







文章目录
- 1.概述
- 2.线程池在何时初始化
- 3.构建线程池框架
- 3.1 初始化ExecutorBuilder集合
- 3.1.1 构造函数
- 3.1.1.1 普通操作的Executor
- 3.1.1.2 索引操作的Executor
- 3.1.1.3 批处理操作的Executor (无)
- 3.1.1.4 get操作的Executor
- 3.1.1.5 查询操作的Executor
- 3.1.1.6 管理操作的Executor
- 3.1.1.7 监听操作的Executor
- 3.1.1.8 flush操作的Executor
- 3.1.1.9 refresh操作的Executor
- 3.1.1.10 warmer操作的Executor
- 3.1.1.11 snapshot操作的Executor
- 3.1.1.12 碎片处理操作的Executor
- 3.1.1.13 强制merge操作的Executor
- 3.1.1.14 获取碎片操作的Executor
- 3.2 ThreadPool对象的作用
- 4.利特尔法则
- M.扩展

1.概述
转载:[10]elasticsearch源码深入分析——线程池的封装
2.线程池在何时初始化
当Node完成了PluginsService的构造后,紧接会通过getExecutorBuilders方法取得线程池的Executor构造器列表,代码如下:
List<ExecutorBuilder<?>> executorBuilders = pluginsService.getExecutorBuilders(settings)
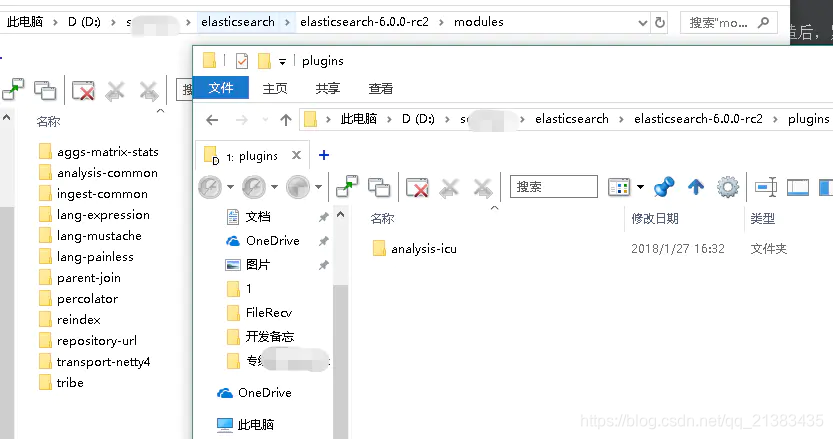
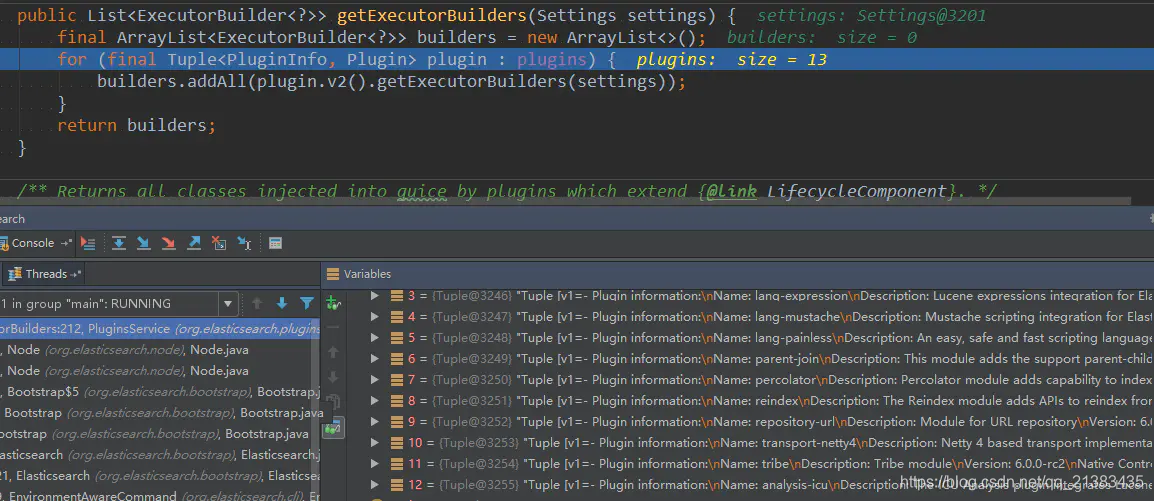
此时PluginsService对象中已经有了需要加载的所有plugin了,包含modules路径和plugins路径中的所有组件,这里统称为plugin。如下图所示总共是包含了13个已加载的Plugin,分别是modules路径中的默认必须加载的12个和Plugins路径中的自定义安装的1个(ICU分词器)。如下图所示
3.构建线程池框架
3.1 初始化ExecutorBuilder集合
Node实例化过程中,通过代码:
List<ExecutorBuilder<?>> executorBuilders =
pluginsService.getExecutorBuilders(settings);
查找到自定义的线程池Executor构建器。再获得自定义线程池构建器集合后,开始构建线程池(ThreadPool)。
ThreadPool threadPool =
new ThreadPool(settings, executorBuilders.toArray(new ExecutorBuilder[0]));
3.1.1 构造函数
public ThreadPool(final Settings settings, final ExecutorBuilder<?>... customBuilders) {
assert Node.NODE_NAME_SETTING.exists(settings);
final Map<String, ExecutorBuilder> builders = new HashMap<>();
// 获得处理器CPU的数量,
final int allocatedProcessors = EsExecutors.allocatedProcessors(settings);
final int halfProcMaxAt5 = halfAllocatedProcessorsMaxFive(allocatedProcessors);
final int halfProcMaxAt10 = halfAllocatedProcessorsMaxTen(allocatedProcessors);
final int genericThreadPoolMax = boundedBy(4 * allocatedProcessors, 128, 512);
builders.put(Names.GENERIC, new ScalingExecutorBuilder(Names.GENERIC, 4, genericThreadPoolMax, TimeValue.timeValueSeconds(30)));
builders.put(Names.WRITE, new FixedExecutorBuilder(settings, Names.WRITE, allocatedProcessors, 200));
builders.put(Names.GET, new FixedExecutorBuilder(settings, Names.GET, allocatedProcessors, 1000));
builders.put(Names.ANALYZE, new FixedExecutorBuilder(settings, Names.ANALYZE, 1, 16));
builders.put(Names.SEARCH, new AutoQueueAdjustingExecutorBuilder(settings,
