







Lab1 MapReduce 论文阅读
实现
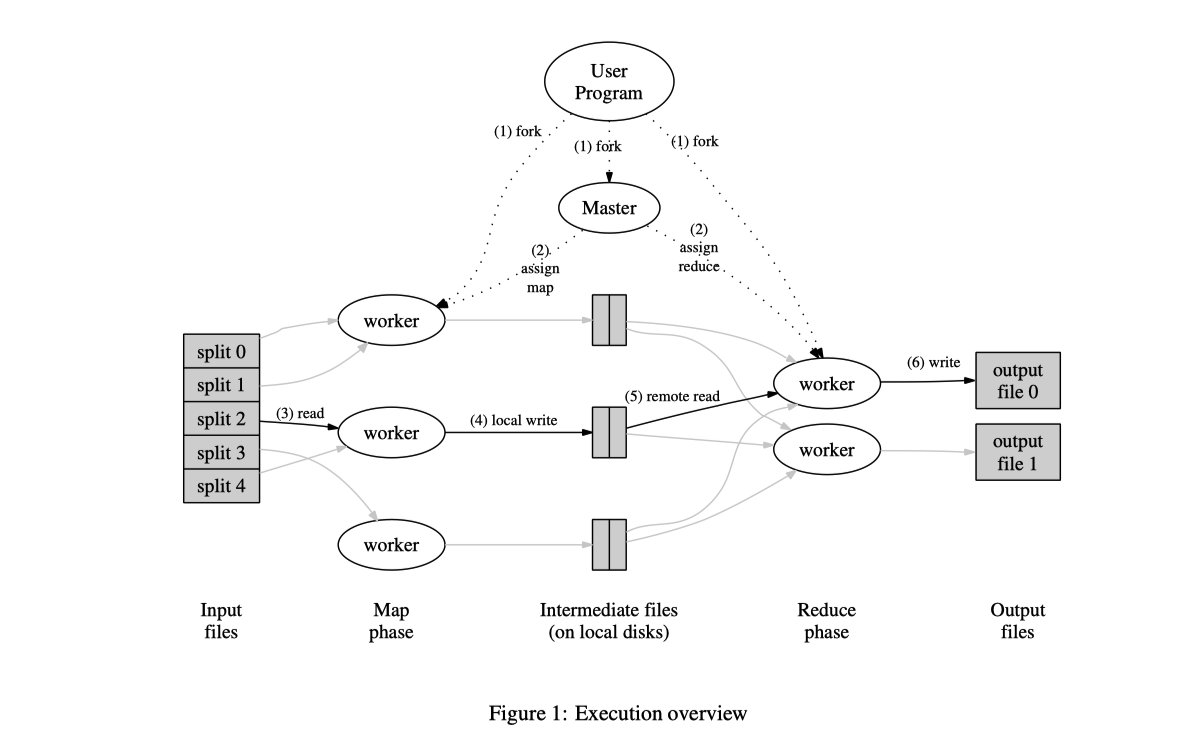
执行过程概述
1.首先把输入的文件分割成M pieces,16-64MB,可以在多个集群中的机器上启动
2.Master比较特殊,其余的worker被master指派工作;M个map task,R个reduce task
3.Map task的worker 读取相应的input split中内容和,将其解析成kv-pair并将pair传递给用户所定义的Map-Function,由Map-function所产生的kv-pair会被缓存在内存中;
4.周期性地,缓存的pair呗写入本地磁盘,并被分区函数分成R个区域,这些键值对存在本地磁盘上的位置被传回master,由master来将这些位置传送给reduce workers;
5.当reduce worker收到master发送的位置信息,它会调用远程程序来从map worker的本地磁盘中读取数据,当reduceworker读取了全部了中间结果时,它将其按照key来分类,从而将key一样的结果分在一起。分类很有必要因为一个reduce task中会有很多不同key的部分。当中间结果intermediate data太大了,会启动external sort
6.当reduce worker通过唯一的key循环遍历了分类之后的中间结果,它会把key和相应的中间结果set发送给用户定义的reduce function,输出结果被加在reduce分区的output中。
7.当全部的map和reduce任务都完成之后,master会唤醒user program,user program向代码返回值。
计算完毕之后,计算的结果会有R个输出文件(每个reduce task一个),一般这些文件不需要进行合并,因为通常会作为下一个mapreduce的输入。
Master 数据结构
master保持了一些数据结构。
对于每个map task和reduce task,其储存了状态(idle、in-progress、completed),还有其所在的work machine的身份(对于非空闲的tasks);
master是中间计算结果存储位置从map tasks到reduce tasks的管道,所以,对于每个计算完成的map task,master中会储存map task所生成的中间文件的location和大小;
这些信息会逐渐push给拥有in-progress reduce task的worker
容错
因为mapreduce被设计来处理大规模的计算,成百上千的机器,因此必须能优雅地处理机器的故障问题。
Worker Failure
master会周期性地ping所有的worker,如果在某段时间内没有收到某个worker的response,即视作其failed。
任何一个worker的map task完成之后,会reset至idle状态,可以有资格被其他的workers调度,同样的,如果某个worker上的task failed了,也会重新reset至idle而等待重新调度。
当map task计算输出结果所在磁盘的machine fail了,已经运行成功的map task也会重新执行;而已经完成的reduce tasks不需要重新执行因为它们的结果被存储在global file system中。
如果因为worker A failed了因此由B来重新执行一个map task,那么所有的reduce tasks都会被告知,所有还没从A读取数据的reduce task都会转而从worker B读取数据。
MapReduce对大规模的worker失败也有良好的适应力。
Master Failure
