







一、数据查询
1.集合查询
集合操作的种类
并-UNION
交-INTERSECT
差-EXCEPT
例1.查询计算机科学系的学生及年龄不大于19岁的学生
select *
from Student
where Sdept='CS'
union
select *
from Student
where Sage<=19;
或者可以用or实现:
select *
from Student
where Sdept='CS' or Sage<=19;
执行结果:
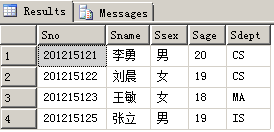
可见,union相当于数学中的并集
例2.查询选修了课程1或者选修了课程2的学生
select Sno
from SC
where Cno = '1'
union
select Sno
from SC
where Cno='2';
例3.查询计算机科学系的学生与年龄不大于19岁的学生的交集
问题可翻译为:
查询计算机系中年龄不大19岁的学生
select *
from Student
wher Sdept='CS'
intersect
select *
from Student
where Sage<=19;
或者可以用and实现
select *
from Student
where Sdept='CS' and Sage<=19;
执行结果:
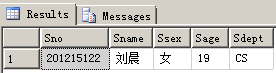
例4.查询既选修了课程1又选修了课程2的学生。
select Sno
from SC
where Cno='1'
intersect
select Sno
from SC
where Cno='2';
例5.查询计算机科学系的学生与年龄不大于19岁的学生的差集
该问题可翻译为:
查询计算机科学系中大于19岁的学生
select *
from Student
where Sdept='CS'
except
select *
from Student
where Sage<=19;
2.基于派生表的查询
子查询不仅可以出现在where子句中
还可以出现在from子句中
这时子查询生成的临时派生表成为主查询的查询对象
例1.找出每个学生超过他自己选修课程平均成绩的课程号
select Sno,Cno
from SC,(select Sno,avg(Grade)
from SC
group by Sno)
as Avg_sc(avg_sno,avg_grade)--这里使用了聚集函数,所以派生表要指定属性列
where SC,Sno=Avg_sc.avg_sno and
SC.grade>=Avg_sc.avg_grade;
//派生表是临时创建的,查询完成之后并不会真的创建一个表
执行结果:
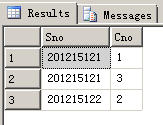
例2.查询所有选修了1号选修课的学生姓名
select Sname
from Student,(select Sno
from SC
where SC.Cno='1') as SC1
where Student.Sno=SC1.Sno;
3.selcet语句的一般形式
SCSELECT [ALL|DISTINCT]
<目标列表达式> [别名] [ ,<目标列表达式> [别名]] …
FROM <表名或视图名> [别名]
[ ,<表名或视图名> [别名]] …
|(<SELECT语句>)[AS]<别名>
[WHERE <条件表达式>]
[GROUP BY <列名1>[HAVING<条件表达式>]]
[ORDER BY <列名2> [ASC|DESC]];
二、数据更新
CRUD
C create new records
R retrieve existing records
U update existing records
D delete wxisting records
1.插入数据
插入数据的方式有两种,一是插入元祖,二是子查询结果。
①.插入元组
在之前的作业里,已经进行过元组插入的练习,这里主要的重点是如何插入子查询结果。
之前作业中涉及到的数据更新:
https://blog.csdn.net/qq_21331159/article/details/115165279
②.插入子查询结果
create table Dept_age
(Sdept char(15)
Avg_age SMALLINT);
insert
into Dept_age(Sdept,Avg_age)
select Sdept,AVG(Sage)
from Student
group by Sdept;
2.修改数据
--语句格式
UPDATE <表名> SET <列名>=<表达式>[,<列名>=<表达式>]…
[WHERE <条件>];
--修改指定表中满足WHERE子句条件的元组
--SET子句给出<表达式>的值用于取代相应的属性列
--如果省略WHERE子句,表示要修改表中的所有元组
--------------------------------------------
RDBMS修改语句时会检查修改操作是否破坏表上已定义的完整性规则
1.实体完整性
2.主码不允许修改
3.用户定义的完整性
①.修改某一个元素的值
例.将学生201215121的年龄改为22岁
update Student
set Sage=22
where Sno='201215121';
②.修改多个元组的值
例.将所有学生的年龄增加1岁。
update Student
set Sage=Sage+1;
③.带子查询的修改语句
update SC
set Grade=0
where Sno in(select Sno
from Student
where Sdept='CS');
3.删除数据
语句格式:
DELETE FROM <表名>
[WHERE <条件>];
--功能:删除指定表中满足WHERE子句条件的元组
where子句可指定要删除的元组
缺省表示删除表中的全部元组,表的定义仍在字典中
表中原数据

例1.删除学号为201215128的学生记录。
delete
from Student
where Sno=201215128;
执行结果:

例2.删除带有子查询的语句
delete
from SC
where Sno in(select Sno
from Student
where Sdept='CS');
三、空值的处理
空值就是“不知道”或“不存在”或“无意义”的值。
一般有以下几种情况:
- 该属性应该有一个值,但目前不知道它的具体值
- 该属性不应该有值
- 由于某种原因不便于填写(例如未知)
1.空值的产生
关于空值的产生,空值并不是一个普通的值,所以需要面对空值,做特殊的处理,下面的例子中,就会产生空值
例1.向SC表中插入一个元组,学生号是”201215126”,课程号是”1”,成绩为空。
insert into SC
values('201215126','1',NULL);
/*或
insert into SC(Sno,Cno)
values('201215126','1');
*/
例2.将Student表中学生号为”201215200”的学生所属的系改为空值。
update Student
set Sdept = NULL
where Sno='20215200';
2.空值的判断
判断一个属性的值是否为空值,用is null或is not null表示
例1.从Student表中找出漏填了数据的学生信息
select *
from Student
where Sname is null or Sage is null or Sdept is null or Ssex is null;
3.空值的约束条件
在属性定义或者域定义中:
- 有NOT NULL约束条件的不能取空值
- 加了UNIQUE限制的属性不能取空值
- 码属性不能取空值
4.空值的运算
例1.找出选修1号课程的不及格的学生。
select Sno
from SC
where Cno='1' and Grade<60;
例2.选出选修1号课程的不及格的学生以及缺考的学生。
select Sno,Sname
from SC
where (Grade<60 or Grade is null) and Cno='1';
四、视图
视图的特点——虚表
虚表是从一个或几个基本表或视图导出的表,只存放视图的定义,而本身并不存放数据(相当于只是一个查询语句),基表中的数据发生变化,从视图中查询出的数据也随之改变
1.定义视图
语句格式:
CREATE VIEW <视图名> [(<列名> [,<列名>]…)]
AS <子查询>
[WITH CHECK OPTION]; --查询子条件
----------------------------------------------
组成视图的属性列名:全部省略或全部指定
全部省略:
由子查询中SELECT目标列中的诸字段组成
全部指定:(明确指定所有列名)
1.某个目标列是聚集函数或列表达式
2.多表连接时选出了几个同名列作为视图的字段
3.需要在视图中为某个列启用新的更合适的名字
例1.建立信息系学生的视图。
create view IS_Student
as select Sno,Sname,Sage
from Student
where Sdept='IS';
执行结果:

例2.建立信息系学生的视图,并要求进行修改和插入 操作时仍需保证该视图只有信息系的学生 。
可在上一问的基础上在句尾添加一条with check option,这样在对视图进行插入、修改和删除操作时,RDBMS会自动加上Sdept='IS’的条件。
例3.建立信息系选修了1号课程的学生的视图(包括 学号、姓名、成绩)。
create view IS_S1
as select Student.Sno,Sname,Grade
from Student,SC
where Student.Sno=SC.Sno and
Student.Sdept='IS' and
SC.Cno='1';
例4.建立信息系选修了1号课程且成绩在90分以上的学生的视图。(基于视图的视图)
create view IS_S2
as select Sno,Sname,Grade
from IS_S1
where Grade>=90;
例5.定义一个反映学生出生年份的视图。(带表达式的视图)
create view BT_S(Sno,Sname,Sbirth)
as
select Sno,Sname,2014-Sage
from Student;
例6.将学生的学号及平均成绩定义为一个视图(分组视图)
create view S_G(Sno,Gavg)
as
select Sno,AVG(Grade)
from SC
group by Sno;
2.视图删除
语句格式:
DROP VIEW <视图名>[CASCADE];
--但已经取消了CASCADE的删除方法,所以并不能加CASCADE
例.删除视图BT_S和IS_S1
drop view BT_S;--可以直接删除
drop view IS_S1;--执行错误,必须删除之前与之关联的IS_S2
3.查询视图
在用户角度,查询视图与查询基本表相同
实现查询的方法:'视图消解法'
1.进行有效性检查
2.转换成等价的对基本表的查询
3.执行修正后的查询
例1.在信息系学生的视图中找出年龄小于20岁的学生。
select Sno,Sage
from IS_Student
where Sage<20;
视图消解转换后的查询语句为:
select Sno,Sage
from Student
where Sdept='IS' and Sage<20;
但视图消解法有时不能生成正确的查询,如下面的例二:
例2.在S_G视图中查询平均成绩在90分以上的学生学号和平均成绩
视图查询:
select *
from S_G
where Gavg>=90;
消解法后的查询:
select Sno,AVG(Grade)
from SC
where AVG(Grade)>=90
Group by Sno;
根据之前所学,直接消解法得到的查询是错误的
正确查询应将where 替换为 having
select Sno,AVG(Grade)
from SC
Group by Sno;
having AVG(Grade)>=90;
having短句 和 where 子句的区别:
作用对象不同,where子句作用于表或视图,从中选择满足条件的元组,having短句作用于组,从总选择满足条件的组.
而且,在group by子句中使用where会出现报错:
聚合不应出现在 WHERE 子句中,除非该聚合位于 HAVING 子句或选择列表所包含的子查询中,并且要对其进行聚合的列是外部引用。
4.更新视图
更新视图与更新表中数据一样
同样使用insert、update、delete为视图更新,为视图更新之后,其基于的表也会发生相应改变,以下几道例题,都以将对视图的修改改为对表的修改
例1.将信息系学生视图IS_Student中学 号”201215122”的学生姓名改为”刘辰”。
update IS_Student
set Sname='刘辰'
where Sno='201215122'
例2.向信息系学生视图IS_S中插入一个新的学生记录, 其中学号为”201215129”,姓名为”赵新”,年龄为20岁
insert
into IS_Student
values('201215129','赵新',20);
例3.删除信息系学生视图IS_Student中学号 为”201215129”的记录
delete
from IS_Student
where Sno='201215129';
但并不意味着所有对视图的更新都可以替换为对表的更新,一些视图是不可更新的,因为对这些视图的更新不能唯一地有意义地转换成对相应基本表的更新
5.视图的作用
- 简化用户的操作
- 使用户能以多种角度看待同一数据
- 对重构数据库提供了一定程度的逻辑独立性
- 对机密数据提供安全保护
- 适当的利用视图可以更清晰的表达查询
因为课实在是比较多,这次作业交的比平常就晚了很多QAQ
下面的几个实验报告我也尽量在今天写完 orz















 1599
1599











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