Names.SEARCH, searchThreadPoolSize(allocatedProcessors), 1000, 1000, 1000, 2000));
builders.put(Names.SEARCH_THROTTLED, new AutoQueueAdjustingExecutorBuilder(settings,
Names.SEARCH_THROTTLED, 1, 100, 100, 100, 200));
builders.put(Names.MANAGEMENT, new ScalingExecutorBuilder(Names.MANAGEMENT, 1, 5, TimeValue.timeValueMinutes(5)));
// no queue as this means clients will need to handle rejections on listener queue even if the operation succeeded
// the assumption here is that the listeners should be very lightweight on the listeners side
builders.put(Names.LISTENER, new FixedExecutorBuilder(settings, Names.LISTENER, halfProcMaxAt10, -1, true));
builders.put(Names.FLUSH, new ScalingExecutorBuilder(Names.FLUSH, 1, halfProcMaxAt5, TimeValue.timeValueMinutes(5)));
builders.put(Names.REFRESH, new ScalingExecutorBuilder(Names.REFRESH, 1, halfProcMaxAt10, TimeValue.timeValueMinutes(5)));
builders.put(Names.WARMER, new ScalingExecutorBuilder(Names.WARMER, 1, halfProcMaxAt5, TimeValue.timeValueMinutes(5)));
builders.put(Names.SNAPSHOT, new ScalingExecutorBuilder(Names.SNAPSHOT, 1, halfProcMaxAt5, TimeValue.timeValueMinutes(5)));
builders.put(Names.FETCH_SHARD_STARTED,
new ScalingExecutorBuilder(Names.FETCH_SHARD_STARTED, 1, 2 * allocatedProcessors, TimeValue.timeValueMinutes(5)));
builders.put(Names.FORCE_MERGE, new FixedExecutorBuilder(settings, Names.FORCE_MERGE, 1, -1));
builders.put(Names.FETCH_SHARD_STORE,
new ScalingExecutorBuilder(Names.FETCH_SHARD_STORE, 1, 2 * allocatedProcessors, TimeValue.timeValueMinutes(5)));
for (final ExecutorBuilder<?> builder : customBuilders) {
if (builders.containsKey(builder.name())) {
throw new IllegalArgumentException("builder with name [" + builder.name() + "] already exists");
}
builders.put(builder.name(), builder);
}
this.builders = Collections.unmodifiableMap(builders);
threadContext = new ThreadContext(settings);
final Map<String, ExecutorHolder> executors = new HashMap<>();
for (final Map.Entry<String, ExecutorBuilder> entry : builders.entrySet()) {
logger.info("分配线程池每种类型的情况:name:{} value:{}",entry.getKey(),entry.getValue().getRegisteredSettings());
final ExecutorBuilder.ExecutorSettings executorSettings = entry.getValue().getSettings(settings);
final ExecutorHolder executorHolder = entry.getValue().build(executorSettings, threadContext);
if (executors.containsKey(executorHolder.info.getName())) {
