






综述
多模态模型的定义
当我们提到多模态模型时,通常是指那些能够理解和处理两种或两种以上不同类型数据(如文本、图像、声音等)并进行交互的模型。多模态模型在处理和理解信息时会利用来自不同模态的数据,并可能在多种模态之间进行转换或融合。
CLIP 则可以成为一个多模态模型
参考文献
- 大模型超详细解读 (目录)
- 多模态视频预训练最新进展概览
- 音频-文本多模态大模型
- 多模态模型整合中“以LLMs为核心”和“以Image为核心”哪个更有前景?
- 多模态学习—简介
- 视觉预训练模型梳理: ViT & CLIP & MAE & SimCLR
- Transformer学习(八)—BeiT和MAE
模型发展
BEiT: BERT Pre-Training of Image Transformers,CV 领域的 Bert,将图像离散化然后进行掩码学习,MIM
BEiT 系列的发展:
- BEIT v1 (2021.6),提出一种成功的视觉自监督预训练方法 Masked Image Modeling,但仅限于视觉任务
- VLMo (2021.10),以 BEiT 作为第一步,提出一种分阶段的视觉语言预训练方法
- VL-BEiT (2022.6),设计一种单阶段,同时使用单一模态数据集和多模态数据集的,视觉语言预训练方法
- BEIT v2 (2022.8),仅限于视觉任务
- BEIT v3 (2022.8)
代码库
-
salesforce 的多模态算法库,包含 BLIP、ALBEF 等算法,以及VQA等多种应用。
salesforce/LAVIS -
meta 的多模态算法库,包含ViLT、MMBT等算法,侧重于多模态分类等任务。
facebookresearch/multimodal -
meta 的另一个多模态仓库,包含 CLIP、FLAVA 等模型,侧重多模态预训练等任务。
facebookresearch/mmf
三种常见结构
- 单塔结构同时编码所有的图像-文本组合,并通过图像-文本匹配的目标获得相似度分数(VL-BERT,UNITER,ViLT,ALBEF 等)
- 双塔结构分别对图像和文本进行编码,并通过简单的点乘来计算相似度的分数(CLIP,ALIGN)
- 混合结构(混合专家模型 Mixture-of-Modality-Experts, MoME) 是由双塔结构和单塔结构串联组成,首先从双编码器中获得前 k 个候选答案,然后使用后面的单塔结构计算这 k 个候选者的图像文本匹配分数 (VLMo,VL-BEIT,ALBEF )
单塔和双塔的优缺点参考 多模态超详细解读 (四):VLMo:混合多模态专家的视觉语言预训练
三种常见 loss
- Contrastive Loss, 对比 loss
- MDM, Mask Data Modeling
- MAE,也是一种 mask loss,但是 encoder 仅输入未被 mask 的部分
Triplet Loss 可以看作是对比学习的一种特殊情况,其中每次对比一个正样本对和一个负样本对。然而,对比学习在处理负样本时通常更加高效,因为它可以在每个训练步骤中同时考虑多个负样本。
常见的下游任务
- 检索 (找相似度最大的)
- 分类
- 拿到 embedding 之后直接下游有标签 finetune
- zero-shot,本质是用分类标签构造 caption 后检索
- caption
- 没有 LLM 就是在提前设置好的 caption 里面检索
- 有 LLM 就用 LLM 生成
图像—文本多模态
以 ITC 收尾的 beit3 v2 就是一个 CLIP 模型,是一个双塔模型
ITC, Image-Text Contrastive Learning: 在跨模态学习中,图像-文本对比学习(Image-Text Contrastive Learning)是一种常用的方法
双塔模型(Two-Tower Model),在机器学习领域,特别是在推荐系统和信息检索中,是一种常见的深度学习架构。这种模型设计包含两个独立的网络塔(tower),分别用于处理和映射两种不同类型的输入数据至一个共同的嵌入空间(embedding space)。
在训练时,双塔模型通常采用对比损失(contrastive loss)或者三元组损失(triplet loss)来优化模型参数,使得相关的用户-物品对的嵌入向量在嵌入空间中更接近,而不相关的则更远离。
DALLE
DALLE 实际上并不是多模态模型,但是后续很多模型用了其中的一些结构,主要是 dVAE 把图像离散化
尽管 DALL·E 在生成图像时使用了文本描述,但它的主要功能是图像生成,DALL·E 在某种程度上处理多模态数据,而不是同时处理和理解多种模态数据。因此,DALL·E 更常被描述为一个条件生成模型,而不是一个多模态模型。
DALLE 的
- dVAE
- Transformer
- CLIP
三个模型都是不同阶段独立训练的。(VALLE 的时候为啥没有直接加上 CLIP 呢)

训练阶段: DALL·E 使用图像和相应的文本描述来学习如何生成图像,自回归的方式生成
推理阶段: DALL·E 只需要文本描述即可生成图像,不需要输入图像
和 VALLE (S1 自回归, S2 分层推理) 或者我的 SoundStorm (S1 自回归 text->semantic, S2 Diffusion semantic->acoustic, acoustic -> wav) 的 Stage 1 非常相似
训练阶段: text 作为 condition,自回归地生成 codec
推理阶段: prompt wav 的 text + 输入的 text 拼接作为 condition,prompt wav 作为 prompt,自回归地生成 wav,最终生成的 wav 的开头就是 prompt wav,需要截断,prompt wav 在这里的作用是指导音色和情感,但是也可以类似于 DALLE 一样在推理的时候直接不加 prompt wav(也就是 DALLE 中的参考图像)相应地 prompt wav 的 text 也不需要拼接到输入 text 之前,直接输入 0 作为自回归推理的开始,不过这样的话,音色就是不确定的
DALLE 也可以在推理时加入 prompt 图像指导生成图像的风格(DALLE-2), DALLE 是文字描述指导图像生成,本身就可以在文字描述中增加风格的描写,比 VALLE TTS 这种文本和语音必须匹配的任务自由度更高,语音合成从 VALLE 进入大模型时代,核心变化就是连续特征变成离散特征,可以从更多的数据中收益
CLIP
也是需要标签的,成本高
CLIP 是由 OpenAI 提出的一种多模态神经网络,它能有效地借助自然语言的监督来学习视觉的概念,但并不是用类似 ImageNet 高质量,密集标注数据集做完全监督
作者创建了一个包含4亿对 (图像,文本) 的新数据集 WebImageText (WIT),训练数据是文本-图像对:一张图像和它对应的文本描述,并通过对比语言-图像预训练的方式训练了 CLIP 模型,是一种从自然语言监督中学习视觉模型的有效新方法。(如何构建?是文本但不是分类标签?caption 任务)
判断图片和文本的匹配程度
“词袋”(Bag of Words,BoW)是一种简单但有效的文本表示方法,它忽略了单词在文本中的顺序和上下文,并将文本表示为仅仅是单词出现次数的集合。
并没有用到 BEiT 的用 VAE 将图像离散化
paper
Learning Transferable Visual Models From Natural Language Supervision
代码
参考文献
- 官方文档:CLIP: Connecting text and images
- 多模态超详细解读 (一):CLIP:大规模语言-图像对比预训练实现不俗 Zero-Shot 性能
- 神器CLIP:连接文本和图像,打造可迁移的视觉模型
创新点
模型细节
- 联合训练阶段: 联合训练了一个处理图像的 CNN 和一个处理文本的 Transformer 模型,来预测图像的 caption
