







hadoop的三种模式
本地模式:数据存储在linux本地
为分布式模式:数据存储在单台hdfs上
完全分布式模式:数据存储在多台hdfs上
本地模式
在hadoop目录下新建aa文件夹,然后新建bb.txt
aa bb cc
dd aa ee
ff gg hh
bb dd ee
然后使用命令计算单词的出现的次数
aa和cc是文件夹的意思,从aa文件夹中读取,写入到cc文件夹中
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar wordcount aa cc
然后进入cc目录,查询part-r-00000计算出来的效果
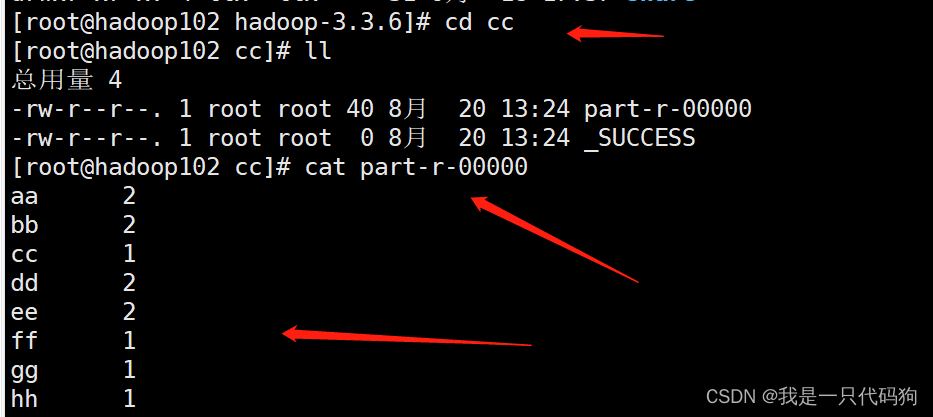 但是要注意,文件夹已经存在的不能再计算,否则会报错
但是要注意,文件夹已经存在的不能再计算,否则会报错

完全分布式模式
把102的jdk和hadoop都拷贝到103和104两台机器上
scp -r jdk1.8.0_231/ root@hadoop103:/opt/module/
scp -r hadoop-3.3.6/ root@hadoop103:/opt/module/
scp -r /etc/profile root@hadoop103:/etc/profilescp -r hadoop-3.3.6/ root@hadoop104:/opt/module/
scp -r jdk1.8.0_231/ root@hadoop104:/opt/module/
scp -r /etc/profile root@hadoop104:/etc/profile
然后再103和104的机器上执行 下面的命令,使得jdk和hadoop生效
source /etc/profile
ssh免密登录
我们在拷贝的时候,每次都需要输入103和104机器的密码,我们可以做ssh免密登录
在102,103,104机器项目根目录生成公钥和私钥,一路回车
ssh-keygen -t rsa
然后在102,103,104机器上执行下面的命令 把公钥拷贝到3台机器上
ssh-copy-id hadoop102
ssh-copy-id hadoop103
ssh-copy-id hadoop104

这时候我们在执行scp命令,就不需要在登录了
集群配置
注意:
NameNode和SecondaryNameNode 不要安装在同一台机器上
ResourceManager也很消耗内存,不要和NameNode,SecondaryNameNode配置在同一台机器上
