







最近在学kmp算法,奈何研究了2天,才搞懂,很多人并没有理解kmp算法的本质,所以我尽量在这里把这个算法的原理说清楚。
首先假设有一个text数组
| a | b | x | a | b | c | a | b | c | a | b | a |
和pattern数组
| a | b | c | a | b | a |
在不会kmp算法的时候我们只能选择bf方法,时间复杂度为O(M*N),效率非常低,那么为什么效率会这么低呢?相必你也非常清楚,bf方法回溯太多了,时间复杂度肯定会非常高,所以想解决这个问题,我们就要解决回溯的问题,所以便有了kmp算法,在接下来的学习中,你会感受到这个算法的巧妙之处。
首先我们需要弄懂一个概念,前缀表(不包括最后一个)和后缀表(不包括第一个),以patter数组为例子,它的前缀有a ab abc abca abcab,他的后缀有b bc bca bcab bcaba,知道这个概念以后,我们来求一下pattern数组最长相等的前后缀,首先第一个默认是0,所以咱们a下面写0,ab也没有写0,abc没有写0,abca有一个相同所以写1,依此类推···
表示如下:
| a | b | c | a | b | a |
| 0 | 0 | 0 | 1 | 2 | 1 |
这个概念弄懂以后,我们该如何实现呢?这一步非常的巧妙,没有弄懂的话就多举几个例子跟着走,我们需要一个循环来计算最长相等前后缀,创建一个prefix数组,然后定义len=0和i=1,如果他们不相等并且len=0,那么下面的数组写0,然后i继续往下走,如果相等len加一(这里是在原来的基础上加一),把len的值赋给下面数组的第i个,i继续往后走,不过这里有一个情况,就是如果突然有一个中断了该怎么办?