








1.概述
转载并且补充:你想知道的所有关于Kafka Leader选举流程和选举策略都在这(内含12张高清图,建议收藏)
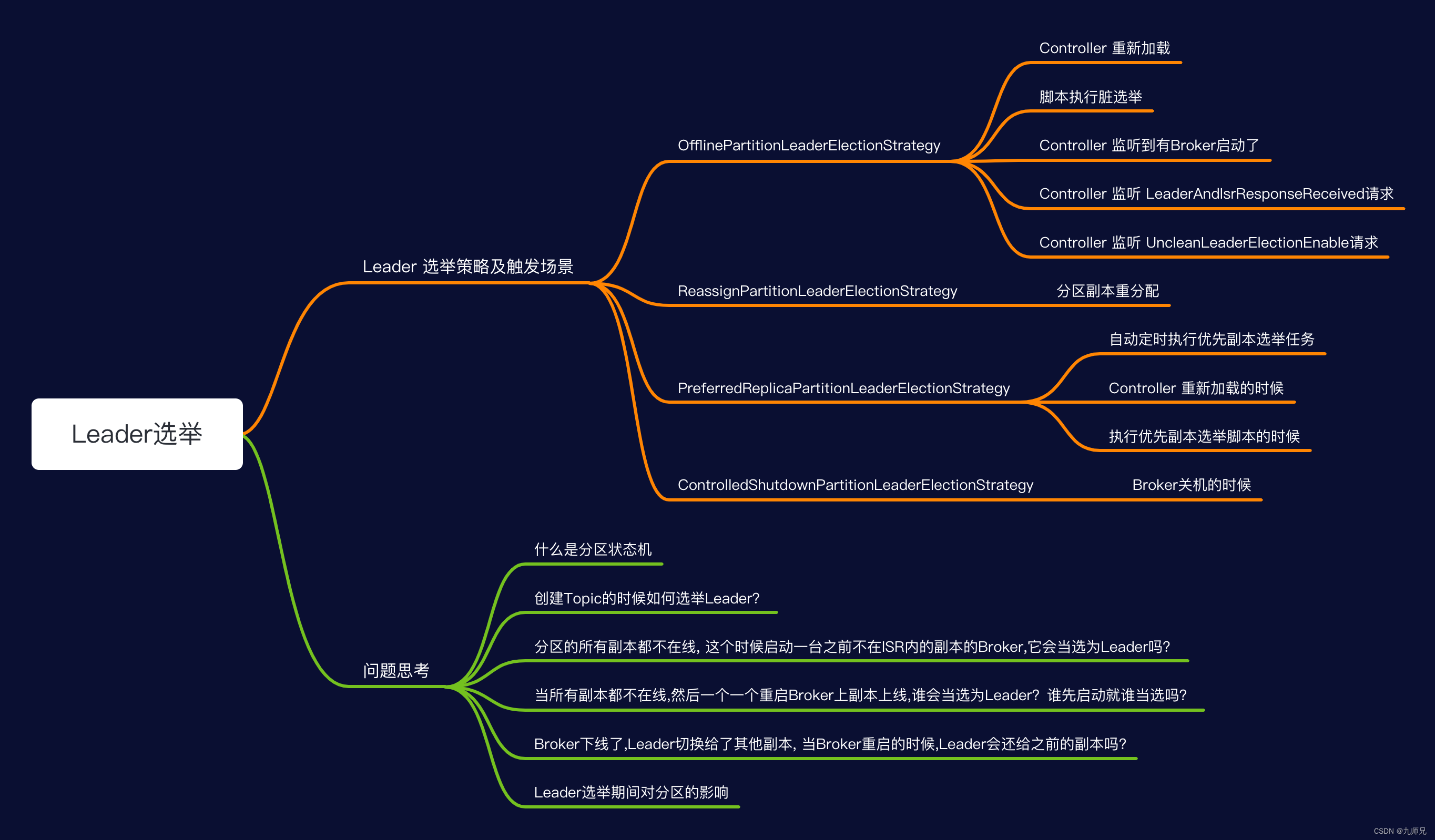
2.思考几个问题
- 什么是分区状态机?
- 创建Topic的时候如何选举Leader?
- 分区的所有副本都不在线, 这个时候启动一台之前不在ISR内的副本,它会当选为Leader吗?
- 当所有副本都不在线,然后一个一个重启Broker上副本上线,谁会当选为Leader?谁先启动就谁当选吗?
- Broker下线了,Leader切换给了其他副本, 当Broker重启的时候,Leader会还给之前的副本吗?
- 选举成功的那一刻, 生产者和消费着都做了哪些事情?
- Leader选举期间对分区的影响
- Broker宕机了,会立即触发所有副本脱离ISR吗?
- Broker宕机了,为什么会又触发受控关机Leader选举策略、又会触发离线分区Leader选举策略?
3.分区Leader选举流程分析
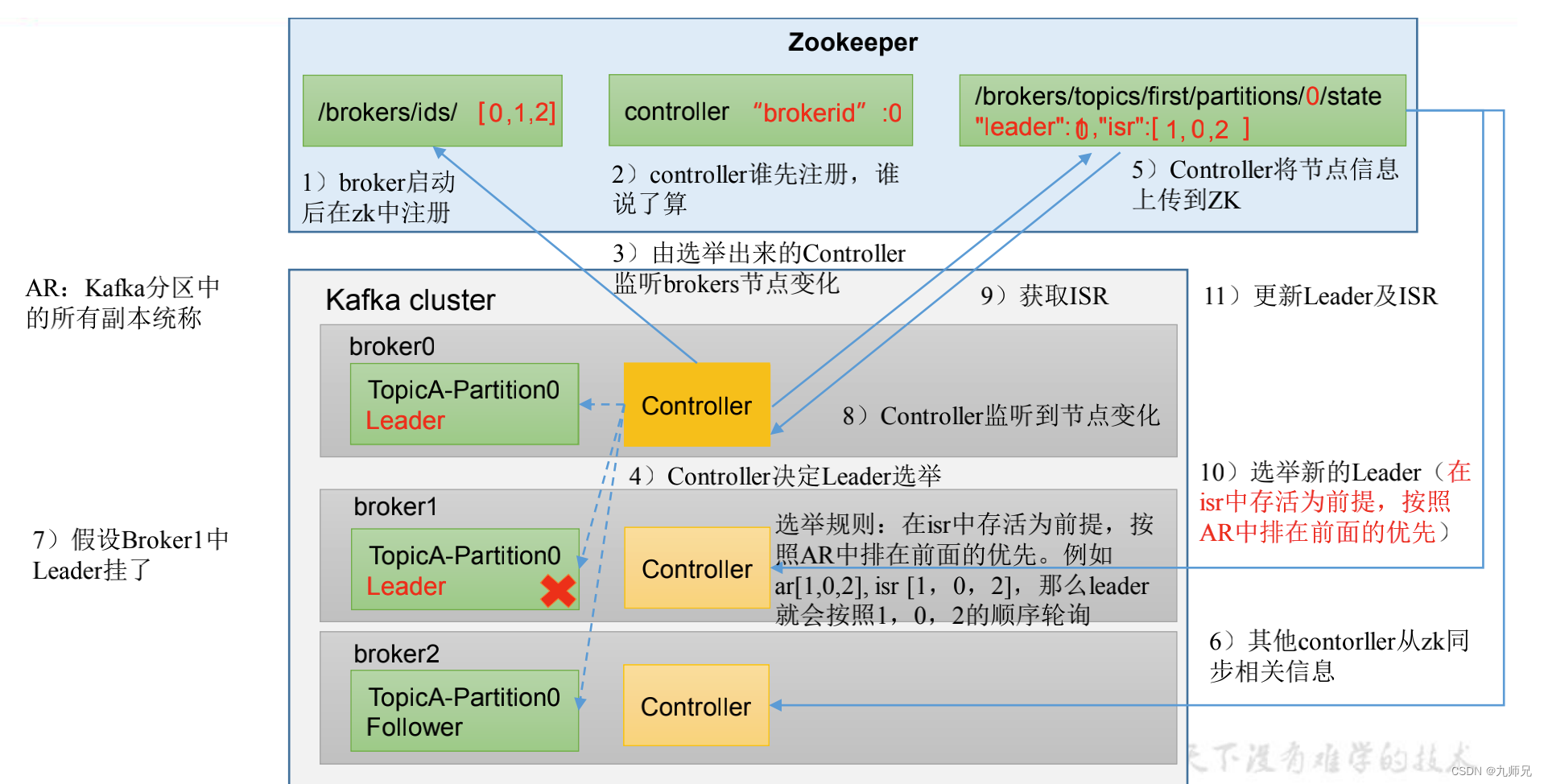
在开始源码分析之前, 大家先看下面这张图, 好让自己对Leader选举有一个非常清晰的认知,然后再去看后面的源码分析文章,会更容易理解。
Kafka 集群中有一个 broker 的 Controller 会被选举为 Controller Leader ,负责管理集群 broker 的上下线,所有 topic 的分区副本分配 和 Leader 选举等工作。
详情请看

整个流程分为三大块
触发选举场景 图左
执行选举流程 图中
Leader选举策略 图右
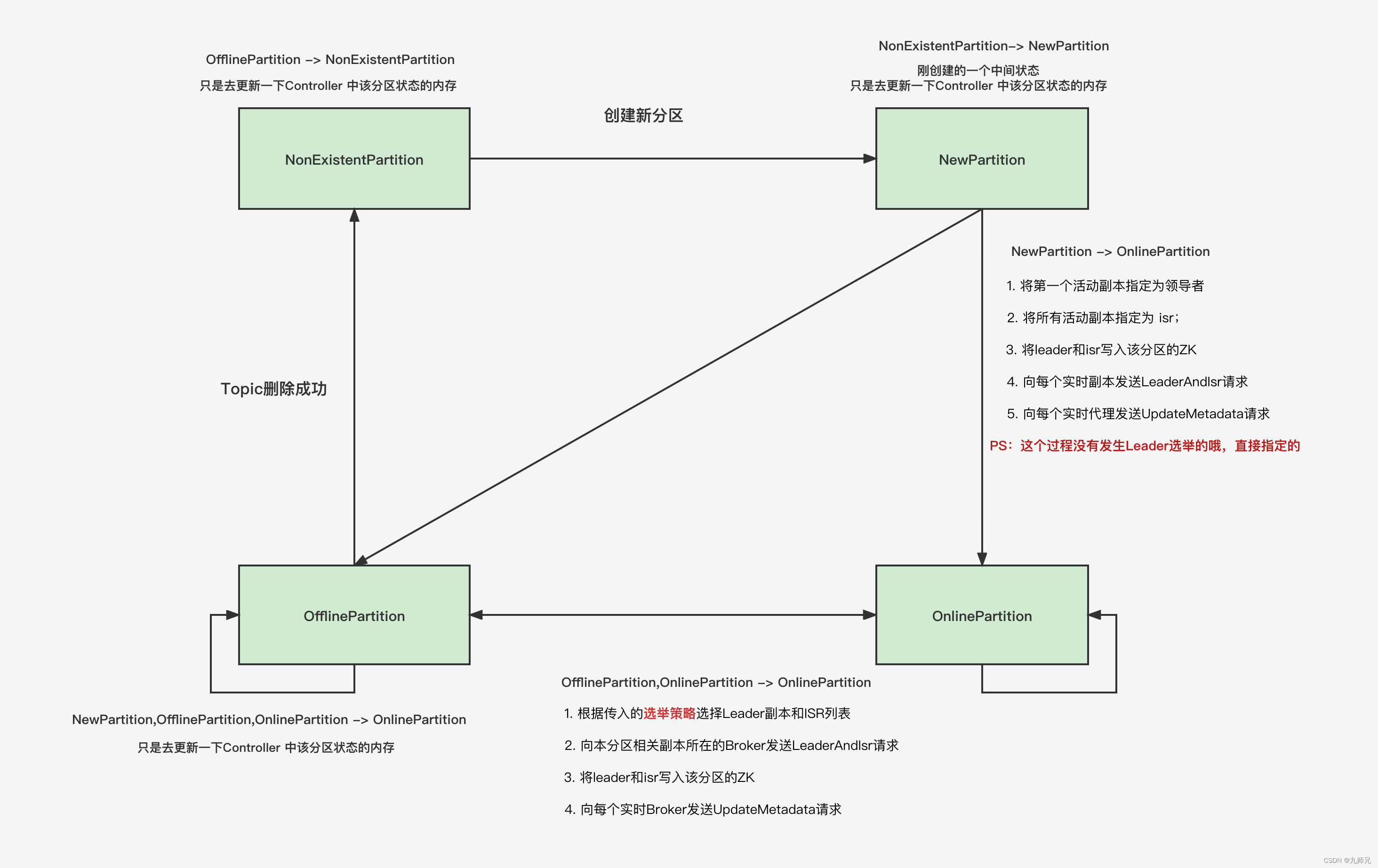
这里我们主要讲解分区状态机,这张图表示的是分区状态机
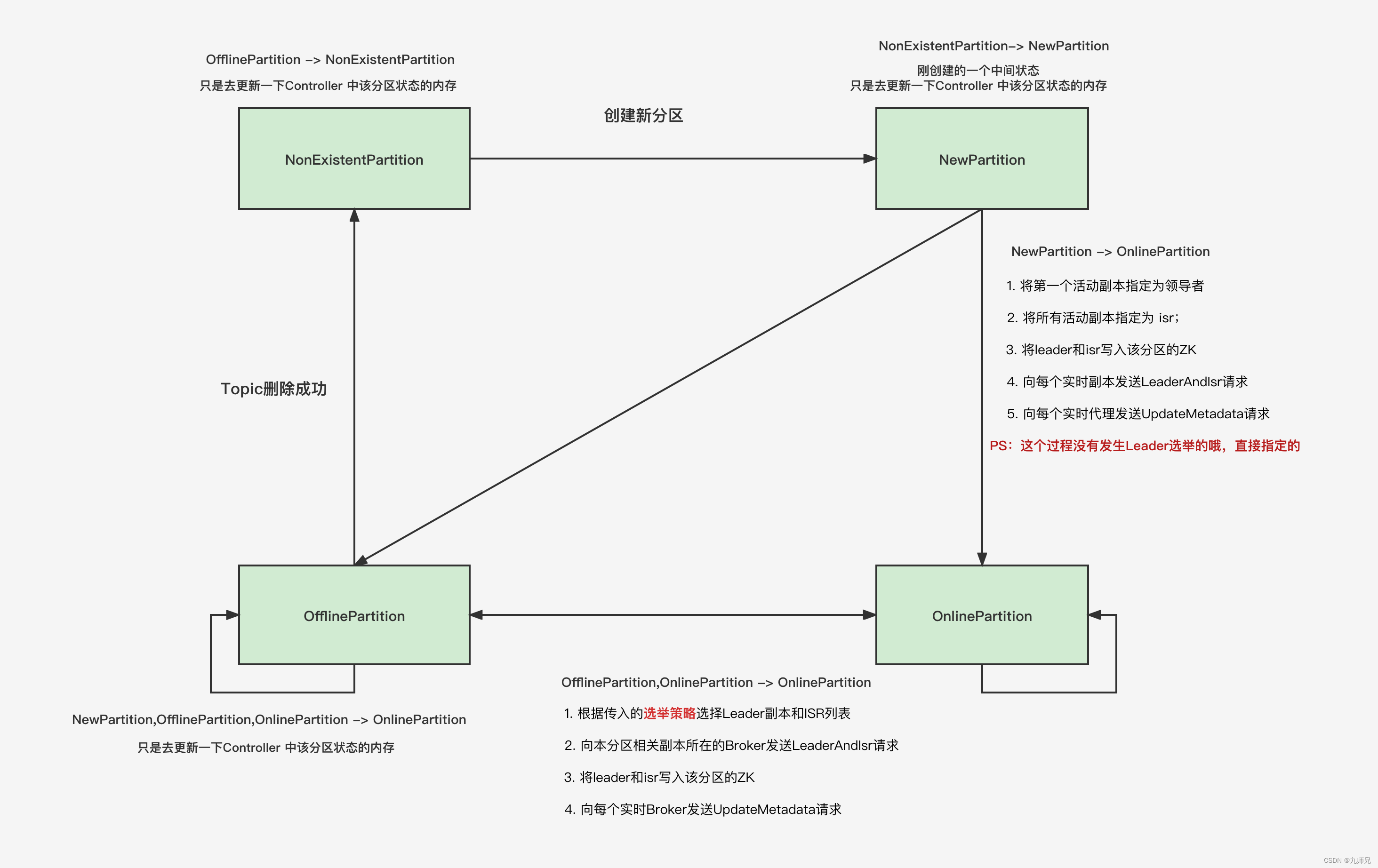
NonExistentPartition :分区在将要被创建之前的初始状态是这个,表示不存在
NewPartition: 表示正在创建新的分区, 是一个中间状态, 这个时候只是在Controller的内存中存了状态信息
OnlinePartition: 在线状态, 正常的分区就应该是这种状态,只有在线的分区才能够提供服务
OfflinePartition: 下线状态, 分区可能因为Broker宕机或者删除Topic等原因流转到这个状态, 下线了就不能提供服务了
NonExistentPartition: 分区不存在的状态, 当Topic删除完成成功之后, 就会流转到这个状态, 当还处在删除中的时候,还是停留在下线状态。
我们今天要讲的Leader选举就是在之前状态=>OnlinePartition状态的时候发生的。
4.Leader选举流程分析
源码入口:
PartitionStateMachine#electLeaderForPartitions
/**
* 状态机流转 处理
**/
private def doHandleStateChanges(
partitions: Seq[TopicPartition],
targetState: PartitionState,
partitionLeaderElectionStrategyOpt: Option[PartitionLeaderElectionStrategy]
): Map[TopicPartition, Either[Throwable, LeaderAndIsr]] = {
//不相干的代码省略了
targetState match {
// 不相干的代码省略了, 这里状态流程到 OnlinePartition
case OnlinePartition =>
