







本文使用MPI通信协议实现了一个并行前缀和计算程序,实现了自动生成N个随机数并使用P个进程计算其前缀和。
MPI Scan 算法的底层由归约树组成。 最初,根据进程ID为每个进程分配连续且相等的编号,并将这些编号的总和计算为一个节点。 假设共有P个进程,则该规约树共有P个叶子节点。由于该规约树为一个完全二叉树,因此叶子节点共有2k个,k为任意整数。因此P=2k,即1,2,4,8,16…
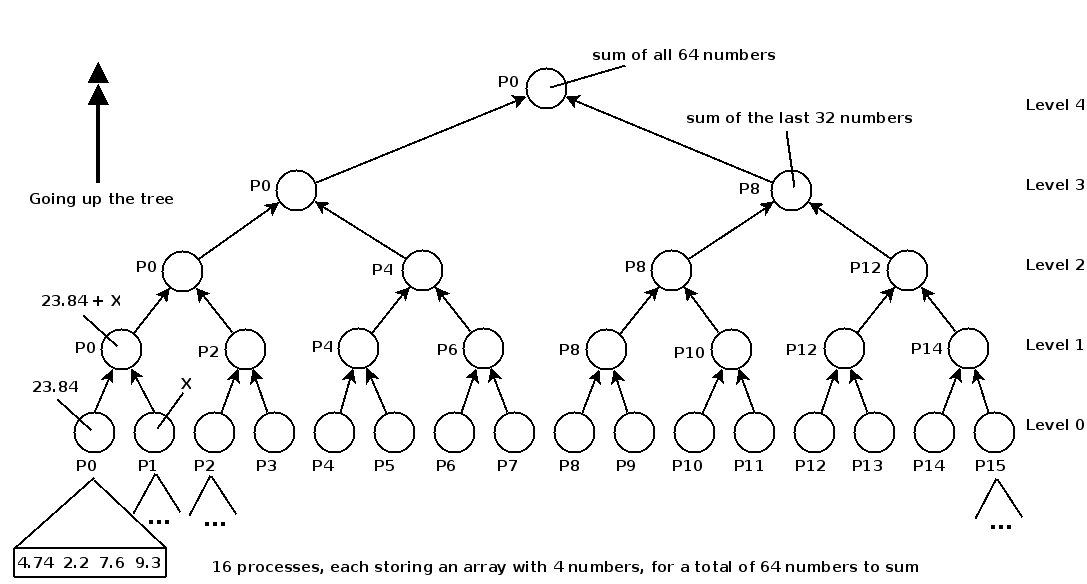
如图所示,假设共有16个进程,即16个叶子节点,每个叶子节点存储4个数字。算法图解如下:
Up phase(上升阶段)
子树和定义
树中的每个节点都有一个与之关联的子树和,该子树和等于与以该节点为根的子树的叶子相关联的所有数组值的总和。如图所示,例如对于层数为0的P0节点,其子树和为4.74+2.2+7.6+9.3。对于层数为1的P0节点,则其子树和为层数为0的P0和P1节点的子树和相加。
构建求和树
在up phase阶段,子节点发送求和信息给父节点,自下而上构建求和树。
规约树中,偶数编号的节点总是左孩子,奇数编号的节点总是右孩子。
每次迭代,第l层的的偶数进程(编号为r)接收奇数进程(编号为r+2^l)发送的子树和,并升级至l+1层,变为两节点的父节点,新的子树和则为原来的子树和加上原来它的右兄弟的子树和。右兄弟在发送完它的子树和后,使命完成,变为非活动状态。不断向上,迭代到第log2(P)层后,则P0最终变为根节点,存储所有数字的和。P8存储了后半32个数字的和。
注意,算法过程中各个节点并行求解,因此时间复杂度是O(logN)的。
Down phase(下降阶段)

构建完求和树之后,该求和树将作为前缀和求解的输入。
在down phase阶段,算法将从根节点(log2(P)-1层)开始,每次迭代进入下一层。每个节点有一个prefix sum值和一个sum值。
每个节点的prefix sum值为以该节点为根节点的子树的最右侧叶子节点之前的所有数字之和。
初始状态下,因为root节点存储了所有数字的和sum,因此该sum值就是根节点的prefix sum值。
如图所示,算法迭代过程中level l+1层的节点的prefix sum值已知,该值等于左孩子节点的prefix sum值加上右孩子节点的sum值。每次迭代,该层节点将会计算出自己的prefix sum值。
迭代过程
- 左子树在下降之前作为父节点,所以它知道父节点的前缀和
prefix sum,并负责发送它给右兄弟。 - 右子树接收左兄弟发送的父节点
prefix sum作为自己的prefix sum,并发送自己子树的和sum值。 - 然后左子树接收右兄弟的
sum值,计算**父节点的prefix sum减去右兄弟的sum**作为自己的prefix sum。
注意,下降过程中,左孩子节点也是它自己的父节点,因此先前的prefix sum值就是它父节点的prefix sum值,左孩子节点的prefix sum值通过减去右兄弟的sum值来修正。
在最底层,每个节点都计算出了自己的prefix sum值,但是该prefix sum值是它叶子节点中最右侧数字的prefix sum值。每个节点需要依次减去其右侧节点数字,顺序计算其剩余N/P-1个prefix sum值。
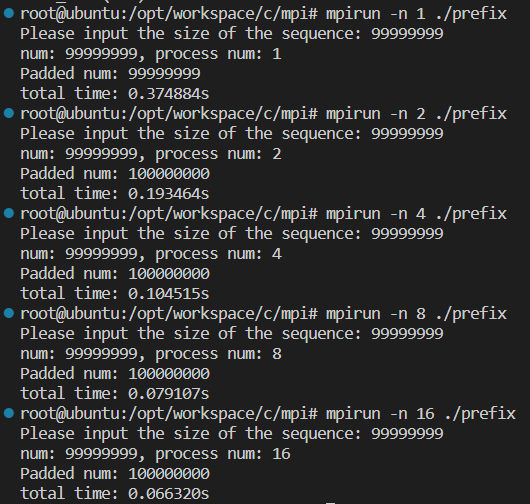
我的虚拟机共有4个cpus,每个cpu有4个cores。
-v参数的意思是将结果输出至屏幕。
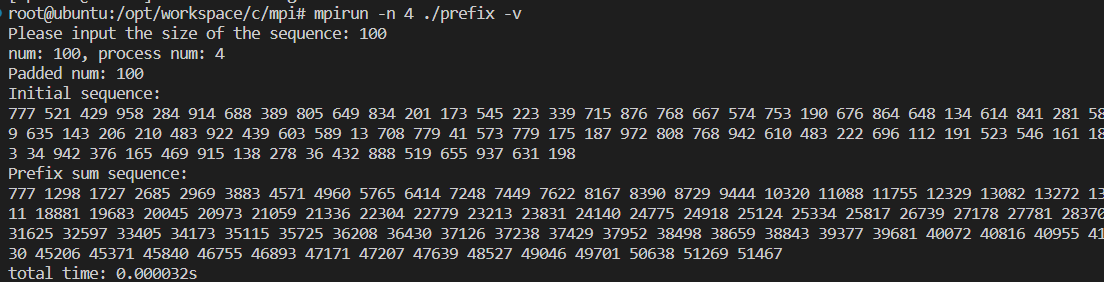
测试时间效率:
算法代码
#include <stdio.h>
#include <mpi.h>
#include <stdlib.h>
#include <time.h>
#include <limits.h>
#include <math.h>
#include <unistd.h>
#define MAX_RAND_NUMBER 1000
typedef int DATA_TYPE;
#define MPI_DATA_TYPE MPI_INT
int display = 0;
void generate_random_numbers(DATA_TYPE *random_numbers, size_t num);
DATA_TYPE get_sum(DATA_TYPE *numbers, size_t size);
void print_arr(DATA_TYPE *numbers, size_t size);
void up_phase(int rank, int process_num,
DATA_TYPE *random_numbers, size_t group_size,
DATA_TYPE *overall_sum);