- 对比学习阶段: 给定一个 Batch 的 N 个 (图片,文本) 对,图片输入给 Image Encoder 得到表征 I ,文本输入给 Text Encoder 得到表征 T,作者认为配对的属于是正样本, 不配对的属于负样本。最大化 N 个正样本的 Cosine 相似度,最小化 N²-N 个负样本的 Cosine 相似度。
- 从头开始训练 CLIP,不使用 ImageNet-1K 权重初始化 Image Encoder,也不使用预先训练的权重初始化 Text Encoder
- 使用线性投影将每个编码器的表征映射到多模态的嵌入空间 -> 需要在同一个尺度下才能计算 text 和 image 的相似度
- Image Encoder: 改进版的 ResNet-50 和 ViT ✅,图像的输入 resize 为固定的大小
Text Encoder: 改进版的 Transformer,[EOS]处 Transformer 末层的输出被视为文本的特征,然后通过 LN,后接 Linear 层投影到多模态空间中,所以文本嵌入的大小是固定的 - CLIP虽然是多模态模型,但它主要是用来训练可迁移的视觉模型,如 zero-shot 的图像分类任务
应用
-
Zero-Shot Transfer
一张 ImageNet-1K 验证集的图片,我们希望 CLIP 预训练好的模型能完成这个分类的任务,因为 Image Encoder 没有分类头,于是采用了下面的 Prompt Template 模式比如来一张 ImageNet-1K 验证集的图片,作者把它喂入 CLIP 预训练好的 Image Encoder,得到特征 I1,接下来把所有类别的词汇 “cat”, “dog” 等,做成一个 prompt:“A photo of a {object}”,并将这个 prompt 喂入 CLIP 预训练好的 Text Encoder,依次得到特征 T1, T2,…,Tn,最后看哪个的余弦相似度和 I1最高,就代表该图片是哪个类别的。进一步地,可以将这些相似度看成 logits,送入 softmax 后可以到每个类别的预测概率。
可以简单理解原本的分类是做填空题,这种方式变成了选择题,需要提前把所有可能的答案告诉他,需要和所有可能的结果都计算下相似度
本质是一个图像检索任务
-
Representation Learning
表征学习(representation Learning),即自监督学习中常用的 linear probe:用训练好的模型先提取特征,然后用一个线性分类器来有监督训练(如 ASR 里面用语音 SSL 的特征 finetune ASR 任务)作者进一步评估了CLIP 的表征学习能力,一种比较常见的方法是冻住模型的骨干部分,只训练最后的分类器,通过在某个数据集上的精度来衡量提取到的特性的好坏
-
作为 DALLE 的排序模型
-
更多应用参考 神器CLIP:连接文本和图像,打造可迁移的视觉模型
BEiT
自监督
ViT (from 谷歌) -> 图像领域的 Transformrer,把图像分成了 patch
BEiT -> 图像领域的 BERT,用了 dVAE 编码和 MIM 掩码学习(不是恢复 mask 块的像素(回归问题)而是恢复 mask 块的 visual token(分类问题))
事实上像素级自编码是从 NLP 到 CV 的最直接翻译,但是效果更差,所以用了 dVAE
本文提出的 MIM 方式比对比学习和自我蒸馏❓更好
paper
BEiT: BERT Pre-Training of Image Transformers
代码
参考文献
- 通用多模态基础模型BEiT-3:引领文本、图像、多模态预训练迈向“大一统” 的第一部分
- 图像预训练:BEIT
- Self-Supervised Learning 超详细解读 (三):BEiT:视觉BERT预训练模型
创新点
- MIM mask 学习
- 预训练好的 dVAE(DALLE)把图像离散化
模型细节
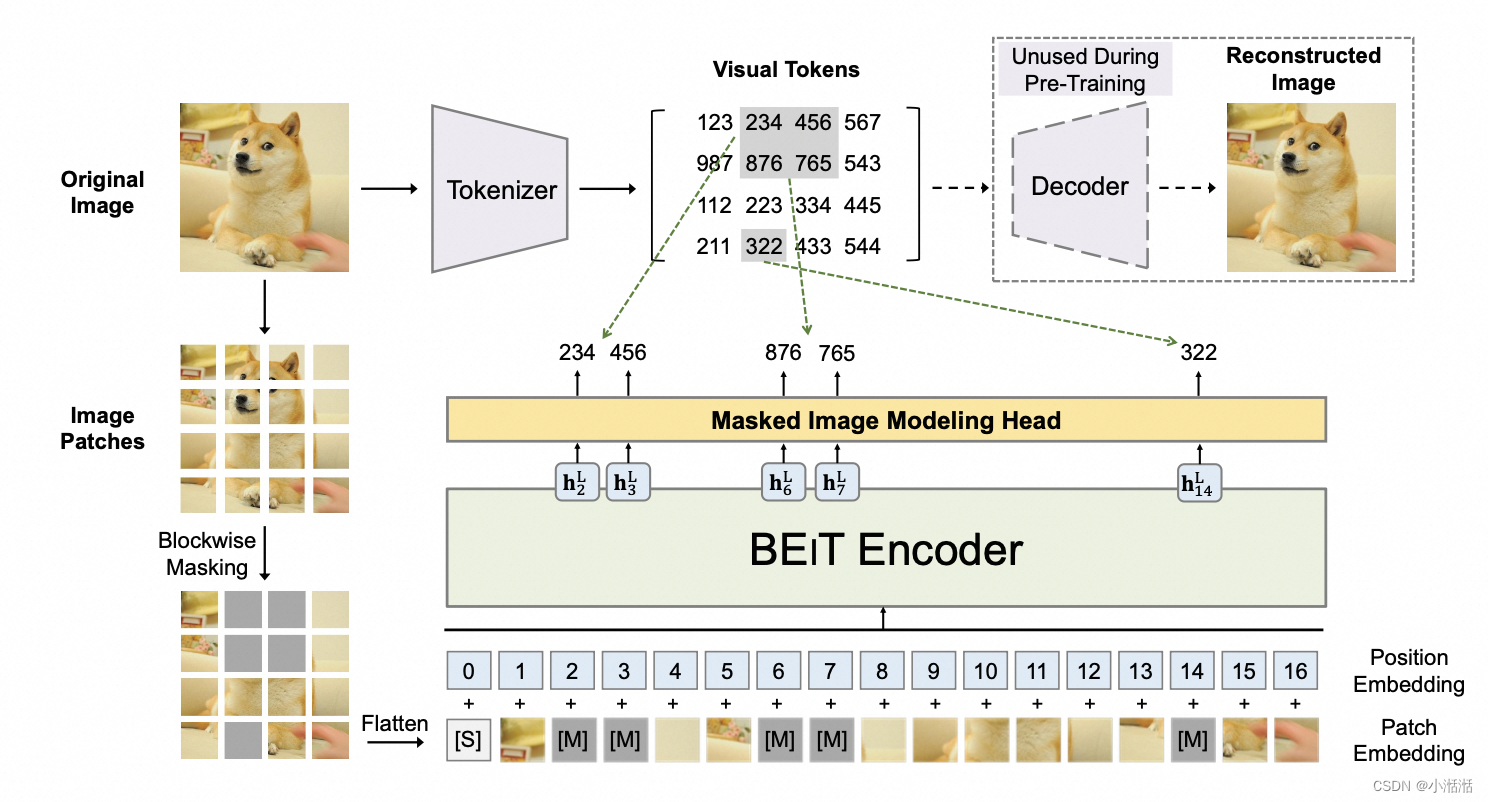
本质是一个自监督的图像领域的 BERT,BERT 通过 MLM 方式训练,BEiT 通过 MIM 方式训练,本质还是一个图像任务,下游任务是图像分类和语义分割,可以通过把 BEiT Encoder 输出的特征 h 加一些轻量级任务层实现
BERT 输入输出都是 token,BEiT 输入是 image patch 输出是 visual token
不同的是,BERT 的 Encoder 输入是 token,输出还是 token,让盖住的 token 与输出的预测 token
越接近越好;而 BEIT 的 Encoder 输入是 image patches,输出是 visual tokens,让盖住的位置输出的
visual tokens 与真实的 visual tokens 越接近越好。真实的 visual tokens 是通过一个额外训练的
dVAE 得到的
图像对比学习有一些问题(相比之下还要平衡各个损失函数之间的权重,需要非常大的批 batchsize,跑大模型很困难),参考 通用多模态基础模型BEiT-3:引领文本、图像、多模态预训练迈向“大一统”,本文类似于 Bert 的掩码图像建模(Masked Image Modeling, MIM)
但是文本是离散信号,图像是连续信号,需要解决这个问题:
- 通过编码学习 Tokenizer,将图像变成离散的视觉符号(visual token),类似文本(因为视觉任务本身没有一个大的词汇表);
- 将图像切成多个小“像素块”(patch),每个像素块相当于一个字符
对比学习: 真实帧特征为正,相邻帧特征为负,如,wav2vec2
MLM: 掩码学习,如,Bert,hubert
w2v-bert 是 对比学习 + MLM
骨干网络是 ViT,核心逻辑是把图像分成 patch
ViT(Vision Transformer)是用于计算机视觉任务的一种模型,它将 Transformer 架构——最初是为了处理自然语言处理(NLP)任务而设计的——应用到了图像识别领域。ViT 是由Google Research的Alexey Dosovitskiy 等人在 2020 年的论文《An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale》中提出的。
ViT 的核心思想是将图像分割成一系列的小图像块(patches),就像在自然语言处理中将文本分割成一系列的单词或词片段(tokens)一样。这些图像块被线性嵌入(embedding)到一个高维空间中,并被处理为序列数据。ViT 模型接着在这些嵌入上应用标准的Transformer结构,包括自注意力(self-attention)机制和前馈网络(feed-forward network),来学习图像块之间的关系。
具体来说,ViT 的步骤如下:
图像分割: 将输入图像分割成大小相等的小块(例如16x16像素的块)。
块嵌入: 将每个小块映射到一个固定大小的向量中。通常,这涉及到一个线性变换和添加一个位置编码(position encoding)以保留图像块的空间位置信息。
Transformer 编码: 将这些嵌入的块(视为序列的元素)输入到 Transformer 编码器中,Transformer 编码器由多层自注意力层和前馈网络层组成。
类别嵌入: 通常在序列的开始加入一个特别的“类别”(class)嵌入,用于聚合全局信息并在最后的层中用于分类任务。
输出: 对于分类任务,最终使用类别嵌入来进行分类预测。由于其简单和高效,ViT 在多个图像识别基准测试中取得了优异的性能,特别是当配合大量训练数据和数据增强技术时。它的成功表明 Transformer 架构也可以在视觉领域中很好地工作,不仅仅是在语言任务中。
和 Transformer 在 LLM 中的地位一样,ViT 通常作为 LVM 的组件使用