throw new IllegalStateException("duplicate executors with name [" + executorHolder.info.getName() + "] registered");
}
logger.debug("created thread pool: {}", entry.getValue().formatInfo(executorHolder.info));
executors.put(entry.getKey(), executorHolder);
}
executors.put(Names.SAME, new ExecutorHolder(DIRECT_EXECUTOR, new Info(Names.SAME, ThreadPoolType.DIRECT)));
this.executors = unmodifiableMap(executors);
final List<Info> infos =
executors
.values()
.stream()
.filter(holder -> holder.info.getName().equals("same") == false)
.map(holder -> holder.info)
.collect(Collectors.toList());
this.threadPoolInfo = new ThreadPoolInfo(infos);
logger.info("初始化Scheduler.initScheduler");
this.scheduler = Scheduler.initScheduler(settings);
TimeValue estimatedTimeInterval = ESTIMATED_TIME_INTERVAL_SETTING.get(settings);
logger.info("创建CachedTimeThread 并且设置成 daemon");
this.cachedTimeThread = new CachedTimeThread(EsExecutors.threadName(settings, "[timer]"), estimatedTimeInterval.millis());
this.cachedTimeThread.start();
}
首先通过代码获得处理器CPU的数量,
Runtime.getRuntime().availableProcessors()
当然这个值是可以被Setting中设置的变量processors来覆盖的。这个变量在代码中被标记为availableProcessors。然后创建变量
halfProcMaxAt5,这个变量的意思是availableProcessors的一半,但最大不超过5。halfProcMaxAt10,这个变量的意思是availableProcessors的一半,但最大不超过10。
这两个变量在后面创建各种线程池构造器中反复用到。
在确定了可使用的处理器数量后,就能确定线程池的最小值(genericThreadPoolMax),ElasticSearch中是确定为:可用CPU处理器数量的4倍,且固定范围为最小128,最大为512。
由此可见如果用一般服务器的话,线程池上限最终会被确定为128,可以说还是比较高的设定了。
接下来开始构造执行不同操作时线程池Executor,ElasticSearch中把各个操作的Executor构造为Map,Map<String, ExecutorBuilder>,下面是各个Executor对象的解释:
3.1.1.1 普通操作的Executor
普通操作的Executor:构建一个可伸缩的Executor构建器,value为ScalingExecutorBuilder对象。接收参数和对应操作如下:
builders.put(Names.GENERIC, new ScalingExecutorBuilder(Names.GENERIC, 4, genericThreadPoolMax, TimeValue.timeValueSeconds(30)));
public ScalingExecutorBuilder(final String name, final int core, final int max, final TimeValue keepAlive, final String prefix) {
super(name);
this.coreSetting =
Setting.intSetting(settingsKey(prefix, "core"), core, Setting.Property.NodeScope);
this.maxSetting = Setting.intSetting(settingsKey(prefix, "max"), max, Setting.Property.NodeScope);
this.keepAliveSetting =
Setting.timeSetting(settingsKey(prefix, "keep_alive"), keepAlive, Setting.Property.NodeScope);
}
