爬取京东本周热卖商品基本信息存入MySQL
网络爬虫介绍
概述
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
产生背景
随着网络的迅速发展,万维网成为大量信息的载体,如何有效地提取并利用这些信息成为一个巨大的挑战。搜索引擎(Search Engine),例如传统的通用搜索引擎AltaVista,Yahoo!和Google等,作为一个辅助人们检索信息的工具成为用户访问万维网的入口和指南。但是,这些通用性搜索引擎也存在着一定的局限性,如:
1、不同领域、不同背景的用户往往具有不同的检索目的和需求,通用搜索引擎所返回的结果包含大量用户不关心的网页。
2、通用搜索引擎的目标是尽可能大的网络覆盖率,有限的搜索引擎服务器资源与无限的网络数据资源之间的矛盾将进一步加深。
3、万维网数据形式的丰富和网络技术的不断发展,图片、数据库、音频、视频多媒体等不同数据大量出现,通用搜索引擎往往对这些信息含量密集且具有一定结构的数据无能为力,不能很好地发现和获取。
4、通用搜索引擎大多提供基于关键字的检索,难以支持根据语义信息提出的查询。
为了解决上述问题,定向抓取相关网页资源的聚焦爬虫应运而生。聚焦爬虫是一个自动下载网页的程序,它根据既定的抓取目标,有选择的访问万维网上的网页与相关的链接,获取所需要的信息。与通用爬虫(general?purpose web crawler)不同,聚焦爬虫并不追求大的覆盖,而将目标定为抓取与某一特定主题内容相关的网页,为面向主题的用户查询准备数据资源。
抓取策略
网页的抓取策略可以分为深度优先、广度优先和最佳优先三种。深度优先在很多情况下会导致爬虫的陷入(trapped)问题,目前常见的是广度优先和最佳优先方法。三种具体的差异大家可以自己查阅,在这里我就不多说了。
项目简介
需求概要
1、按照下面所述进入京东本周热卖页面,抓取本周热卖页面所有商品链接。
2、抓取所有商品链接后,进入商品详情页面,抓取商品ID、名称、图片链接等基本信息。
3、将抓取的所有信息存入设计好的MySQL表中。
注意事项
1、由于抓取多个页面,所以需要用多线程。
2、京东商品的价格以及评价都是通过JS异步传输的,所以从网页源码中无法获取商品这些信息,需要用调试工具加载页面所有内容,然后找到JS异步传输所请求的URL,然后继续请求并获取Response(商品价格和评价)。
3、我所使用的环境为浏览器(Chrome)、IDE(Eclipse)、项目(Maven)、Maven依赖(junit4.12、httpclient 4.4、htmlcleaner2.10、json 20140107)。
4、依赖中的httpclient、htmlcleaner、json的版本最好使用我所指定的,其他的版本很容易出现问题。同时获取XPath最好用Chrome抓,火狐等容易出错。
5、抓取日期为2016/4/30日,京东页面以后很可能会改动,所以这套代码之后可能抓不到正确数据。所以大家要注重爬取过程和原理。
6、由于我对每个页面用了一个线程,所以爬取的商品超过100的时候,插入商品信息到数据库时,可能会出现超过MySQL最大连接数错(默认100),可以在配置文件my.ini中修改(打开 MYSQL 安装目录,打开 my.ini 找到 max_connections ,默认是 100, 一般设置到500~1000比较合适,然后重启MySQL)。
其他
这篇文章主要演示了爬取京东本周热点的所有商品基本信息,如果要继续了解如何爬取所有用户评价的话,可以参考另一篇文章:
爬取京东本周热卖商品所有用户评价存入MySQL:http://blog.csdn.NET/u011204847/article/details/51292546
爬取的页面导航
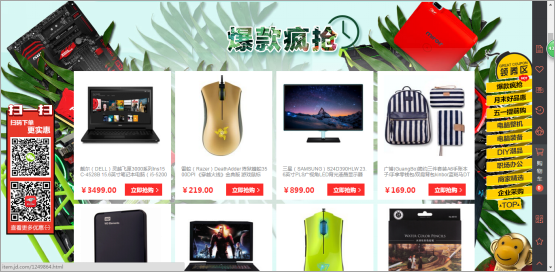
首先进入京东首页,然后鼠标移到全部商品分类—》电脑、办公—》玩3C—》本周热卖。