与 BERT 的自监督学习不同,ViT 在预训练过程中采用了基于 ImageNet 数据集的有监督学习方法
BEiT 为视觉大模型预训练的研究开创了一个全新的方向,首次将掩码预训练应用在了 CV 领域非常具有创新性
总之 BEiT 是 CV 领域的 BERT
涉及到 2 个模型:
- 把图像 tokenize(encode) 成 visual token 的 VAE 模型 ,这里是 dVAE,image tokenizer,是 DALLE 提供的预训练模型 => 每个 visual token 是一个位于 [1,8192] 之间的数,就像有个 image 的词汇表一样
VQ-VAE 和 dVAE 都是学习离散潜在表示的VAE的变种,它们利用不同的技术来实现连续到离散的映射
在 VQ-VAE 中,编码器输出的连续潜在变量会被量化为最近的码字,这些码字来自于预先定义的码本(codebook) 或词汇表(vocabulary)
dVAE 可能会使用 Gumbel-softmax 分布(为了解决 visual token 是离散的数,所以优化时没法求导的问题)或其他方法来对连续潜在表示进行离散化 - BEiT Encoder
- (最后一层) softmax classifier
BEiT-2
BEiT v1 使用 DALLE 里面预训练好的 image tokenizer,BEiT v2 训练自己的 VAE,BEiT v2最核心的贡献是使用了 VQ-KD 作为视觉标志的生成结构,本质还是图像预训练模型
VAE 包含 dVAE 和 VQVAE,v1 用 dVAE,v2 用 VQVAE(引入了 codebook)
BEiT v1 并未对 dVAE 学到的这个语义空间进行深入的探讨和优化,这也大大限制了BEiT v1的可解释性和使用空间。
BEiT v2 的核心思想是通过一个训练好的模型,例如 CLIP 或是 DINO 作为 Teacher 来指导视觉标志的学习,这个方法在 BEiT v2 中被叫做矢量量化-知识蒸馏(Vector-quantized Knowledge Distillation,VQ-KD)
paper
BEiT v2: Masked Image Modeling with Vector-Quantized Visual Tokenizers
代码
参考文献
创新点
- 矢量量化-知识蒸馏(Vector-quantized Knowledge Distillation,VQ-KD)训练 image tokenizer
- 引入了
[CLS]标志来学习图像的全局信息,从而使得 BEiT v2 在线性探测(Linear Probe)方式也能拥有非常高的准确率 - VAE 解码器的目标从图像像素变成了由教师模型编码的语义特征
模型细节
VQ-KD
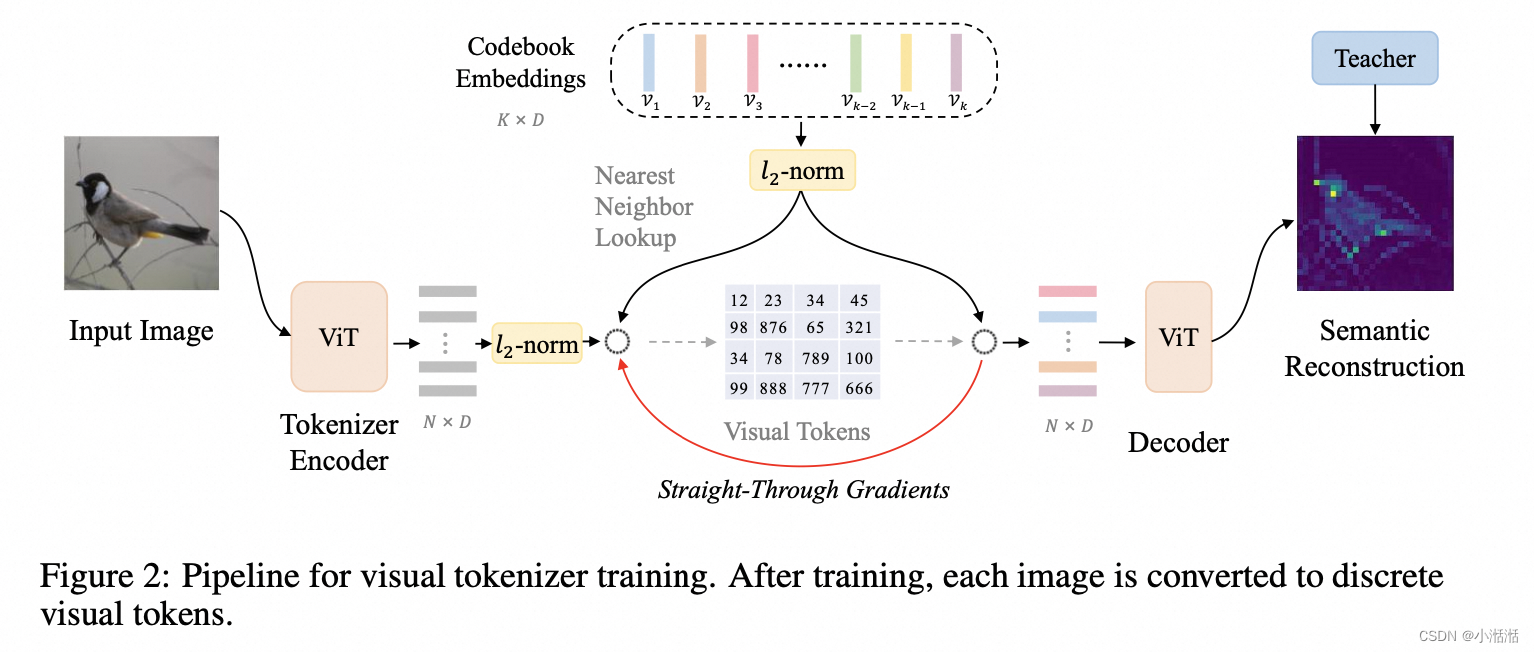
编码器: 根据一个可学习的代码本将输入图像转换为离散的标记
解码器: 学习重构由教师模型( CLIP 或是 DINO,如 CLIP 的 image encoder)编码的语义特征,条件是基于离散的标记
编码器和解码的 backbone 也是 ViT,DALLE 的 dVAE 的 backbone 是 CNN
BEiT v2 预训练
为了学习图像的全局信息,BEiT v2 借鉴了Condenser 的思想,在输入编码中拼接了 [CLS] 标志,然后通过对 [CLS] 标志的预训练来得到图像的全局信息。因此BEiT v2 的预训练分成两个部分:
- MIM 的训练
与 BEiT v1 类似,增加了[CLS] [CLS]标志的训练
两个浅层Transformer只会用在[CLS]预训练中,当预训练完成之后,这一部分便会被舍弃
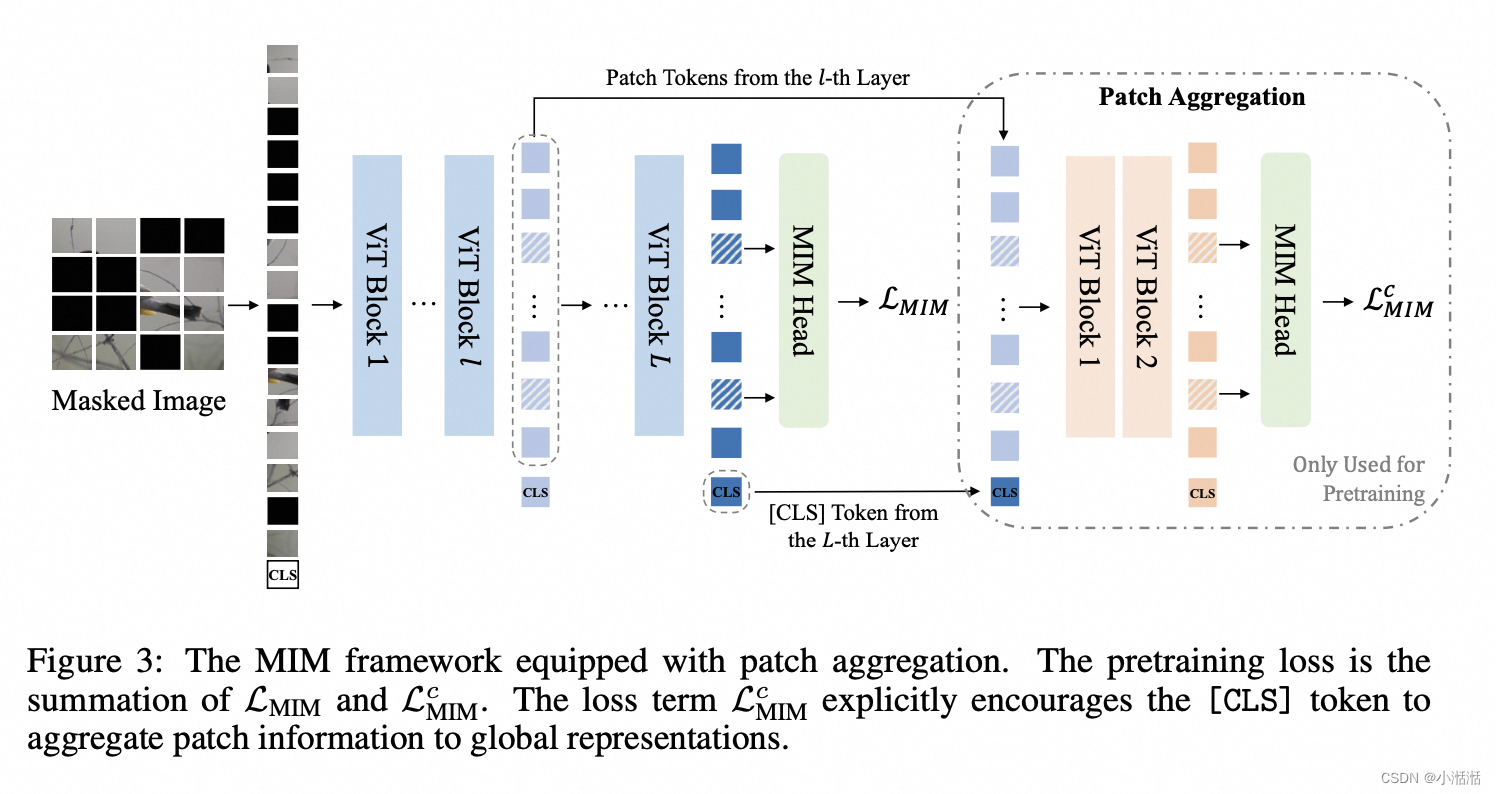
上图 2 个部分是一起训练的,因为 The pretraining loss is the summation of LMIM and LcMIM,训练的 loss 是两个 loss 相加
VLMo
paper
VLMo: Unified Vision-Language Pre-Training with Mixture-of-Modality-Experts
代码
参考文献
模型细节
VLMo中提出了Multiway Transformers这个大道至简但又行之有效的架构。将多种模态对应到不同的FFN参数,对self-attention进行共享。如果对多模态工作相关工作进行过梳理,就会发现前几年的不少工作都纠结在“单塔”、“双塔”的建模之争中,或是陷在无穷无尽的特征融合魔改中。在 VLMo 里,一个重要的洞察是将单塔、双塔模型进行了有机统一。这样预训练同样的参数,即可以进行深度的特征融合,也可以对单模态进行编码。
VLMo 相当于是一个混合专家 Transformer 模型 (Mixture-of-Modality-Experts, MoME)
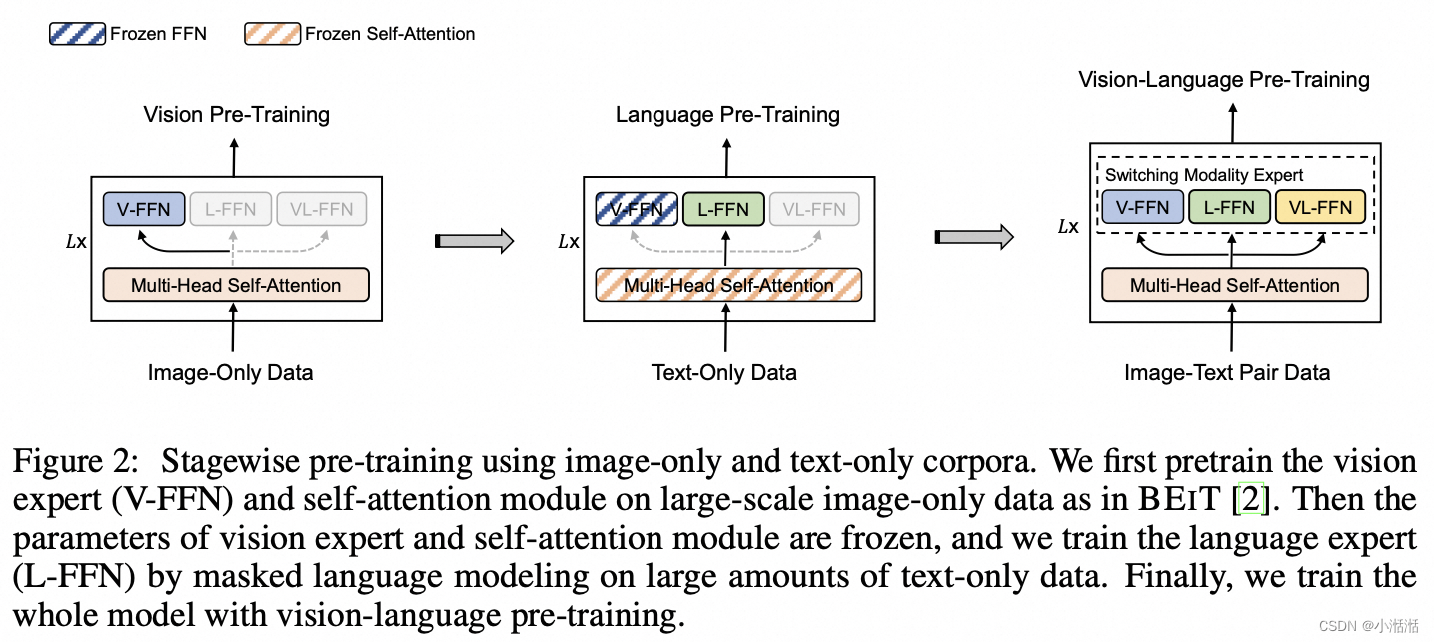
VLMo 在训练的时候也是遵循多模态模型常见的三个预训练任务,分别是图文对比学习 (Image-Text Contrastive Learning) (类似于 CLIP),图文匹配 (Image-Text Matching) (二分类,yes or no) 和完形填空 (Masked Language Modeling) (图片 + 部分 mask 的文本,对 mask 住的文本进行填空)。此外,作者还提出一种分阶段的预训练策略,除了图像-文本对数据集,还有效地利用了大规模的纯图像和纯文本语料库。第一阶段像 BEIT 一样使用 masked image modeling 的方法在视觉数据集上预训练,第二阶段像 BERT 一样使用 masked language modeling 的方法在文本数据集上预训练,第三阶段使用上阶段的初始化权重在多模态数据集上预训练。
MoME Transformer 也是先一个 Multi-Head Self-Attention 的子模块,再串联一个 FFN 的子模块。但是和正常 Transformer 不同的是,这个 FFN 子模块是由3个并行,独立的 FFN 并联得到的。这3个 FFN 分别是 Vision-FFN,Language-FFN 和 Vision-Language-FFN,作者称它们分别为:视觉专家,文本专家和视觉文本专家。它们可以看成是3个专家模型,但是前面的 Multi-Head Self-Attention 都是共享权重的
训练过程:
VLMo 的预训练任务也基本遵循了常规多模态学习的方案的 3 个经典预训练任务,分别是:
-
对比学习任务 (Image-Text Contrast, ITC)
-
图文匹配任务 (Image-Text Matching, ITM,二分类)
-
完形填空任务 (Masked Language Modeling, MLM,预测任务)
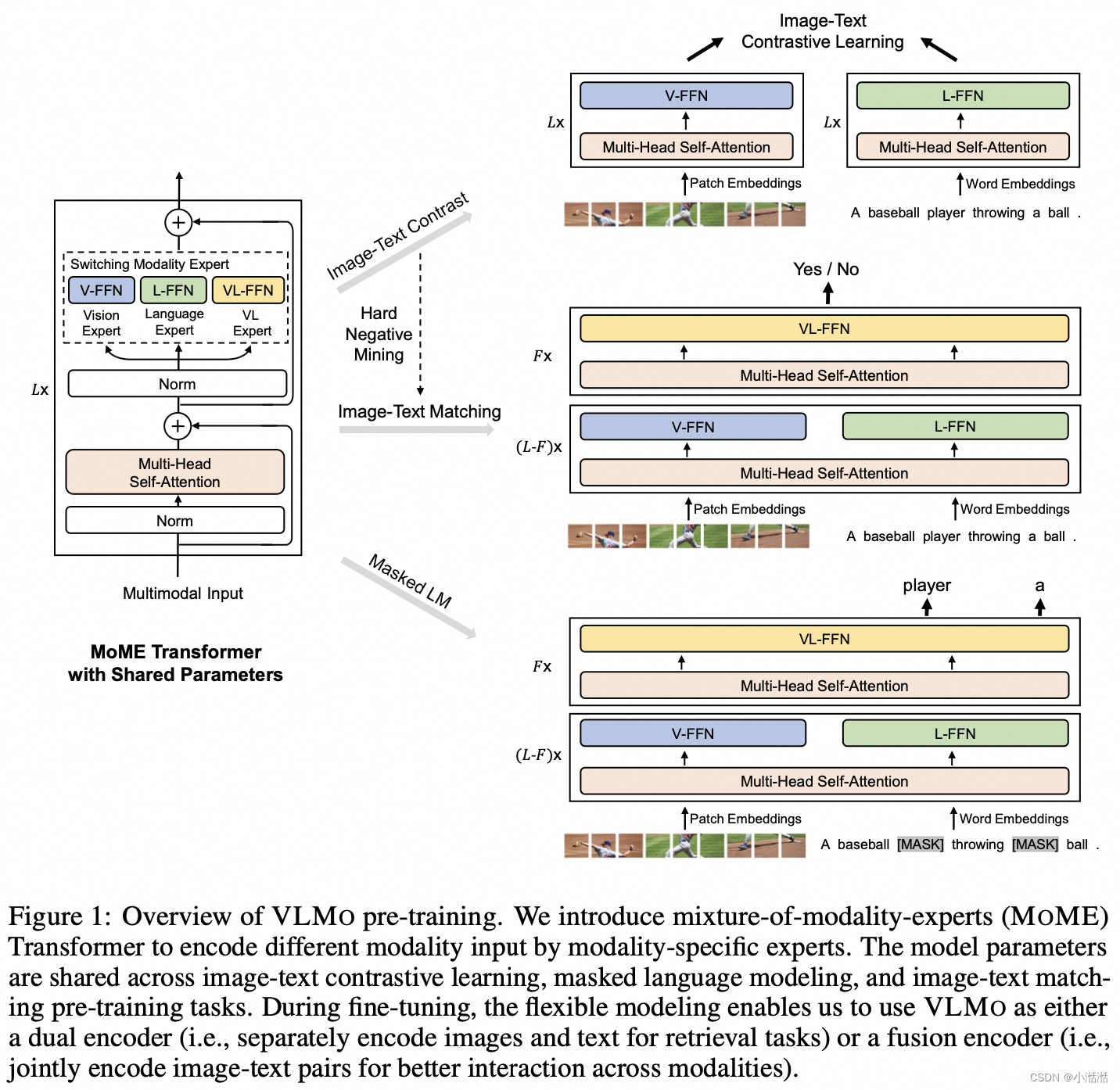
分阶段预训练过程:
目标是利用大规模的纯图像的数据集和纯文本的语料库 -
第1步 (视觉预训练): 在纯图像数据集上面预训练视觉专家模型,方案就是 Masked Image Modeling 的做法。文本专家模型和视觉文本专家模型的 FFN 权重冻结,共享的 Self-Attention 参数更新。
-
第2步 (文本预训练): 在纯文本数据集上面预训练文本专家模型,方案就是 Masked Language Modeling 的做法。视觉专家模型和视觉文本专家模型的 FFN 权重冻结,共享的 Self-Attention 参数也冻结,注意这里的 Self-Attention 的参数还是视觉数据集上面训练出来的了。
-
第3步 (多模态预训练): 在多模态数据集上面预训练文本专家模型,方案就是上面的3个目标函数,所有参数都开放更新。
下游任务:
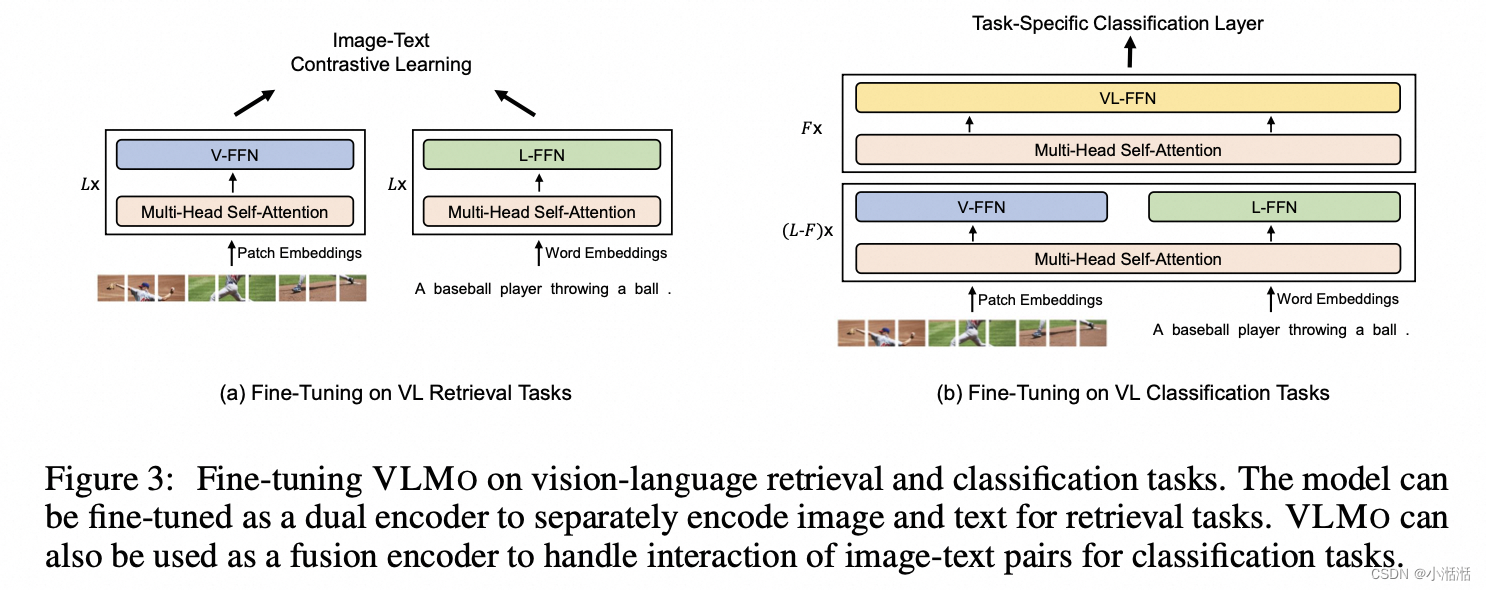