name:线程池执行者的名称,也就是generic。core:线程池中线程的最小值,固定为4。将thread_pool.generic.core的设为这个值。max:线程池中线程的最大值,对应上面提到的genericThreadPoolMax,在本机跑的结果是128keepAlive:超过4个线程后,线程保持活跃的时间。这个值固定为30秒。这个参数被设定为变量thread_pool.generic.keep_alive
3.1.1.2 索引操作的Executor
索引操作的Executor:构建一个固定的Executor构建器。key为index,value为FixedExecutorBuilder对象,接收参数和对应操作如下:
public FixedExecutorBuilder(
final Settings settings,
final String name,
final int size,
final int queueSize,
final String prefix,
final boolean deprecated
) {
super(name);
final String sizeKey = settingsKey(prefix, "size");
final Setting.Property[] properties;
if (deprecated) {
properties = new Setting.Property[]{Setting.Property.NodeScope, Setting.Property.Deprecated};
} else {
properties = new Setting.Property[]{Setting.Property.NodeScope};
}
this.sizeSetting =
new Setting<>(
sizeKey,
s -> Integer.toString(size),
s -> Setting.parseInt(s, 1, applyHardSizeLimit(settings, name), sizeKey),
properties);
final String queueSizeKey = settingsKey(prefix, "queue_size");
this.queueSizeSetting = Setting.intSetting(queueSizeKey, queueSize, properties);
}
settings:Node的配置settings。设定配置变量 thread_pool.index.size的值为该参数中cpu的数量name:线程池执行者的名称,也就是idnex。size:线程的固定大小,和参数name一起构造配置变量thread_pool.index.size的值为size的值,本机跑的结果是4。queueSize:阻塞队列的大小,构造配置变量thread_pool.index.queue_size的值为200,注意这个值固定为200。
3.1.1.3 批处理操作的Executor (无)
批处理操作的Executor:构建一个固定的Executor构建器。key为bulk,value为FixedExecutorBuilder对象,接收参数和对应操作如下:
- settings:Node的配置settings。设定配置变量thread_pool.bulk.size的值为该参数中cpu的数量
- name:线程池执行者的名称,也就是
bulk。 - size:线程的固定大小,和参数name一起构造配置变量thread_pool.bulk.size的值为size的值,本机跑的结果是4。
- queueSize:阻塞队列的大小,构造配置变量thread_pool.bulk.queue_size的值为200,注意这个值固定为200。
3.1.1.4 get操作的Executor
get操作的Executor:构建一个固定的Executor构建器。key为get,value为FixedExecutorBuilder对象,接收参数和对应操作如下:
public FixedExecutorBuilder(
final Settings settings,
final String name,
final int size,
final int queueSize,
final String prefix,
final boolean deprecated
) {
super(name);
final String sizeKey = settingsKey(prefix, "size");
final Setting.Property[] properties;
if (deprecated) {
properties = new Setting.Property[]{Setting.Property.NodeScope, Setting.Property.Deprecated};
} else {
properties = new Setting.Property[]{Setting.Property.NodeScope};
}
this.sizeSetting =
new Setting<>(
sizeKey,
s -> Integer.toString(size),
s -> Setting.parseInt(s, 1, applyHardSizeLimit(settings, name), sizeKey),
properties);
final String queueSizeKey = settingsKey(prefix, "queue_size");