| hadoop102 | hadoop103 | hadoop104 | |
| hdfs | NameNode,DataNode | DataNode | SecondaryNameNode,DataNode |
| yarn | NodeManager | ResourceManager,NodeManager | NodeManager |
进入/opt/module/hadoop-3.3.6/etc/hadoop目录,修改配置文件
vi core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License athttp://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
--><!-- Put site-specific property overrides in this file. -->
<configuration>
<!-- 指定 NameNode 的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop102:8020</value>
</property>
<!-- 指定 hadoop 数据的存储目录,data目录会自动创建-->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.3.6/data</value>
</property>
</configuration>
vi hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License athttp://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
--><!-- Put site-specific property overrides in this file. -->
<configuration>
<!-- nn web 端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop102:9870</value>
</property>
<!-- 2nn web 端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop104:9868</value>
</property>
</configuration>
vi yarn-site.xml
<?xml version="1.0"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License athttp://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<configuration><!-- Site specific YARN configuration properties -->
<!-- 指定 MR 走 shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定 ResourceManager 的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop103</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CO
NF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAP
RED_HOME</value>
</property>
</configuration>
vi mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License athttp://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
--><!-- Put site-specific property overrides in this file. -->
<configuration>
<!-- 指定 MapReduce 程序运行在 Yarn 上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/opt/module/hadoop-3.3.6</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/opt/module/hadoop-3.3.6</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/opt/module/hadoop-3.3.6</value>
</property>
</configuration>
然后把这4个文件拷贝到103和104机器上
scp core-site.xml root@hadoop103:/opt/module/hadoop-3.3.6/etc/hadoop/
scp core-site.xml root@hadoop104:/opt/module/hadoop-3.3.6/etc/hadoop/