// 分区状态是 OfflinePartition 或者 OnlinePartition 的话 就都需要执行一下选举策略
if (partitionsToElectLeader.nonEmpty) {
// 根据选举策略 进行选举。这里只是找出
val electionResults = electLeaderForPartitions(
partitionsToElectLeader,
partitionLeaderElectionStrategyOpt.getOrElse(
throw new IllegalArgumentException("Election strategy is a required field when the target state is OnlinePartition")
)
)
}
}
可以看到 我们最终是调用了doElectLeaderForPartitions 执行分区Leader选举。
PartitionStateMachine#doElectLeaderForPartitions
// 删除了部分无关代码
private def doElectLeaderForPartitions(
partitions: Seq[TopicPartition],
partitionLeaderElectionStrategy: PartitionLeaderElectionStrategy
): (Map[TopicPartition, Either[Exception, LeaderAndIsr]], Seq[TopicPartition]) = {
// 去zookeeper节点 /broker/topics/{topic名称}/partitions/{分区号}/state 节点读取基本信息。
val getDataResponses = try {
zkClient.getTopicPartitionStatesRaw(partitions)
}
val failedElections = mutable.Map.empty[TopicPartition, Either[Exception, LeaderAndIsr]]
val validLeaderAndIsrs = mutable.Buffer.empty[(TopicPartition, LeaderAndIsr)]
// 遍历从zk中获取的数据返回信息
getDataResponses.foreach { getDataResponse =>
val partition = getDataResponse.ctx.get.asInstanceOf[TopicPartition]
// 当前分区状态
val currState = partitionState(partition)
if (getDataResponse.resultCode == Code.OK) {
TopicPartitionStateZNode.decode(getDataResponse.data, getDataResponse.stat) match {
case Some(leaderIsrAndControllerEpoch) =>
if (leaderIsrAndControllerEpoch.controllerEpoch > controllerContext.epoch) {
//...
} else {
// 把通过校验的leaderandisr信息 保存到列表
validLeaderAndIsrs += partition -> leaderIsrAndControllerEpoch.leaderAndIsr
}
case None =>
//...
}
} else if (getDataResponse.resultCode == Code.NONODE) {
//...
} else {
//...