this.queueSizeSetting = Setting.intSetting(queueSizeKey, queueSize, properties);
}
- settings:Node的配置settings。设定配置变量thread_pool.get.size的值为该参数中cpu的数量
- name:线程池执行者的名称,也就是get。
- size:线程的固定大小,和参数name一起构造配置变量thread_pool.get.size的值为size的值,本机跑的结果是4。
- queueSize:阻塞队列的大小,构造配置变量thread_pool.get.queue_size的值为1000,注意这个值固定为1000。
3.1.1.5 查询操作的Executor
查询操作的Executor:构建一个根据利特尔法则自动扩展长度的Executor构建器,这个构建器的逻辑与其他构建器不同,也显得比较复杂,也说明了对于查询操作,ElasticSearch做了特殊的优化。key为search,value为AutoQueueAdjustingExecutorBuilder对象,接收参数和对应操作如下:
builders.put(Names.SEARCH, new AutoQueueAdjustingExecutorBuilder(settings,
Names.SEARCH, searchThreadPoolSize(allocatedProcessors), 1000, 1000, 1000, 2000));
- settings:Node的配置settings。设定配置变量thread_pool.search.size的值为该参数中cpu的数量
- name:线程池执行者的名称,也就是search。
- size:线程的固定大小,和参数name一起构造配置变量thread_pool.search.size的值为size的值,本机跑的结果是7。
- initialQueueSize:初始化队列的大小,固定设置为1000,造配置变量thread_pool.search.queue_size的值为200
- minQueueSize:队列的最小长度,固定设置为1000设定配置变量thread_pool.search.min_queue_size的值为1000
- maxQueueSize:队列的最大长度,固定设置为1000,设定配置变量thread_pool.search.max_queue_size的值为1000
- frameSize:队列的步进长度,固定设置为2000,构造配置变量thread_pool.search.auto_queue_frame_size的值为200,注意这个值固定为200。
- thread_pool.search.target_response_time针对search操作的相应被设置为1S,
3.1.1.6 管理操作的Executor
管理操作的Executor:构建一个可伸缩的Executor构建器。key为management,value为ScalingExecutorBuilder对象,接收参数和对应操作如下:
builders.put(Names.MANAGEMENT, new ScalingExecutorBuilder(Names.MANAGEMENT, 1, 5, TimeValue.timeValueMinutes(5)));
settings:Node的配置settings。设定配置变量thread_pool.management.size的值为该参数中cpu的数量
name:线程池执行者的名称,也就是management,
size:线程的固定大小,和参数name一起构造配置变量thread_pool.management.size的值为size的值,本机跑的结果是1。
queueSize:阻塞队列的大小,构造配置变量thread_pool.management.queue_size的值为200,注意这个值固定为200。
keepAlive:超过1个线程后,线程保持活跃的时间。这个值固定为5分钟。这个参数被设定为变量thread_pool.management.keep_alive。
3.1.1.7 监听操作的Executor
监听操作的Executor:构建一个固定的Executor构建器。key为listener,value为FixedExecutorBuilder对象,接收参数和对应操作如下:
builders.put(Names.LISTENER, new FixedExecutorBuilder(settings, Names.LISTENER, halfProcMaxAt10, -1, true));
settings:Node的配置settings。设定配置变量thread_pool.listener.size的值为该参数中cpu的数量
name:线程池执行者的名称,也就是listener,
size:线程的固定大小,上文提到的halfProcMaxAt10,和参数name一起构造配置变量thread_pool.listener.size的值为size的值,本机跑的结果是2。
queueSize:阻塞队列的大小,构造配置变量thread_pool.listener.queue_size的值为-1,意思就没有阻塞队列。
3.1.1.8 flush操作的Executor
