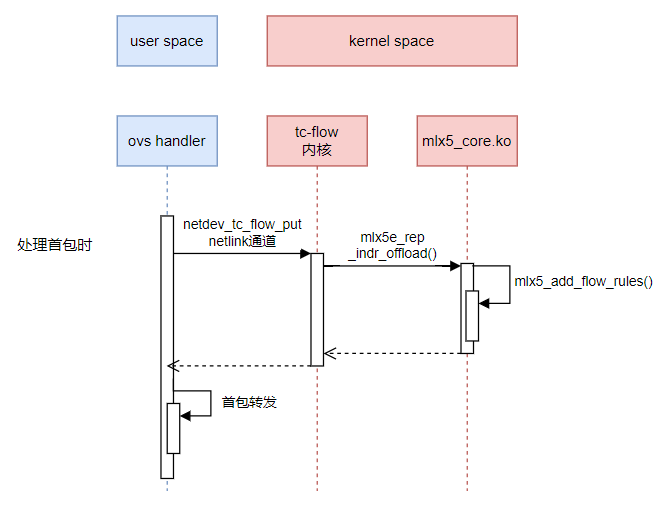
代码分析
// ovs kernel datapath 路径
// -- user space ---
dpif_netlink_operate
-->try_send_to_netdev // 先卸载。这里会卡住。
dpif_netlink_operate_chunks // 再转发
dpif_netlink_operate__
dpif_netlink_init_flow_put // netlink
// -- kernel space ---
ovs_flow_cmd_new()
ovs_flow_tbl_lookup(&dp->table, &new_flow->key);
ovs_flow_tbl_insert(&dp->table, new_flow, &mask);
// ovs卸载路径
// --- user space ---
dpif_netlink_operate
try_send_to_netdev
parse_flow_put(dpif, put);
netdev_flow_put(dev, &match,...)
flow_api->flow_put(netdev,...)
netdev_tc_flow_put()
tc_replace_flower(&id, &flower); // netlink 通信。组装tc-flow指令给tc内核模块
// --- kernel space ------
tc_ctl_tfilter // tc module。不属于ovs代码
// 代表口卸载
mlx5e_rep_indr_setup_tc_cb // mlx5_core.ko
mlx5e_rep_indr_offload(priv->netdev, type_data, priv,flags);
mlx5e_configure_flower(netdev, priv, flower, flags)
mlx5e_tc_add_flow(priv, f, flags, dev, &flow);
mlx5e_add_fdb_flow(priv, f, flow_flags,filter_dev, flow);
mlx5e_tc_offload_fdb_rules
mlx5_eswitch_add_offloaded_rule
==>mlx5_add_flow_rules //与 rte_flow/ib一样的底层调用接口
// data structure
const struct net_device_ops mlx5e_netdev_ops = {
.ndo_setup_tc = mlx5e_setup_tc,
}
netdev_offload_dpdk卸载 vs netdev_offload_tc卸载对比
- 异步IO方式。netdev_offload_dpdk卸载是异步的由专门的线程offload_main处理。而tc-flow内核卸载是同步,卸载面会卡住数据面。netdev_offload_tc卸载依赖netlink系统调用通道,其依赖发送等待应答机制,发消息后还要等待应答。而且netdev_offload_tc使用。
- 进(线)程间通信方式。netdev_offload_dpdk线程间的通信方式是共享内存(无锁队列)的方式,ovs-pmd与offload_main线程直接内存交互,无需系统调用。而netdev_offload_tc卸载是通过netlink系统调用与内核态网卡驱动交互。
- CPU核隔离。netdev_offload_dpdk卸载隔离业务面与数据面。netdev_offload_dpdk卸载及其相应的转发面(ovs-dpdk)都是运行在专门的核上,不会抢占业务核。
- netdev_offload_dpdk适合高并发的模型。netdev_offload_tc是netlink交互,netlink通道可成为性能瓶颈。
- 隔离内核空间。避免卡内核bug
ovs revalidato线程分析
ovs revalidator 负责更新每条已卸载流的统计,以及异步删除超时流。
对于已卸载到硬件的流表,其流统计信息存于硬件寄存器中。ovs revalidator线程中会定时轮询,从硬件寄存器中获取流统计信息。
流程图
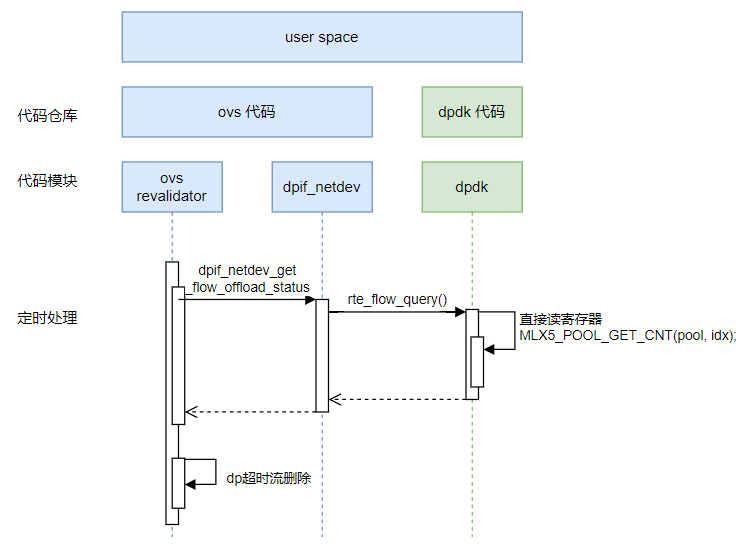
代码分析
udpif_revalidator()
revalidate(revalidator);
dpif_flow_dump_next
dpif->dpif_class->flow_dump_next(thread, flows, max_flows);
dpif_netdev_flow_dump_next
dp_netdev_flow_to_dpif_flow
get_dpif_flow_status()
dpif_netdev_get_flow_offload_status()
netdev_offload_dpdk_flow_get
netdev_dpdk_rte_flow_query_count
==>rte_flow_query()
// --- rte_flow_query in dpdk -----------
rte_flow_query
flow_dv_query
flow_dv_query_count
_flow_dv_query_count(dev, cnt_idx, &pkts, &bytes);
cnt = flow_dv_counter_get_by_idx(dev, counter, NULL);
MLX5_POOL_GET_CNT(pool, idx % MLX5_COUNTERS_PER_POOL); // 直接读硬件统计寄存器















 1117
1117











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