- a) 检索任务,双塔结构
- b) 视觉问答 (Visual Question Answering, VQA) 和视觉推理 (Natural Language Visual Reasoning, NLVR, 该任务是确定文本描述是否适用于一对图像 ),单塔结构
VQA 任务就是说给出了一个自然图像和一个问题,任务是生成或者说选择出正确的答案,常见的做法,将 VQA 2.0 转换为分类任务,并从 3,129 个备选答案中进行选择
NLVR 给出一个文本和一对图像,任务是预测描述对图像输入是否正确,把三元组输入 (image1, image2, text) 变成两个图文对
VL-BEiT
是 VLMo 的后续工作
VLMo 是一种分阶段的视觉语言预训练方法,第一步训练视觉模型,第二步训练文本模型,最后一步才是视觉文本的多模态模型。VL-BEIT 给出一种极简多模态解决方案。VL-BEIT 使用共享的 Transformer 对单模态和多模态数据进行掩码预测 (Masked Prediction),是一种从头开始训练的单阶段的视觉语言预训练方法。 在这一个阶段里面,VL-BEIT 的目标不仅仅包括了使用纯视觉数据集的掩码图像建模,还包括了使用纯文本数据集的掩码语言建模,和使用多模态数据集的掩码视觉语言建模。
paper
VL-BEiT: Generative Vision-Language Pretraining
代码
https://github.com/microsoft/unilm/tree/master/vl-beit -> 没有代码只有 README
参考文献
模型细节
遵循了 VLMo 的架构设计思路。这样做的好处是在预训练之后,VL-BEIT 模型可以微调为纯视觉模型,又可以微调为双塔多模态模型或者单塔多模态模型,以用于各种视觉和视觉语言下游任务
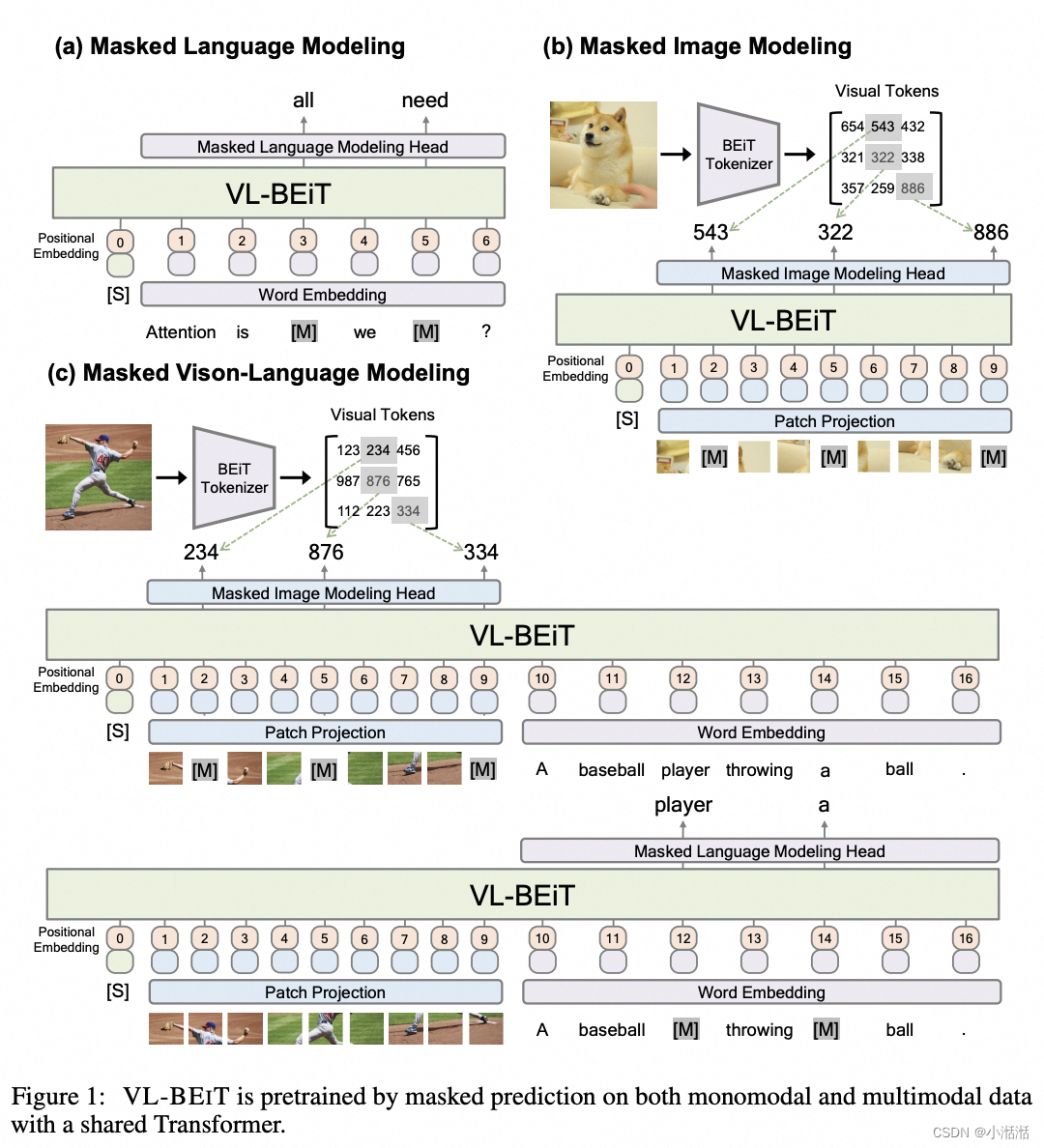
VL-BEIT 在预训练时同时使用了3个预训练任务,它们分别是:
- 掩码语言建模 (Masked Language Modeling, MLM)
- 掩码图像建模 (Masked Image Modeling, MIM)
- 掩码视觉语言建模 (Masked Vision-Language Modeling, MVLM)
这个任务使用的数据集是成对的图片,文本对。这个任务的目标是根据图片和对应的文本线索,去恢复被 mask 的图像 patch 和文本 token,如图 1© 所示。以 50% 的概率随机 mask 文本 token,根据图片和损坏的文本的联合表征来恢复 mask 的文本 token。同样随机 mask 图片 patch,根据损坏的图片和文本的联合表征来恢复 mask 的图片 patch。MVLM 任务鼓励模型去学习图片线索和文本信息之间的对齐。(感觉和 ERNIE-SAT 有点像,ERNIE-SAT 是随机 mask 输入法人语音和 phoneme 的部分片段 )
VL-BEIT 在预训练时要使用3种数据集:
- 纯视觉数据集
- 纯文本数据集
- 多模态数据集
VL-BEIT 做了两种经典的多模态下游任务:
- 多模态分类任务 (VQA ,NLVR2) => VQA 同 VLMo 转为分类任务,微调为一个单塔模型,NLVR2 本身就是二分类
- 多模态检索任务 => 首先使用 VL-BEIT 作为双塔模型来获得前 k 个候选者,然后使用该模型作为单塔模型,根据其图像-文本匹配分数对候选者进行排名❓(混合结构)
以及两种视觉任务:
- 图像分类
- 语义分割
BEIT-3🌟
我们现在只能训练起来 base
VL-BEIT 是一个大的模型 VL-BEIT,BEIT-3 是 3 个小模型,V-FFN,L-FFN, VL-FFN
BEIT-3 的模型尺寸量级达到了 ViT-giant 的级别
BEIT-3 仅仅采 Mask Data Modeling 这一个目标函数,不仅学习表征,而且学习不同模态之间的对齐,仅有 MDM 一种 loss
BEIT-3 从三个方面实现了大一统:
- 模型架构 => MoME,即 Multiway Transformer
- 预训练任务 => Mask Data Modeling
- 预训练架构放大 => ViT-giant
VLMo 中使用的 Mixture-of-Modality-Experts, MoME = 这里的 Multiway Transformer
BEIT-3 没有使用图像-文本对比损失进行预训练
只使用一种预训练任务(MLM) 而不像 VLMo 那样使用多种训练任务如对比学习、图文匹配和完形填空等
【Vision Transformer】BEiT3详解 有人评论表示 BEiT3 除了 scale up 以外和 VL-BERT 没什么区别,原作董力表示赞同,VL-BERT 也是微软亚研院同一个团队的, VL-BEiT 里面也引用了 VL-BERT
仅使用交叉熵损失训练
paper
Image as a Foreign Language: BEiT Pretraining for All Vision and Vision-Language Tasks
代码
参考文献
- 多模态超详细解读 (十):BEIT-3:一个模型架构和一个训练任务,多模态领域的集大成者
- 原作之一的评价:如何评价微软提出的BEIT-3:通过多路Transformer实现多模态统一建模?
- 通用多模态基础模型BEiT-3:引领文本、图像、多模态预训练迈向“大一统”
模型细节
VLMo 这个架构里面:FFN 分为 3 块,分别是 Vision FFN,Language FFN 和 Vision-Language FFN ,作者把每个 FFN 命名为 Expert
- 文本数据通过SentencePiece分词器
- 图像数据通过BEIT v2的分词器(VQ-KD)
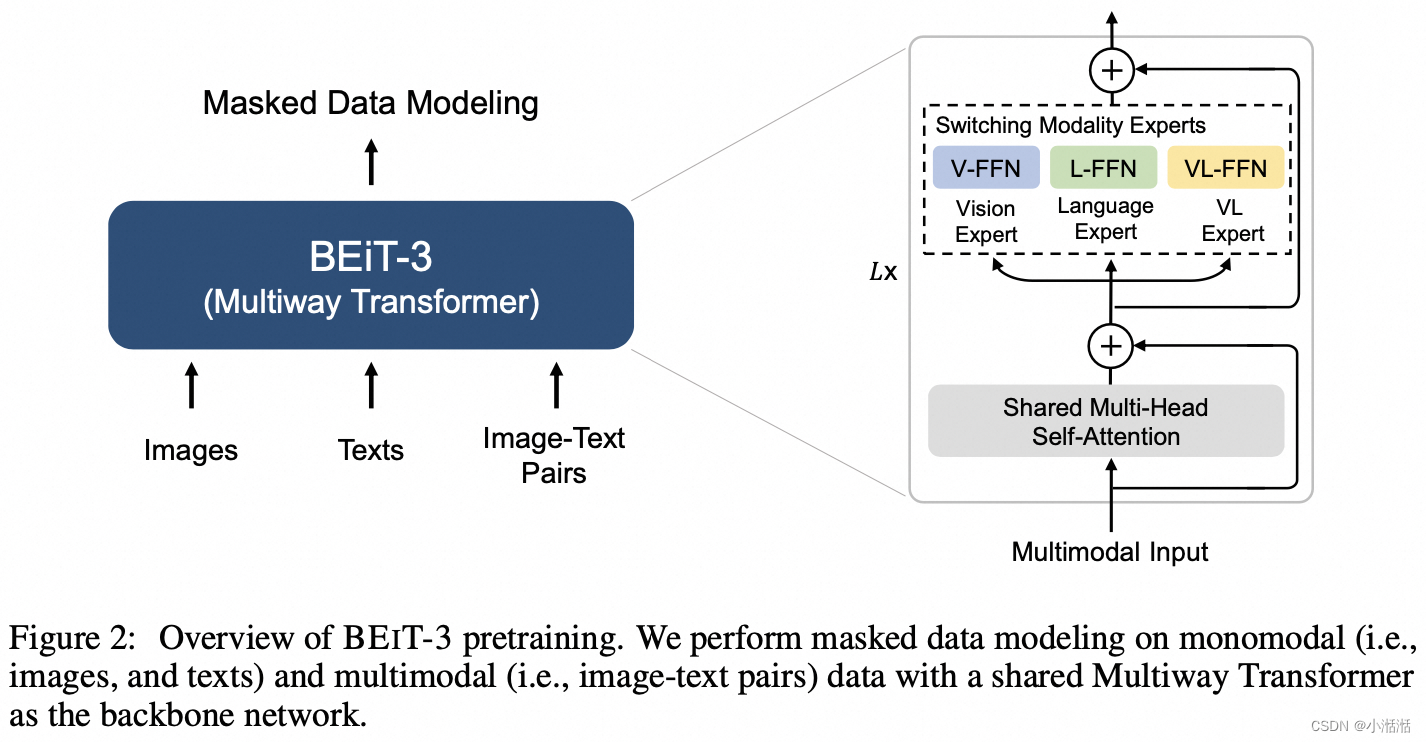
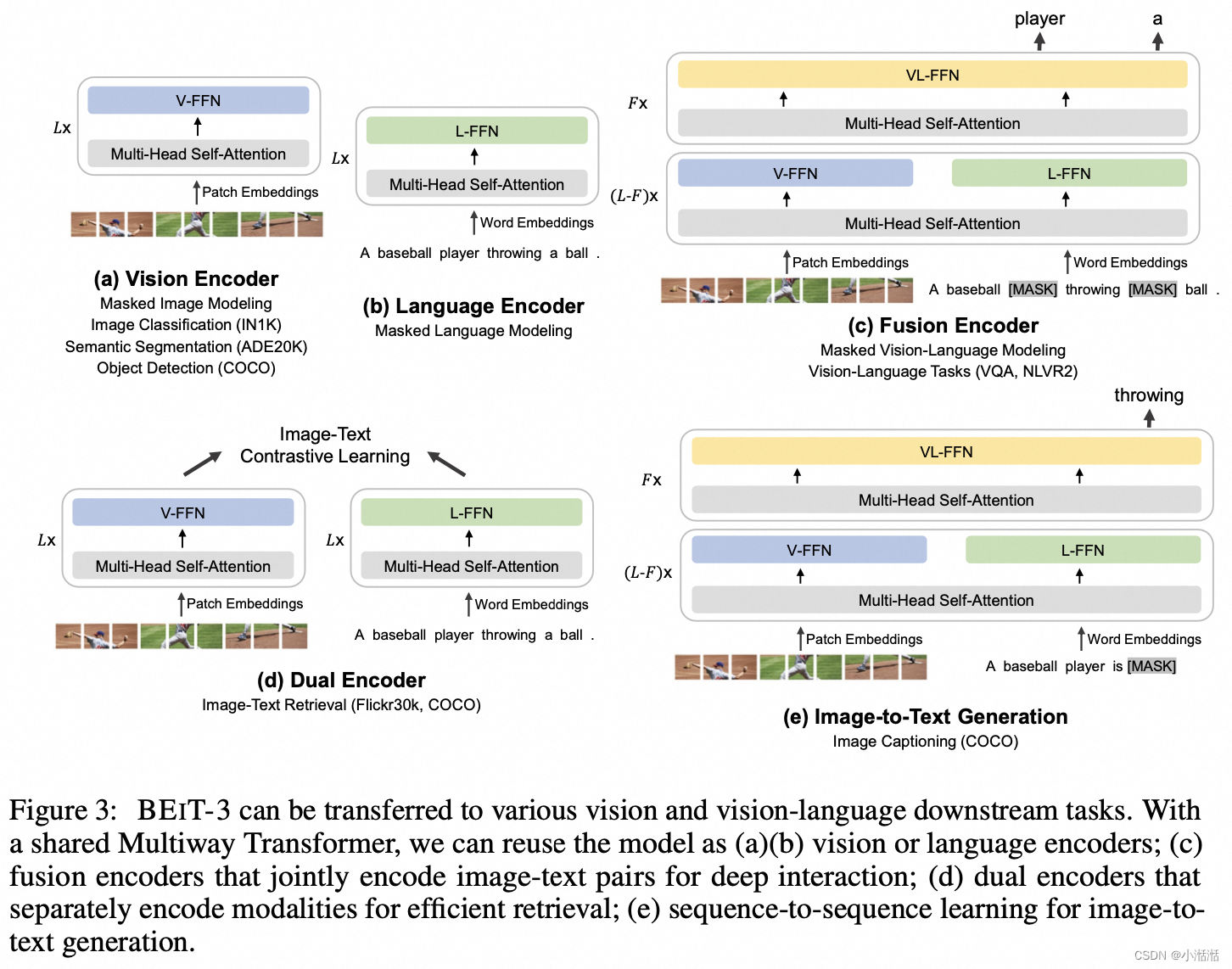
- 图 3(a) 所示是 BEIT-3 模型转换为视觉编码器,适配任务:图像分类,目标检测,语义分割 (ImageNet-1K, COCO, ADE20K)
- 图 3(b) 所示是 BEIT-3 模型转换为文本编码器。
- 图 3© 所示是单塔结构,联合编码图像-文本对以进行深度交互的融合编码器,适配任务:多模态理解任务 (VQA, NLVR2)。
- 图 3(d) 所示是双塔结构,对每个模态进行单独编码以求高效的图文检索,适配任务:图文检索任务 (Flickr30k, COCO)。
- 图 3(e) 所示是单塔结构,用于图像到文本生成任务,适配任务:多模态生成任务 (COCO)。
使用一组(特定领域)模态专家有助于模型捕获更多的模态特定信息
共享的自注意力模块学习不同模态之间的对齐,并且能够为多模态(如视觉-语言)任务实现深度融合
应用场景
多模态视觉-文本任务:
- 视觉问答任务 (Visual Question Answering, VQA)
- 视觉推理任务 (Visual Reasoning) ,即 NLVR2
- 图像字幕任务 (Image Captioning)
- 图文检索任务 (Image-Text Retrieval)
单模态视觉任务:
当 BEIT-3 用作视觉编码器时,有效参数的数量与 ViT-giant 相当,即大约 1B 参数
- 目标检测和实例分割
- 语义分割
- 图像分类 => 不是在预训练好的 Backbone 之后加一个分类层之后做微调,将任务制定为图像到文本检索任务,类似于 CLIP 的做法,zero-shot
VindLU
在我们的优化中用到了这里面的 视频时序编码,其实是视频抽帧,多帧输入
VidL - Video-and-Language
本文没有提出另一个新的 VidL 模型,而是进行了一项彻底的实证研究,解开 VidL 模型设计因素中最重要的因素 => 构建一个高性能VidL框架需要哪些关键步骤?