scp hdfs-site.xml root@hadoop103:/opt/module/hadoop-3.3.6/etc/hadoop/
scp hdfs-site.xml root@hadoop104:/opt/module/hadoop-3.3.6/etc/hadoop/
scp yarn-site.xml root@hadoop103:/opt/module/hadoop-3.3.6/etc/hadoop/
scp yarn-site.xml root@hadoop104:/opt/module/hadoop-3.3.6/etc/hadoop/
scp mapred-site.xml root@hadoop103:/opt/module/hadoop-3.3.6/etc/hadoop/
scp mapred-site.xml root@hadoop104:/opt/module/hadoop-3.3.6/etc/hadoop/
然后配置workers ,注意不要有空格
vi workers
hadoop102
hadoop103
hadoop104
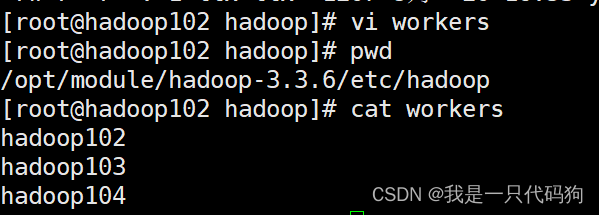
然后把workers拷贝到103和104机器上
scp workers root@hadoop103:/opt/module/hadoop-3.3.6/etc/hadoop/
scp workers root@hadoop104:/opt/module/hadoop-3.3.6/etc/hadoop/
启动集群
如果是集群第一次启动,需要在102机器上格式化NameNode
注意:格式化NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,
集群找不到以往数据
如果集群在运行过程中报错,需要重新格式化NameNode的话,一定要先停止NameNode和DataNode进程,并且要删除所有机器的data和logs目录,然后再进行格式化
在102机器上 格式化namenode
cd /opt/module/hadoop-3.3.6
hdfs namenode -format
在102机器配置hdfs和yarn脚本的root账号访问权限,如果不配,hdfs和yarn启动会报错
cd /opt/module/hadoop-3.3.6/sbin
将start-dfs.sh,stop-dfs.sh两个文件顶部添加以下参数
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
