






java8的stream流常用例子
数据准备
//准备map数据
List<Map<String,String>> mapDatas = new ArrayList<>();
for (int i = 0; i < 10; i++) {
Map<String,String> map = new HashMap<>();
if (i % 2 == 0){
map.put("province","北京");
map.put("listcount",""+i*Math.round(15f));
map.put("index","count"+i);
}else {
map.put("province","上海");
map.put("listcount",""+i*Math.round(15f));
map.put("index","count"+i);
}
mapDatas.add(map);
}
//准备entity数据
List<Student> studentList = new ArrayList<>();
studentList.add(new Student("1231","典韦","男","2011-09-08","12379","刀"));
studentList.add(new Student("1233","孙尚香","女","2012-09-08","12379","枪"));
studentList.add(new Student("1232","李白","男","2010-09-08","12379","剑"));
studentList.add(new Student("1234","王昭君","女","2010-09-08","12379","棍子"));
1. stream().forEach
//1 stream().forEach的使用(对象list跟maplist是一样使用的)
mapDatas.stream().forEach(map -> {
//获取当前map的索引
int curIndex = mapDatas.indexOf(map);
System.err.println(map);
});

2. stream().filter
//2 stream().filter 的用法 过滤出北京的数据
List<Map<String, String>> filterDatas = mapDatas.stream().filter(map -> {
return map.get("province").equals("北京");
}).collect(Collectors.toList());
System.err.println(filterDatas);
结果:
[{listcount=0, province=北京, index=count0}, {listcount=30, province=北京, index=count2}, {listcount=60, province=北京, index=count4}, {listcount=90, province=北京, index=count6}, {listcount=120, province=北京, index=count8}]
3. stream().map
//3 stream().map 提取list对象的某个属性为list,也可以提取map的某个key
List<String> snames = studentList.stream().map(student -> {
return student.getSname();
}).collect(Collectors.toList());
System.err.println(snames);
结果:
[典韦, 孙尚香, 李白, 王昭君]
4. stream().sorted
//4 stream().sorted 根据某个属性排序
// 升序
// entity排序
List<Student> sortStudents = studentList.stream()
.sorted(Comparator.comparing(Student::getSno))
.collect(Collectors.toList());
System.err.println(sortStudents);
System.err.println("-------------");
// map 排序
List<Map<String, String>> mapSortDatas = mapDatas.stream()
.sorted(Comparator.comparing(map -> (map.get("index"))))
.collect(Collectors.toList());
System.err.println(mapSortDatas);
System.err.println("------------------");
//降序
// entity排序
List<Student> sortStudents2 = studentList.stream()
.sorted((student1, student2) -> student2.getSno().compareTo(student1.getSno()))
.collect(Collectors.toList());
System.err.println(sortStudents2);
System.err.println("-------------");
// map 排序
List<Map<String, String>> mapSortDatas2 = mapDatas.stream()
.sorted((map1, map2) -> map2.get("index").compareTo(map1.get("index")))
.collect(Collectors.toList());
System.err.println(mapSortDatas2);
结果:
[Student{sno='1231', sname='典韦', sex='男', birthday='2011-09-08', phone='12379', dorm='刀'}, Student{sno='1232', sname='李白', sex='男', birthday='2010-09-08', phone='12379', dorm='剑'}, Student{sno='1233', sname='孙尚香', sex='女', birthday='2012-09-08', phone='12379', dorm='枪'}, Student{sno='1234', sname='王昭君', sex='女', birthday='2010-09-08', phone='12379', dorm='棍子'}]
-------------