最终发现下列因素影响最大:
- temporal modeling 时序建模设计
- video-to-text multimodal fusion 视频文本多模型融合方案
- masked modeling objectives mask 建模
- joint training on images and videos 联合训练
video 是以帧的形式输入的
paper
VindLU: A Recipe for Effective Video-and-Language Pretraining
代码
参考文献
模型细节
mPLUG-Owl
给模型生成 caption 的,有语言模型
论文
- mPLUG-Owl: Modularization Empowers Large Language Models with Multimodality
- mPLUG-Owl2: Revolutionizing Multi-modal Large Language Model with Modality Collaboration
代码
参考文献
EVA-CLIP
论文
EVA-CLIP-18B: Scaling CLIP to 18 Billion Parameters
代码
参考文献
音频—图像多模态
音频: 包含语音、歌声、自然音效(狗叫、雷声等)、music 等,一般音频模型是指对音频分类(如果有人在说话,只描述男人/女人/小孩在说话,不描述具体说话的内容),音频生成(自然音效生成,用于视频配自然音效的场景,AIGC 里面比较火),music 生成(MD5 生成曲谱,本质是个 NLP 任务,可以作为歌声合成的背景音乐)
speech 类: 涉及到人声的
- 识别类:如 ASR (语音识别),声纹识别(与人脸识别类似,一般用的 backbone 和音频分类也比较像),情绪识别(也是分类问题),语音翻译(输入英文语音,输出中文文本,或者直接输出中文语音(对数据要求高))
- 生成类:TTS (语音合成,输入文本,输出音频),歌声合成(复杂的语音合成,需要输入韵律),声音克隆(只克隆音色,不克隆情感,输入文本和音色特征,输出音频),声音转换(可以克隆语速,情感,抖音用户的声音变成猴哥,输入输出都是音频),歌声转换(复杂的声音转换,AI 孙燕姿)
增强类: 音频 3A 算法,声学回声消除(AEC)、背景噪声抑制(ANS)、自动增益控制(AGC),主要就是降噪,是 ASR 的前处理,一般比较小的语音团队不会有这类配置
语音圈子比较小,一般音频类任务也会扔给 speech 的同学做
论文标题都是 MAE,看看有没有对比 loss,因为针对我们的任务,检索对齐比分类更重要
音频—图像多模态似乎无法做 zero-shot 的音频分类任务,因为音频分类在文本—图像里面是通过把标签文本变成 caption 做检索任务实现的
参考文献
OmniVec 比 BEATs 在 esc50 上好,但是没有代码
Audiovisual Masked Autoencoders 谷歌
BEATs
纯音频分类模型,mAP 50.9% 是 10 个模型混合的结果
目前应用在声音劣质机审(更新了权重)里面,和 BEiT-3 v2 (没有更新权重)里面
之前的音频 SSL 模型都是用重建 loss,重建 loss 表征低阶特征,忽略高阶音频语义,离散标签可能更好
论文
BEATs: Audio Pre-Training with Acoustic Tokenizers
代码
- microsoft/unilm/beats
只有推理代码没有训练代码,但是可以尝试用 audio_quality 的 trainer 和 dataloader
模型细节
backbone 是 vanilla ViT model
监督音频预训练
- 域外监督 PSLA (ImageNet)
- 域内监督 AudioSet
Whisper AT
纯音频的任务
https://github.com/YuanGongND/whisper-at
AudioMAE
是从音频谱图进行自监督学习,是 MAE 的一个扩展,并不是一个音频-图像多模态任务,应该还算是一个纯音频任务,指标上没有 BEATs 好
和 MDM 的区别是,encoder 仅仅输入未被 mask 的部分,decoder 再对 mask 进行重建,MAE 实现了特征提取和内容重建的解耦
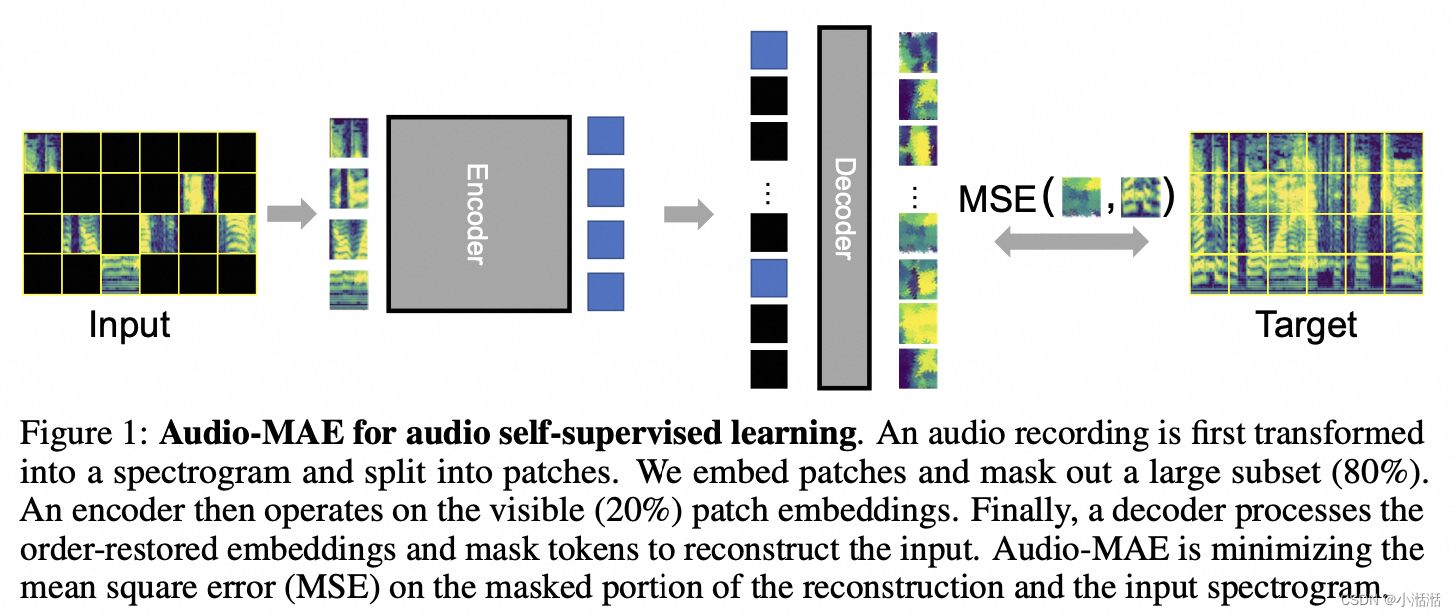
论文
Masked Autoencoders that Listen
facebook
代码
- facebookresearch/AudioMAE pytorch 的,有预训练和 finetune 代码
AV-MAE (代码是 JAX 的) ❎❎❎
只用到了 Mask loss,没有用到对比 loss
这个是音频-图像多模态的
Audiovisual Masked Autoencoders (AV-MAE) pretrains models on video and audio data jointly, and shows improvements in both unimodal and multimodal downstream tasks.
论文中也提到了 CAV-MAE
对预训练模型的 inference 是得到 encoder 的输出 emb
对 fine-tune 模型的 inference 是得到 AudioSet + VGGSound 的所有类别的分类
论文
Audiovisual Masked Autoencoders
谷歌的
代码
- google-research/scenic/projects/av_mae
有预训练和 fine-tune 步骤,代码是 JAX 的❎❎❎
特点
- 只用了 mask loss
- 不像 CAV-MAE 那样用了在 ImageNe
CAV-MAE ✅
MAE 比 BEiT 更先进,实现了特征提取和内容重建的解耦,如何看待何恺明最新一作论文Masked Autoencoders?
ICLR 2023 作者是 MIT 的,代码是 pytorch 的,作者还是 AST、PSLA 等工作的作者
AudioSet-2M 上纯 Audio 的任务没有 Audio MAE 好(Audio MAE 是纯音频任务)
融合了对比 loss 和 MDM 掩码 loss,作者认为两者是互补的
只使用 4 个 GPU 进行预训练和微调
论文
Contrastive Audio-Visual Masked Autoencoder
代码
文档写的很多,有预训练和 fine-tune 步骤
如果对单模态 fine-tune, inference 时候也是单模态,本文 单 Audio 的 AS-2M mAP 是 46.6, 比 BEATSiter3+ 的 48.6 差,如果想用 AV 51.8,可能需要输入两个模态
https://github.com/YuanGongND/cav-mae/issues/14#issuecomment-1685761762
Again, if you are only interested in audio tagging, you could start
with something simpler, e.g.,
https://huggingface.co/spaces/yuangongfdu/whisper-at.The CAV-MAE is mainly for multi-modal applications, though it does
have strong audio tagging performance.
模型细节
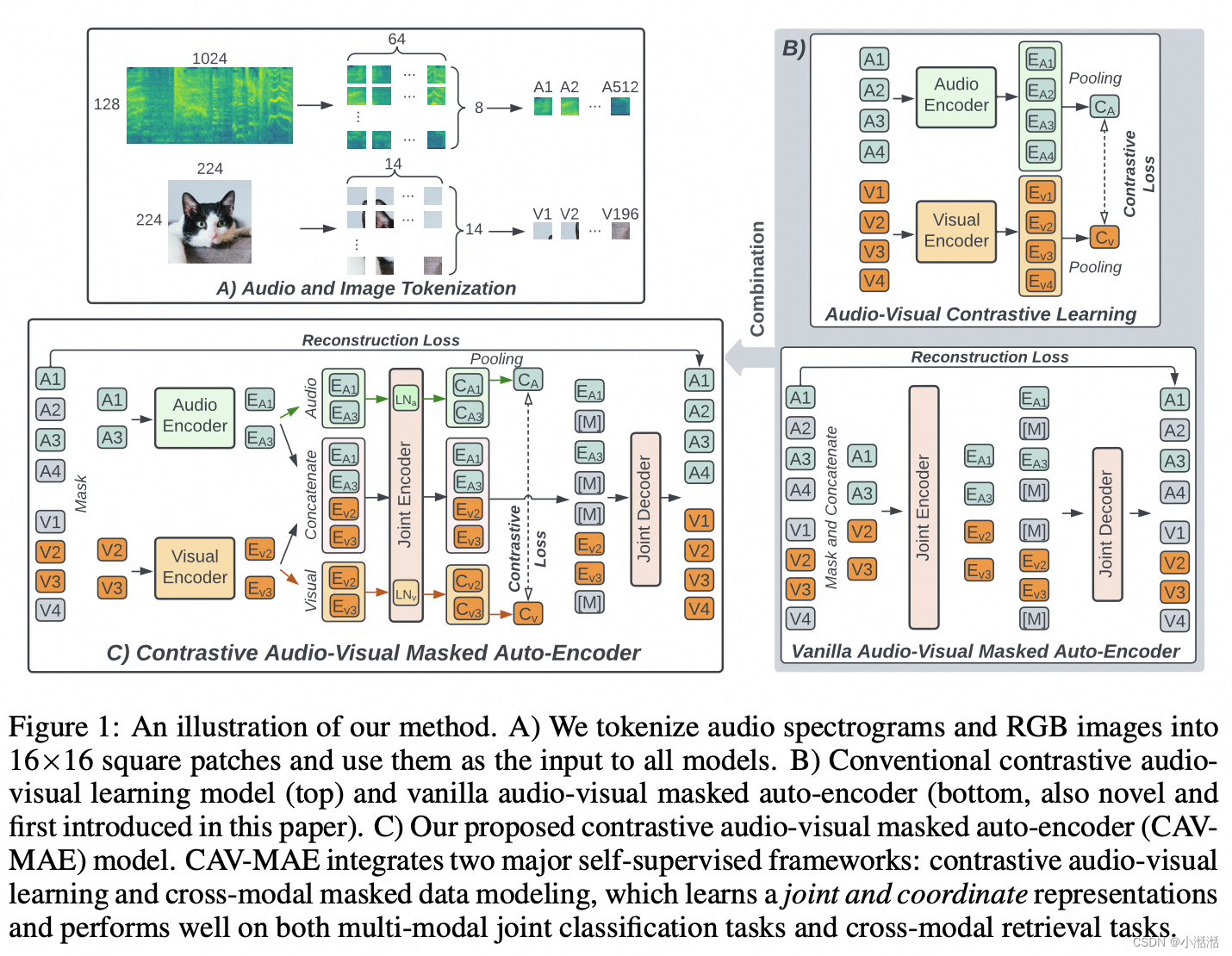
- 数据集:AudioSet(有对应的视频)和 VGG Sound,10s 中均匀采样 10 帧,帧聚合策略
- 音频编码器: AST
- 图像编码器:ViT
- 使用在 ImageNet 预训练权重初始化所有模型的权重,使用了原始视觉 MAE He等人(2022年)的权重,只使用了自监督预训练权重(即没有使用微调后的权重)
- encoder 是 12 层 transformer (11 + 1),decoder 是 8 层 transformer
图像输入并没有考虑 BEiT 那种离散形式,只是用了 patch 作为输入
训练时,随机选一个(所以本质在训练的时候只需要一张图片,所以可以处理音频-图像问题)
预测时,多个帧的预测结果进行平均,代价是不考虑帧相关性
使用 224 × 224 的固定大小
音频输入也没有用到离散语音 token,是把 mel 频谱当做一个图像处理,使用 10s 的固定长度
推理时不用 decoder,只用 encoders,我们可以使用单模态流输出和多模态流输出的总和,或者仅使用多模态流输出进行微调。在我们的实验中,它们的表现相似。
预训练的时候只用 AudioSet-2M
MAViL
facebook 的的,也是用了 mask loss 和 对比 loss,但是代码没有放出来
MAViL: Masked Audio-Video Learners
facebookresearch/MAViL 只有占位代码
VGGSound(数据集)
VGGSound: 大型多模态单标签音频数据集
音频,图像,音频类别标签(AudioSet 的子集)
音频—文本多模态
FSD50K: An Open Dataset of Human-Labeled Sound Events
检索任务:
✅谁在后面谁是输入
- Audio-Text retrieval takes a natural language query to retrieve relevant audio files in a database.