}
}
// 如果没有 有效的分区,则直接返回
if (validLeaderAndIsrs.isEmpty) {
return (failedElections.toMap, Seq.empty)
}
// 根据入参 传入的 选举策略 来选择Leader
val (partitionsWithoutLeaders, partitionsWithLeaders) = partitionLeaderElectionStrategy match {
// 离线分区 策略 (allowUnclean 表示的是是否允许脏副本参与选举, 如果这里是true,则忽略topic本身的unclean.leader.election.enable 配置,如果是false,则会考虑 unclean.leader.election.enable 的配置。 )
case OfflinePartitionLeaderElectionStrategy(allowUnclean) =>
// 这里就是判断allowUnclean的参数,如果这里是true,则忽略topic本身的unclean.leader.election.enable 配置,如果是false,则会考虑 unclean.leader.election.enable 的配置。因为每个topic的配置可能不一样,所以这里组装每个分区的信息和allowUnclean 返回
val partitionsWithUncleanLeaderElectionState = collectUncleanLeaderElectionState(
validLeaderAndIsrs,
allowUnclean
)
// 去选择一个合适的副本 来当选 leader。这里只是计算得到了一个值们还没有真的当选哈
leaderForOffline(controllerContext, partitionsWithUncleanLeaderElectionState).partition(_.leaderAndIsr.isEmpty)
// 分区副本重分配Leader 选举策略
case ReassignPartitionLeaderElectionStrategy =>
// 去选择一个合适的副本 来当选 leader。这里只是计算得到了一个值们还没有真的当选哈
leaderForReassign(controllerContext, validLeaderAndIsrs).partition(_.leaderAndIsr.isEmpty)
// 优先副本选举策略
case PreferredReplicaPartitionLeaderElectionStrategy =>
// 去选择一个合适的副本 来当选 leader。这里只是计算得到了一个值们还没有真的当选哈
leaderForPreferredReplica(controllerContext, validLeaderAndIsrs).partition(_.leaderAndIsr.isEmpty)
// 受控关机策略
case ControlledShutdownPartitionLeaderElectionStrategy =>
// 去选择一个合适的副本 来当选 leader。这里只是计算得到了一个值们还没有真的当选哈
leaderForControlledShutdown(controllerContext, validLeaderAndIsrs).partition(_.leaderAndIsr.isEmpty)
}
// 这里是上面策略 没有找到Leader的所有分区,遍历一下,打一个异常日志。
partitionsWithoutLeaders.foreach { electionResult =>
val partition = electionResult.topicPartition
val failMsg = s"Failed to elect leader for partition $partition under strategy $partitionLeaderElectionStrategy"
failedElections.put(partition, Left(new StateChangeFailedException(failMsg)))
}
// 整理一下上面计算得到哦的结果
val recipientsPerPartition = partitionsWithLeaders.map(result => result.topicPartition -> result.liveReplicas).toMap
val adjustedLeaderAndIsrs = partitionsWithLeaders.map(result => result.topicPartition -> result.leaderAndIsr.get).toMap
// 这里去把leader和isr的信息写入到zk中去啦 节点 /broker/topics/{topic名称}/partitions/{分区号}/state
val UpdateLeaderAndIsrResult(finishedUpdates, updatesToRetry) = zkClient.updateLeaderAndIsr(
adjustedLeaderAndIsrs, controllerContext.epoch, controllerContext.epochZkVersion)
// 遍历更新完成的分区, 然后更新Controller里面的分区leader和isr的内存信息 并发送LeaderAndISR请求
finishedUpdates.foreach { case (partition, result) =>
result.right.foreach { leaderAndIsr =>
val replicaAssignment = controllerContext.partitionFullReplicaAssignment(partition)
val leaderIsrAndControllerEpoch = LeaderIsrAndControllerEpoch(leaderAndIsr, controllerContext.epoch)
// 更新内存
controllerContext.partitionLeadershipInfo.put(partition, leaderIsrAndControllerEpoch)
// 发送LeaderAndIsr请求
controllerBrokerRequestBatch.addLeaderAndIsrRequestForBrokers(recipientsPerPartition(partition), partition,
leaderIsrAndControllerEpoch, replicaAssignment, isNew = false)
}
}
(finishedUpdates ++ failedElections, updatesToRetry)
}
总结一下上面的源码
-
去zookeeper节点 /broker/topics/{topic名称}/partitions/{分区号}/state 节点读取基本信息。
-
遍历从zk中获取的leaderIsrAndControllerEpoch信息,做一些简单的校验:zk中获取的数据的controllerEpoch必须<=当前的Controller的controller_epoch。最终得到 validLeaderAndIsrs, controller_epoch 就是用来防止脑裂的, 当有两个Controller当选的时候,他们的epoch肯定不一样, 那么最新的epoch才是真的Controller
-
如果没有获取到有效的validLeaderAndIsrs 信息 则直接返回
-
根据入参partitionLeaderElectionStrategy 来匹配不同的Leader选举策略。来选出合适的Leader和ISR信息
-
根据上面的选举策略选出的 LeaderAndIsr 信息进行遍历, 将它们一个个写入到zookeeper节点/broker/topics/{topic名称}/partitions/{分区号}/state中。 (当然如果上面没有选择出合适的leader,那么久不会有这个过程了)
注意:当没有选出Leader的时候,那么是不会去更新ZK中的Leader和ISR信息的。
那么你应该会问,这种情况下Leader没有选出,那么就应该更新为-1呀!那么是在什么时候去更新的呢? -
遍历上面写入zk成功的分区, 然后更新Controller里面的分区leader和isr的内存信息 并发送LeaderAndISR请求,通知对应的Broker Leader更新了。
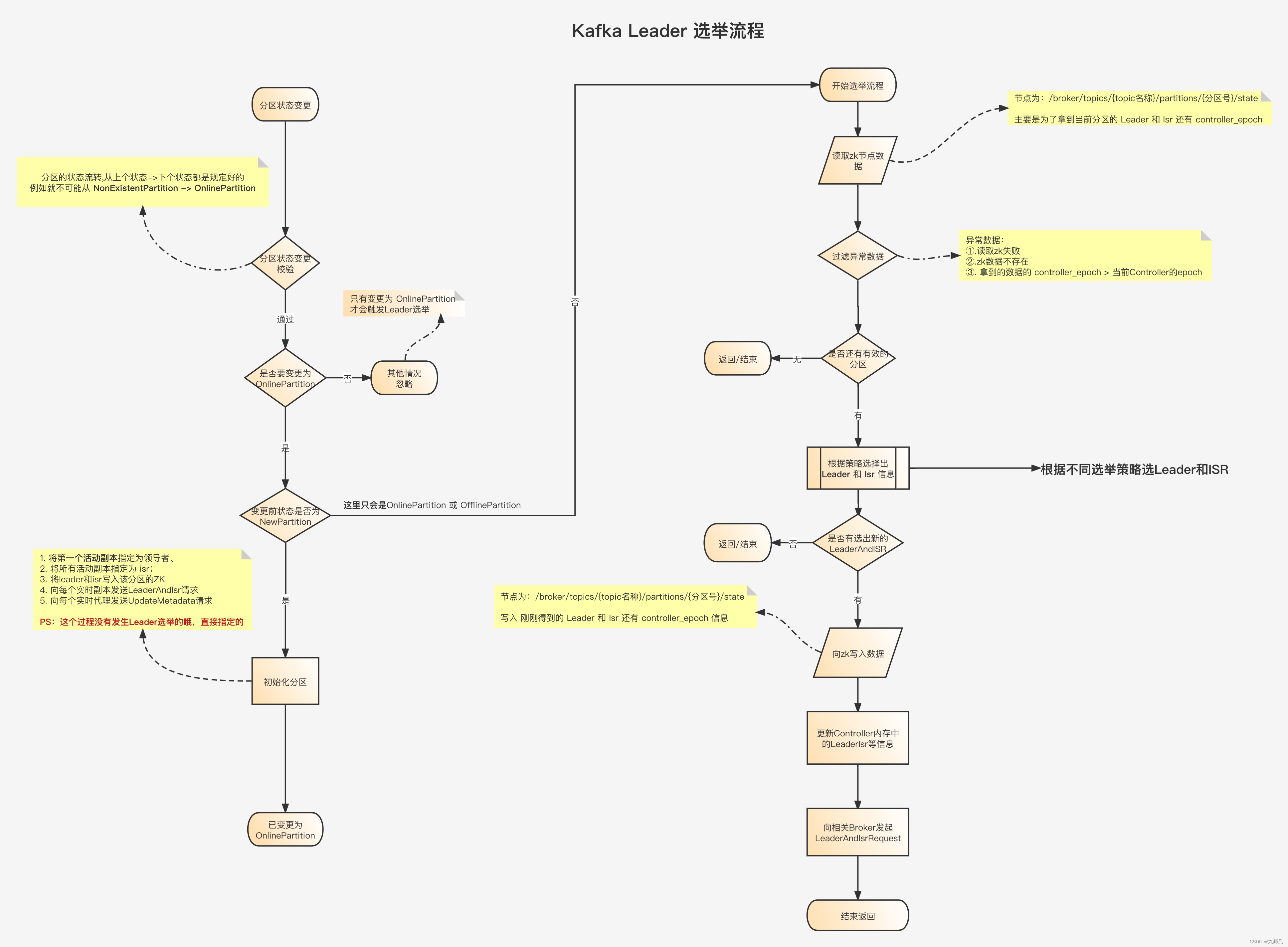
注意: 当没有选出Leader的时候,那么是不会去更新ZK中的Leader和ISR信息的。
那么你应该会问,这种情况下Leader没有选出,那么就应该更新为-1呀!那么是在什么时候去更新的呢?
上面我们只是分析了Leader选举的流程,但是在调用的地方是分区状态的流转触发了Leader选举。
分区状态有流转那么就会伴随着副本的状态流转。比如 副本状态流转到 OfflineReplica
副本离线的时候就有可能触发我们去更新 zk中的节点信息
KafkaController#onReplicasBecomeOffline
private def onReplicasBecomeOffline(newOfflineReplicas: Set[PartitionAndReplica]): Unit = {
//省略部分。。。
// 这里触发分区状态流程
partitionStateMachine.triggerOnlinePartitionStateChange()
// 副本状态流转到OfflineReplica
replicaStateMachine.handleStateChanges(newOfflineReplicasNotForDeletion.toSeq, OfflineReplica)
}
下面的关机代码就是更新zk节点数据的计算方式
ReplicaStateMachine#doRemoveReplicasFromIsr
val adjustedLeaderAndIsrs: Map[TopicPartition, LeaderAndIsr] = leaderAndIsrsWithReplica.flatMap {
case (partition, result) =>
result.toOption.map { leaderAndIsr =>
val newLeader = if (replicaId == leaderAndIsr.leader) LeaderAndIsr.NoLeader else leaderAndIsr.leader
val adjustedIsr = if (leaderAndIsr.isr.size == 1) leaderAndIsr.isr else leaderAndIsr.isr.filter(_ != replicaId)
partition -> leaderAndIsr.newLeaderAndIsr(newLeader, adjustedIsr)
}
}
从代码我们可以看出来, 当 :
当前要离线的副本==Leader, 那么这个新Leader == -1;否则新Leader还是等于原Leader
当Isr的数量只剩下1个的时候,那么ISR等于原ISR,否则新ISR=(原ISR-当前的被离线的副本)
这里的逻辑是不是就解释清楚了我们一开始的问题
什么时候Leader会设置为-1
看上面的Leader选举策略是不是很简单, 总结一下就是:
分区状态变更, 分区状态变更的时候会触发Leader选举,选举成功会去zk修改节点brokers/topics/{Topic}/partitions/{分区}/state值
分区状态变更,一般伴随着副本状态的变更,副本状态的变更也会触发去修改zk节点 brokers/topics/{Topic}/partitions/{分区}/state
一般如果Leader选举的时候选举出来了新的LeaderAndISR,那么副本变更的时候修改zk的值基本不变。
但是如果Leader选举的时候没有选举LeaderAndIsr,那么在副本状态变更这一步骤
就会将zk节点的leader设置为-1. 设置的逻辑就是上面提过的:
当前要离线的副本==Leader, 那么这个新Leader == -1;否则新Leader还是等于原Leader
当Isr的数量只剩下1个的时候,那么ISR等于原ISR,否则新ISR=(原ISR-当前的被离线的副本)
上面分析了Leader选举策略流程,但是中间究竟是如何选择Leader的?
