







深度学习中有众多有效的优化函数,比如应用最广泛的SGD,Adam等等,而它们有什么区别,各有什么特征呢?下面就来详细解读一下
一、先来看看有哪些优化函数
BGD 批量梯度下降
所谓的梯度下降方法是无约束条件中最常用的方法。假设f(x)是具有一阶连续偏导的函数,现在的目标是要求取最小的f(x) : min f(x)
核心思想:负梯度方向是使函数值下降最快的方向,在迭代的每一步根据负梯度的方向更新x的值,从而求得最小的f(x)。因此我们的目标就转变为求取f(x)的梯度。
当f(x)是凸函数的时候,用梯度下降的方法取得的最小值是全局最优解,但是在计算的时候,需要在每一步(xk处)计算梯度,它每更新一个参数都要遍历完整的训练集,不仅很慢,还会造成训练集太大无法加载到内存的问题,此外该方法还不支持在线更新模型。其代码表示如下:
for i in range(nb_epochs):
params_grad = evaluate_gradient(loss_function, data, params)
params = params - learning_rate * params_grad我们首先需要针对每个参数计算在整个训练集样本上的梯度,再根据设置好的学习速率进行更新。
公式表示如下:
假设h(theta)是我们需要拟合的函数,n表示参数的个数,m表示训练集的大小。J(theta)表示损失函数。
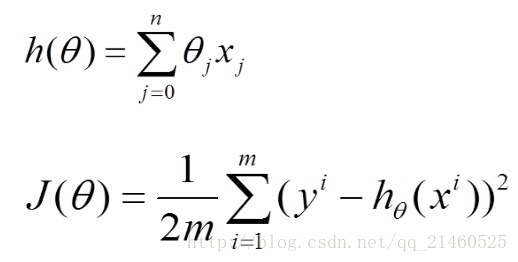

不难看出,在批量梯度下降法中,因为每次都遍历了完整的训练集,其能保证结果为全局最优,但是也因为我们需要对于每个参数求偏导,且在对每个参数求偏导的过程中还需要对训练集遍历一次,当训练集(m)很大时,这个计算量是惊人的!
所以,为了提高速度,减少计算量,提出了SGD随机梯度下降的方法,该方法每次随机选取一个样本进行梯度计算,大大降低了计算成本。
SGD随机梯度下降
随机梯度下降算法和批量梯度下降的不同点在于其梯度是根据随机选取的训练集样本来决定的,其每次对theta的更新,都是针对单个样本数据,并没有遍历完整的参数。当样本数据很大时,可能到迭代完成,也只不过遍历了样本中的一小部分。因此,其速度较快,但是其每次的优化方向不一定是全局最优的,但最终的结果是在全局最优解的附近。
需要:学习速率 ϵ, 初始参数 θ
每步迭代过程:
1. 从训练集中的随机抽取一批容量为m的样本{x1,…,xm},以及相关的输出yi
2. 计算梯度和误差并更新参数
代码表示如下:(需要注意的是,在每次迭代训练中,需要重新洗牌训练集)
for i in range(nb_epochs):
np.random.shuffle(data)
for example in data:
params_grad = evaluate_gradient(loss_function, example, params)
params = params - learning_rate * params_grad虽然BGD可以让参数达到全局最低点并且停止,而SGD可能会让参数达到局部最优,但是仍然会波动,甚至在训练过程中让参数会朝一个更好的更有潜力的方向更新。但是众多的实验表明,当我们逐渐减少学习速率时,SGD和BGD会达到一样的全局最优点。</
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