void down_phase(int rank, int process_num,
DATA_TYPE *random_numbers, size_t group_size,
DATA_TYPE sum);
void my_MPI_Scan(int rank, int process_num, DATA_TYPE *random_numbers, size_t group_size)
{
DATA_TYPE sum;
up_phase(rank, process_num, random_numbers, group_size, &sum);
down_phase(rank, process_num, random_numbers, group_size, sum);
}
int main(int argc, char **argv)
{
int rank, process_num;
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &process_num);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Barrier(MPI_COMM_WORLD);
/* Total size of the sequence */
size_t num;
size_t initial_num;
if (rank == 0)
{
int opt;
while ((opt = getopt(argc, argv, "v")) != -1)
{
switch (opt)
{
case 'v':
display = 1;
break;
default:
fprintf(stderr, "Usage: %s [-v]\n", argv[0]);
exit(EXIT_FAILURE);
}
}
printf("Please input the size of the sequence: ");
scanf("%ld", &num);
initial_num = num;
printf("num: %ld, process num: %d\n", num, process_num);
/* Padding the numbers */
if (num % process_num)
num += process_num - (num % process_num);
printf("Padded num: %ld\n", num);
}
/* Broadcast the sequence size to other processes */
MPI_Bcast(&num, 1, MPI_UNSIGNED_LONG, 0, MPI_COMM_WORLD);
int group_size = num / process_num;
DATA_TYPE *random_numbers = (DATA_TYPE *)calloc(group_size, sizeof(DATA_TYPE));
DATA_TYPE *all_random_numbers;
if (rank == 0)
{
/* It's rank0's responsibility to generate all the random numbers */
all_random_numbers = (DATA_TYPE *)calloc(num, sizeof(DATA_TYPE));
generate_random_numbers(all_random_numbers, initial_num);
if (display)
{
puts("Initial sequence:");
print_arr(all_random_numbers, initial_num);
}
}
/* Scatter the random numbers to the processes appropriately */
MPI_Scatter(all_random_numbers, group_size, MPI_DATA_TYPE, random_numbers,
group_size, MPI_DATA_TYPE, 0, MPI_COMM_WORLD);
/* ========= Start algorithm =========*/
double start = MPI_Wtime();
my_MPI_Scan(rank, process_num, random_numbers, group_size);
MPI_Barrier(MPI_COMM_WORLD);
double end = MPI_Wtime();
/* ========= End algorithm ========== */
/* Gather the result sequence to the root process(rank0) */