master可以周期性地检查上面提到的数据结构,并写checkpoint。如果master挂了,会从上一个checkpointed state重新开始。当然,因为只有一个master,所以失败概率会比较小,所以如果master failed了程序会终止,用户可以检查并重新尝试。
Semantics in the Presence of Failures
(语义中出现的失败?)
当用户提供确定的function和input时,我们的分布式计算过程会给出相同的output。这得益于我们的map和reduce计算时原子,map任务会产生R个临时结果,而reduce会产生一个结果,如果master接收到了一个已经完成的task消息,会忽略它。也会保证最后的output结果只有一个。
任务间隔
我们将map阶段分为M片,将reduce阶段分为R片,理想阶段,任务数量M和R应该比机器的数量要大很多,这样可以让一个worker运行很多个task来提升动态平衡,并且在有失败时加速恢复。
但是M和R的数量是有边界的,master要分配M+R个任务,并且在内存中需要存储O(M*R)state
在实践中,一般把每个task分为16-64mb,R的数量时我们机器数量的小几倍。
lab1
lab1
配置运行
before
go build -buildmode=plugin ../mrapps/wc.go
go build -buildmode=plugin /Users/jiarui/Study/Distributed System/6.824/src/mrapps/wc.go
Lecture2 RPC and Thread
多线程垃圾回收机制
《effective go》
多线程
io 并发
并行化
易用(后台检查等功能)
共享内存
两个线程同时对同一个变量操作race
如果一个cpu正在执行这段代码,而另一个cpu在关闭它
mutex mu 锁 muteX mu.lock()
把锁中间的代码封装起来
coordination
线程之间互相等待、协作
chaneel、condition variable、wait group
死锁 T1和T2两个线程互相等到
Crawler练习
CocurrentMuteX 共享内存的方法
函数中传递了map,没有加*传递指针,是因为map本身是go中内置的指针
在CocurrentMuteX这个函数中,fetchState是一个指针对象,这是因为要在所有的goroutine中更改其值,因此传入地址
WaitGroup是go中的一个计数器,用于等待
defer 相当于java中finally
如果go中内部函数访问了定义在外部的变量,当外部的函数返回时,内部的变量指向何处?go注意内部函数使用了外部变量时,会分配heap堆内存在存储这些变量,供其使用,最后gc检测涉及到这个堆的函数退出没
race探测器 go -race XXX.go 会检测是否有读写在同一个地址上
channel方法
通过通信而不会是共享内存的方法来传递值
//
// Concurrent crawler with channels
//
func worker(url string, ch chan []string, fetcher Fetcher) {
urls, err := fetcher.Fetch(url)
if err != nil {
ch <- []string{}
} else {
ch <- urls
}
}
func master(ch chan []string, fetcher Fetcher) {
n := 1
fetched := make(map[string]bool)
for urls := range ch {
for _, u := range urls {
if fetched[u] == false {
fetched[u] = true