[{listcount=0, province=北京, index=count0}, {listcount=15, province=上海, index=count1}, {listcount=30, province=北京, index=count2}, {listcount=45, province=上海, index=count3}, {listcount=60, province=北京, index=count4}, {listcount=75, province=上海, index=count5}, {listcount=90, province=北京, index=count6}, {listcount=105, province=上海, index=count7}, {listcount=120, province=北京, index=count8}, {listcount=135, province=上海, index=count9}]
------------------
[Student{sno='1234', sname='王昭君', sex='女', birthday='2010-09-08', phone='12379', dorm='棍子'}, Student{sno='1233', sname='孙尚香', sex='女', birthday='2012-09-08', phone='12379', dorm='枪'}, Student{sno='1232', sname='李白', sex='男', birthday='2010-09-08', phone='12379', dorm='剑'}, Student{sno='1231', sname='典韦', sex='男', birthday='2011-09-08', phone='12379', dorm='刀'}]
-------------
[{listcount=135, province=上海, index=count9}, {listcount=120, province=北京, index=count8}, {listcount=105, province=上海, index=count7}, {listcount=90, province=北京, index=count6}, {listcount=75, province=上海, index=count5}, {listcount=60, province=北京, index=count4}, {listcount=45, province=上海, index=count3}, {listcount=30, province=北京, index=count2}, {listcount=15, province=上海, index=count1}, {listcount=0, province=北京, index=count0}]
5. stream().collect 利用Collectors分组
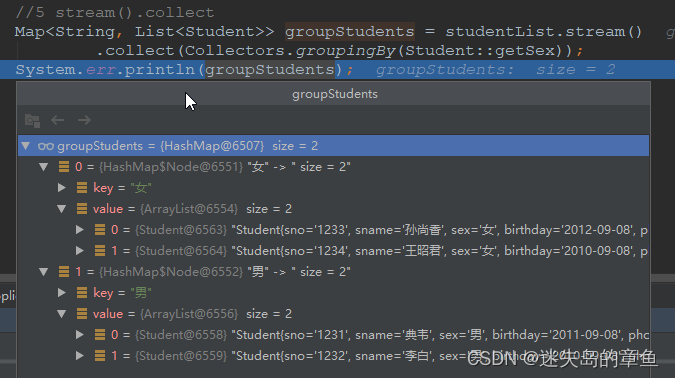
list entity分组
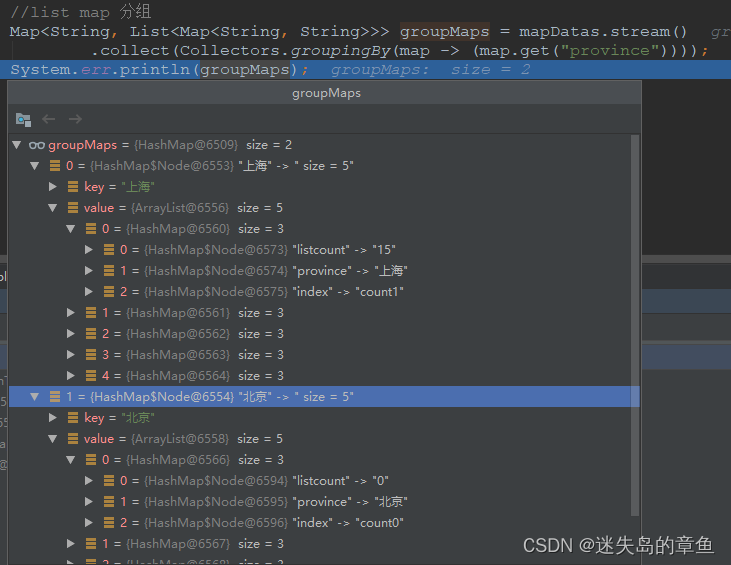
list map 分组
分组过后排序(根据某一字段排序)
list entity 分组排序
Map<String, List<Student>> sortGroupStudent = studentList.stream()
.sorted(Comparator.comparing(Student::getSno))
.collect(Collectors.groupingBy(Student::getSex));
System.err.println(sortGroupStudent);
结果:
{女=[Student{sno='1233', sname='孙尚香', sex='女', birthday='2012-09-08', phone='12379', dorm='枪'}, Student{sno='1234', sname='王昭君', sex='女', birthday='2010-09-08', phone='12379', dorm='棍子'}], 男=[Student{sno='1231', sname='典韦', sex='男', birthday='2011-09-08', phone='12379', dorm='刀'}, Student{sno='1232', sname='李白', sex='男', birthday='2010-09-08', phone='12379', dorm='剑'}]}
list map 分组排序
Map<String, List<Map<String, String>>> sortGroupMap = mapDatas.stream().sorted(Comparator.comparing(map -> map.get("index")))
.collect(Collectors.groupingBy(map -> (map.get("province"))));
System.err.println(sortGroupMap);
结果:
{上海=[{listcount=15, province=上海, index=count1}, {listcount=45, province=上海, index=count3}, {listcount=75, province=上海, index=count5}, {listcount=105, province=上海, index=count7}, {listcount=135, province=上海, index=count9}], 北京=[{listcount=0, province=北京, index=count0}, {listcount=30, province=北京, index=count2}, {listcount=60, province=北京, index=count4}, {listcount=90, province=北京, index=count6}, {listcount=120, province=北京, index=count8}]}
分组过后根据key排序
entity分组根据key排序
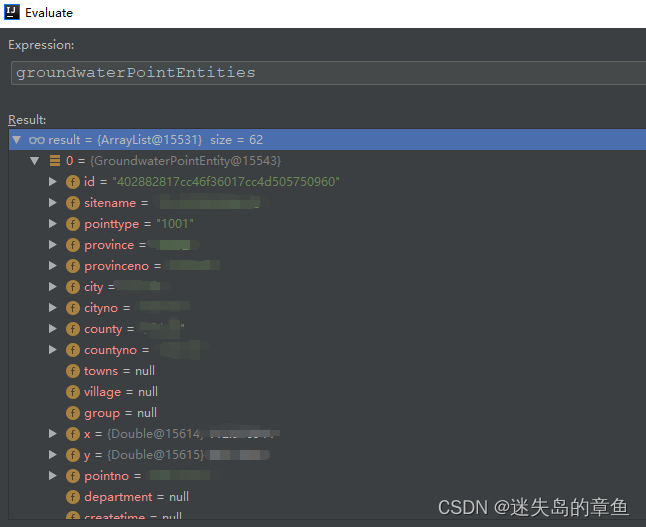
Map<String, List<GroundwaterPointEntity>> groupDatas = groundwaterPointEntities
.stream().sorted(Comparator.comparing(GroundwaterPointEntity::getPointtype)).collect(Collectors.toList())
.stream().collect(Collectors.groupingBy(GroundwaterPointEntity::getPointtype,LinkedHashMap::new,Collectors.toList()));
结果:
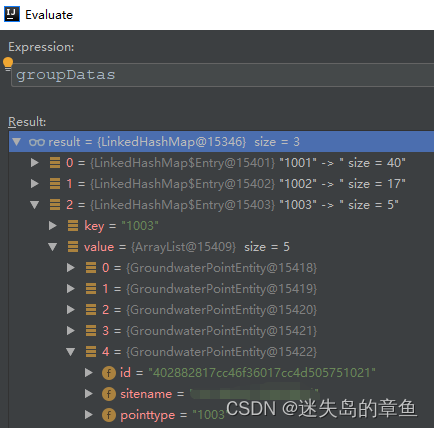
groupingBy解析
类似于Collectors.groupingBy(GWYearMonitorPointDto::getPointtypename)这种
默认进来是这个方法