- Text- Audio retrieval takes an audio file as a query to retrieve relevant natural language descriptions.
Microsoft / CLAP
LTU-AS 在零样本 GTZAN 音乐类型分类任务中的准确率几乎是 CLAP的两倍
和 CLIP 一样并不属于自监督,因为仍然需要成对的数据
SSL 训练时候是自监督的,下游任务也是受监督的,只能在固定类别里面预测
Wav2Clip 和 AudioClip 从 CLIP 中提取学习,并使用来自 AudioSet 的音频和❗️类标签❗️而不是音频和自然语言进行训练 -> 使用自然语言应该更加灵活和泛化
论文
CLAP: Learning Audio Concepts From Natural Language Supervision
ICASSP 2023
Audio retrieval with wavtext5k and CLAP training 也是 CLAP 同一个团队,估计就是代码里面说的 2023 版本的权重,这篇文章应该是 2022 版本的权重
- 介绍了个数据集 WavText5K,提供了下载的代码
- text encoder 用 RoBERTa
- 也介绍了最好的 audio encoder 是 D-CNN+HTSAT
代码
- microsoft/CLAP
❗️❗️❗️只有推理代码没有训练代码,issue 里面也说不会很快放出 finetune 代码 ❗️❗️ - 参考文章 Audio concepts from language
代码里面默认用的是 2023 版的模型,没有考虑 finetune 还是预训练,应该默认是预训练的
模型细节
- 音频编码器:
- 2022 版, PANNS 里面的 CNN14,80.8 million parameters(0.08B),AudioSet 上预训练好的
- 2023 版本,PANNS CNN14 + HTSAT(Transformer 结构),考虑到 HTSAT 的输入长度有限但是更长的音频可能是有益的,所以用两者相加的方式
- 文本编码器:
- 2022 版,BERT base,使用 HuggingFace 实现的 BERT base uncased,110 million parameter(0.11B)
- 2023 版,RoBERTa
- 2022 版整体模型不到 0.2B,存储大小应该是 0.8G,代码里面的权重有 2G+,估计是存了其他东西(比如梯度),2023 版权重文件就是 600M+
- 2023 版论文只给出了 retrieval 任务的指标
音频随机剪辑或者 padding 到 5s
❗️❗️❗️❗️❗️训练数据中加入 AudioSet 使得结果变差,在 AudioSet 中,YouTube 的标题和描述往往不能描述视频片段的声学内容,而是描述整个视频 (这是一个我们业务场景的重要参考)
LAION-AI / CLAP ✅
from 多模态算法讨论群:LAION 这个据说效果不太好,试了下情绪分类,基本都是分错的,bert-vits2 用它做文本语音情绪控制,效果也不太好
Peingi 论文里面有 LAION 和 CLAP 的比较,LAION 的分类结果较好
这个论文里面也有和 CLAP 的比较,也是这个更好
在 ZS 音频分类任务上比微软 CLAP 好
在 retrieval 检索任务上比 CLAP-HTSAT 好
发布了 LAION-Audio-630K 数据集,给了下载链接
论文
Large-scale Contrastive Language-Audio Pretraining with Feature Fusion and Keyword-to-Caption Augmentation
ICASSP 2023
代码
LAION-AI/CLAP
好像有训练代码,star 和 issue 也都比微软的多,放出来的权重文件也更多
❗️ BEATs 论文里面有 Wav2CLIP 和 AudioCLIP 的指标,在 AS-2M 上很差,属于 Out-of-domain Supervised Pre-Training,BEATs 属于 Self-Supervised Pre-Training,PANN 属于 In-domain Supervised Pre-Training
❗️❗️❗️CLAP 论文也提到在 ZS 音频分类任务上比 Wav2CLIP 和 AudioCLIP 好
模型细节
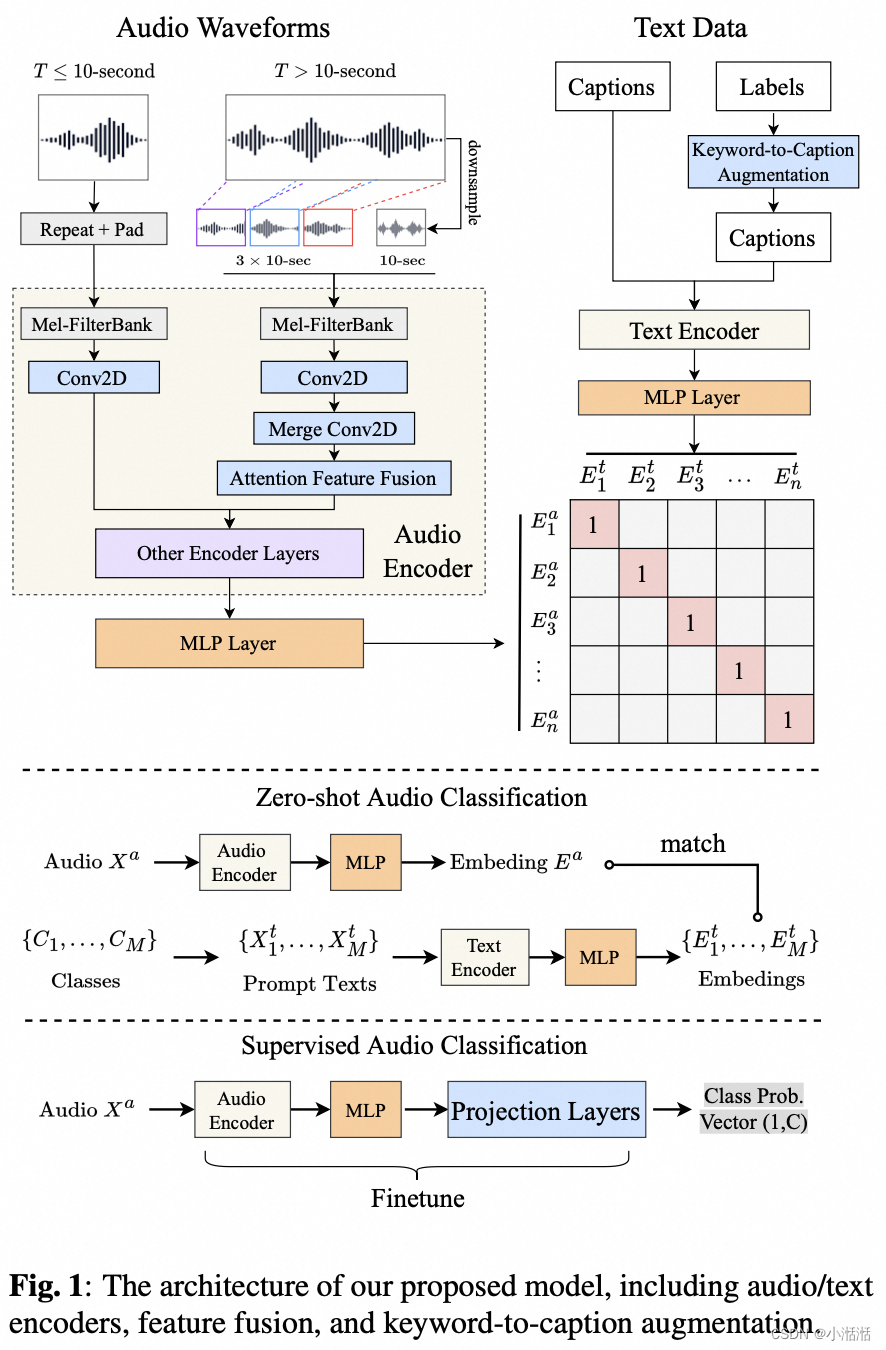
- 音频编码器:
- PANN CNN-based,使用倒数第二层的输出
- HTSAT transformer-based (BEATs 论文的表格能看出来比 PANN 小,效果更好),使用倒数第二层的输出
- 文本编码器:
- CLIP 的 text encoder (改进版的 Transformer)
- BERT
- RoBERTa
We apply both 2- layer MLPs with ReLU activation to map both audio and text outputs into
512 dimensions
[EOS]处 Transformer 末层的输出被视为文本的特征,所以文本嵌入的大小是固定的,与输入长度无关
- 最佳配置:HTSAT + RoBERTa
- 对于变长的 audio 输入根据时长做不同的处理,传统方法在处理长音频时在计算上效率低下,需要切片后求平均等(slice & vote),最终用 a fixed chunk duration d = 10 seconds
- T ≤ d,重复后 padding
- T > d,提取 3 个 10s 的局部输入和 1 个下采样得到的 10s 的全局输入,最终融合成一个
- 最终输入的 shape 是 (T = 1024, F = 64)
- 用预训练好的 T5 语言模型,把某些数据集(如 AudioSet)和合理 label or tag (即 keyword)转成 caption,对输出做一些 de-bias 去偏操作
- loss: 只有对比 loss
音频—文本多模态,增加 LLM
本质是利用 LLM 的文本生成任务
前面的模型做 caption 是构造可能的 caption,再通过检索获取最可能的,这里的 caption 是直接通过 LLM 生成
Pengi
- 封闭式任务,分类和检索
- 开放式任务,音频描述和音频问答 AQA (如 Clotho-aqa)
主要是个 Caption 任务,Pengi 是一款文本生成模型,文本-音频检索任务上,对比模型(CLAP)比生成模型更好,分类任务上 Pengi 更好,Pengi 没有用到对比 loss,所以不太能对齐,但是对我们的任务,感觉检索比分类更重要❗️❗️❗️❗️❗️❗️
CLAP 模型只能支持封闭式任务,如果没有额外的模块和微调,就无法执行开放式任务。
Pengi performs better than CLAP on most audio classification tasks, and can also outperform the literature
是 Audio Language Model (ALM) ,CLIP 就属于 视觉语言模型(VLM)
Pengi 和 CLAP 是 Qwen-Audio (生成式的,因为有大语言模型) 的一个 baseline,Pengi 以 CLAP 为 baseline,Pengi 和 CLAP 都是微软同一个团队的
自监督和无监督都需要微调步骤
仅做 audio 相关,不包含 ASR 相关任务
论文
Pengi: An Audio Language Model for Audio Tasks
微软的 NeurIPS 2023
代码
也是在 issue 中说没有放训练代码的计划
模型细节
利用迁移学习,将所有音频任务框定为文本生成任务
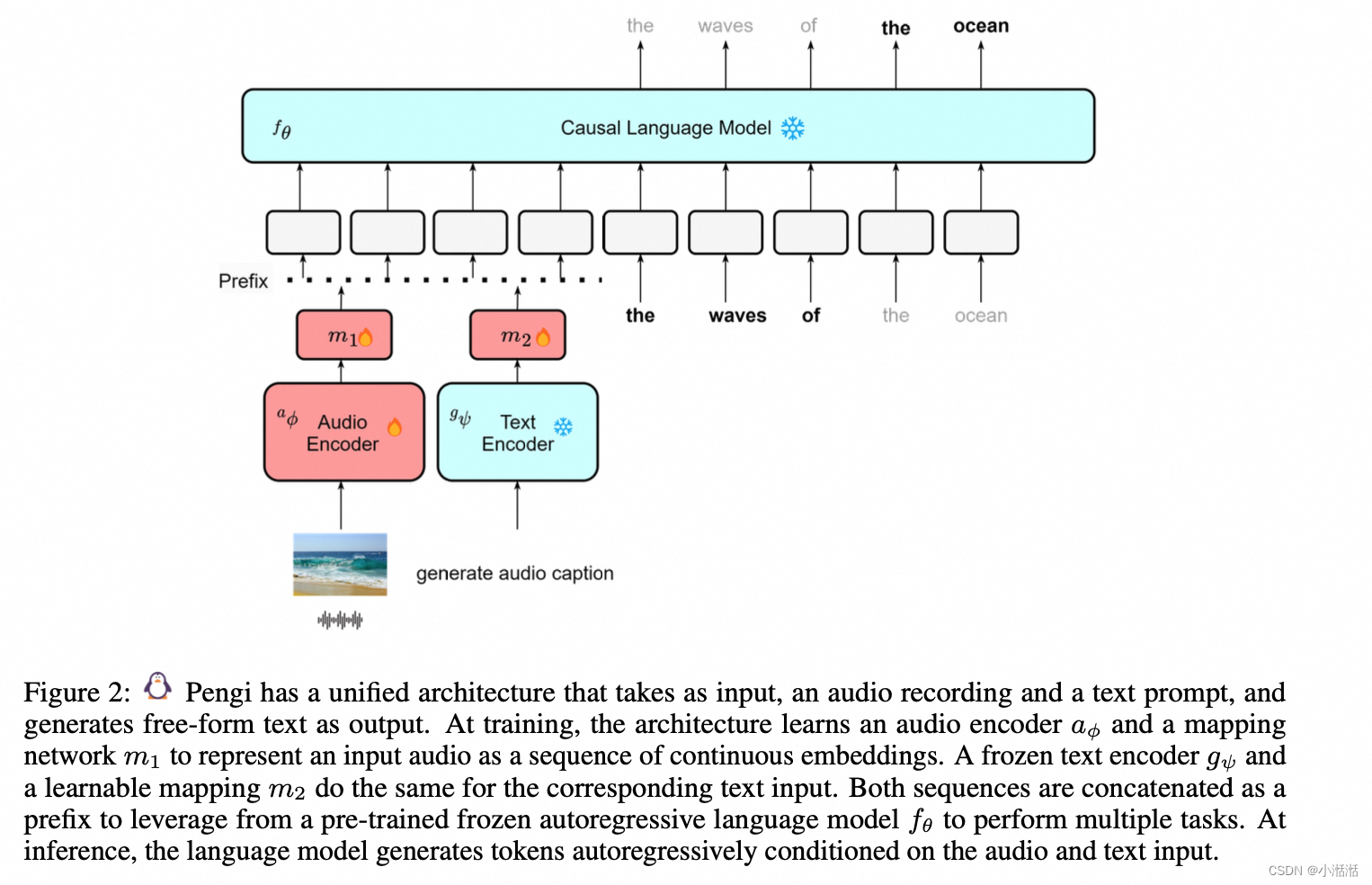
上图蓝色的是冻住的,红色的训练的
之前的模型(BEiTv3等)只是有两个 encoder,这个模型引入了语言模型(Causal Language Model,GPT2-base (124M)),模型 size 会变大(Qwen-Audio 也是有语言模型的)
- 音频编码器: HTSAT-CLAP 里面的音频编码器,HTSAT (ESC-50 上 BEATs 98.1, HTSAT 97.0),音频分类模型
- 文本编码器: 可以任意选择,是冻住的,这里是 CLIP’s text encoder (改进版的 Transformer)
- 映射网络 m1、m2 来自 Clipcap ( Clipcap: Clip prefix for image captioning.)