进入本周热卖(要抓取的网页,抓取这个页面所有商品的URL以及商品基本信息)
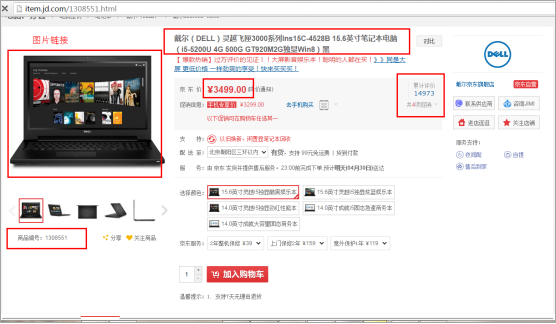
点击本周热卖中第一个商品:价格为3499的戴尔电脑链接后,商品详情如下。
工具使用介绍
获取商品元素的XPath
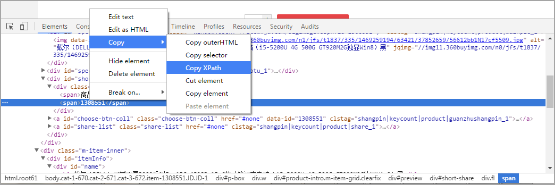
1、使用Chrome浏览器(其他浏览器获取的XPath可能无法识别)打开商品详情页面,然后按键盘上面的F12键打开开发者工具。接下来操作流程如下图中所示:

2、选择网页元素中的商品ID,然后右键选择Copy XPath
XPath示例:
- *[@id="short-share"]/div/span[2]
3、然后我们就可以用此方法获取商品URL、商品名称。注意,价格和商品评价都是JS异步传输,无法通过XPath方法获取。所以需要特殊处理。
查找JS异步传输请求的URL
详细流程如下图中所示:

现在我们知道如何去查找我们所需要的信息,接下来将使用代码去获取这些信息,最后写入MySQL数据库。
代码实现
工具类:
由于接下来代码会使用到工具类,所以先贴出来。为了方便解释代码,一些冗余的代码就不抽取成方法了。
- import java.io.IOException;
- import org.apache.http.HttpEntity;
- import org.apache.http.client.ClientProtocolException;
- import org.apache.http.client.methods.CloseableHttpResponse;
- import org.apache.http.client.methods.HttpGet;
- import org.apache.http.impl.client.CloseableHttpClient;
- import org.apache.http.impl.client.HttpClientBuilder;
- import org.apache.http.impl.client.HttpClients;
- import org.apache.http.util.EntityUtils;
-
- public class SpiderUtils {
-
-
- public static String download(String url) {
-
- HttpClientBuilder builder = HttpClients.custom();
- CloseableHttpClient client = builder.build();
- HttpGet request = new HttpGet(url);
- String str = "";
- try {
-
- CloseableHttpResponse response = client.execute(request);
-
- HttpEntity entity = response.getEntity();
-
- str = EntityUtils.toString(entity);
- } catch (ClientProtocolException e) {
- e.printStackTrace();
- } catch (IOException e) {
- e.printStackTrace();
- }
- return str;
- }
-
- }
获取热卖页面所有商品的URL
热卖页面:
1、页面示例

2、分析获取所有商品URL
通过查找页面源码可以发现所有商品URL都类似 //item.jd.com/2717678.html 这种格式,只是2717678这个商品ID不同而已,所以我们可以用正则获取这些URL。
3、代码及打印结果
代码示例:
- @Test
- public void test6() {
-
- String content = SpiderUtils.download("http://sale.jd.com/act/6hd0T3HtkcEmqjpM.html");
-
- Pattern compile = Pattern.compile("//item.jd.com/([0-9]+).html");
-
- Matcher matcher = compile.matcher(content);
-
- HashSet<String> hashSet = new HashSet<String>();
- while (matcher.find()) {
- String goodURL = matcher.group(0);
- hashSet.add(goodURL);
- }
- for (String url : hashSet) {
- System.out.println(url);
- }
- }
打印的部分结果:(实际代码中使用时需要再添加”http:”前缀)

