






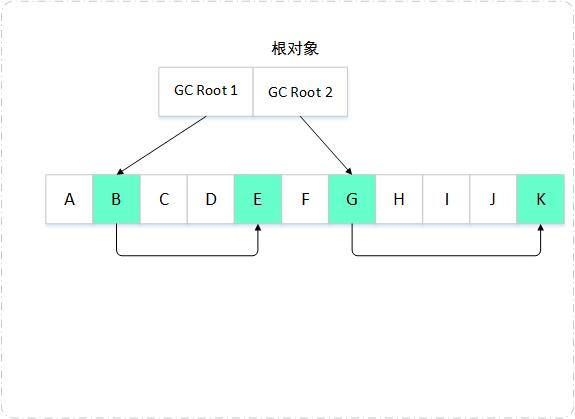
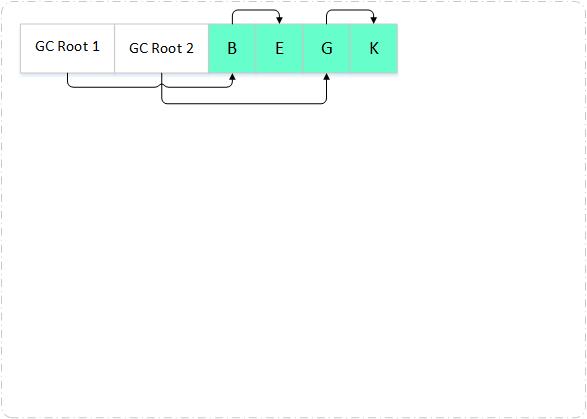
如何判定哪些对象可回收?
可达性分析算法
在主流的JVM实现中,都是通过可达性分析算法来判定对象是否存活的。可达性分析算法的基本思想是:通过一系列被称为"GC Roots"的对象作为起始点,从这些节点开始向下搜索,搜索走过的路径称为引用链,当一个对象到GC Roots对象没有任何引用链相连,就认为GC Roots到这个对象是不可达的,判定此对象为不可用对象,可以被回收。
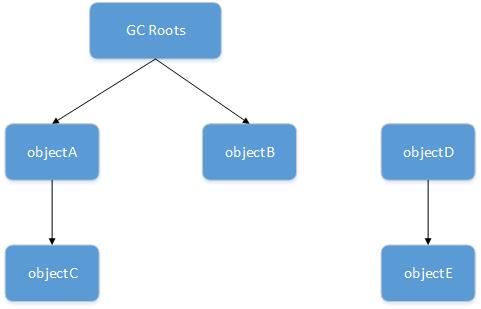
在Java中,可作为GC Roots的对象包括下面几种:
1、虚拟机栈中引用的对象;
2、方法区中类静态属性引用的对象;
3、方法区中常量引用的对象;
4、本地方法栈中Native方法引用的对象。
垃圾回收算法
标记清除算法
标记阶段:标记的过程其实就是前面介绍的可达性分析算法的过程,遍历所有的GC Roots对象,对从GC Roots对象可达的对象都打上一个标识,一般是在对象的header中,将其记录为可达对象;
清除阶段:清除的过程是对堆内存进行遍历,如果发现某个对象没有被标记为可达对象(通过读取对象header信息),则将其回收。
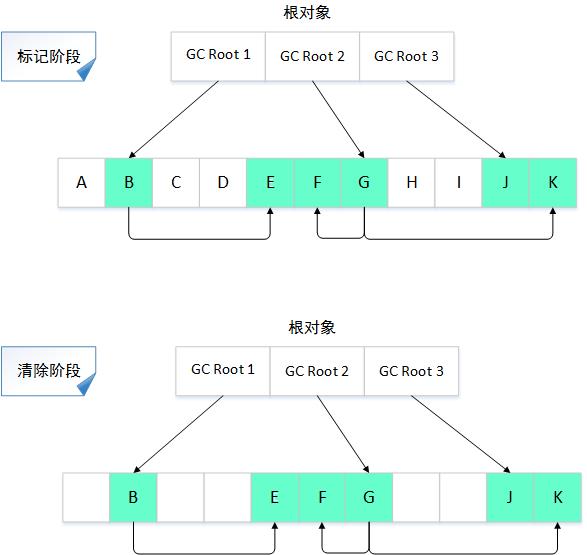
对于没有标记的对象则会放到一个单向的空闲列表free_list里面,这样当新建对象需要分配内存时我们就可以从free_list里面取出合适的分块。
缺点
1、内存碎片化。因为对象不移动,所以导致块是不连续的,容易出现空闲内存很多,但分配大对象时找不到合适的块。
2、分配速度慢。其操作仍是一个O(n)的操作,最坏情况是每次都要遍历到最后。同时因为碎片化,大对象的分配效率会更慢(相对影响较小)
3 、破坏了用户程序的局部性,破坏了缓存命中率
复制算法
从GC Roots根节点开始遍历,将根节点及其引用的子节点全部复制到TOSPACE,每复制一个对象,就把 free 指针向后移动相应大小的位置。
在执行Copying GC时,如果一个对象被拷贝了,那么该对象的mark word可以存储它的forwarding pointer指向新的拷贝
(不用把堆都遍历一遍)
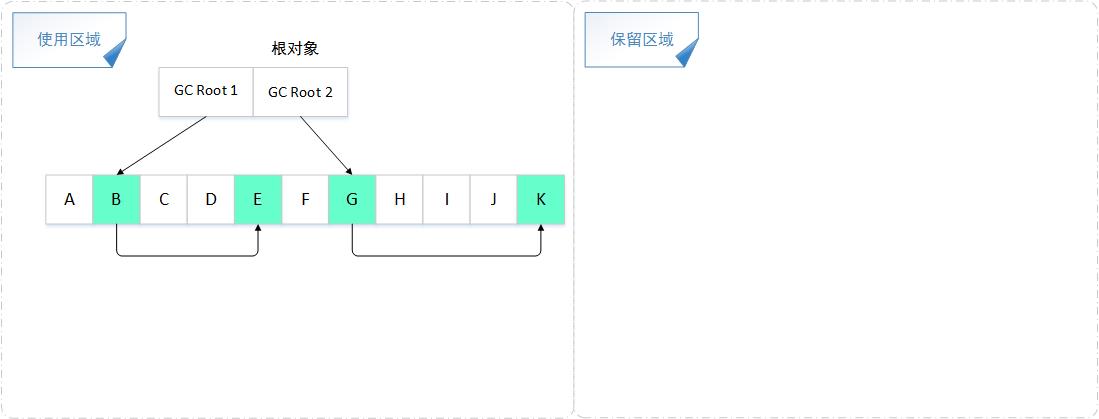