MPI_Gather(random_numbers, group_size, MPI_DATA_TYPE, all_random_numbers,
group_size, MPI_DATA_TYPE, 0, MPI_COMM_WORLD);
if (rank == 0)
{
if (display)
{
puts("Prefix sum sequence:");
print_arr(all_random_numbers, initial_num);
}
printf("total time: %lfs\n", end - start);
}
free(random_numbers);
if (rank == 0)
free(all_random_numbers);
MPI_Finalize();
return 0;
}
void print_arr(DATA_TYPE *numbers, size_t size)
{
for (size_t i = 0; i < size; i++)
printf("%d ", numbers[i]);
printf("\n");
}
void generate_random_numbers(DATA_TYPE *random_numbers, size_t num)
{
srand(time(NULL));
if (!random_numbers)
{
printf("Not enough memory\n");
exit(EXIT_FAILURE);
}
for (size_t i = 0; i < num; i++)
random_numbers[i] = rand() % MAX_RAND_NUMBER;
}
DATA_TYPE get_sum(DATA_TYPE *numbers, size_t size)
{
DATA_TYPE sum = 0;
for (size_t i = 0; i < size; i++)
sum += numbers[i];
return sum;
}
void up_phase(int rank, int node_num,
DATA_TYPE *random_numbers, size_t group_size,
DATA_TYPE *overall_sum)
{
MPI_Status status;
/* Initialy, each node's value is the sum of its numbers */
DATA_TYPE sum = get_sum(random_numbers, group_size);
int alive = 1;
int step = 1;
int max_level = (int)log2(node_num);
for (int level = 0; level < max_level; level++, step <<= 1)
{
if (!alive)
break;
int position = rank / step;
if (position % 2 == 0) // receiver, left sibling, which will
{ // level up after added by the right sibling
DATA_TYPE sender_sum;
int right_sibling = rank + step;
/* The even-numbered process receives the sum information sent by the odd-numbered process */
MPI_Recv(&sender_sum, 1, MPI_DATA_TYPE, right_sibling, 0, MPI_COMM_WORLD, &status);
sum += sender_sum;
}
else // sender, right sibiling
{
int left_sibling = rank - step;
MPI_Send(&sum, 1, MPI_DATA_TYPE, left_sibling, 0, MPI_COMM_WORLD);
alive = 0;
}
MPI_Barrier(MPI_COMM_WORLD);
}
*overall_sum = sum;
}
void down_phase(int rank, int node_num,
DATA_TYPE *numbers_in_node, size_t group_size,
DATA_TYPE sum)
{
DATA_TYPE parent_prefix_sum;
int level;
MPI_Status status;
/* The rank0 process is the root of the tree */
if (rank == 0)