这个是根据传入的策略类型, 来做不同的选择
那么有哪些策略呢?以及什么时候触发这些选举呢?
5.分区的几种策略以及对应的触发场景
- OfflinePartitionLeaderElectionStrategy
遍历分区的AR, 找到第一个满足以下条件的副本:
副本在线
在ISR中。
如果找不到满足条件的副本,那么再根据 传入的参数allowUnclean判断
allowUnclean=true:AR顺序中所有在线副本中的第一个副本。
allowUnclean=false: 需要去查询配置 unclean.leader.election.enable 的值。
若=true ,则跟上面 1一样 。
若=false,直接返回None,没有找到合适的Leader。
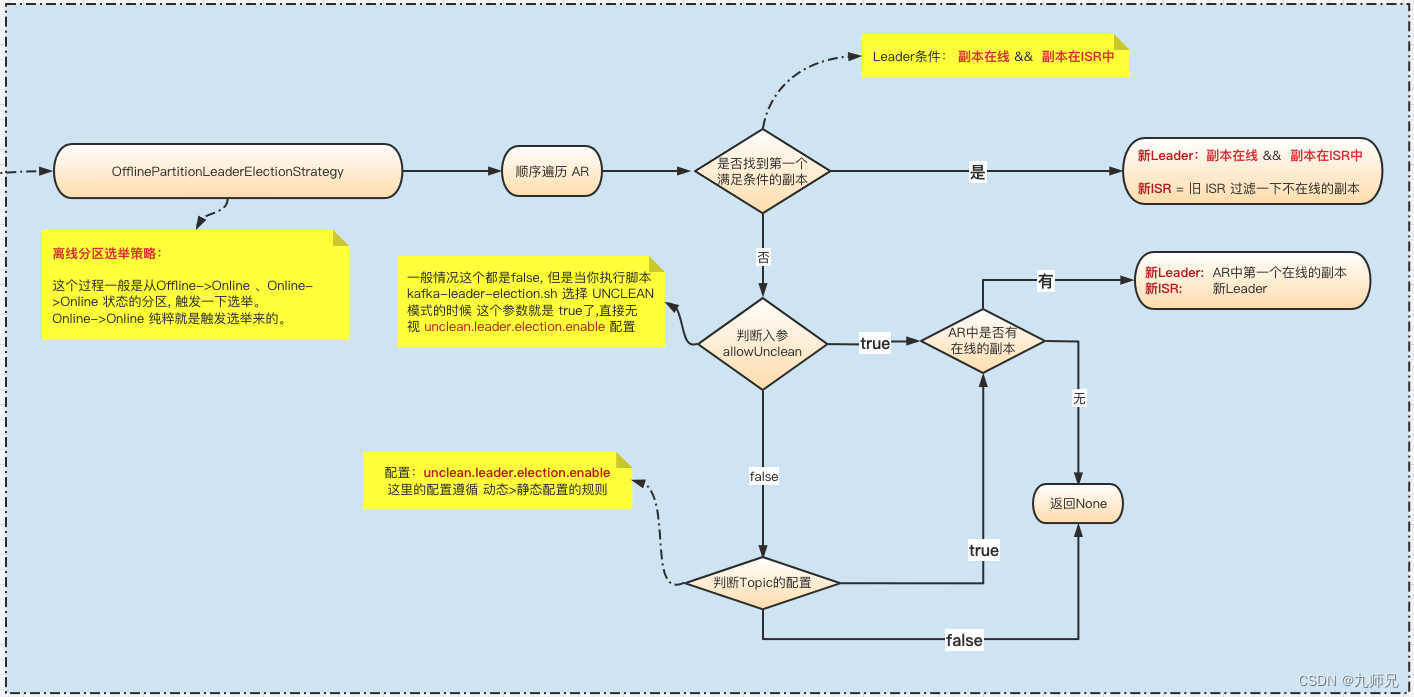
源码位置:
Election#leaderForOffline
触发场景:脚本执行脏选举
当执行 kafka-leader-election.sh 的时候并且 模式选择的是UNCLEAN . 则会触发这个模式。
这里注意一下,入参allowUnclean = (electionTrigger == AdminClientTriggered)
意思是: 当触发的场景是AdminClientTriggered的时候, 则allowUnclean=true,表示 不关心配置参数 unclean.leader.election.enable 是什么, 如果没有找到符合条件的Leader, 则就去非ISR 列表找Leader。
刚好 我能脚本执行的时候 触发器就是 AdminClientTriggered
其他触发器有:
AutoTriggered : 定时自动触发。
ZkTriggered:Controller切换的时候触发的(zk节点/controller 的变更便是Controller角色的切换)
AdminClientTriggered:客户端主动触发。
触发场景:Controller 监听到有Broker启动了
同上。
触发源码入口:
KafkaController#processBrokerChange#onBrokerStartup
partitionStateMachine.triggerOnlinePartitionStateChange()
触发场景:Controller 监听 LeaderAndIsrResponseReceived请求
同上。
当Controller向对应的Broker发起 LeaderAndIsrRequest 请求的时候.
有一个回调函数callback, 这个回调函数会向Controller发起一个事件为 LeaderAndIsrResponseReceived 请求。
具体源码在:
ControllerChannelManager#sendLeaderAndIsrRequest

Controller收到这个事件的请求之后,根据返回的 leaderAndIsrResponse 数据
会判断一下有没有新增加的离线副本(一般都是由于磁盘访问有问题)
如果有新的离线副本,则需要将这个离线副本标记为Offline状态
触发场景:Broker宕机,Controller监听到了变更
源码入口:
KafkaController#onReplicasBecomeOffline
partitionStateMachine.triggerOnlinePartitionStateChange()
这里会先找那些Leader副本已经离线了或者正在等待关机的Broker中的副本。
然后对这些分区触发状态变更,将他们的分区状态变成离线状态 也就是:OfflinePartition
再调用partitionStateMachine.triggerOnlinePartitionStateChange() 就会对上述分区重新选举了。
或许你会问:
为啥Broker关机的时候会执行两次选举策略?一个是ControlledShutdownPartitionLeaderElectionStrategy,接着就是OfflinePartitionLeaderElectionStrategy。
其实执行两次选举并不冲突! 第一次一个是ControlledShutdownPartitionLeaderElectionStrategy 选举会将大部分的分区成功切换到新的Leader。 但是对于如果刚好副本数量==1的话,是不会执行ControlledShutdownPartitionLeaderElectionStrategy策略选举的。
并且当broker的配置 controlled.shutdown.enable=false. 那么这里的受控关机选举策略就不会执行了。
接下来就是执行OfflinePartitionLeaderElectionStrategy选举策略, 补充一下上述没有成功切换的分区。
加szzdzhp001,领取全部kafka知识图谱
触发场景:Controller 监听 UncleanLeaderElectionEnable请求
当我们在修改动态配置的时候, 将动态配置:unclean.leader.election.enable设置为 true 的时候
会触发向Controller发起UncleanLeaderElectionEnable的请求,这个时候则需要触发一下。触发请求同上。
触发源码入口:
KafkaController#processTopicUncleanLeaderElectionEnable
partitionStateMachine.triggerOnlinePartitionStateChange(topic)
上面的触发调用的代码就是下面的接口
对处于 NewPartition 或 OfflinePartition 状态的所有分区尝试变更为
OnlinePartition 的状态。 状态的流程触发了Leader选举。
SCALA
/**
* 此 API 对处于 NewPartition 或 OfflinePartition 状态的所有分区尝试变更为
* OnlinePartition 状态的状态。 这在成功的控制器选举和代理更改时调用
*/
def triggerOnlinePartitionStateChange(): Unit = {
// 获取所有 OfflinePartition 、NewPartition 的分区状态
val partitions = controllerContext.partitionsInStates(Set(OfflinePartition, NewPartition))
triggerOnlineStateChangeForPartitions(partitions)
}
private def triggerOnlineStateChangeForPartitions(partitions: collection.Set[TopicPartition]): Unit = {
// 尝试将 所有 NewPartition or OfflinePartition 状态的分区全部转别成 OnlinePartition状态,
//但是除了那个分区所对应的Topic正在被删除的所有分区
val partitionsToTrigger = partitions.filter { partition =>
!controllerContext.isTopicQueuedUpForDeletion(partition.topic)
}.toSeq
// 分区状态机进行状态流转 使用 OfflinePartitionLeaderElectionStrategy 选举策略(allowUnclean =false 不允许 不在isr中的副本参与选举)
handleStateChanges(partitionsToTrigger, OnlinePartition, Some(OfflinePartitionLeaderElectionStrategy(false)))
}
获取所有 OfflinePartition 、NewPartition 的分区状态
尝试将 所有 NewPartition or OfflinePartition 状态的分区全部转别成 OnlinePartition状态,
但是如果对应的Topic正在删除中,则会被排除掉
分区状态机进行状态流转 使用 OfflinePartitionLeaderElectionStrategy 选举策略(allowUnclean=true 表示如果从isr中没有选出leader,则允许从非isr列表中选举leader ,allowUnclean=false 表示如果从isr中没有选出leader, 则需要去读取配置文件的配置 unclean.leader.election.enable 来决定是否允许从非ISR列表中选举Leader。 )
加szzdzhp001,领取全部kafka知识图谱
- ReassignPartitionLeaderElectionStrategy
分区副本重分配选举策略:
当执行分区副本重分配的时候, 原来的Leader可能有变更, 则需要触发一下 Leader选举。
只有当之前的Leader副本在经过重分配之后不存在了。
例如: [2,0] ==> [1,0] 。 原来2是Leader副本,经过重分配之后变成了 [1,0]。2已经不复存在了,所以需要重新选举Leader。
当原来的分区Leader副本 因为某些异常,下线了。需要重新选举Leader
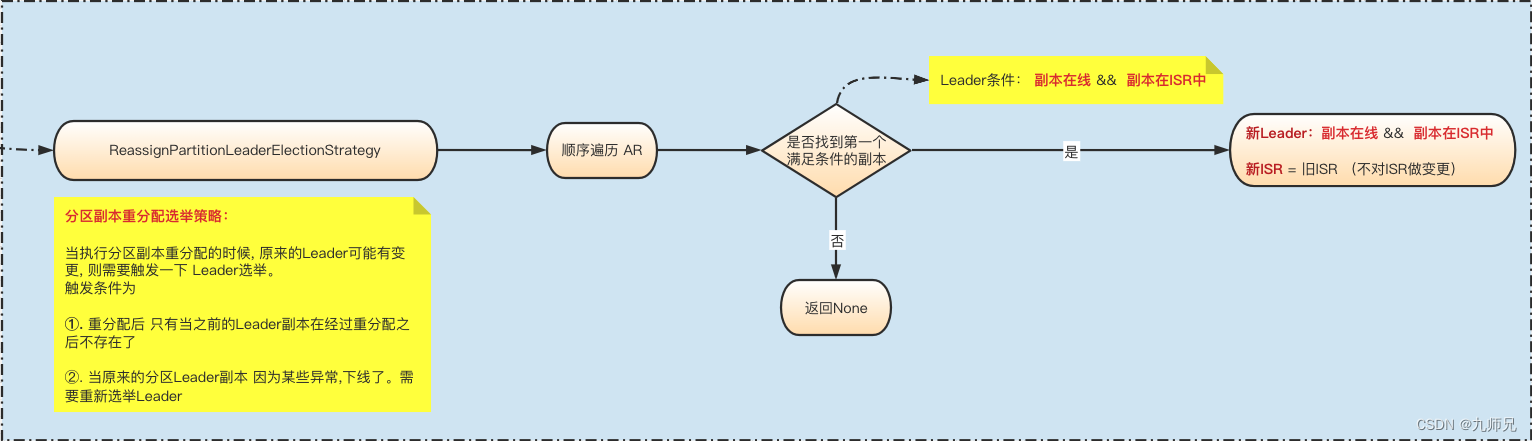
分区副本重分配发生的Leader选举.