将start-yarn.sh,stop-yarn.sh顶部也需添加以下参数
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
然后拷贝到103和104机器上
scp start-dfs.sh root@hadoop103:/opt/module/hadoop-3.3.6/sbin/
scp start-dfs.sh root@hadoop104:/opt/module/hadoop-3.3.6/sbin/
scp stop-dfs.sh root@hadoop103:/opt/module/hadoop-3.3.6/sbin/
scp stop-dfs.sh root@hadoop104:/opt/module/hadoop-3.3.6/sbin/
scp start-yarn.sh root@hadoop103:/opt/module/hadoop-3.3.6/sbin/
scp start-yarn.sh root@hadoop104:/opt/module/hadoop-3.3.6/sbin/
scp stop-yarn.sh root@hadoop103:/opt/module/hadoop-3.3.6/sbin/
scp stop-yarn.sh root@hadoop104:/opt/module/hadoop-3.3.6/sbin/
在102机器上修改hadoop的java_home的目录
cd /opt/module/hadoop-3.3.6/etc/hadoop
vi hadoop-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_231
然后拷贝到103和104机器上
scp hadoop-env.sh root@hadoop103:/opt/module/hadoop-3.3.6/etc/hadoop/
scp hadoop-env.sh root@hadoop104:/opt/module/hadoop-3.3.6/etc/hadoop/
在102机器上启动hdfs
cd /opt/module/hadoop-3.3.6
./sbin/start-dfs.sh
在102机器上输入jps查看进程,可以看到NameNode和DataNode已经启动
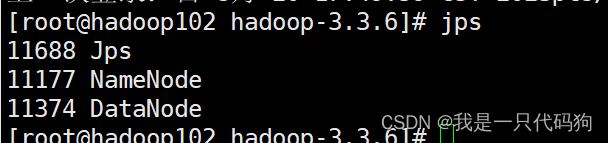
在配置了ResourceManager的103机器上面启动yarn
cd /opt/module/hadoop-3.3.6