很多人会从头开始比较,我个人认为是可以得出正确答案的(如果不是希望指正),但是这里选择从斜下方回溯会更好,因为它prefix数组保存着最大相等前后缀,我们并不需要从头开始比较,而是从最大前后缀的下一个比较会更好(自己的理解)
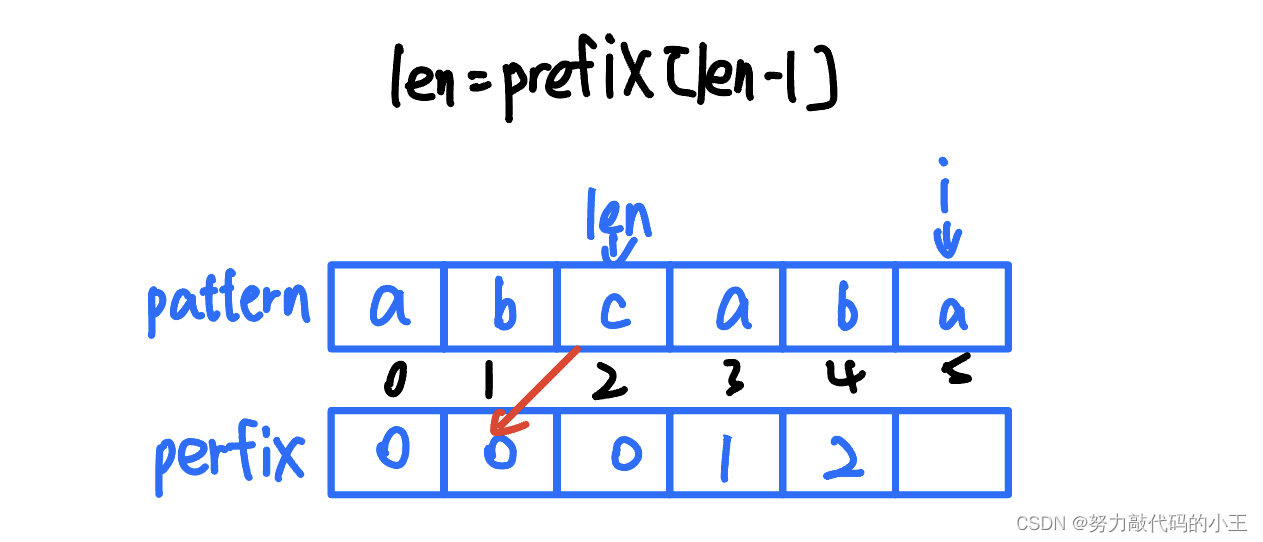
这里可以换别数值去思考,慢慢体会其中的奥秘, 下面两个数组进行比较时你会更容易理解这里为什么要这么做,这里的代码如下:
void prefix_table(char pattern[],int prefix[],int n)
{
prefix[0]=0;
int len=0;
int i=1;
while(i<n)
{
if(pattern[i]==pattern[len])
{
len++;
prefix[i]=len;
i++;
}
else
{
if(len>0)
{
len=prefix[len-1];
}
//判断永远不相等
else
{
prefix[i]=0;
i++;
}
}
}
}既然咱们是斜着来用的话,不妨把第一位设置为-1(默认),整个prefix数组往后移,这样用起来很方便,最后一位是不需要的,为什么呢?因为既然是斜着匹配了,永远也用不到最后一个,所以咱们的数组可以理解为这样:
| a | b | c | a | b | a |
| -1 | 0 | 0 | 0 | 1 | 2 |
这个代码对于我们来说非常简单,如下:
void move_prefix_table(int prefix[],int n)
{
int i;
for(i=n-1;i>0;i--)
{
prefix[i]=prefix[i-1];
}
prefix[i]=-1;