- Causal Language Model: 在训练和推理的时候都是冻住的(Multimodal few-shot learning with frozen language models),GPT2-base (124M)
先进行了 CLAP 训练,再用到这个模型上
base.pth 里面包含了 gpt2 和 clip-vit-base-patch16,最后一起 load 进来了,所以可以注释掉对应的 “from_pretrained” ❎,因为有的是 AutoModel,需要从 目录中读取对应的模型结构,这里应该是读过一次权重,最后被 base.pth 覆盖掉了
推理需要 ~8G 显存
Qwen-Audio
Pengi 只关注自然声音理解任务,音频编码器 + 文本编码器 + LLM (GPT2)
SALMMON 利用文本编码器和语音编码器提取来自不同音频和文本输入的表示,然后将输入通过 Q-former 风格的注意力机制连接到训练良好的 LLM 以生成响应,有 2 个编码器, beats + whisper + LLM (Vicuna LLM 7B / 13B)
Whisper 仅专注于语音翻译和识别任务
本文集成语音、自然声音、音乐和歌曲,采用单一编码器处理所有音频
使用广泛的音频数据集进行共同训练
Qwen-Audio 多任务预训练,冻结了 LLM 的权重,仅优化音频编码器
Qwen-Audio-Chat 监督式微调,固定音频编码器的权重,在 Qwen-Audio 的基础上,只优化 LLM
也和 SALMONN 比了,但是 AAC 上没比,Figure 1 中比了
论文
Qwen-Audio: Advancing Universal Audio Understanding via Unified Large-Scale Audio-Language Models
代码
caption 任务参考 eval_audio/evaluate_caption.py
'<audio>{}</audio><|startofanalysis|><|unknown|><|caption|><|en|><|notimestamps|><|caption_{}|>'
可以使用 transformers 和 modelscope 库进行推理,modelscope 里面的函数和 transformers 一样
使用 CPU 进行推理,需要约 32GB 内存
默认 GPU 进行推理,需要约 24GB 显存
4卡,每张卡 6G 内存,增加 CUDA_VISIBLE_DEVICES=0 后,0 卡 18G (fp16),V100 上时间都是 2.8s+
cpu 上的时间是 31s,且 htop (DSW 上是 44 卡) 都打满了
cpu 12核是 19s
load checkpoint 都需要很长时间,10s+
每次的输出都不一样,固定了 torch.manual_seed(1234) 和 output_style 就一样了
output_style 最终选 clotho,因为示例代码用的就是这个
模型最终选 Qwen-Audio,因为 Qwen-Audio-Chat 的输出不太一样
用复杂的 generate 的输入(示例代码中),和用 README.md 的简单写法不太一样,且可以直接得到文本,没有其他标签(是因为对 output_ids 的处理),推理时间变成了 3.5s
do_sample=True 设置了 seed,每次的结果也一样
333297990498
do_sample = False
A woman is speaking about the benefits of a plant while a man plays the guitar in the background.
do_sample = True
A woman is giving a speech about a plant.
taobao_100
用 batch 推理的时候 do_sample=False 会有 repeat
do_sample = False
merged_responses: [
"here's a fish tank with a fish in it and a fish food dispenser and a fish food dispenser and a fish food dispenser and a fish food dispenser",
'music is playing',
'a woman speaks, and music plays, and the woman speaks again, and the woman speaks again, and the woman speaks again, and the woman speaks',
'a woman is speaking while music is playing',
'A woman speaks, and music plays, as the woman speaks again, and the music continues.',
'music is playing',
'A man speaks, music plays, and a child sings.',
'music is playing and a man is singing',
"many people may not know that the couple's bed is not allowed to sleep with others.",
'people are singing and speaking, and a woman is speaking']
do_sample = True
merged_responses: [
'this is a fairly small fish tank with one small fish and a tiny blue fish and it is working nicely the room is silent with music in the background',
'A guitar is playing jazz music as a drummer plays with the cymbals, and background noise can be heard.',
'a woman speaks, followed by a woman singing to the rhythm of a speech synthesizer, and another woman speaking',
'a woman speaks while playing music',
'A woman speaks and music plays as the woman speaks.',
'the music plays in the background as the piano is being played',
'A man speaks and sings, followed by music and children singing.',
'music and people are singing and speaking in a variety of languages',
'people are talking and music is playing in the background.',
'People are singing, and then two men are speaking.']
因为是生成式模型,所有有部分的输出不一定是 caption,不太稳。。如 [30]
TODO:
- 多跑几条
- 多条 caption,需要组成 AudioDataset, bs 需要考虑 gpu 显存的上限,但是最后在 mvap 里面还是只能用单条
模型细节
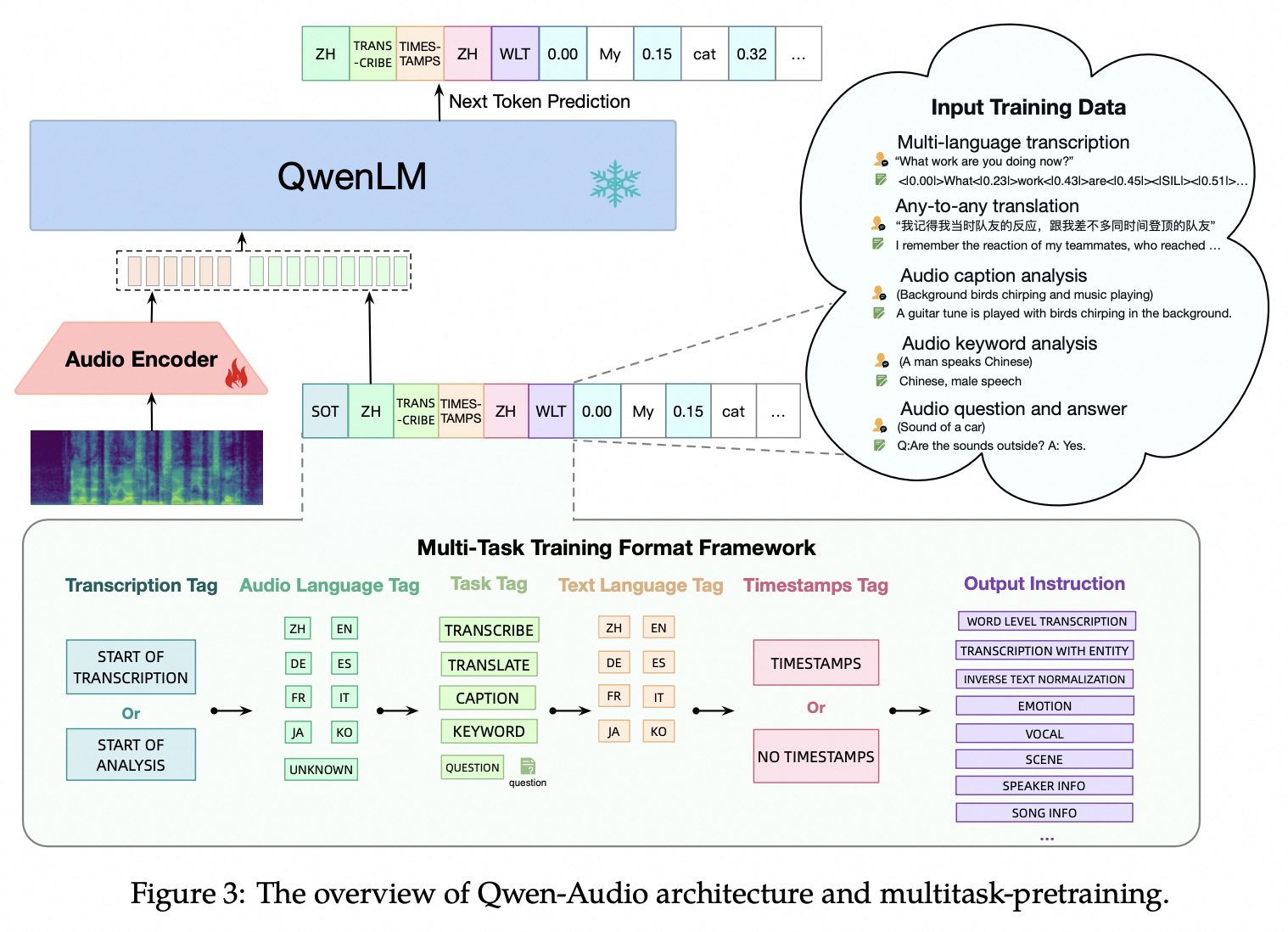
- 音频编码器: Whisper-large-v2 初始化权重, Whisper 本身是语音识别模型
- 大语言模型: Qwen-7B 初始化权重,是一个 32 层的 Transformer 解码器模型,隐藏层大小为4096,总共拥有 77 亿参数
- SpecAugment 作为数据增强
注意 Audio caption 和 Audio keyword
标签:
- 转录标签
- 音频语言标签
- 任务标签:<|transcribe|>、<|translate|>、<|caption|>、<|analysis|> 以及 <|question-answer|>
- 文本语言标签:指定输出文本序列的语言 (audio caption 是不是也能输出中文)
- 时间戳标签
- 输出指导:最后,我们提供输出指导以进一步指定任务和不同子任务的期望格式,之后文本输出开始
效果
SALMONN (太大了)❎❎❎
这个是 7B / 13B 太大了,也是有大语言模型的生成式模型
用了 QFormer 混合了 whisper 和 beats 的输出,这块和 InterVideo 有点像
whisper 和 beats 都是冻结的,LLM 也是冻结的,加了个 LoRA
各个模型都要分别下载下来
论文
SALMONN: Towards Generic Hearing Abilities for Large Language Models
代码
加载速度太慢了(默认使用 cpu, 6min 才加载的 shards 1/2 的一半)
4 gpu LLAMA 14s,每个 GPU 内存占用 4g
model.safetensors 一直 load 不了,换成 pytorch_model.bin 可以 load 了
加载好模型后,4 个 GPU 每个 GPU 是 6G 显存
模型细节
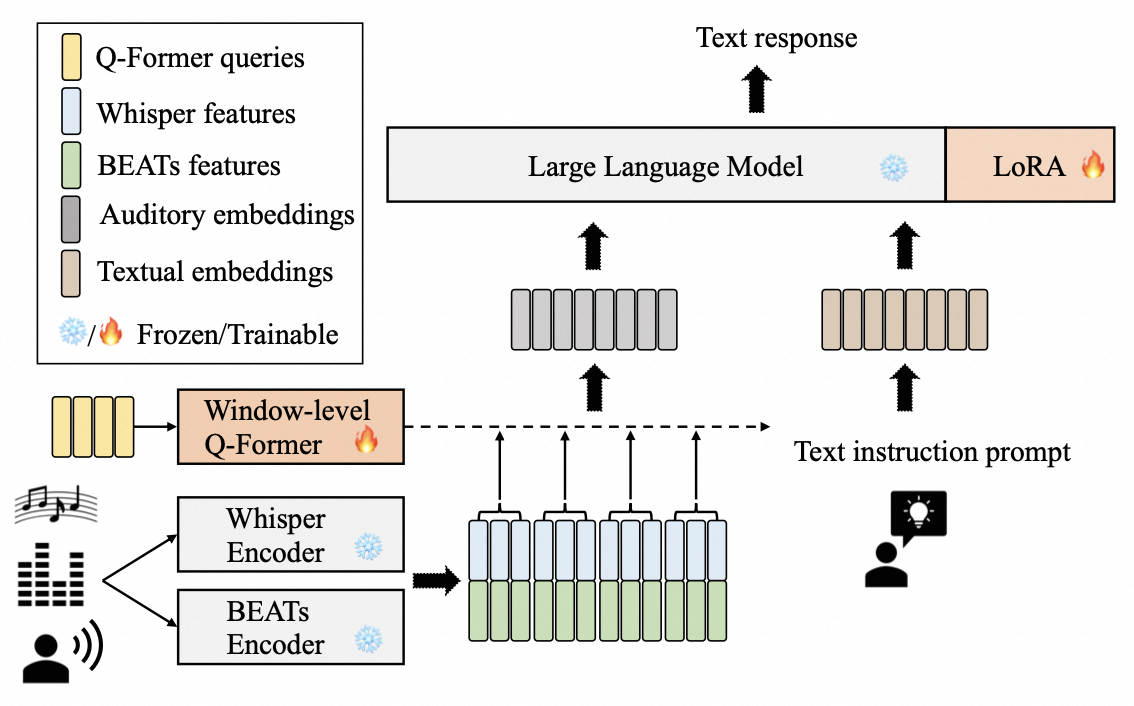
- LLM Vicuna LLM
- beats (音频分类)
- whisper (语音识别)
效果
让其生成 audio caption, 大部分情况下无法生成
能生成的情况下,由于用了 whisper,可以描述语音的内容(如,第五条)
prompt = ‘Please describe the audio.’
prompt = ‘Please write down what your hear in the audio.’
则全都无法生成
图像—文本—音频多模态
LanguageBind > ImageBind > AudioCLIP ?
VALOR❓
三个模态数据集和预训练模型
论文
VALOR: Vision-Audio-Language Omni-Perception Pretraining Model and Dataset
中国科学院大学人工智能学院
代码
有训练代码
AudioCLIP
可能是 ImageBind 的 baseline❎
在纯音频任务上的效果不那么好,关键是三个模态
论文
AudioCLIP: Extending CLIP to Image, Text and Audio
代码
ImageBind
baseline 是 AudioCLIP (Zero-shot text to audio 检索和分类) 和 AudioMAE (音频分类)
6 种模态混合
Audio 分类任务作者比较的模型是:
- Self-supervised AudioMAE 模型。
- 用于音频分类任务的微调 supervised AudioMAE 模型。
不同模态和 image 对齐
ImageBind 在 ESC 数据集上没有 AudioCLIP 好,因为后者用了监督数据
ImageBind 是一个学习一个联合特征嵌入 (Joint Embedding) 的方法,这个联合嵌入可以同时编码 images, text, audio, depth, thermal, 和 IMU 数据。而且,在训练这个联合嵌入的时候,不需要所有模态彼此同时出现的数据集,比如不需要配对的 image + text + audio + depth + IMU 数据。而是只需要与 image/video 配对的数据即可,比如,image + text,image + audio 这样的数据集。
论文
ImageBind: One Embedding Space To Bind Them All
CVPR 2023
代码
facebook 、pytorch
没有训练代码,之前实习生好像在业务数据上跑过测试
参考文献
- 多模态超详细解读 (十一):ImageBind:图像配对数据绑定6种模态
- ImageBind: 表征大一统?也许还有一段距离
- Meta刚发布了ImageBind,一个跨六种模态的整体化人工智能模型,这是对它的详细分析
- ImageBind跨越6种模态,统一向量表征
- 【论文极速读】IMAGEBIND —— 通过图片作为桥梁桥联多模态语义
- 多模态学习8—理解Bind系列网络
模型细节
不同模态的 backbone:
- 图像模态 ViT,来自于已经训练好的 ViT-H
- 视频转化为 2 帧图像,ViT
- 音频进行采样转化为 2D 图像,ViT
- 热力图、深度图转化为1维图像,同样使用 ViT 处理
- IMU,transformer
- 文本,transformer,并使用 CLIP 的参数进行初始化,于预训练的 OpenCLIP
每种模态的encoder后面,采用单独的linear层进行映射,随后进行归一化norm,变成统一维度大小的embedding。最后将这个embedding放入到InfoNCE中进行学习
应用场景
- 跨模态检索:快速对齐音频,深度图和文本信息
- 给一个嵌入增加来自不同模态的另一个嵌入可以自然地增加语音信息
- 音频到图像的生成,通过预训练的 DALLE-2 解码器,旨在与 CLIP 的文本嵌入一起工作
LanguageBind
ICLR 2024
在 Audio 上效果优于 ImageBind
似乎采用文本来进行连接,是一种更加自然的方式。这就是LanguageBind的思路
作者构建了一个 10 million 的数据集 VIDAL-10M
论文
代码
有训练代码,数据集好像没有全部开源 DATASETS.md
参考文献
- 超越ImageBind? 北大&腾讯LanguageBind已开源!