flush操作的Executor:构建一个可伸缩的Executor构建器。key为flush,value为ScalingExecutorBuilder对象,接收参数和对应操作如下:
builders.put(Names.FLUSH, new ScalingExecutorBuilder(Names.FLUSH, 1, halfProcMaxAt5, TimeValue.timeValueMinutes(5)));
settings:Node的配置settings。设定配置变量thread_pool.flush.size的值为该参数中cpu的数量
name:线程池执行者的名称,也就是flush,
size:线程的固定大小,上文提到的halfProcMaxAt5,和参数name一起构造配置变量thread_pool.flush.size的值为size的值,本机跑的结果是4。
keepAlive:超过1个线程后,线程保持活跃的时间。这个值固定为5分钟。这个参数被设定为变量thread_pool.management.keep_alive。
3.1.1.9 refresh操作的Executor
refresh操作的Executor:构建一个可伸缩的Executor构建器。key为refresh,value为ScalingExecutorBuilder对象,接收参数和对应操作如下:
builders.put(Names.REFRESH, new ScalingExecutorBuilder(Names.REFRESH, 1, halfProcMaxAt10, TimeValue.timeValueMinutes(5)));
settings:Node的配置settings。设定配置变量thread_pool.refresh.size的值为该参数中cpu的数量
name:线程池执行者的名称,也就是refresh,
size:线程的固定大小,上文提到的halfProcMaxAt10,和参数name一起构造配置变量thread_pool.refresh.size的值为size的值,本机跑的结果是4。
keepAlive:超过1个线程后,线程保持活跃的时间。这个值固定为5分钟。这个参数被设定为变量thread_pool.management.keep_alive。
3.1.1.10 warmer操作的Executor
warmer操作的Executor:构建一个可伸缩的Executor构建器。key为warmer,value为ScalingExecutorBuilder对象,接收参数和对应操作如下:
builders.put(Names.WARMER, new ScalingExecutorBuilder(Names.WARMER, 1, halfProcMaxAt5, TimeValue.timeValueMinutes(5)));
settings:Node的配置settings。设定配置变量thread_pool.warmer.size的值为该参数中cpu的数量
name:线程池执行者的名称,也就是warmer,
size:线程的固定大小,上文提到的halfProcMaxAt5,和参数name一起构造配置变量thread_pool.warmer.size的值为size的值,本机跑的结果是4。
keepAlive:超过1个线程后,线程保持活跃的时间。这个值固定为5分钟。这个参数被设定为变量thread_pool.management.keep_alive。
3.1.1.11 snapshot操作的Executor
snapshot操作的Executor:构建一个可伸缩的Executor构建器。key为snapshot,value为ScalingExecutorBuilder对象,接收参数和对应操作如下:
builders.put(Names.SNAPSHOT, new ScalingExecutorBuilder(Names.SNAPSHOT, 1, halfProcMaxAt5, TimeValue.timeValueMinutes(5)));
settings:Node的配置settings。设定配置变量thread_pool.snapshot.size的值为该参数中cpu的数量
name:线程池执行者的名称,也就是snapshot,
size:线程的固定大小,上文提到的halfProcMaxAt5,和参数name一起构造配置变量thread_pool.snapshot.size的值为size的值,本机跑的结果是4。
keepAlive:超过1个线程后,线程保持活跃的时间。这个值固定为5分钟。这个参数被设定为变量thread_pool.management.keep_alive。
3.1.1.12 碎片处理操作的Executor
碎片处理操作的Executor:构建一个可伸缩的Executor构建器。key为fetch_shard_started,value为ScalingExecutorBuilder对象,接收参数和对应操作如下:
builders.put(Names.FETCH_SHARD_STARTED,
new ScalingExecutorBuilder(Names.FETCH_SHARD_STARTED, 1, 2 * allocatedProcessors, TimeValue.timeValueMinutes(5)));
settings:Node的配置settings。设定配置变量thread_pool.fetch_shard_started.size的值为该参数中cpu的数量
