







 本文介绍了Zipkin——一个用于收集服务定时数据的分布式跟踪系统,以解决微服务架构中的延迟问题。通过Zipkin,开发者可以理解和分析服务间的调用关系,监控系统性能瓶颈。文章详述了Zipkin的下载、启动,以及如何在SpringBoot微服务中集成和使用Zipkin进行分布式跟踪,展示了服务调用链路和时间消耗,最后提到了数据持久化的可能性。
本文介绍了Zipkin——一个用于收集服务定时数据的分布式跟踪系统,以解决微服务架构中的延迟问题。通过Zipkin,开发者可以理解和分析服务间的调用关系,监控系统性能瓶颈。文章详述了Zipkin的下载、启动,以及如何在SpringBoot微服务中集成和使用Zipkin进行分布式跟踪,展示了服务调用链路和时间消耗,最后提到了数据持久化的可能性。
微服务之分布式跟踪系统(springboot+zipkin)
一、zipkin是什么
zipkin是一个开放源代码分布式的跟踪系统,由Twitter公司开源,它致力于收集服务的定时数据,以解决微服务架构中的延迟问题,包括数据的收集、存储、查找和展现。它的理论模型来自于Google Dapper 论文。
每个服务向zipkin报告计时数据,zipkin会根据调用关系通过Zipkin UI生成依赖关系图,显示了多少跟踪请求通过每个服务,该系统让开发者可通过一个 Web 前端轻松的收集和分析数据,例如用户每次请求服务的处理时间等,可方便的监测系统中存在的瓶颈。
二、什么需要分布式跟踪系统(zipkin)
当代的互联网的服务,通常都是用复杂的、大规模分布式集群来实现的。特别是随着微服务架构和容器技术的兴起(加速企业敏捷,快速适应业务变化,满足架构的高可用和高扩展),互联网应用往往构建在不同的服务之上,这些服务,有可能是由不同的团队开发、可能使用不同的编程语言来实现、有可能布在了几千台服务器,横跨多个不同的数据中心。因此,就需要一些可以帮助理解系统行为、用于快速分析性能问题的工具。先是Google开发其分布式跟踪系统并且发表了Dapper 论文,然后由Twitter参照Dapper论文设计思想开发zipkin分布式跟踪系统,同时开源出来。
zipkin通过采集跟踪数据可以帮助开发者深入了解在分布式系统中某一个特定的请求时如何执行的。假如说,我们现在有一个用户请求超时,我们就可以将这个超时的请求调用链展示在UI当中。我们可以很快度的定位到导致响应很慢的服务究竟是什么。如果对这个服务细节也很很清晰,那么我们还可以定位是服务中的哪个问题导致超时。同时,通过服务调用链路能够快速定位系统的性能瓶颈。