./sbin/start-yarn.sh
进入windows电脑的C:\Windows\System32\drivers\etc目录
修改hosts
192.168.10.102 hadoop102
192.168.10.103 hadoop103
192.168.10.104 hadoop104
浏览器查看hdfs的NameNode
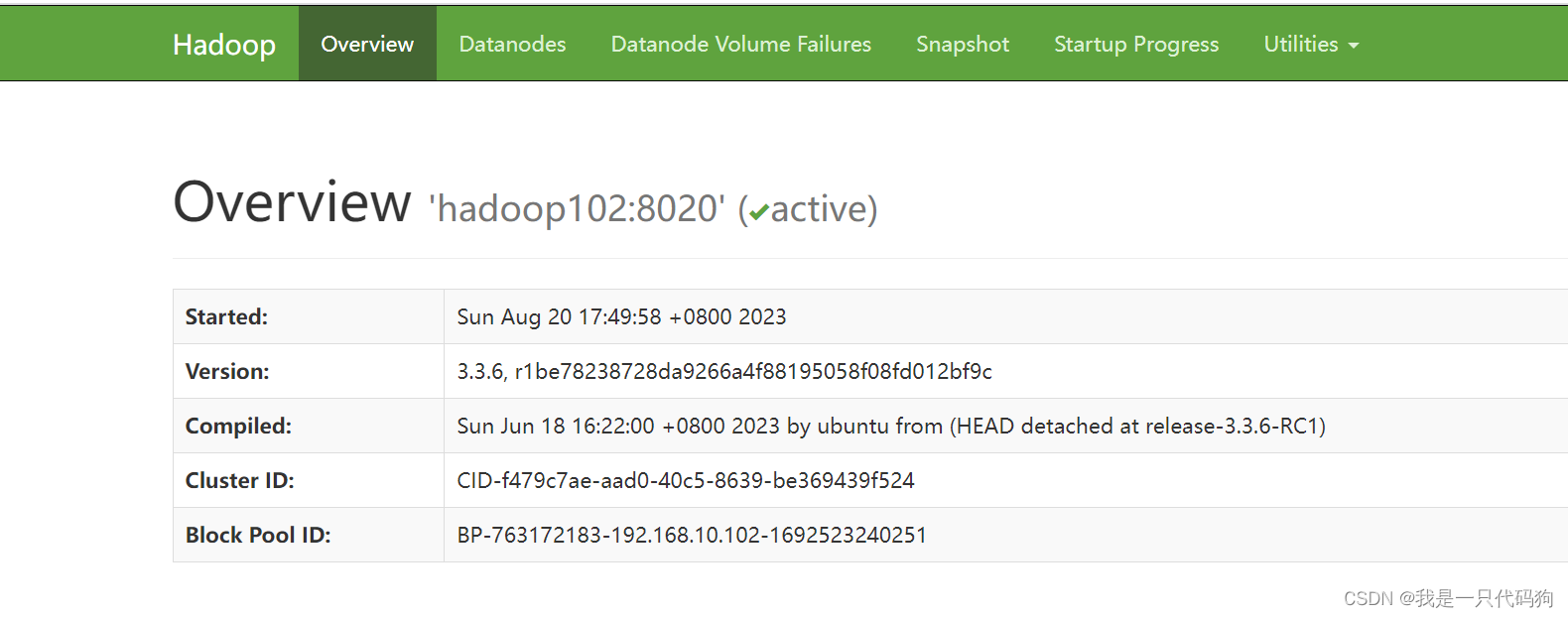
浏览器查询yarn的ResourceManager
上传文件到集群
在102机器上面创建目录,注意ddd目录前面要斜杠
hadoop fs -mkdir /ddd
在102机器下随便创建一个txt文件,上传文件到ddd目录下
hadoop fs -put /opt/888.txt /ddd
选择Utilities 然后选中第一个,就看到我们创建好的ddd目录,点进去
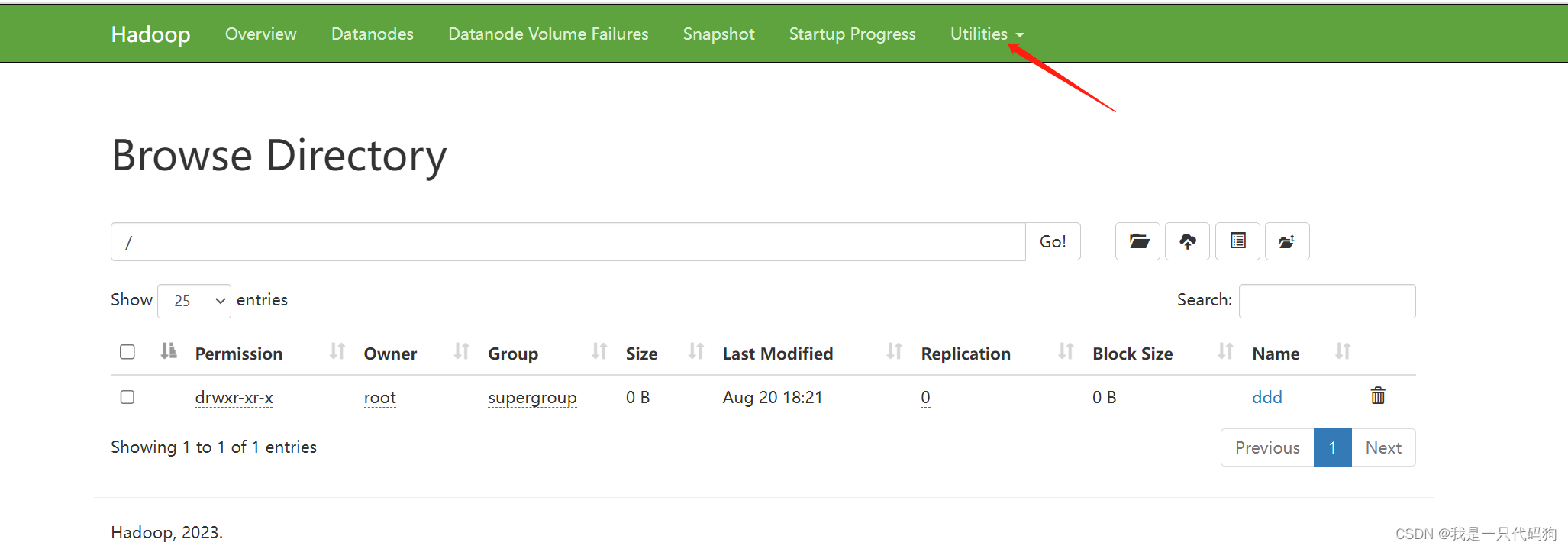
可以看到我们上传的888.txt文件
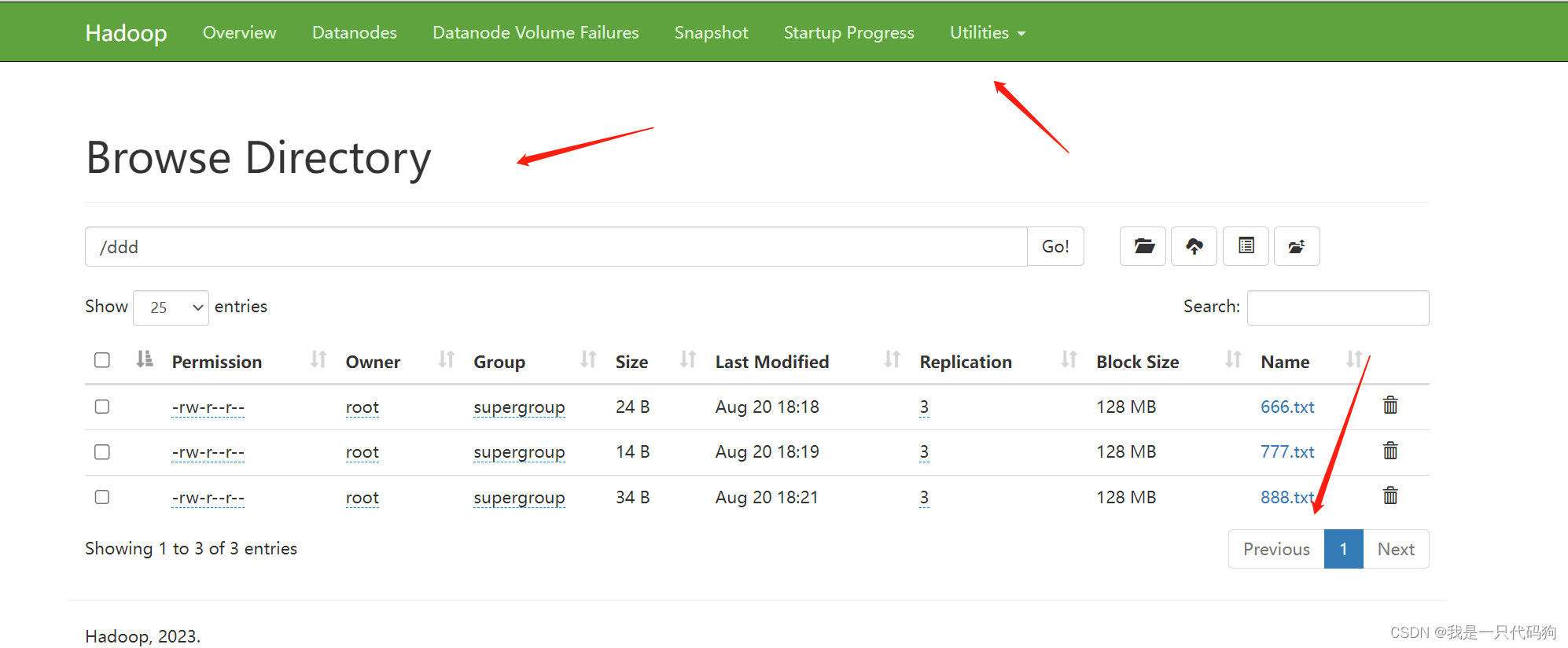
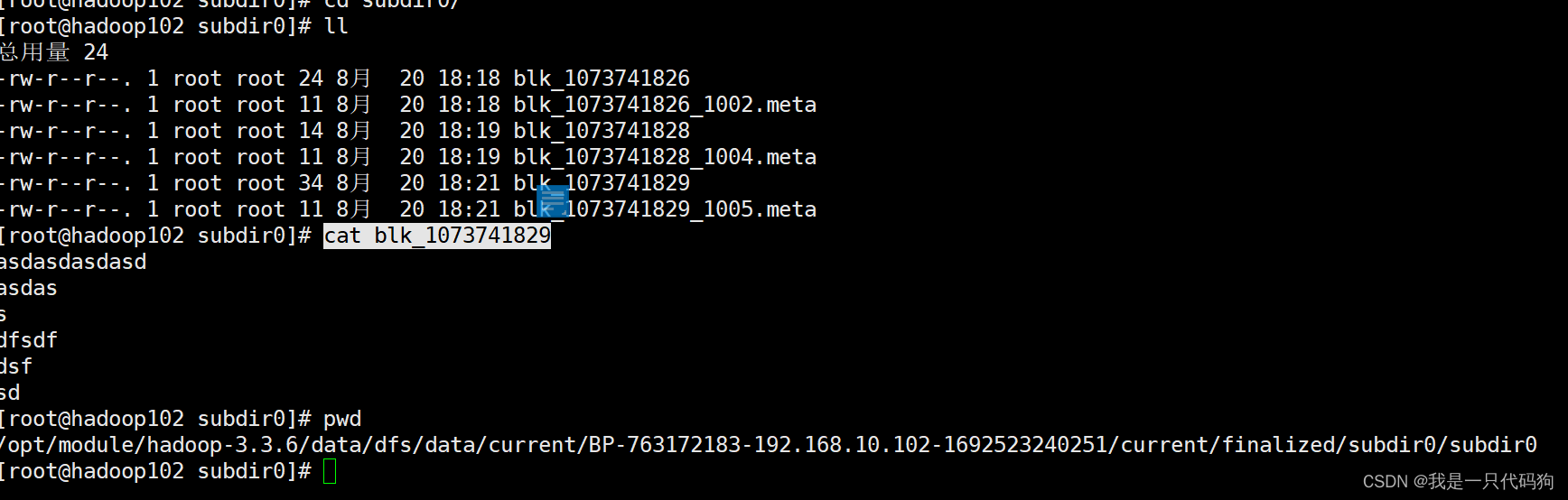
查询hdfs存储路径
cd /opt/module/hadoop-3.3.6/data/dfs/data/current/BP-763172183-192.168.10.102-1692523240251/current/finalized/subdir0/subdir0
cat blk_1073741829
计算hdfs存储好的ddd文件夹下面的文件单词统计信息,生成到ff目录下
hadoop jar /opt/module/hadoop-3.3.6/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar wordcount /ddd /ff
会创建一个ff的目录
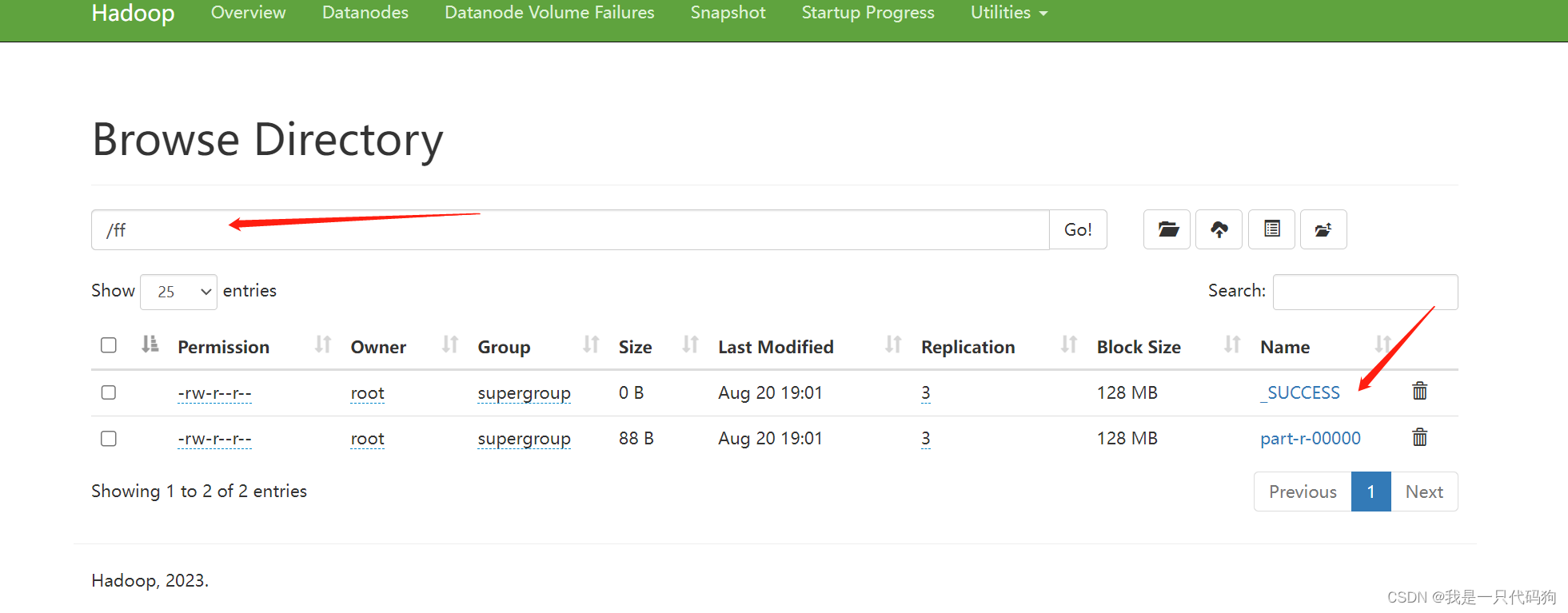
会在这里显示计算的过程
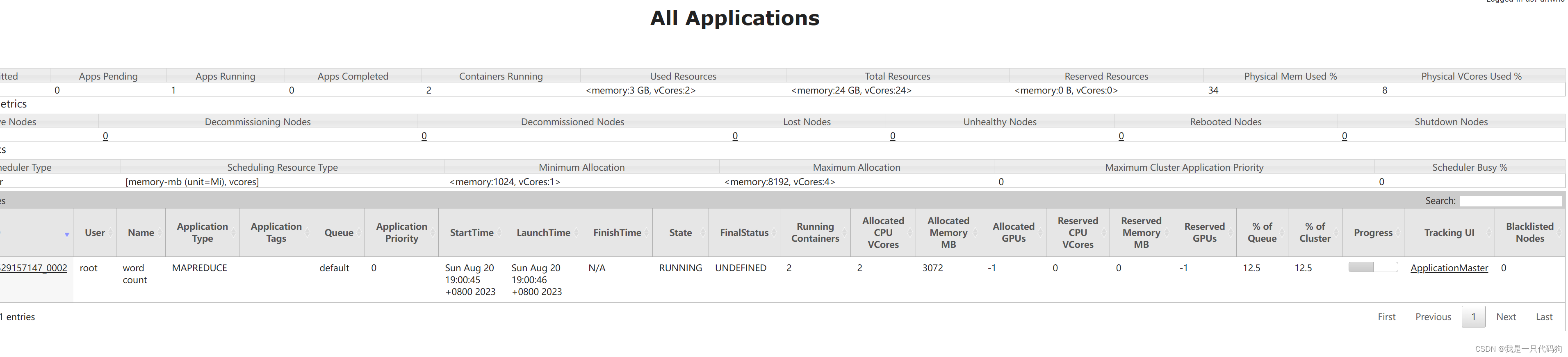
当我们点击History 的时候会报错,需要配置历史服务器
配置历史服务器
cd /opt/module/hadoop-3.3.6/etc/hadoop
vi mapred-site.xml
在下面追加配置
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop102:10020</value>