n += 1
go worker(u, ch, fetcher)
}
}
n -= 1
if n == 0 {
break
}
}
}
func ConcurrentChannel(url string, fetcher Fetcher) {
ch := make(chan []string)
go func() {
ch <- []string{url}
}()
master(ch, fetcher)
}
有两个一开始没理解的点:
1.在ConcurrentChannel为什么要使用go func给ch赋值,因为如果不另起一个协程的话,ch就和master位于同一个进程,不能又读又写,会出现死锁。

2.for urls := range ch {这一句的循环需要ch中有内容时才会执行,不然会堵塞,只有在最后n==0时才会break,因此这里可以理解为master一直在读ch中的内容,启动的多个workers一直在往ch中写东西,如果读的时候没有符合要求的数据就一直等着,直至传入了新的urls再启动新的任务。
Lab3 GFS
论文阅读
分布式文件管理系统
Introduction
几个相比于传统选择设计的不同点
组件失败component failures
持续的监视、错误的探测和容错还有移动恢复很重要
2.大文件的处理
诸如io操作和块的大小等设计假设和参数需要被重新设计。
3.大多数的文件会在现有内容上增加内容时产生文件的异变,文件的增加将成为表现改进和原子性保证的重点
4.协同设计应用和api以提高灵活性
Design Overview
2.1 Assumptions
设计给多台廉价的机器,其必须持续地监控、探测、容错、自动修复;
系统存储数量比较少的大文件,预计会有million个100mb或者更大的文件。
工作量主要包括两种读取:大的文件流读入large streaming reads和小的随机读入;
工作量还有很多大的序列化的向文件添加数据的写入;
系统必须效率高地实现多用户并发给同一文件添加内容时的良好语义
高持续的带宽比低的延迟更重要
2.2 Interface
2.3 Architecture
一个GFS集群包括了多个clients访问的一个master和多个chunkservers,如图
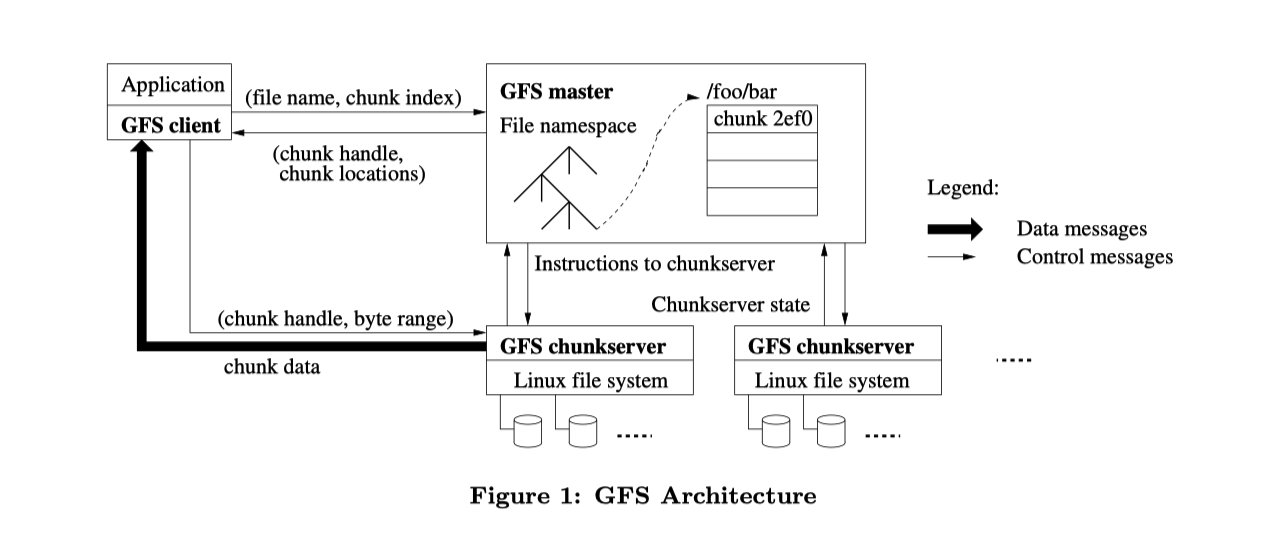
文件被分成合适大小的chunks,当每个chunk创建时,master会给每个chunk分配一个不改变的块句柄;chunkserver把chunks存储在本地的磁盘,然后按照的chunk handle和byte range来读写块数据,为了可靠性,每个块会被复制在多个chunkservers上,默认情况三个复制,可更具用户需求更改。
master会维持所有的文件系统元数据。包括namespace、access control information,文件到块的映射信息、现在的块定位等。master会周期性地向chunkserver发送heartbeat
clinet code连接到每个应用实现的api,与master和chunkserver交流
client和chunkserver都不缓存文件数据,client贮存并不会有什么好处因为大多数huge file或者working set的applications stream太大了;chunkserver不需要cashe file data,因为块作为本地文件处理。
课程笔记
大型存储系统
设计一个优秀的接口和内部结构
设计大型分布式系统,性能问题(performance)是最重要的,将数据sharding分片到不同的服务器上
faults 同错很重要,复制是很重要的一个方法;但是如果采用复制的方法可能会遇到一些不一致的问题,需要进行额外的设计和网络中的通信,因此保持一致性consistency会导致性能降低一部分。