三、zipkin下载与启动
在本节中,我们将介绍下载和启动zipkin实例,以便在本地检查zipkin。有三种安装方法:使用官网自己打包好的Jar运行,Docker方式或下载源代码自己打包Jar运行(因为zipkin使用了springboot,内置了服务器,所以可以直接使用jar运行)。zipkin推荐使用docker方式运行,我后面会专门写一遍关于docker的运行方式,而源码运行方式好处是有机会体验到最新的功能特性,但是可能也会带来一些比较诡异的坑,所以不做讲解,下面我直接是使用官网打包的jar运行过程:
(1) 下载jar文件
wget -O zipkin.jar 'https://search.maven.org/remote_content?g=io.zipkin.java&a=zipkin-server&v=LATEST&c=exec'不过,我在运行的过程中,发现无法下载。然后我通过翻墙软件,下载了其最新的jar文件(zipkin-server-1.17.1-exec.jar),我这里也提供其下载地址。
(2) 启动实例
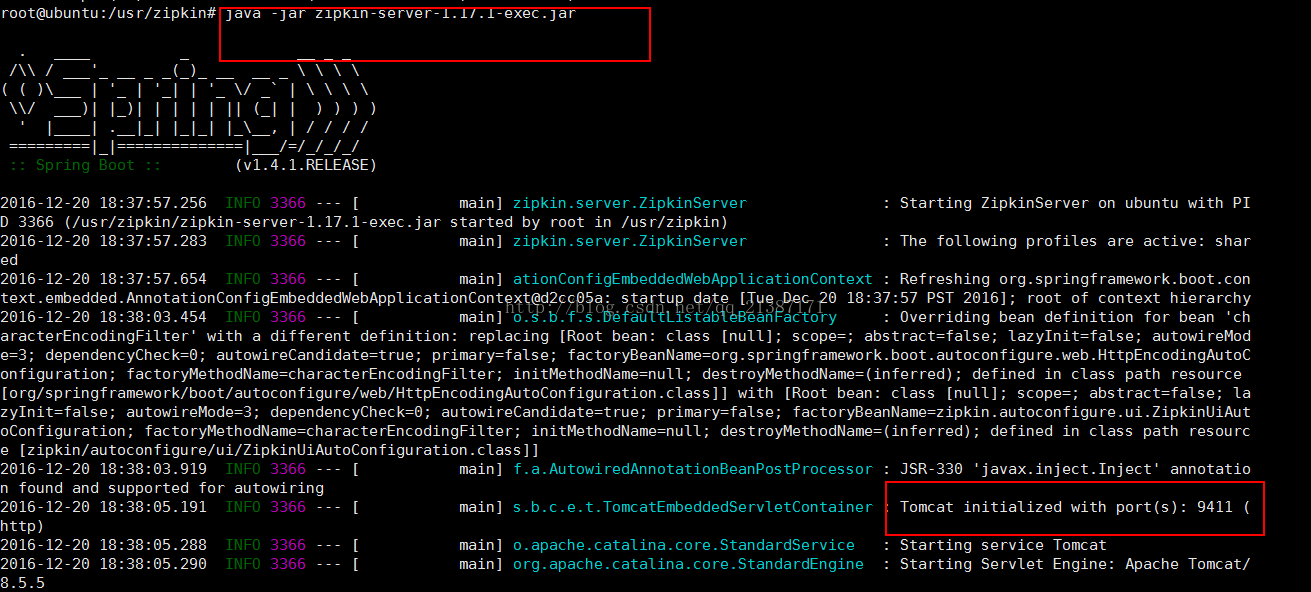
java-jar zipkin-server-1.17.1-exec.jar或者java -jar zipkin.jar(注意需要安转JDK8或者以上的版本),启动成功如下图所示:
(3) 查看运行效果
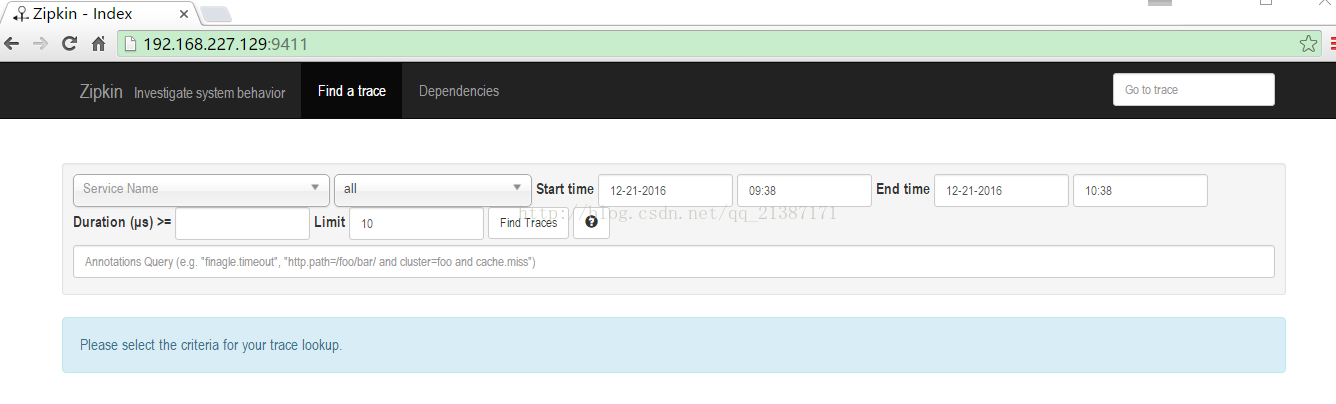
通过上图,我们发现zipkin使用springboot,并且启动的端口为9411,然后我们通过浏览器访问,效果如下:
四、zipkin的架构与核心概念
将数据发送到zipkin的已检测应用程序中的组件称为Reporter。它通过几种传输方式之一将跟踪数据发送到zipkin收集器,zipkin收集器将跟踪数据保存到存储器。稍后,存储由API查询以向UI提供数据。为了保证服务的调用链路跟踪,zipkin使用传输ID,例如,当正在进行跟踪操作并且它需要发出传出http请求时,会添加一些headers信息以传播ID,但它不能用于发送详细信息(操作名称、数据等)。其架构图如下所示:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 604
604

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