获取所有商品名称
1、商品名称页面示例
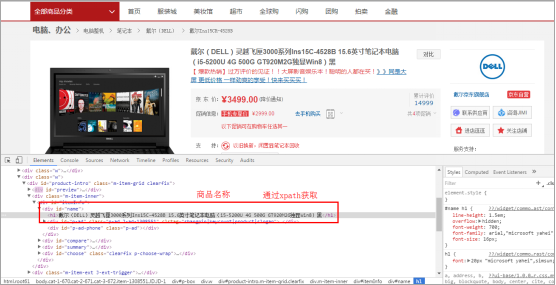
2、我们可以使用代码加载商品详情页面,然后通过工具获取XPath(获取方法可以参考之前的工具使用介绍),然后使用代码通过XPath获取Path中的商品名称。
3、代码及打印结果(所有商品的名称)
代码示例:
- @Test
- public void test7() {
-
-
- String content = SpiderUtils.download("http://sale.jd.com/act/6hd0T3HtkcEmqjpM.html");
-
- Pattern compile = Pattern.compile("//item.jd.com/([0-9]+).html");
-
- Matcher matcher = compile.matcher(content);
-
- HashSet<String> hashSet = new HashSet<String>();
- while (matcher.find()) {
-
- String goodURL = matcher.group(0);
-
- hashSet.add(goodURL);
- }
-
- for (String goodURL : hashSet) {
-
- String contents = SpiderUtils.download("http:" + goodURL);
- HtmlCleaner htmlCleaner = new HtmlCleaner();
-
- TagNode tn = htmlCleaner.clean(contents);
-
- String xpath = "//*[@id=\"name\"]/h1";
- Object[] objects = null;
- String name = "";
-
- try {
-
- objects = tn.evaluateXPath(xpath);
- } catch (XPatherException e) {
- e.printStackTrace();
- }
-
- if (objects != null && objects.length > 0) {
-
- TagNode node = (TagNode) objects[0];
-
- name = node.getText().toString();
- }
- System.out.println(goodURL);
- }
- }
打印的部分结果:

获取所有商品ID
1、商品编号页面

2、使用Chrome的开发者工具(F12)获取商品编号的XPath,然后通过代码查找到所有的ID。
3、代码及打印结果(所有商品ID)
代码示例:
- @Test
- public void test8(){
-
-
- String content = SpiderUtils.download("http://sale.jd.com/act/6hd0T3HtkcEmqjpM.html");
-
- Pattern compile = Pattern.compile("//item.jd.com/([0-9]+).html");
-
- Matcher matcher = compile.matcher(content);
-
- HashSet<String> hashSet = new HashSet<String>();
- while (matcher.find()) {
-
- String goodURL = matcher.group(0);
-
- hashSet.add(goodURL);
- }
-
- for (String goodURL : hashSet) {
-
- String contents = SpiderUtils.download("http:"+goodURL);
- HtmlCleaner htmlCleaner = new HtmlCleaner();
-
- TagNode tn = htmlCleaner.clean(contents);
-
- String xpath = "//*[@id=\"short-share\"]/div/span[2]";
- Object[] objects = null;
- try {
- objects = tn.evaluateXPath(xpath);
- } catch (XPatherException e) {
- e.printStackTrace();
- }
- TagNode node = (TagNode)objects[0];
-
- String id = node.getText().toString();
- System.out.println(id);
- }
- }
打印的部分结果:

获取所有商品的图片URL
代码示例:
- @Test
- public void test9() {
-
-
- String content = SpiderUtils.download("http://sale.jd.com/act/6hd0T3HtkcEmqjpM.html");
-
- Pattern compile = Pattern.compile("//item.jd.com/([0-9]+).html");
-
- Matcher matcher = compile.matcher(content);
-
- HashSet<String> hashSet = new HashSet<String>();
- while (matcher.find()) {
-
- String goodURL = matcher.group(0);
-
- hashSet.add(goodURL);
- }
-
-
- for (String goodURL : hashSet) {
-
- String contents = SpiderUtils.download("http:" + goodURL);
- HtmlCleaner htmlCleaner = new HtmlCleaner();
-
- TagNode tn = htmlCleaner.clean(contents);
-
- String xpath = "//*[@id=\"spec-n1\"]/img";
- Object[] objects = null;
- String picUrl = "";
-
- try {
- objects = tn.evaluateXPath(xpath);
- } catch (XPatherException e) {
- e.printStackTrace();
- }
-
- if (objects != null && objects.length > 0) {
- TagNode node = (TagNode) objects[0];
-
- picUrl = node.getAttributeByName("src").toString();
- }
- System.out.println(picUrl);
- }
- }
打印的部分结果:

获取所有商品价格
1、商品价格是通过JS异步传输的数据,无法通过XPath方法直接获取。所以首先需要我们通过之前工具使用的介绍,找到JS异步请求的URL。
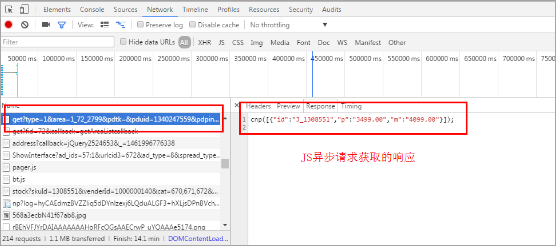
2、拷贝找到的URL:http://p.3.cn/prices/get?type=1&area=1_72_2799&pdtk=&pduid=1340247559&pdpin=&pdbp=0&skuid=J_1308551&callback=cnp
在浏览器中打开可以看到

这个URL中还有不需要的东西:&callback=cnp ,去掉之后为:
http://p.3.cn/prices/get?type=1&area=1_72_2799&pdtk=&pduid=1340247559&pdpin=&pdbp=0&skuid=J_1308551
再在浏览器中打开,结果为:(是一个Json格式字符串)

这才是我们最终要请求的URL。
3、代码及打印结果
单个商品代码:
- @Test
- public void test12() {
-
- String pricURl = "http://p.3.cn/prices/get?type=1&area=1_72_2799&pdtk=&pduid=1340247559&pdpin=&pdbp=0&skuid=J_1308551";
-
- String con = SpiderUtils.download(pricURl);
-
- JSONArray jsonArray = new JSONArray(con);
-
- JSONObject jsonObject = jsonArray.getJSONObject(0);
-
- String priceStr = jsonObject.getString("p");
- double price = Double.parseDouble(priceStr);
- System.out.println(price);
- }
打印结果:

多个商品代码:
代码示例:
- @Test
- public void test11() {
-
- HashSet<String> goodIds = goodId();
-
- for (String goodId : goodIds) {
-
- String pricURl = "http://p.3.cn/prices/get?type=1&area=1_72_2799&pdtk=&pduid=1340247559&pdpin=&pdbp=0&skuid=J_" + goodId;
-
- String con = SpiderUtils.download(pricURl);
-
- JSONArray jsonArray = new JSONArray(con);
-
- JSONObject jsonObject = jsonArray.getJSONObject(0);
-
- String priceStr = jsonObject.getString("p");
- double price = Double.parseDouble(priceStr);
- System.out.println(price);
- }
- }
打印的部分结果示例:

获取商品详情
1、商品介绍页面

2、代码及打印结果(这里只测试一个商品,之后代码中是获取所有商品)
代码示例:
- @Test
- public void test10(){
-
- String contents = SpiderUtils.download("http://item.jd.com/1308551.html");
- HtmlCleaner htmlCleaner = new HtmlCleaner();
-
- TagNode tn = htmlCleaner.clean(contents);
-
- String xpath = "//*[@id=\"parameter2\"]/li";
- Object[] objects = null;
- try {
- objects = tn.evaluateXPath(xpath);
- } catch (XPatherException e) {
- e.printStackTrace();
- }
-
- for (Object obj : objects) {
- TagNode node = (TagNode)obj;
- String val = node.getText().toString();
- System.out.println(val);
- }
-
- }
打印结果:

保存爬取的数据到MySQL
注意事项
1、由于本周热卖每个页面都用一个线程去跑,每个线程都有一个数据库链接,所以Mysql的数据库连接数需要修改大一点。
解决方式:
打开 MYSQL 安装目录打开my.ini找到max_connections默认是100, 一般设置到500~1000比较合适,然后重启MySQL。
2、这里只是演示爬取数据插入表格,所以表格的设计不是很合理。
插入商品信息
1、商品信息页面展示


2、数据库表设计
数据表说明:

数据表创建语句:
- CREATE TABLE `goodInfo` (
- `id` int(10) NOT NULL AUTO_INCREMENT,
- `goodId` varchar(20) DEFAULT NULL,
- `goodName` varchar(300) DEFAULT NULL,
- `goodPrice` varchar(10) DEFAULT NULL,
- `goodUrl` varchar(300) DEFAULT NULL,
- `goodPicUrl` varchar(300) DEFAULT NULL,
- `goodDetail` text,
- `current_time` datetime DEFAULT NULL,
- PRIMARY KEY (`id`)
- ) ENGINE=InnoDB AUTO_INCREMENT=0 DEFAULT CHARSET=utf8;
3、插入的本周热卖所有商品的信息:ID、名称、URL、图片URL、详情、插入日期。
4、代码示例和部分执行结果
代码示例:(插入商品信息的功能代码在实际代码中会抽取为方法)
-
- public void run() {
-
- String contents = SpiderUtils.download(url);
- HtmlCleaner htmlCleaner = new HtmlCleaner();
-
- TagNode tn = htmlCleaner.clean(contents);
-
-
- String goodsId = "jd_" + goodsId(tn);
- String goodsName = goodsName(tn);
- String goodsPrice = goodsPrice(tn);
-
- String goodsUrl = url;
- String goodsPicUrl = goodsPicUrl(tn);
- String goodsDetils = goodsDetils(tn);
- Date date = new Date();
-
- String curr_time = MyDateUtils.formatDate2(date);
-
-
- MyDbUtils.update(MyDbUtils.INSERT_LOG, goodsId, goodsName, goodsPrice, goodsUrl, goodsPicUrl, goodsDetils, curr_time);
- }
执行结果:
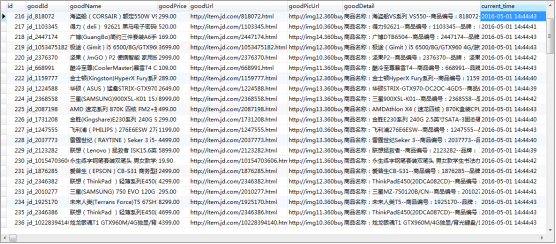
项目代码
注意:MyDbUtils、MyDateUtils这两个工具类的代码就不贴了,项目中用到这两个工具类的方法,大家可以自己实现,比较简单。
Pom依赖
- <dependencies>
- <dependency>
- <groupId>junit</groupId>
- <artifactId>junit</artifactId>
- <version>4.12</version>
- <scope>test</scope>
- </dependency>
- <dependency>
- <groupId>org.apache.httpcomponents</groupId>
- <artifactId>httpclient</artifactId>
- <version>4.4</version>
- </dependency>
- <dependency>
- <groupId>net.sourceforge.htmlcleaner</groupId>
- <artifactId>htmlcleaner</artifactId>
- <version>2.10</version>
- </dependency>
- <dependency>
- <groupId>org.json</groupId>
- <artifactId>json</artifactId>
- <version>20140107</version>
- </dependency>
- <dependency>
- <groupId>commons-dbutils</groupId>
- <artifactId>commons-dbutils</artifactId>
- <version>1.6</version>
- </dependency>
- <dependency>
- <groupId>mysql</groupId>
- <artifactId>mysql-connector-java</artifactId>
- <version>5.1.29</version>
- </dependency>
- </dependencies>
工具类
- import java.io.IOException;
-
- import org.apache.http.HttpEntity;
- import org.apache.http.client.ClientProtocolException;
- import org.apache.http.client.methods.CloseableHttpResponse;
- import org.apache.http.client.methods.HttpGet;
- import org.apache.http.impl.client.CloseableHttpClient;
- import org.apache.http.impl.client.HttpClientBuilder;
- import org.apache.http.impl.client.HttpClients;
- import org.apache.http.util.EntityUtils;
-
- public class SpiderUtils {
-
-
- public staticString download(String url) {
- HttpClientBuilder builder = HttpClients.custom();
- CloseableHttpClient client = builder.build();
- HttpGet request = new HttpGet(url);
- String str = "";
- try {
- CloseableHttpResponse response = client.execute(request);
- HttpEntity entity = response.getEntity();
- str = EntityUtils.toString(entity);
- } catch (ClientProtocolException e) {
-
- e.printStackTrace();
- } catch (IOException e) {
-
- e.printStackTrace();
- }
- return str;
- }
-
- }
业务逻辑处理类
项目入口类
- import org.htmlcleaner.XPatherException;
-
- import java.util.HashSet;
- import java.util.regex.Matcher;
- import java.util.regex.Pattern;
-
- public class Spider {
- public static void main(String[] args)throws XPatherException {
- Spider spider = new Spider();
- spider.start();
- }
-
- public void start() throws XPatherException {
- System.out.println("开始启动爬虫");
-
- String content = SpiderUtils.download("http://sale.jd.com/act/6hd0T3HtkcEmqjpM.html");
-
-
- Pattern compile = Pattern.compile("//item.jd.com/([0-9]+).html");
-
- Matcher matcher = compile.matcher(content);
-
- HashSet<String> hashSet =new HashSet<String>();
- String goodId = "";
-
- while(matcher.find()) {
- String goodURL = matcher.group(0);
- hashSet.add(goodURL);
- }
- for (String goodUrl : hashSet) {
- Thread th = new Thread(newparsePage("http:" + goodUrl));
- th.start();
- }
-
- }
-
- }






















 851
851











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