- 【论文笔记】LanguageBind: Extending Video-Language Pretraining to N-modality by Language-based Semantic …
- 用语言对齐多模态信息,北大腾讯等提出LanguageBind,刷新多个榜单
- 北大&腾讯打造多模态15边形战士!语言作“纽带”,拳打脚踢各模态,超越Imagebind
模型细节
LanguageBind 总共对齐了 5 种模态,包括:视频、文本、音频、深度、红外图等
LanguageBind 的模型结构和训练目标和 ImageBind 的思路很接近,但是增加了 LoRA 等微调技术等
MACAW-LLM
腾讯
论文
Macaw-LLM: Multi-Modal Language Modeling with Image, Audio, Video, and Text Integration
代码
lyuchenyang/Macaw-LLM
有训练代码
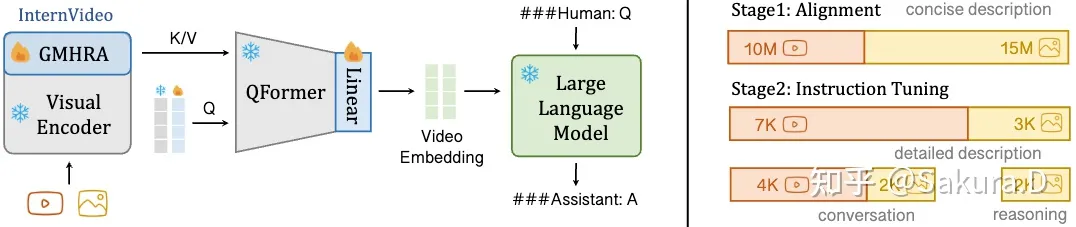
InternVideo2
from xuwen
视频理解
其实是 视频—文本 之间的对齐,视频包含了图像和音频
论文提供了一种标注技术,实现视频文本化
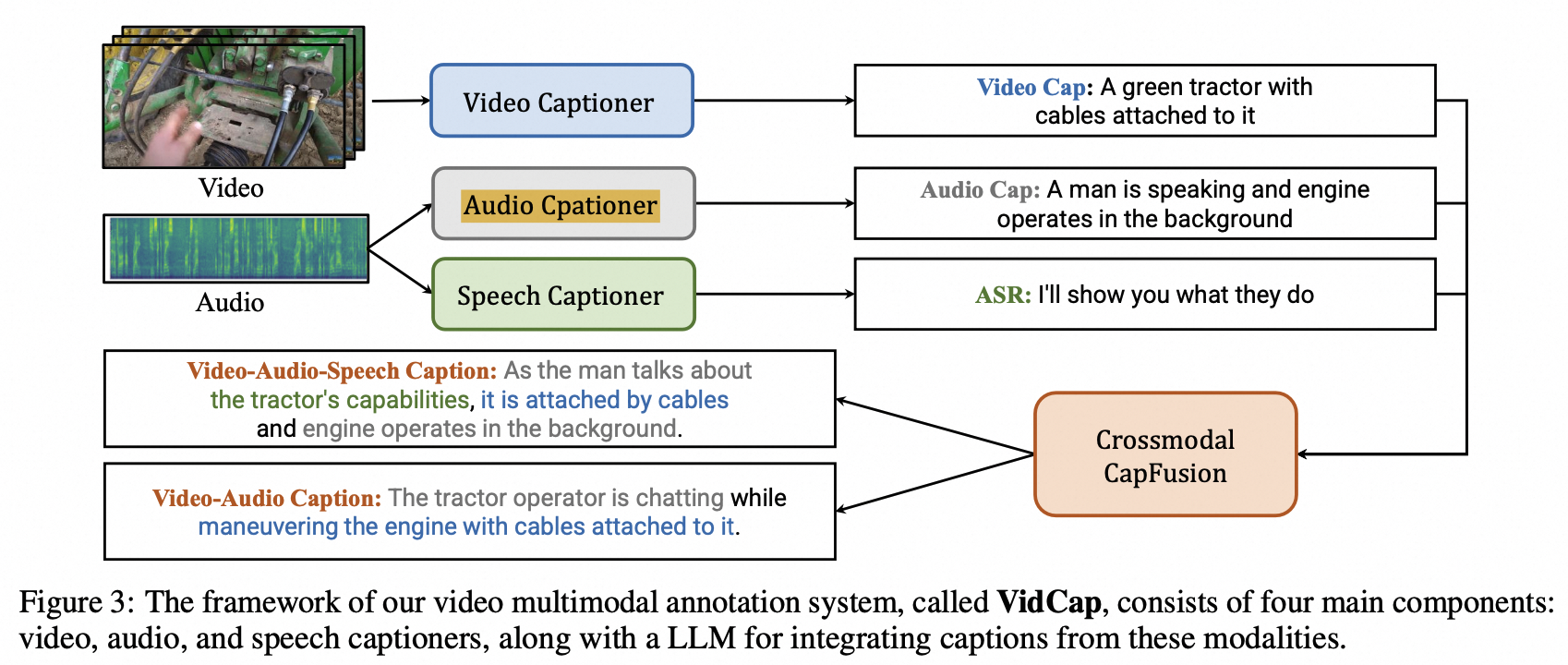
可以参考其中的 VidCap 中的的 audio caption(VideoChat) 加到我们的数据链路中
xuwen: 你看下这个,仿照他那个audio captioner 跑一些audio caption出来看看吧,我理解是 先看一下 他这个数据链路我们能不能复用,如果可以的话,后面对齐的时候直接把音频接进来就好了,不用搞2步对齐了,可以先看下论文: 就是生成数据之后去做各个pair对的对齐,做预训练,其实我看音频那里操作基本都一样10s的clip,梅尔频谱图过beats
xuwen 看起来是想 audio 生成一个 caption,image 生成一个 caption,然后用 LLM 生成融合的 caption
VideoChat 本身是本文同一个团队做的,本文的二作 Kunchang Li 是 VideoChat 的一作
For audio, we craft a audio captioner upon VideoChat [Li et al., 2023d], as we find no open-sourced one. It extracts audio features from inputs by Beats [Chen et al., 2023d]. We learn it by only tuning its Qformer using a combination of the large-scale audio-text corpus WavCaps [Mei et al., 2023] dataset. Details are given in the supplementary material.
VideoChat 是对 Video 做 cap,本文的 Audio captioner 看起来是提取了 BEATs 的特征,finetune 了 Qformer
VideoChat🦜: 基于视频指令数据微调的聊天机器人
用 WavCaps 数据集 finetune 了 VideoChat 的 Qformer(the interface between audio encoder and LLM)
WavCaps 数据集包含大约 40 万带有配对描述的音频片段,可用于多个音频-语言多模态学习任务

约 7567.26 小时的数据
论文
InternVideo2: Scaling Video Foundation Models for Multimodal Video Understanding
代码
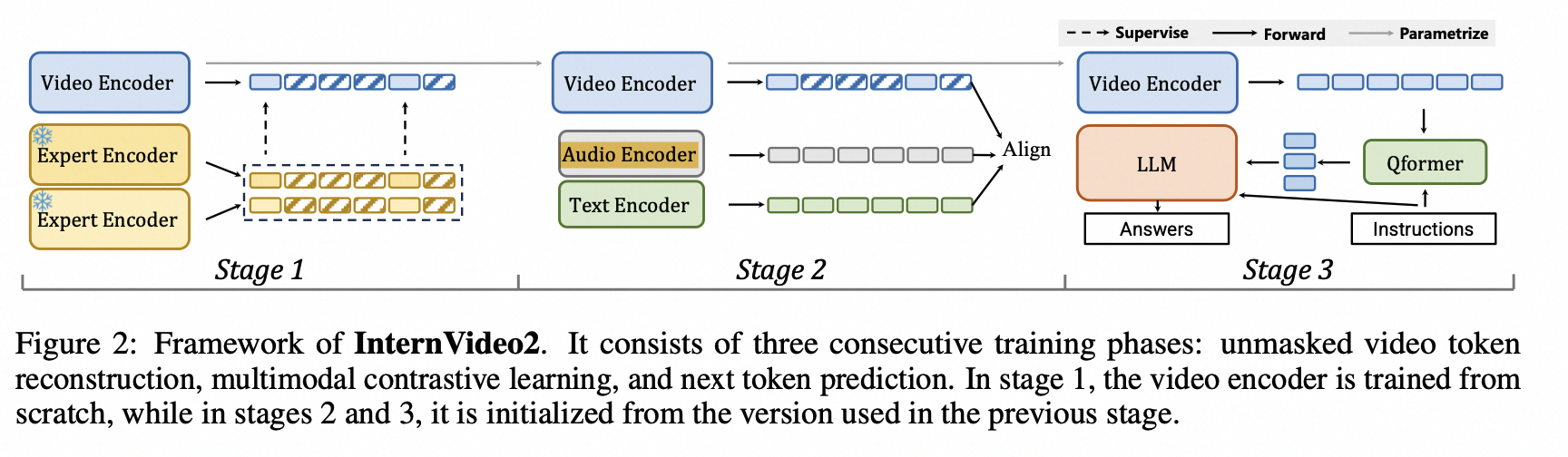
模型细节
三个阶段
- 阶段一:视觉编码器,InternViT 和 VideoMAE-g
- 阶段二:扩展音频和文本编码器,改善了视频与文本之间的对齐,还赋予InternVideo2处理视频-音频任务的能力
- 阶段三:通过下一个 token 预测训练进一步更新了视频编码器,InternVideo2 就是一个视频编码器
dataset:以视频为中心
专注于使用三种模态——音频、视频和语音——重新校准描述与视频的匹配。为此,我们分别为这三种模态生成字幕
三种学习方式:
- mask 重建
- 跨模态对比学习
- next token 预测
提供了一个增强的数据集
视频编码器在 ViT 中引入注意力池化(attention pooling)
stage 1:
利用两个专家模型指导视频编码器进行 mask 的 token 级别重建,采用 InternVL-6B 和 VideoMAEv2-g
stage 2:
利用:
- 视频-音频
- 语音-文本
音频编码器:BEATs
文本和语音编码器:Bert-Large 初始化文本编码器和多模态解码器,使用 Bert-Large 的最初19层作为文本编码器,随后的 5 层配备了交叉关注层,作为多模态解码器
通过文本建立跨模态的对齐和融合
- 冻结了音频编码器,主要侧重于调整视觉和文本特征的一致性
- 冻结了视觉编码器 以实现音频、视觉和文本特征的联合调整
stage 3:
使用 InternVideo2 作为视频编码器,并训练一个视频 BLIP,使其能与开源 LLM 进行交流
仅使用 audio encoder 比加上 speech encoder 要更好
音频任务上音频多模态模型的表现
主要比较
BEATs, Audio-MAE, CAV-MAE, CLAP, Pengi
❗️表示需要有监督 fine-tune
AudioMAE 的训练数据有点麻烦
需要在 AudioSet 上预训练,ESC-50 上 finetune 或者 不 finetune
BEATSiter3+ not only make use of the downstream supervised data during fine-tuning but also in pre-training.
音频-文本 VS. 音频-图像
音频分类任务:
CLAP(Best)is the best performance among our supervised setups、
Pengi(L3) 只训练 3 层 fc 层,其他是冻结的,一般 finetune 的时候可能 encoder 也需要更新权重
| AudioSet-2M (mAP) A | AudioSet-2M (mAP) AV | ESC-50(sv) | ESC-50(zs) | US8K(zs) | FSD50K(zs) | FSD50K(sv) | VGGSound(sv) | |
|---|---|---|---|---|---|---|---|---|
| BEATs iter3+(纯音频) | ❗️48.6 | - | 98.1 | 95.6(iter3) | ||||
| Audio-MAE(local)(纯音频) | 47.3 | - | 97.4 | 94.1 | ||||
| CLAP | - | 96.7 | 82.6 | 73.2 | 30.2 | 58.59 | ||
| Pengi | 94.85(L3) | 91.95 | 71.9 | 46.8 | ||||
| LAION (✅有训练代码) | - | 91.0 | 77.0 | 59.7 | 75.4 | |||
| CAV-MAE Scale+ | 46.6 | 51.2 | - | - | 65.5z(A-V) | |||
| AV-MAE(代码是 tf 的) | 46.6 | 51.8 | - | - |
AAC 任务
AudioCaps
-
SALMONN
METEOR | SPIDEr
25.6 | 47.6 -
Pengi
SPIDEr
0.4667
Clotho
-
Qwen-Audio
CIDEr |SPICE | SPIDEr
0.441 | 0.136 | 0.288 -
Pengi
SPIDEr
0.2709
结论
- 音频-图像多模态, CAV-MAE
- 音频-文本多模态,LAION❓> Pengi > CLAP
- Pengi 在分类任务上表现更好,CLAP 在检索任务上表现更好(from Pengi 论文),因为 Pengi 是生成模型,CLAP 用对比 loss 训练的,我们需要的是对齐,所以检索更重要
- 感觉 CLAP(Best) 比 Pengi(L3) 好,可能 CLAP(Best) 在监督训练里面做了很多设计
- Zero-Shot 任务上,LAION 比 CLAP 好
- 暂时的结论是 音频-文本多模态模型 中, LAION 最好(而且还有训练代码)
- 跨模态的情况下 Audio-MAE (音频-图像) ✅✅ > CLAP (音频-文本),且 Audio-MAE 参数量更小


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