Election#leaderForReassign
private def leaderForReassign(partition: TopicPartition,
leaderAndIsr: LeaderAndIsr,
controllerContext: ControllerContext): ElectionResult = {
// 从Controller的内存中获取当前分区的分配情况, 然后跟 removingReplicas(表示当前重分配需要移除掉的副本) 取差集。也就获取当重分配之后剩下的所有副本分配情况了。
val targetReplicas = controllerContext.partitionFullReplicaAssignment(partition).targetReplicas
// 过滤一下不在线的副本。
val liveReplicas = targetReplicas.filter(replica => controllerContext.isReplicaOnline(replica, partition))
// 这里的isr 是从外部传参进来的, 是去zk节点 /brokers/topics/{topic名称}/partitions/{分区号}/state 中拿取的数据,而不是当前内存中拿到的
val isr = leaderAndIsr.isr
// 在上面的targetReplicas中找到符合条件的第一个元素:副本必须在线, 副本必须在ISR中。
val leaderOpt = PartitionLeaderElectionAlgorithms.reassignPartitionLeaderElection(targetReplicas, isr, liveReplicas.toSet)
// 构造一下 上面拿到的Leader参数, 组装成一个LeaderAndIsr对象,对象多组装了例如:leaderEpoch+1, zkVersion 等等
val newLeaderAndIsrOpt = leaderOpt.map(leader => leaderAndIsr.newLeader(leader))
ElectionResult(partition, newLeaderAndIsrOpt, targetReplicas)
}
// 这个算法就是找到 第一个 符合条件:副本在线,副本在ISR中 的副本。用于遍历的reassignment就是我们上面的targetReplicas,是从内存中获取的。也就是变更后的副本顺序了。那么就是获取了第一个副本啦
def reassignPartitionLeaderElection(reassignment: Seq[Int], isr: Seq[Int], liveReplicas: Set[Int]): Option[Int] = {
reassignment.find(id => liveReplicas.contains(id) && isr.contains(id))
}
总结:
从当前的副本分配列表中,获取副本在线&&副本在ISR中的 第一个副本,遍历的顺序是当前副本的分配方式(AR),跟ISR的顺序没有什么关系。
加szzdzhp001,领取全部kafka知识图谱
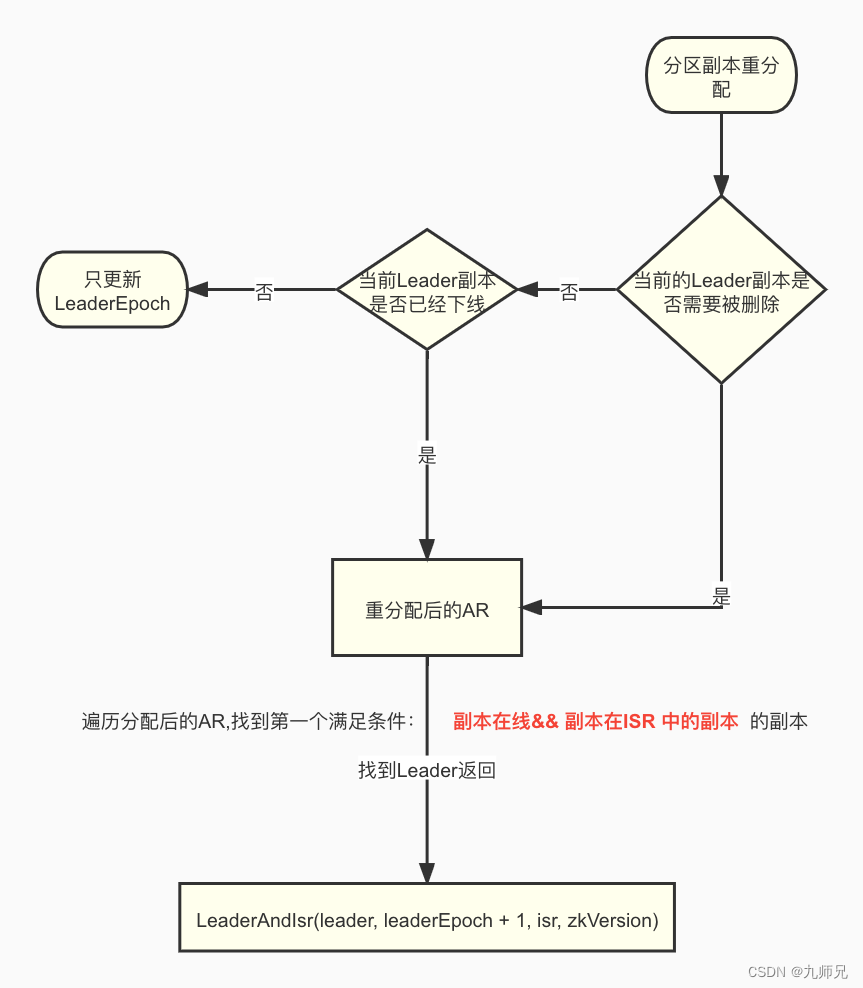
触发场景:分区副本重分配
并不是每次执行分区副本重分配都会触发这个Leader选举策略, 下面两种情况才会触发
只有当之前的Leader副本在经过重分配之后不存在了。例如: [2,0] ==> [1,0] 。 原来2是Leader副本,经过重分配之后变成了 [1,0]。2已经不复存在了,所以需要重新选举Leader。
当原来的分区Leader副本 因为某些异常,下线了。需要重新选举Leader
对应的判断条件代码如下:
KafkaController#moveReassignedPartitionLeaderIfRequired
private def moveReassignedPartitionLeaderIfRequired(topicPartition: TopicPartition,
newAssignment: ReplicaAssignment): Unit = {
// 重分配之后的所有副本
val reassignedReplicas = newAssignment.replicas
//当前的分区Leader是哪个
val currentLeader = controllerContext.partitionLeadershipInfo(topicPartition).leaderAndIsr.leader
// 如果分配后的副本不包含当前Leader副本,则需要重新选举
if (!reassignedReplicas.contains(currentLeader)) {
//触发Leader重选举,策略是ReassignPartitionLeaderElectionStrategy
partitionStateMachine.handleStateChanges(Seq(topicPartition), OnlinePartition, Some(ReassignPartitionLeaderElectionStrategy))
} else if (controllerContext.isReplicaOnline(currentLeader, topicPartition)) {
// 上面2种情况都不符合, 那么就没有必要leader重选举了, 更新一下leaderEpoch就行 了
updateLeaderEpochAndSendRequest(topicPartition, newAssignment)
} else {
//触发Leader重选举,策略是ReassignPartitionLeaderElectionStrategy
partitionStateMachine.handleStateChanges(Seq(topicPartition), OnlinePartition, Some(ReassignPartitionLeaderElectionStrategy))
}
}
3. PreferredReplicaPartitionLeaderElectionStrategy
优先副本选举策略, 必须满足三个条件:
是第一个副本&&副本在线&&副本在ISR列表中。
满足上面三个条件才会当选leader,不满足则不会做变更。
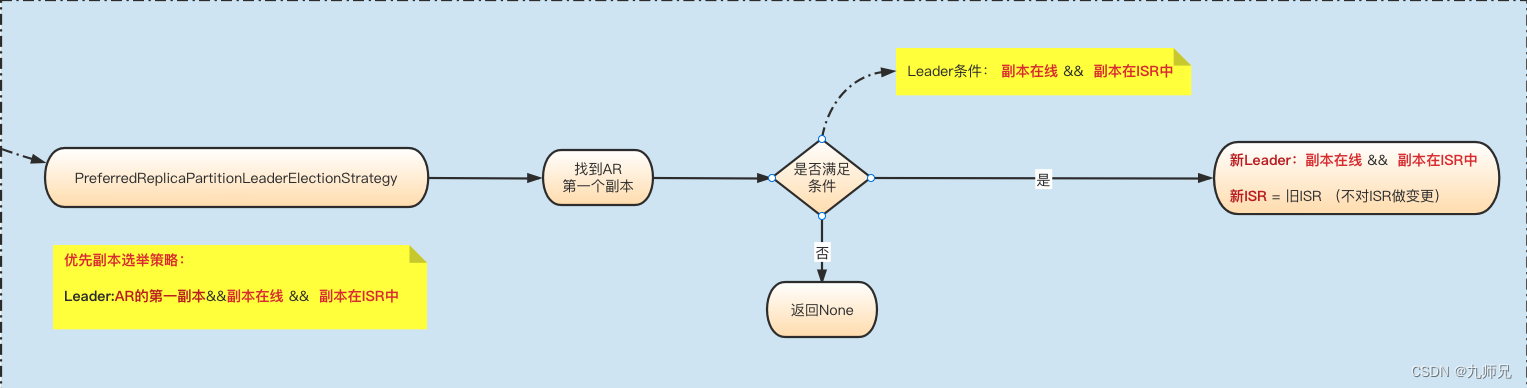
def leaderForPreferredReplica(controllerContext: ControllerContext,
leaderAndIsrs: Seq[(TopicPartition, LeaderAndIsr)]): Seq[ElectionResult] = {
leaderAndIsrs.map { case (partition, leaderAndIsr) =>
leaderForPreferredReplica(partition, leaderAndIsr, controllerContext)
}
}
private def leaderForPreferredReplica(partition: TopicPartition,
leaderAndIsr: LeaderAndIsr,
controllerContext: ControllerContext): ElectionResult = {
// AR列表
val assignment = controllerContext.partitionReplicaAssignment(partition)
// 在线副本
val liveReplicas = assignment.filter(replica => controllerContext.isReplicaOnline(replica, partition))
val isr = leaderAndIsr.isr
// 找出第一个副本 是否在线 并且在ISR中。
val leaderOpt = PartitionLeaderElectionAlgorithms.preferredReplicaPartitionLeaderElection(assignment, isr, liveReplicas.toSet)
// 组装leaderandisr返回 ,注意这里是没有修改ISR信息的