name:线程池执行者的名称,也就是fetch_shard_started,
size:线程的固定大小,和参数name一起构造配置变量thread_pool.fetch_shard_started.size的值为size的值,本机跑的结果是4。
queueSize:阻塞队列的大小,构造配置变量thread_pool.fetch_shard_started.queue_size的值为200,注意这个值固定为200。
3.1.1.13 强制merge操作的Executor
强制merge操作的Executor:构建一个可伸缩的Executor构建器。key为force_merge,value为ScalingExecutorBuilder对象,接收参数和对应操作如下:
builders.put(Names.FORCE_MERGE, new FixedExecutorBuilder(settings, Names.FORCE_MERGE, 1, -1));
settings:Node的配置settings。设定配置变量thread_pool.force_merge.size的值为该参数中cpu的数量
name:线程池执行者的名称,也就是force_merge,
size:线程的固定大小,和参数name一起构造配置变量thread_pool.force_merge.size的值为size的值,本机跑的结果是4。
queueSize:阻塞队列的大小,构造配置变量thread_pool.force_merge.queue_size的值为200,注意这个值固定为200。
3.1.1.14 获取碎片操作的Executor
获取碎片操作的Executor:构建一个可伸缩的Executor构建器。key为fetch_shard_store,value为ScalingExecutorBuilder对象,接收参数和对应操作如下:
builders.put(Names.FETCH_SHARD_STORE,
new ScalingExecutorBuilder(Names.FETCH_SHARD_STORE, 1, 2 * allocatedProcessors, TimeValue.timeValueMinutes(5)));
settings:Node的配置settings。设定配置变量thread_pool.fetch_shard_store.size的值为该参数中cpu的数量
name:线程池执行者的名称,也就是fetch_shard_store,
size:线程的固定大小,和参数name一起构造配置变量thread_pool.fetch_shard_store.size的值为size的值,本机跑的结果是4。
queueSize:阻塞队列的大小,构造配置变量thread_pool.fetch_shard_store.queue_size的值为200,注意这个值固定为200。
至此就完成了org.elasticsearch.threadpool.ThreadPool对象的创建。
3.2 ThreadPool对象的作用
得到ThreadPool的对象后,通过线程池进行了NodeClient的构建。
client = new NodeClient(settings, threadPool);
和ResourceWatcherService对象的构建,
final ResourceWatcherService resourceWatcherService = new ResourceWatcherService(settings, threadPool);
后面还有很多的组件都用到了线程池,比如:
IngestService
ClusterInfoService
MonitorService
ActionModule
IndicesService
NetworkModule
TransportService
DiscoveryModule
NodeService
可以看出都是ElasticSearch的核心组件,这些组件的功能和原理,我都会在以后的文章中讲解,而像ElasticSearch这种存储搜索系统来说IO操作肯定非常频繁,而线程池是专门致力于解决系统的IO问题,它在这些服务组件中的作用也显得愈发重要。
4.利特尔法则
查询操作中提到的利特尔法则是一种描述稳定系统中,三个变量之间关系的法则。
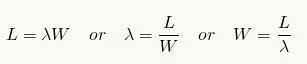
其中L表示平均请求数量,λ表示请求的频率,W表示响应请求的平均时间。举例来说,如果每秒请求数为10次,每个请求处理时间为1秒,那么在任何时刻都有10个请求正在被处理。回到我们的话题,就是需要使用10个线程来进行处理。如果单个请求的处理时间翻倍,那么处理的线程数也要翻倍,变成20个。
理解了处理时间对于请求处理效率的影响之后,我们会发现,通常理论上限可能不是线程池大小的最佳值。线程池上限还需要参考任务处理时间。
假设JVM可以并行处理1000个任务,如果每个请求处理时间不超过30秒,那么在最坏情况下,每秒最多只能处理33.3个请求。然而,如果每个请求只需要500毫秒,那么应用程序每秒可以处理2000个请求。















 1933
1933











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