设计优势
big fast
global
sharding
automativ recovery
single data center
internal use
big sequential access
为大型数据顺序读写所设计的系统
在这类系统中,对数据错误的容忍度相对较高,不像银行等系统,因此gfs提出了弱一致性也能接受,以性能为主要的追求。
master知道每个chunk在哪个chunk server上
每个chunk 64 mb,每个chunk超过64就要新建一个
master实际存储的东西
1.filename到chunkID(chunk handler)数组的映射(这个文件被分成了哪些chunk)
2.chunk hadle到数据的映射(每个chunk所对应的数据) chunk handle->list of chunkservers(因为有副本)/version版本号/primary和其租约时间(哪个chunkserver是primary)
这些信息存在RAM中,防止宕机时丢失信息,会将其写入disk中,将log、checkpoint写入。
读写的步骤
read
- Client将文件名和偏移量发给master,在某个字节范围的数据
- master发送chunk handler和server列表给client
- 客户端和chunkserver中一个通信,发送一个chunk handler和offset偏移,chunkserver储存了文件在本地的文件系统中,根据handler找到chunk,读取客户端锁期望的字节范围数据range of bytes,返回数据给客户端
如果请求的数据范围横跨了两个chunk,那么在底层的lib库会把这个请求分割成两个读请求发送到master,请求下来的数据放到buffer中一起返回
write
追加数据,在最后一个chunk中添加信息,对于写的话,一定需要一个primary
case1:没有primary,master需要与cs们通信,找出具有最新的副本cs的集合,然后挑出一个作为primary,并指定secondary,还要设定租约
一个副本中的chunk版本等于masters服务器中知道的最新版本号,上面提到master中需要把version信息存在磁盘中,是为了防止重启之后丢失信息找不到最新的chunk了(Q:为什么不能直接和各个chunkserver通信,找到其中版本最新的?A:实际最新版本的chunkserver可能存在某些原因(未重启或网络原因)没有相应)
Case2:已经知道谁是p谁是s
client现在知道谁是primary谁是secondary,向它们都发送文件信息,等到它们都返回确认收到了信息之后,再告诉masters;此时primary可能在处理很多clients的请求,会按照某种顺序执行所有请求,并将数据追加到文件中,找到最末尾的chunk并添加内容,然后告诉所有的secondary也写到末尾的相同偏移量处,如果都写入了并向p返回yes,那么向client返回success,否则回复no,由c重新发起。
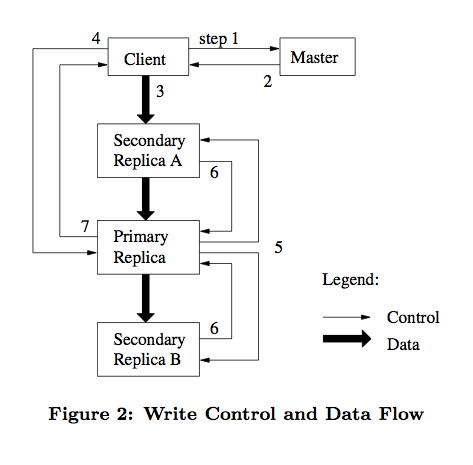
如需要保持强一致性
primary检测重复的请求;secondary需要真正执行某个操作而不是仅仅返回错误;
两阶段提交:在写的时候,第一阶段p给s发消息,确保能否完成,等所有s都答应了,再把任务发过去;
p在确定所有的s拿到拷贝之前就崩溃了,这时候一个s会接任p,但是此时的s和新的p在最后的几次操作上可能不同,所以新的p开始时需要与secondary显式地重新同步,确保最后几步历史操作是一致的
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