val newLeaderAndIsrOpt = leaderOpt.map(leader => leaderAndIsr.newLeader(leader))
ElectionResult(partition, newLeaderAndIsrOpt, assignment)
}
def preferredReplicaPartitionLeaderElection(assignment: Seq[Int], isr: Seq[Int], liveReplicas: Set[Int]): Option[Int] = {
assignment.headOption.filter(id => liveReplicas.contains(id) && isr.contains(id))
}
从内存中获取TopicPartition的分配方式
过滤不在线的副本
找到第一个副本判断一下是否在线&&在ISR列表中。如果满足,则选他为leader,如果不满足,也不会再找其他副本了。
返回leaderAndIsr信息, 这里的ISR是没有做修改的。
加szzdzhp001,领取全部kafka知识图谱
触发场景:自动定时执行优先副本选举任务
Controller 启动的时候,会启动一个定时任务 。每隔一段时间就去执行 优先副本选举任务。
与之相关配置:
## 如果为true表示会创建定时任务去执行 优先副本选举,为false则不会创建
auto.leader.rebalance.enable=true
## 每隔多久执行一次 ; 默认300秒;
leader.imbalance.check.interval.seconds partition = 300
##标识每个 Broker 失去平衡的比率,如果超过该比率,则执行重新选举 Broker 的 leader;默认比例是10%;
##这个比率的算法是 :broker不平衡率=非优先副本的leader个数/总分区数,
##假如一个topic有3个分区[0,1,2],并且有3个副本 ,正常情况下,[0,1,2]分别都为一个leader副本; 这个时候 0/3=0%;
leader.imbalance.per.broker.percentage = 10
触发场景: Controller 重新加载的时候
在这个触发之前还有执行
partitionStateMachine.startup()
相当于是先把 OfflinePartition、NewPartition状态的分区执行了OfflinePartitionLeaderElectionStrategy 策略。
然后又执行了
PreferredReplicaPartitionLeaderElectionStrategy策略
这里是从zk节点 /admin/preferred_replica_election 读取数据, 来进行判断是否有需要执行Leader选举的分区
它是在执行kafka-preferred-replica-election 命令的时候会创建这个zk节点
但是这个已经被标记为废弃了,并且在3.0的时候直接移除了。
源码位置:
KafkaController#onControllerFailover
// 从zk节点/admin/preferred_replica_election找到哪些符合条件需要执行优先副本选举的分区
val pendingPreferredReplicaElections = fetchPendingPreferredReplicaElections()
// 这里的触发类型 是 ZkTriggered
onReplicaElection(pendingPreferredReplicaElections, ElectionType.PREFERRED, ZkTriggered)
private def fetchPendingPreferredReplicaElections(): Set[TopicPartition] = {
// 去zk读取节点 /admin/preferred_replica_election
val partitionsUndergoingPreferredReplicaElection = zkClient.getPreferredReplicaElection
// 如果指定分区的 leader 已经是AR的第一个副本 或者 topic被删除了,则 过滤掉这个分区(没有必要执行leader选举了)
val partitionsThatCompletedPreferredReplicaElection = partitionsUndergoingPreferredReplicaElection.filter { partition =>
val replicas = controllerContext.partitionReplicaAssignment(partition)
val topicDeleted = replicas.isEmpty
val successful =
if (!topicDeleted) controllerContext.partitionLeadershipInfo(partition).leaderAndIsr.leader == replicas.head else false
successful || topicDeleted
}
// 将zk获取到的分区数据 - 刚刚需要忽略的数据 = 还需要执行选举的数据
val pendingPreferredReplicaElectionsIgnoringTopicDeletion = partitionsUndergoingPreferredReplicaElection -- partitionsThatCompletedPreferredReplicaElection
// 找到哪些分区正在删除
val pendingPreferredReplicaElectionsSkippedFromTopicDeletion = pendingPreferredReplicaElectionsIgnoringTopicDeletion.filter(partition => topicDeletionManager.isTopicQueuedUpForDeletion(partition.topic))
// 待删除的分区也过滤掉
val pendingPreferredReplicaElections = pendingPreferredReplicaElectionsIgnoringTopicDeletion -- pendingPreferredReplicaElectionsSkippedFromTopicDeletion
// 返回最终需要执行优先副本选举的数据。
pendingPreferredReplicaElections
}
触发场景:执行优先副本选举脚本的时候
执行脚本 kafka-leader-election.sh 并且选择的模式是 PREFERRED (优先副本选举)
则会选择 PreferredReplicaPartitionLeaderElectionStrategy 策略选举
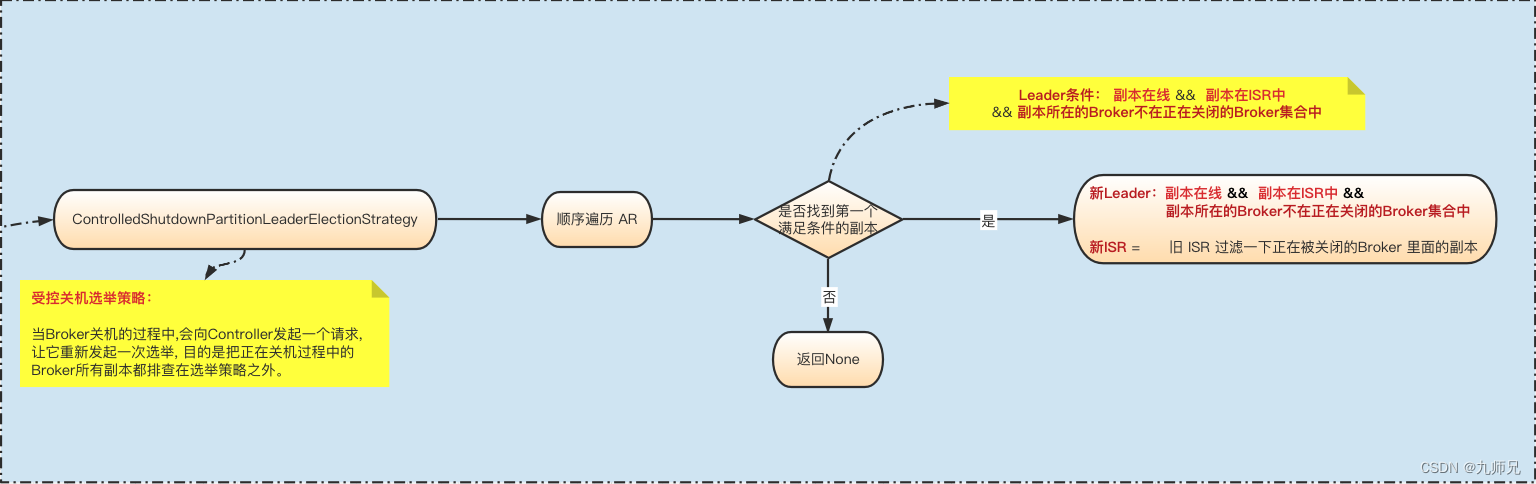
- ControlledShutdownPartitionLeaderElectionStrategy
受控关机选举策略 :
当Broker关机的过程中,会向Controller发起一个请求, 让它重新发起一次选举, 把在所有正在关机(也就是发起请求的那个Broker,或其它同时正在关机的Broker) 的Broker里面的副本给剔除掉。
根据算法算出leader:找到第一个满足条件的副本:
副本在线 && 副本在ISR中 && 副本所在的Broker不在正在关闭的Broker集合中 。
构造新的ISR列表: 在之前的isr列表中将 正在被关闭的Broker里面的副本 给剔除掉
Election#leaderForControlledShutdown
/**
** 为当前领导者正在关闭的分区选举领导者。
* 参数:
* controllerContext – 集群当前状态的上下文
* leaderAndIsrs – 表示需要选举的分区及其各自的领导者/ISR 状态的元组序列
* 返回:选举结果
**/
def leaderForControlledShutdown(controllerContext: ControllerContext,
leaderAndIsrs: Seq[(TopicPartition, LeaderAndIsr)]): Seq[ElectionResult] = {