</property>
<!-- 历史服务器 web 端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop102:19888</value>
</property>
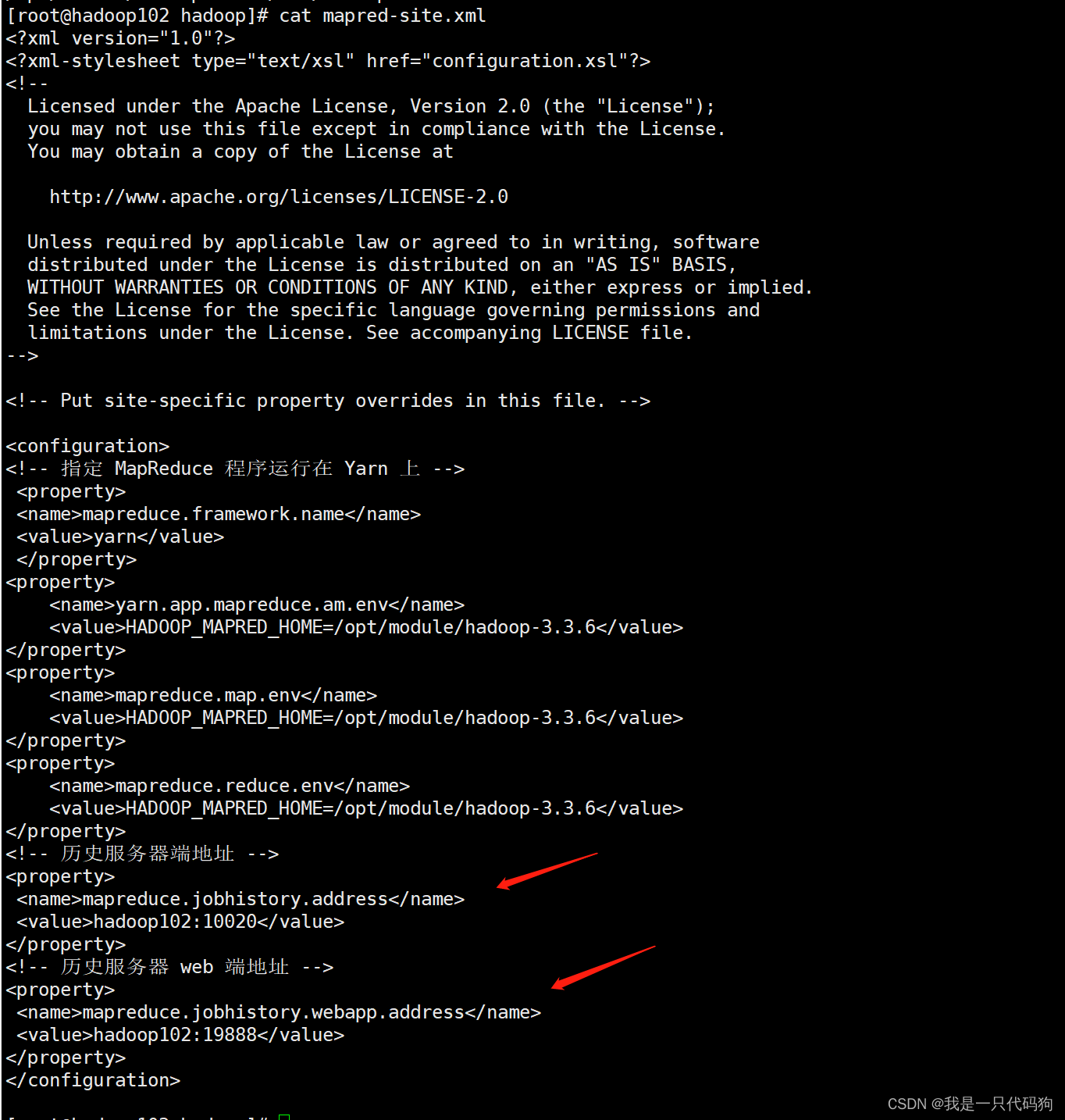
然后拷贝到103和104机器上
scp mapred-site.xml root@hadoop103:/opt/module/hadoop-3.3.6/etc/hadoop/
scp mapred-site.xml root@hadoop104:/opt/module/hadoop-3.3.6/etc/hadoop/
在102机器上启动历史服务器
mapred --daemon start historyserver
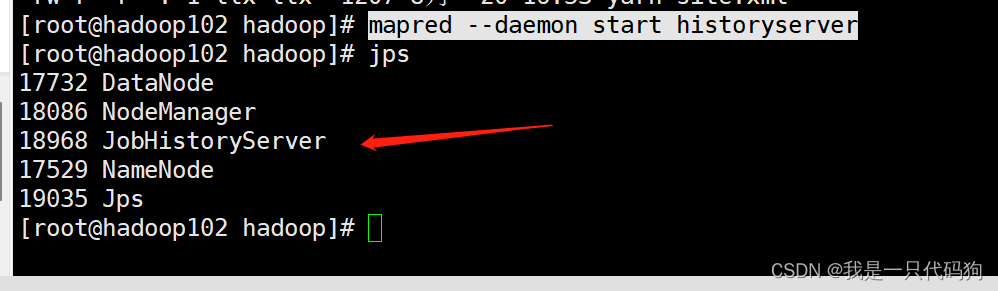
浏览器访问工作历史
http://hadoop102:19888/jobhistory

配置日志的聚集
日志聚集的概念:应用运行完成以后,将所有服务器程序运行日志信息上传到HDFS系统上
注意:开启日志聚集功能,需要重新启动NodeManager,ResourceManager和HistoryServer
cd /opt/module/hadoop-3.3.6/etc/hadoop
vi yarn-site.xml
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop102:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为 7 天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
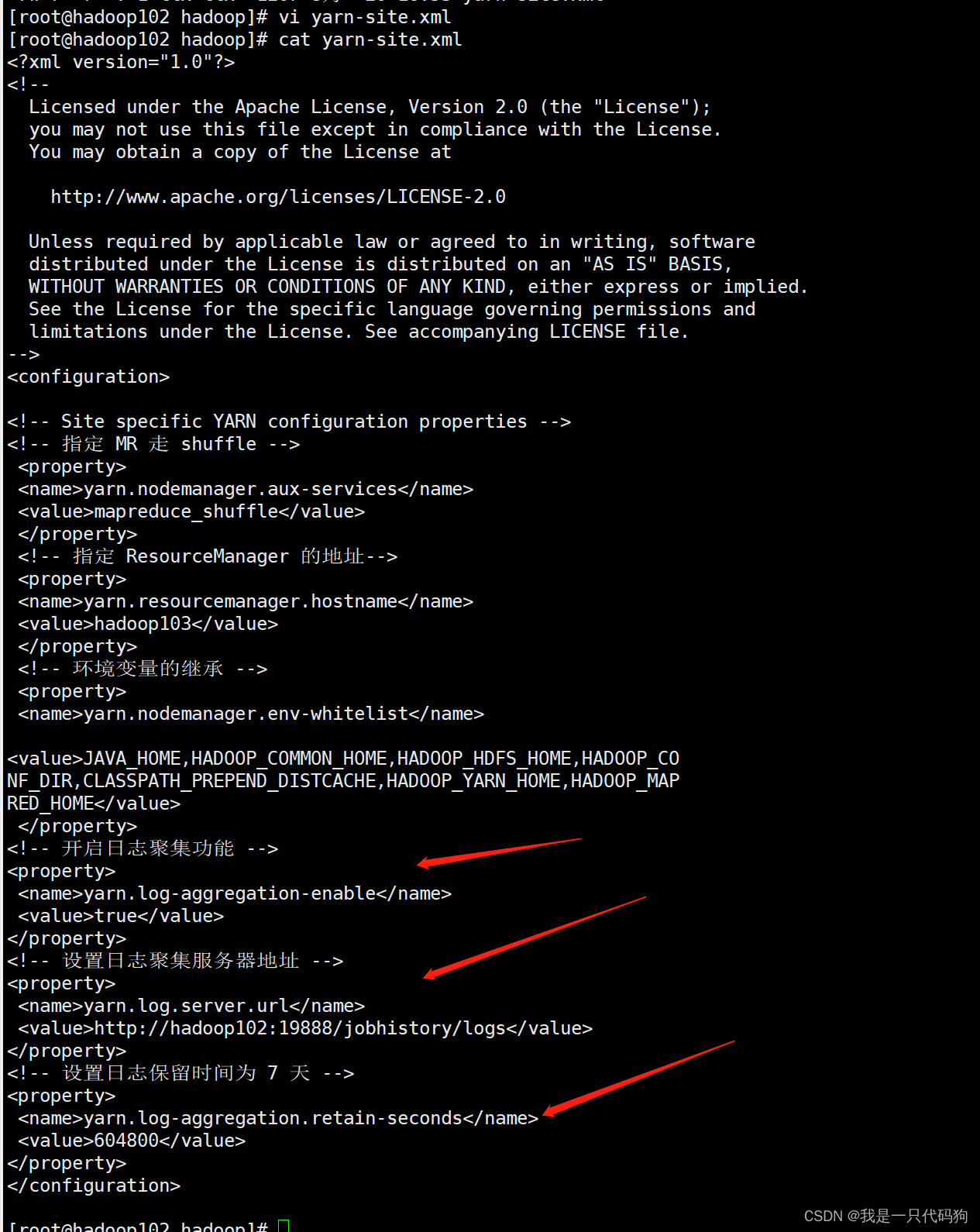
拷贝到103,104机器上
scp yarn-site.xml root@hadoop103:/opt/module/hadoop-3.3.6/etc/hadoop/
scp yarn-site.xml root@hadoop104:/opt/module/hadoop-3.3.6/etc/hadoop/
关闭NodeManager,ResourceManager,和HistoryServer
在103机器停止yarn
cd /opt/module/hadoop-3.3.6
./sbin/stop-yarn.sh
在102机器停止historyserver
mapred --daemon stop historyserver