继续点到下一层

可以看到groupingBy默认给了一个hashmap返回数据结构
当用对象entity进行分组的时候可以用这种分组构造方法,传入LinkedHashMap进行排序
map分组根据key排序
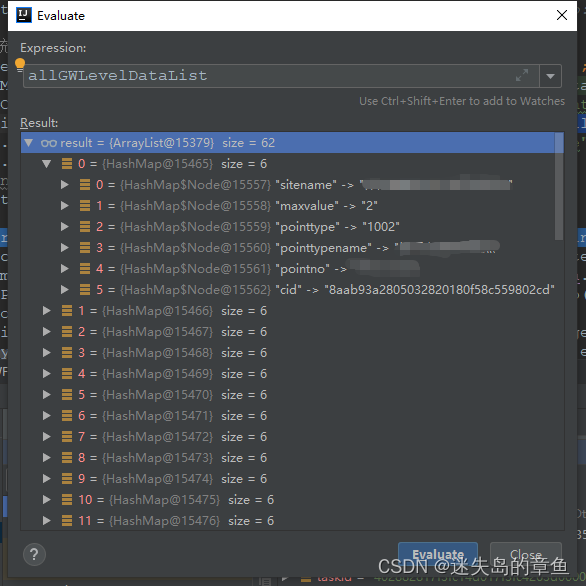
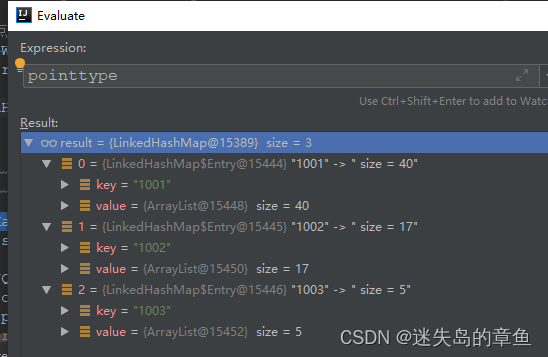
LinkedHashMap<Serializable, List<Map<String, Serializable>>> pointtype = allGWLevelDataList
.stream().collect(Collectors.groupingBy(temp -> temp.get("pointtype"))).entrySet()
.stream().sorted((o1, o2) -> {
return String.valueOf(o1).compareTo(String.valueOf(o2));
}).collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue, (oldvalue, newvalue) -> oldvalue, LinkedHashMap::new));
先将数据分组,然后再把分组后的数据进行排序利用Collectors.toMap
返回一个排序后的新map














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