// 当前正在关闭的 BrokerID
val shuttingDownBrokerIds = controllerContext.shuttingDownBrokerIds.toSet
// 根据策略选出leader
leaderAndIsrs.map { case (partition, leaderAndIsr) =>
leaderForControlledShutdown(partition, leaderAndIsr, shuttingDownBrokerIds, controllerContext)
}
}
}
private def leaderForControlledShutdown(partition: TopicPartition,
leaderAndIsr: LeaderAndIsr,
shuttingDownBrokerIds: Set[Int],
controllerContext: ControllerContext): ElectionResult = {
// 当前分区副本分配情况
val assignment = controllerContext.partitionReplicaAssignment(partition)
// 找到当前分区所有存活的副本(正在关闭中的Broker里面的副本也要算进去)
val liveOrShuttingDownReplicas = assignment.filter(replica =>
controllerContext.isReplicaOnline(replica, partition, includeShuttingDownBrokers = true))
val isr = leaderAndIsr.isr
// 根据算法算出leader:找到第一个满足条件的副本: 副本在线&& 副本在ISR中 && 副本所在的Broker不在正在关闭的Broker集合中。
val leaderOpt = PartitionLeaderElectionAlgorithms.controlledShutdownPartitionLeaderElection(assignment, isr,
liveOrShuttingDownReplicas.toSet, shuttingDownBrokerIds)
//构造新的ISR列表,在之前的isr列表中将 正在被关闭的Broker 里面的副本给剔除掉
val newIsr = isr.filter(replica => !shuttingDownBrokerIds.contains(replica))
//构造leaderAndIsr 加上 zkVersion 和 leader_epoch
val newLeaderAndIsrOpt = leaderOpt.map(leader => leaderAndIsr.newLeaderAndIsr(leader, newIsr))
ElectionResult(partition, newLeaderAndIsrOpt, liveOrShuttingDownReplicas)
}
// 根据算法算出leader:找到第一个副本条件的副本: 副本在线&& 副本在ISR中 && 副本所在的Broker不在正在关闭的Broker集合中。
def controlledShutdownPartitionLeaderElection(assignment: Seq[Int], isr: Seq[Int], liveReplicas: Set[Int], shuttingDownBrokers: Set[Int]): Option[Int] = {
assignment.find(id => liveReplicas.contains(id) && isr.contains(id) && !shuttingDownBrokers.contains(id))
}
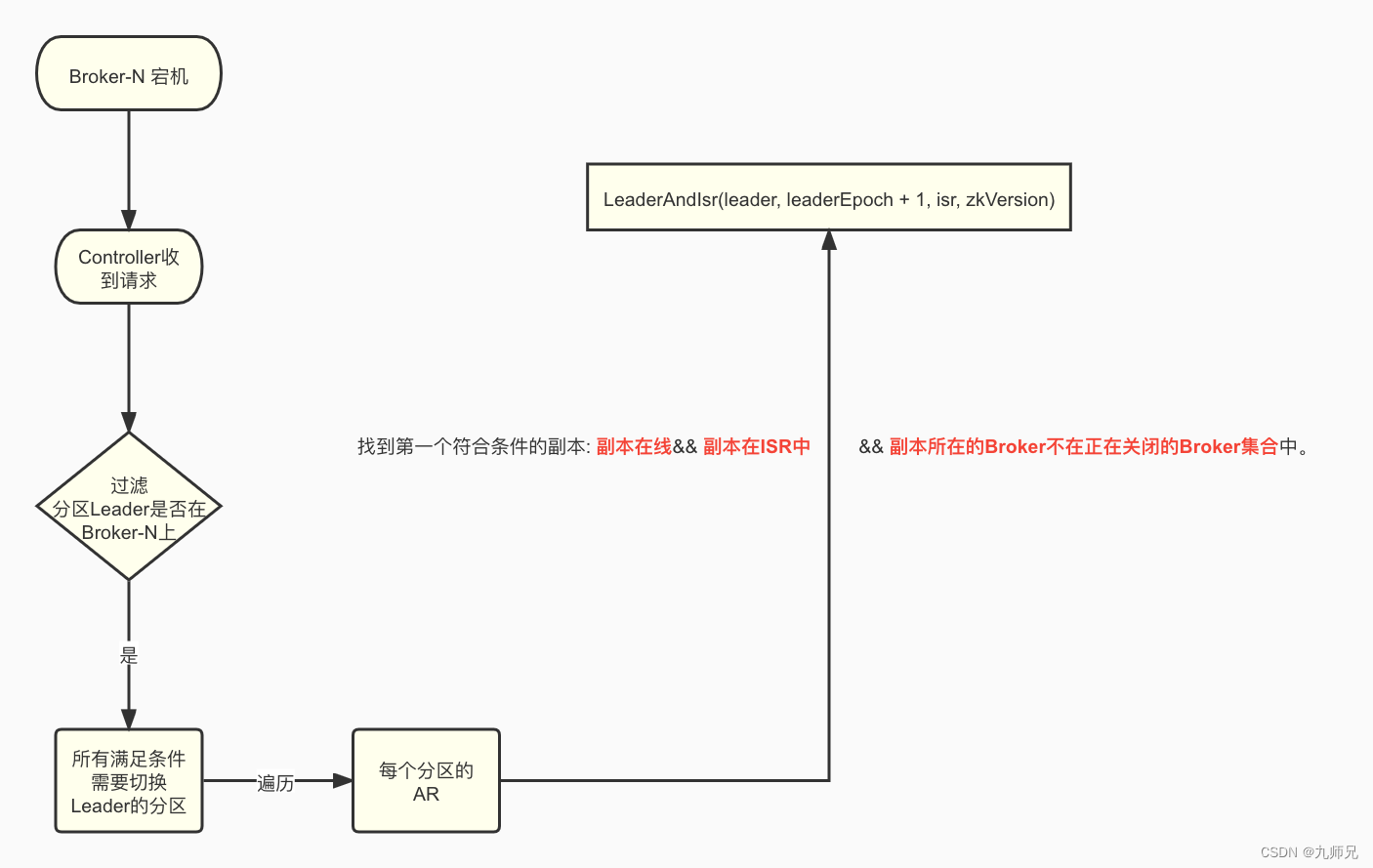
触发场景:Broker关机的时候
当Broker关闭的时候, 会向Controller发一起一个ControlledShutdownRequest请求, Controller收到这个请求会针对性的做一些善后事件。比如说 执行Leader重选举 等等之类的。
这里的选举会将副本数量==1的分区给过滤掉,不会对它进行重选举
源码位置:KafkaServer#controlledShutdown
Controller收到请求的源码位置:KafkaController#doControlledShutdown
与之相关的配置有:
controlled.shutdown.enable : 是否启用受控关闭操作
controlled.shutdown.max.retries 受控关机操作 最大重试的次数
controlled.shutdown.retry.backoff.ms 失败后等等多久再次重试
其他场景
新创建的Topic Leader选举策略
创建新的Topic的时候,并没有发生Leader选举的操作, 而是默认从分区对应的所有在线副本中选择第一个为leader, 然后isr就为 所有在线副本,再组装一下当前的controller_epoch信息,写入到zk节点/brokers/topics/{Topic名称}/partitions/{分区号}/state中。
最后发起 LeaderAndIsrRequest 请求,通知 leader 的变更。
详细看看源码:
PartitionStateMachine#doHandleStateChanges
分区状态从 NewPartition流转到OnlinePartition
/**
* 下面省略了部分不重要代码
*
* 初始化 leader 和 isr 的值 并写入zk中
* @param partitions 所有需要初始化的分区
* @return 返回成功初始化的分区
*/
private def initializeLeaderAndIsrForPartitions(partitions: Seq[TopicPartition]): Seq[TopicPartition] = {
val successfulInitializations = mutable.Buffer.empty[TopicPartition]
// 从当前Controller内存中获取所有分区对应的副本情况
val replicasPerPartition = partitions.map(partition => partition -> controllerContext.partitionReplicaAssignment(partition))
// 过滤一下 不在线的副本(有可能副本所在的Broker宕机了,或者网络拥堵、或者磁盘脱机等等因素造成副本下线了)
val liveReplicasPerPartition = replicasPerPartition.map { case (partition, replicas) =>
val liveReplicasForPartition = replicas.filter(replica => controllerContext.isReplicaOnline(replica, partition))
partition -> liveReplicasForPartition
}
val (partitionsWithoutLiveReplicas, partitionsWithLiveReplicas) = liveReplicasPerPartition.partition { case (_, liveReplicas) => liveReplicas.isEmpty }
partitionsWithoutLiveReplicas.foreach { case (partition, replicas) =>
val failMsg = s"Controller $controllerId epoch ${controllerContext.epoch} encountered error during state change of " +
s"partition $partition from New to Online, assigned replicas are " +
s"[${replicas.mkString(",")}], live brokers are [${controllerContext.liveBrokerIds}]. No assigned " +
"replica is alive."