在103机器重启yarn
./sbin/start-yarn.sh
在102机器重启historyserver
mapred --daemon start historyserver
在102机器上面删除已经计算好的目录ff
hadoop fs -rm -r /ff
在102机器上面重新计算
hadoop jar /opt/module/hadoop-3.3.6/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar wordcount /ddd /ff
浏览器访问历史
http://hadoop102:19888/jobhistory
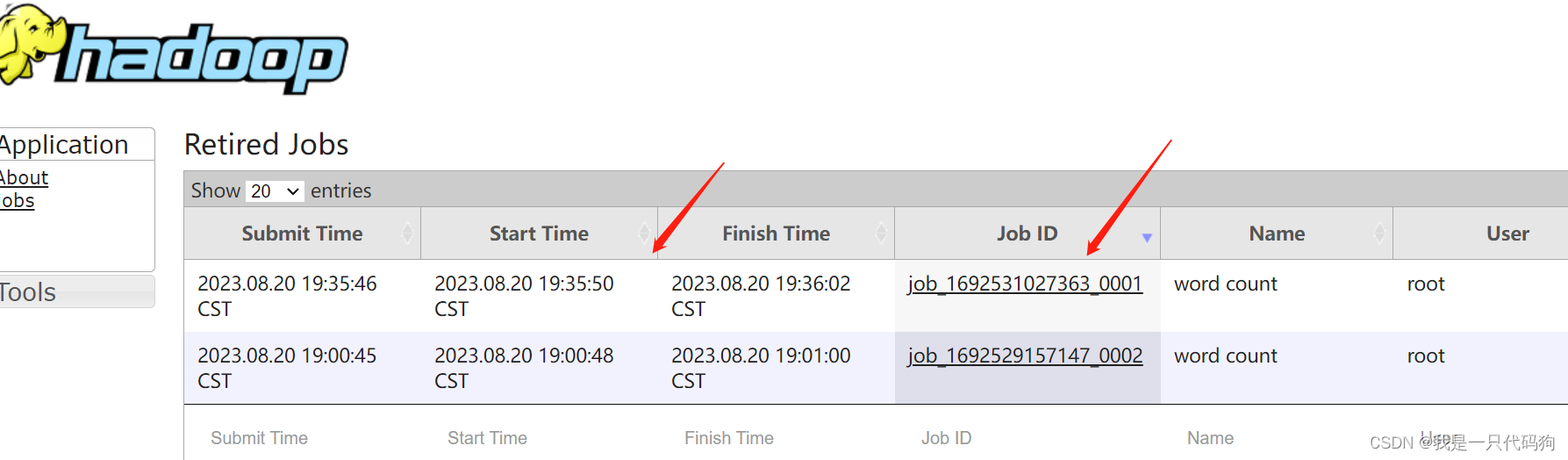
点击logs
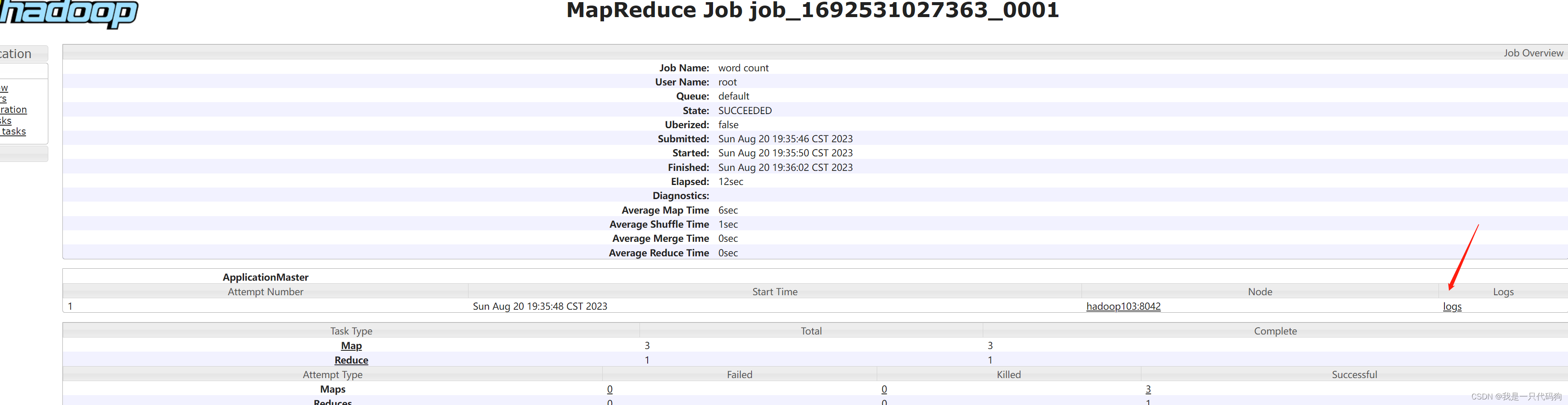
可以看到日志信息

界面上删除文件夹
http://hadoop102:9870/explorer.html#/
当我们在界面上删除文件夹的时候,提示没有权限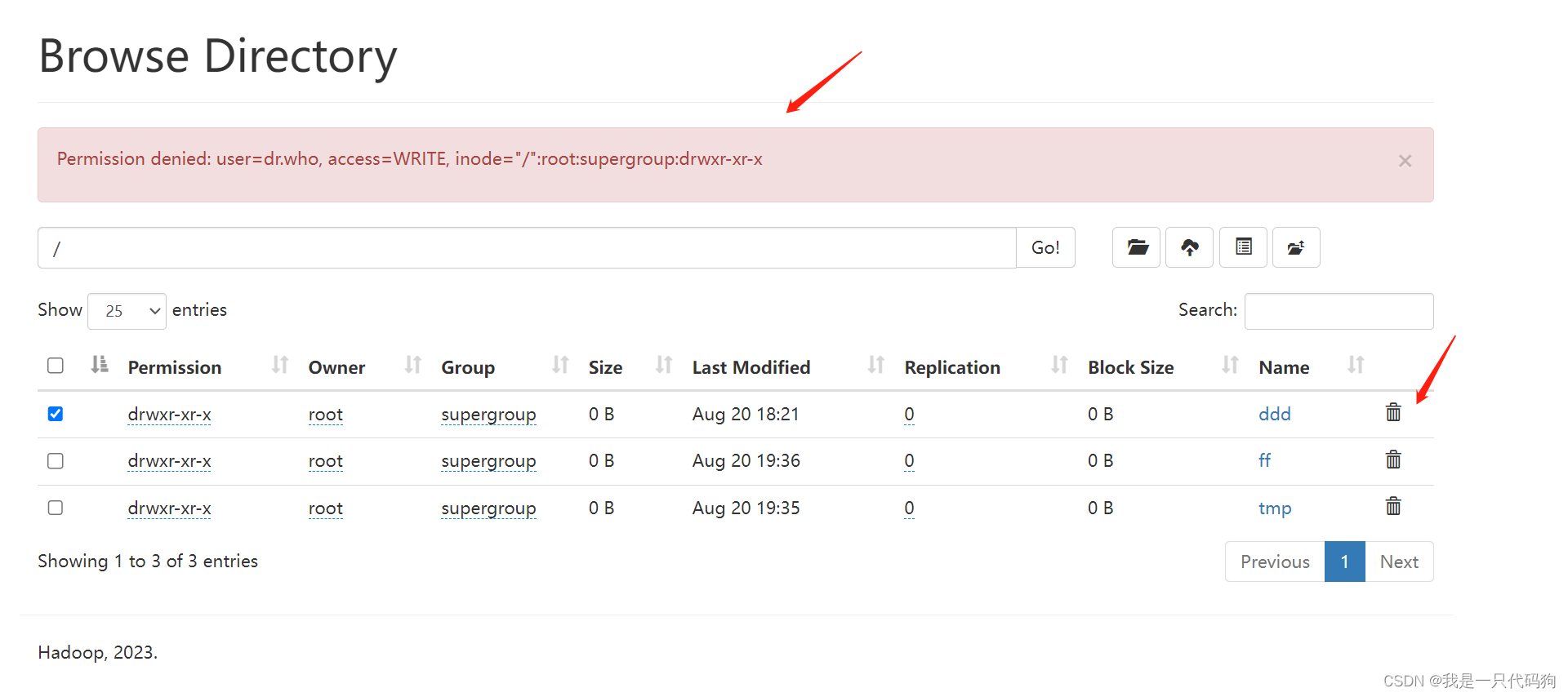
修改core-site.xml文件
cd /opt/module/hadoop-3.3.6/etc/hadoop
vi core-site.xml
在后面追加下面的配置
<!-- 配置 HDFS 网页登录使用的静态用户为 root -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
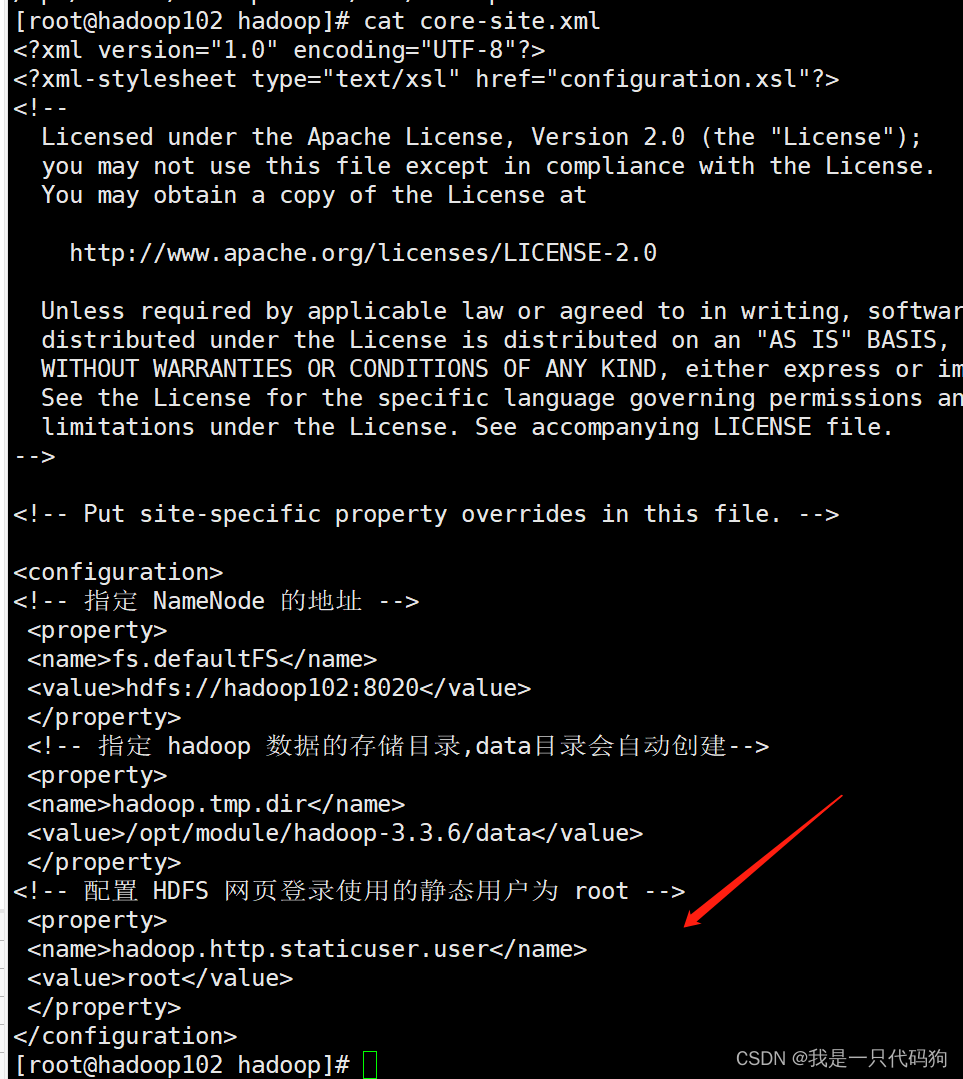
然后把文件拷贝到103,104的机器上
scp core-site.xml root@hadoop103:/opt/module/hadoop-3.3.6/etc/hadoop/
scp core-site.xml root@hadoop104:/opt/module/hadoop-3.3.6/etc/hadoop/
在102机器上重启dfs
cd /opt/module/hadoop-3.3.6/sbin
./stop-dfs.sh
./start-dfs.sh
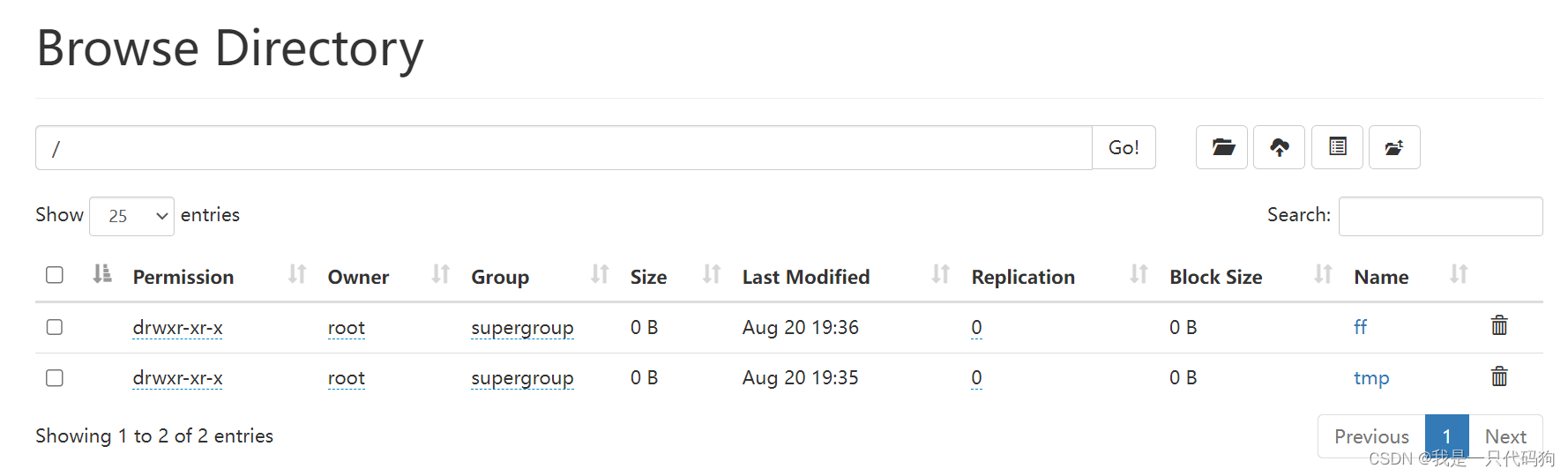
然后再界面上删除文件夹,删除成功















 2514
2514











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