parent_prefix_sum = sum;
int step = node_num / 2;
for (level = (int)log2(node_num) - 1; level >= 0; level--, step >>= 1)
{
/* The process's rank on the current level can be divided by 2^level */
if (rank % step == 0)
{
int position = rank / step;
if (position % 2 == 0) // The even-numbered node serves as the left subtree
{
DATA_TYPE right_sibling_sum;
int right_silbling = rank + step;
/* The left subtree acts as the parent node before descending, so it knows the prefix sum
of the parent node and is responsible for sending the prefix sum of the parent node. */
MPI_Send(&parent_prefix_sum, 1, MPI_DATA_TYPE, right_silbling, 0, MPI_COMM_WORLD);
/* The left subtree receives the sum of the subtrees of the right sibling */
MPI_Recv(&right_sibling_sum, 1, MPI_DATA_TYPE, right_silbling, 0, MPI_COMM_WORLD, &status);
/* Calculates the prefix sum of the parent node minus the sum of the
right sibling as its own prefix sum */
parent_prefix_sum -= right_sibling_sum;
}
else
{
int left_sibling = rank - step;
/* The odd-numbered node acts as the right subtree, receives the prefix sum of the parent node
sent by the left brother, and sends the sum of its own subtree. */
MPI_Recv(&parent_prefix_sum, 1, MPI_DATA_TYPE, left_sibling, 0, MPI_COMM_WORLD, &status);
MPI_Send(&sum, 1, MPI_DATA_TYPE, left_sibling, 0, MPI_COMM_WORLD);
}
}
MPI_Barrier(MPI_COMM_WORLD);
}
/* update the numbers in node to the prefix sum of the numbers */
// index of the last number in the node which haven't been updated
int tail = group_size - 1;
// save the last number of the node
DATA_TYPE number_after = numbers_in_node[tail];
// prefix sum of the node is the prefix sum of the last number
numbers_in_node[tail] = parent_prefix_sum;
// each of the number can be obtained by calculating the prefix of the number following it
// subtract the value of the number following it
while (tail--)
{
DATA_TYPE tmp = numbers_in_node[tail];
numbers_in_node[tail] = numbers_in_node[tail + 1] - number_after;
number_after = tmp;
}
}
















 5825
5825











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