logFailedStateChange(partition, NewPartition, OnlinePartition, new StateChangeFailedException(failMsg))
}
// 拿到所有分区对应的leader 和 isr和 Controller epoch的信息; leader是取所有在线副本的第一个副本
val leaderIsrAndControllerEpochs = partitionsWithLiveReplicas.map { case (partition, liveReplicas) =>
val leaderAndIsr = LeaderAndIsr(liveReplicas.head, liveReplicas.toList)
val leaderIsrAndControllerEpoch = LeaderIsrAndControllerEpoch(leaderAndIsr, controllerContext.epoch)
partition -> leaderIsrAndControllerEpoch
}.toMap
// 将上面得到的信息 写入zk的节点中/brokers/topics/{Topic名称}/partitions/{分区号}/state
val createResponses = try {
zkClient.createTopicPartitionStatesRaw(leaderIsrAndControllerEpochs, controllerContext.epochZkVersion)
} catch {
case e: ControllerMovedException =>
error("Controller moved to another broker when trying to create the topic partition state znode", e)
throw e
case e: Exception =>
partitionsWithLiveReplicas.foreach { case (partition,_) => logFailedStateChange(partition, partitionState(partition), NewPartition, e) }
Seq.empty
}
createResponses.foreach { createResponse =>
val code = createResponse.resultCode
val partition = createResponse.ctx.get.asInstanceOf[TopicPartition]
val leaderIsrAndControllerEpoch = leaderIsrAndControllerEpochs(partition)
if (code == Code.OK) {
controllerContext.partitionLeadershipInfo.put(partition, leaderIsrAndControllerEpoch)
controllerBrokerRequestBatch.addLeaderAndIsrRequestForBrokers(leaderIsrAndControllerEpoch.leaderAndIsr.isr,
partition, leaderIsrAndControllerEpoch, controllerContext.partitionFullReplicaAssignment(partition), isNew = true)
successfulInitializations += partition
} else {
logFailedStateChange(partition, NewPartition, OnlinePartition, code)
}
}
successfulInitializations
}
从当前的Controller 内存中获取所有入参的分区对应的副本信息
过滤那些已经下线的副本( Broker宕机、网络异常、磁盘脱机、等等都有可能造成副本下线) 。
每个分区对应的所有在线副本信息 为 ISR 信息,然后取ISR的第一个副本为leader分区。当然特别注意一下, 这个时候获取的isr信息的顺序就是 分区创建时候分配好的AR顺序, 获取第一个在线的。(因为在其他情况下 ISR的顺序跟AR的顺序并不一致)
组装 上面的 isr、leader、controller_epoch 等信息 写入到zk节点 /brokers/topics/{Topic名称}/partitions/{分区号}/state
例如下面所示
JSON
{"controller_epoch":1,"leader":0,"version":1,"leader_epoch":0,"isr":[0,1,2]}
然后向其他相关Broker 发起 LeaderAndIsrRequest 请求,通知他们Leader和Isr信息已经变更了,去做一下想要的处理。比如去新的leader发起Fetcher请求同步数据。
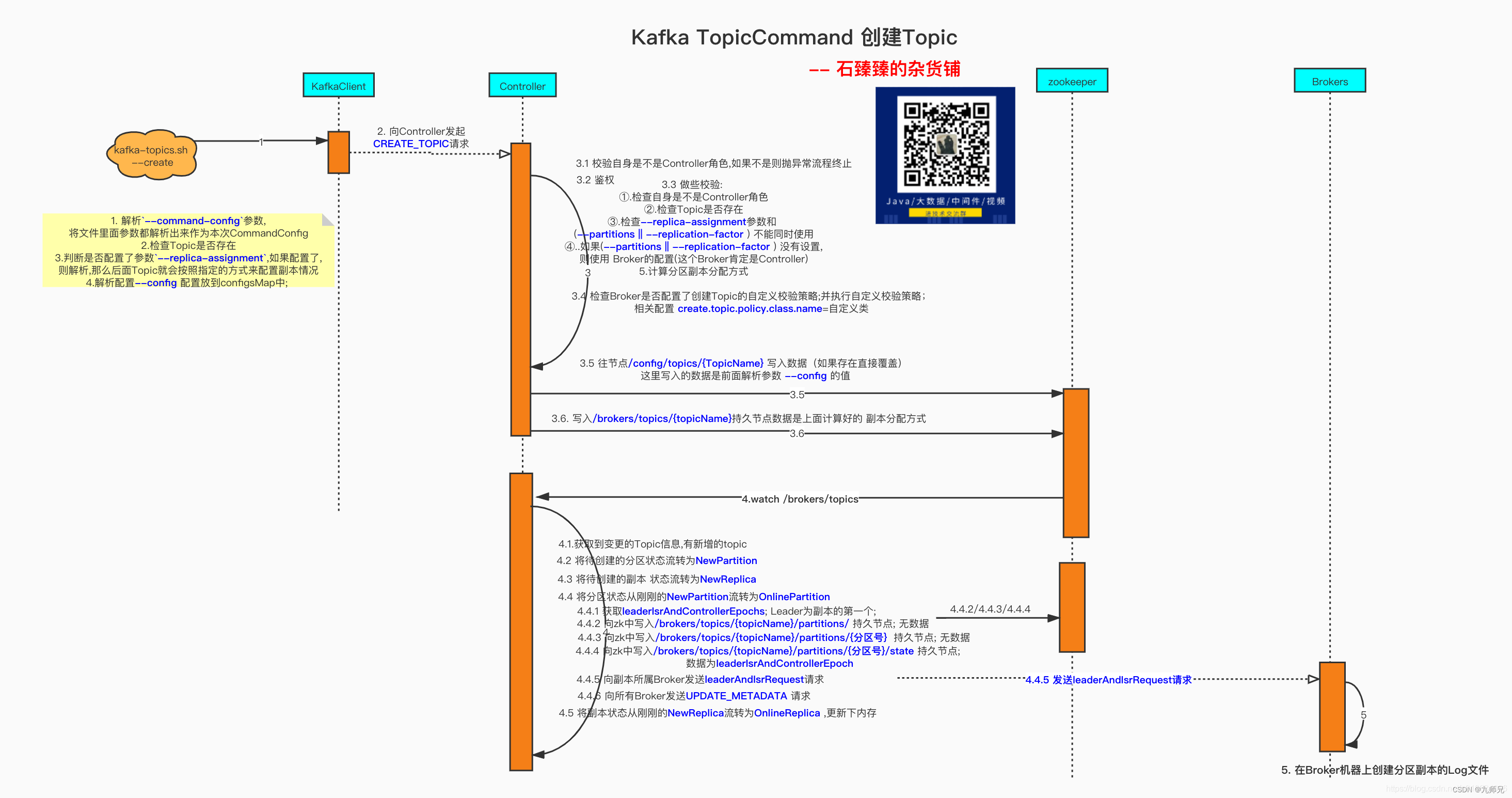
可以看看之前我们分析过的 Topic创建的源码解析 的原理图 如下
重点看:

回答上面的问题
现在,看完全文之后,我想你应该对下面的问题很清楚了吧!
什么是分区状态机
所有的分区状态的流转都是通过分区状态机来进行的, 统一管理! 每个分区状态的流转 都是有严格限制并且固定的,流转到不同状态需要执行的操作不一样, 例如 当分区状态流转到 OnlinePartition 的时候, 就需要判断是否需要执行 Leader选举 ,
创建Topic的时候如何选举Leader?
创建Topic的时候并没有发生 Leader选举, 而是默认将 在线的第一个副本设置为Leader,所有在线的副本列表 为 ISR 列表。 写入到了zookeeper中。
加szzdzhp001,领取全部kafka知识图谱
分区的所有副本都不在线, 这个时候启动一台之前不在ISR内的副本的Broker,它会当选为Leader吗?
视情况而定。
首先, 启动一台Broker, 会用什么策略选举?
看上面的图,我们可以知道是
OfflinePartitionLeaderElectionStrategy
然后看下这个策略是如何选举的?
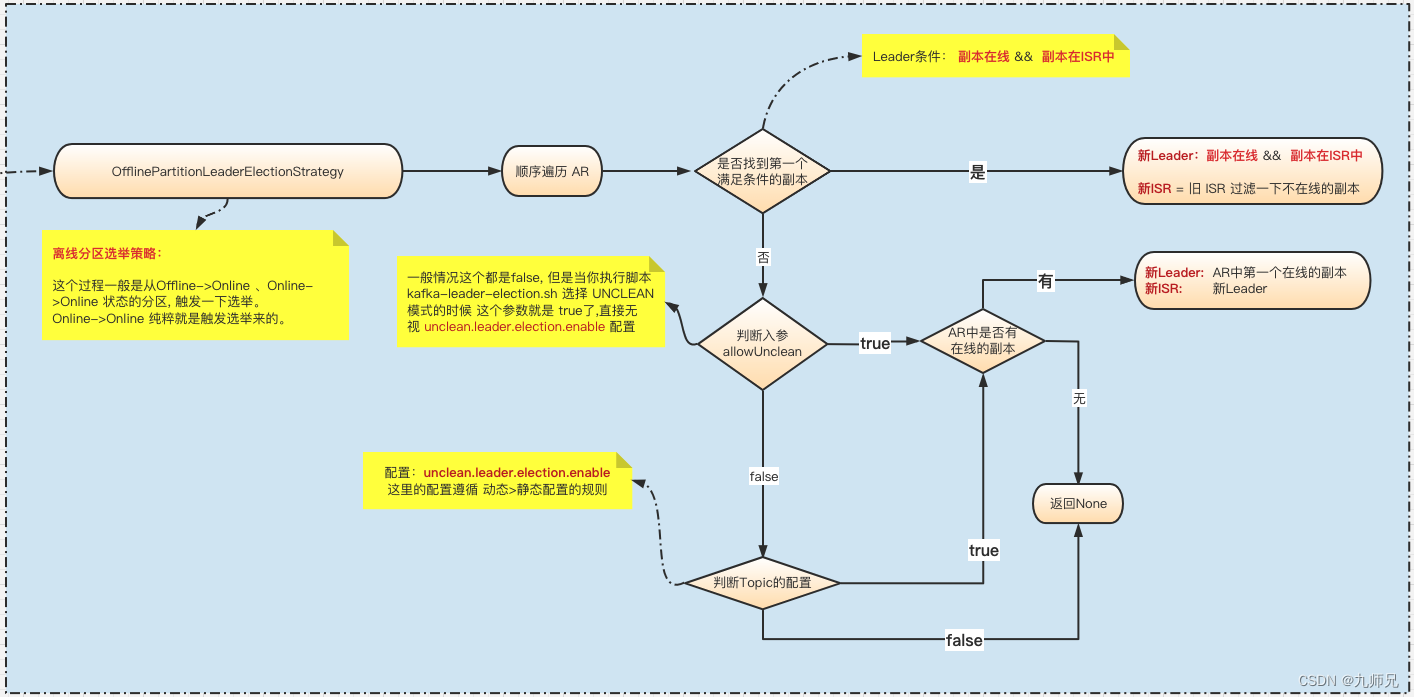
那么最终结果就是:
所有副本不在线,那么一个Leader的候选者都当选不了
那么这个时候就会判断 unclean.leader.election.enable 配置是否为true.
如果是true, 则当前在线的副本就是只有自己这个刚启动的在线副本,自然而然就会当选Leader了。
如果是fase, 则没有副本能够当前Leader, 次数处于一个无Leader的状态。
当所有副本都不在线,然后一个一个重启Broker上副本上线,谁会当选为Leader?谁先启动就谁当选吗?
不是, 跟上一个问题同理
根据 unclean.leader.election.enable 配置决定。
如果是true, 则谁先启动,谁就当选(会丢失部分数据)
如果是false,则第一个在ISR列表中的副本当选。
顺便再提一句, 虽然在这里可能不是AR中的第一个副本当选Leader。
但是最终还是会自动执行Leader均衡的,自动均衡使用的策略是
PreferredReplicaPartitionLeaderElectionStrategy
(前提是开启了自动均衡: auto.leader.rebalance.enable=true)
Broker下线了,Leader切换给了其他副本, 当Broker重启的时候,Leader会还给之前的副本吗?
根据配置 auto.leader.rebalance.enable=true 决定。
true: 会自动执行Leader均衡, 自动均衡策略是 PreferredReplicaPartitionLeaderElectionStrategy 策略
false: 不执行自动均衡。 那么久不会还回去。
关于更详细的 Leader均衡机制请看 Leader 均衡机制
Leader选举期间对分区的影响
Leader的选举基本上不会造成什么影响, Leader的切换非常快, 每个分区不可用的时间在几毫秒内。















 460
460











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