}我们做了这么多准备工作是为了干什么?没错就是为了减少回溯,所以前面才是最重点的步骤,也同样是很多人难以理解的部分,接下来的工作就非常简单了,只需要几个判断就可以。
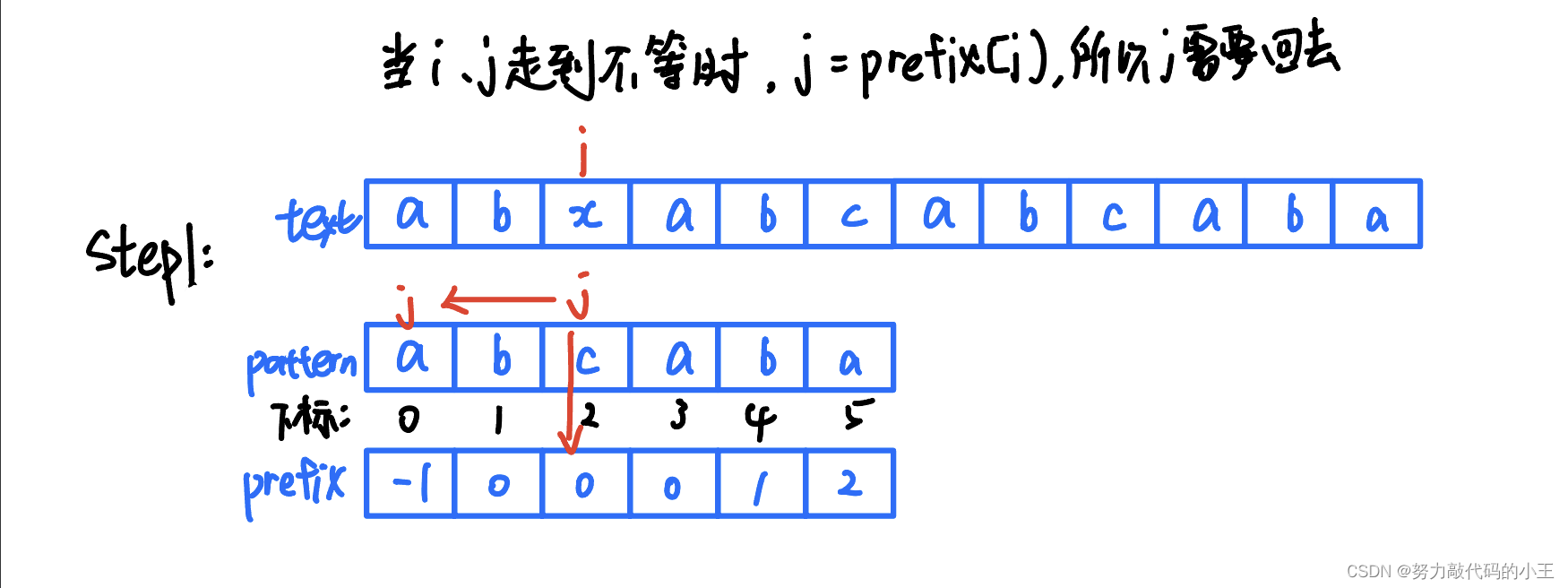
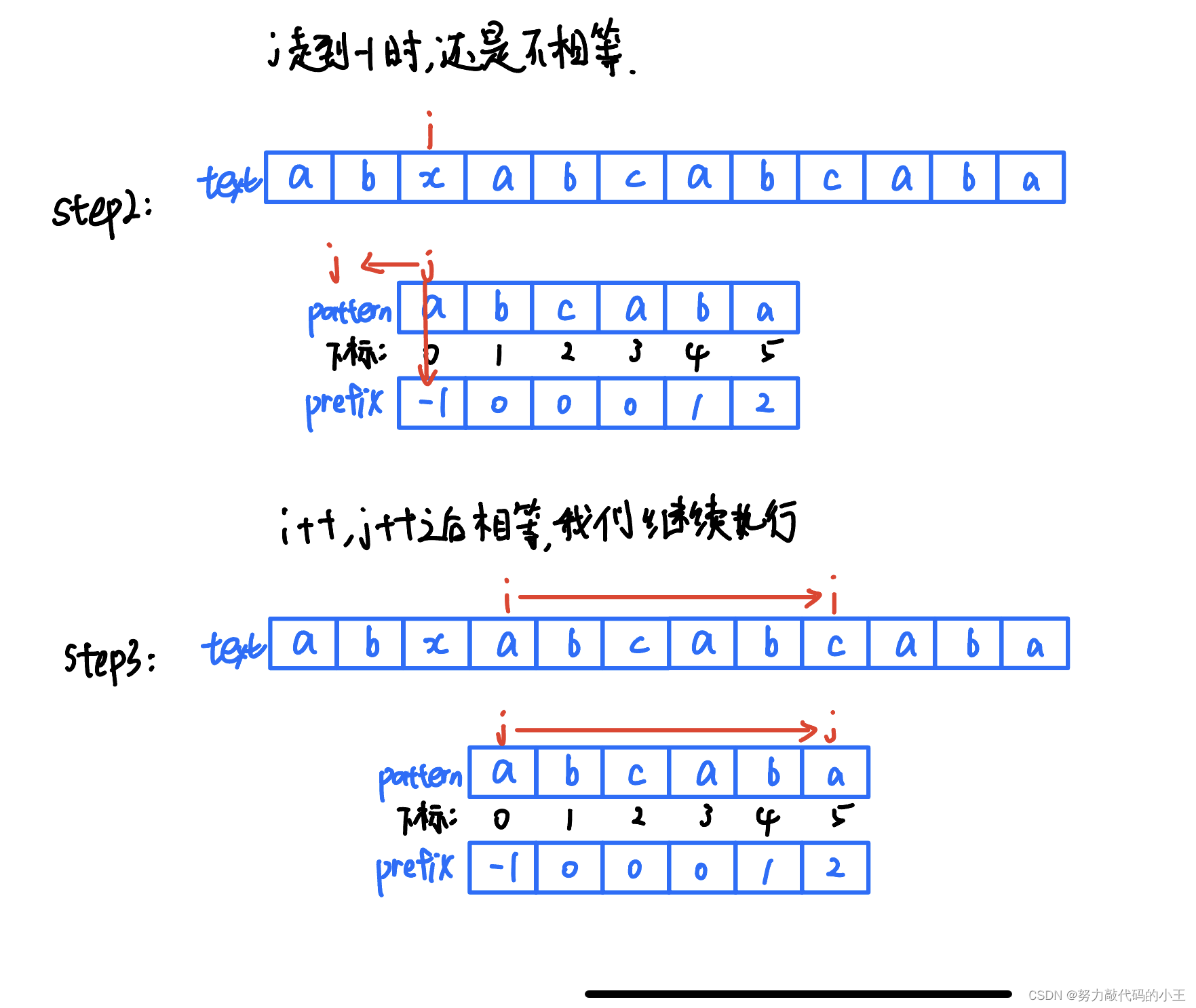

这样思路已经很清楚了吧,代码如下:
void kmp_serach(char text[],char pattern[])
{
//计算pattern的大小
int n=strlen(pattern);
int m=strlen(text);
int* prefix=(int*)malloc(sizeof(int)*n);
prefix_table(pattern,prefix,n);
move_prefix_table(prefix,n);
//text[i] len[text] =m
//pattern[j] len[pattern]=n
int i=0;
int j=0;
while(i<m)
{
if(j==n-1&&text[i]==pattern[j])
{
//i-j就是位置
printf("found pattern at %d\n",i-j);
//匹配完成后继续匹配
j=prefix[j];
}
if(text[i]==pattern[j])
{
i++;
j++;
}
else
{
j=prefix[j];
if(j==-1)
{
j++;
i++;
}
}
}
}














 456
456











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