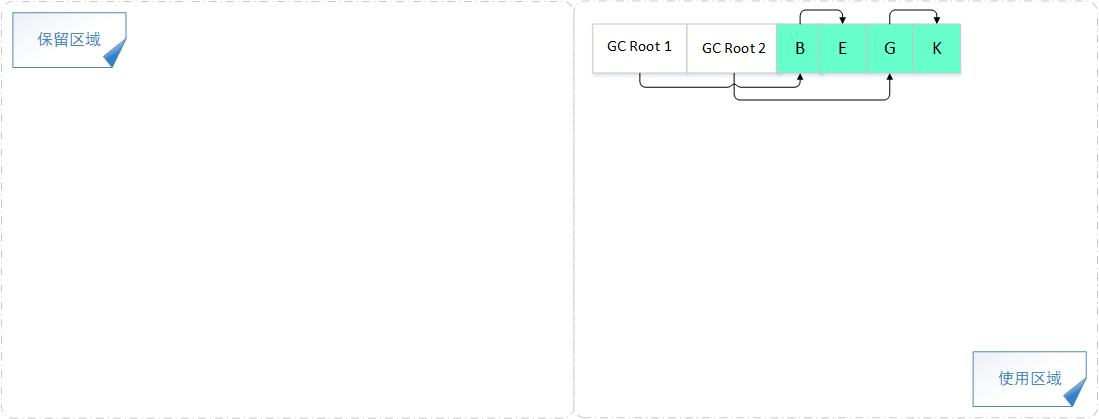
1、将内存缩小为原来的一半,浪费了一半的内存空间,代价太高;
2、如果对象的存活率很高,极端一点的情况假设对象存活率为100%,那么我们需要将所有存活的对象复制一遍,耗费的时间代价也是不可忽视的。
标记整理
-
标记阶段:选取gc根对象。从这些对象开始向下遍历其子对象,最终可能会形成一个又向有环图。在此图中的对象就是活动对象,也就是将要压缩的对象。
-
整理阶段:将对象向着一端移动,移动后对象的相对顺序不变,但是对象紧临。
-
设置forwarding指针
-
搜索整个堆,给活动对象设置forwarding的位置 set_forwarding_ptr(){ scan = new_address = $heap_start while(scan < $heap_end) if(scan.mark == TRUE) scan.forwarding = new_address new_address += scan.size scan += scan.size }更新指针
-
需要让每一个对象知道移动后子对象将来的位置。因此需要修改指针 adjust_ptr(){ //更改根的指针 for(r : $roots) *r = (*r).forwarding scan = $heap_start while(scan < $heap_end) //如果标记过,就将子对象设置为子对象将来的位置(forwarding) if(scan.mark == TRUE) for(child : children(scan)) *child = (*child).forwarding scan += scan.size }移动对象
-
移动对象,过程很简单,每个对象都知道要去的地址,只需要顺序移动便可,然后清除之前的标记。注意要顺序移动,不然会覆盖掉活动对象 move_obj(){ scan = $free = $heap_start while(scan < $heap_end) if(scan.mark == TRUE) new_address = scan.forwarding copy_data(new_address, scan, scan.size) new_address.forwarding = NULL new_address.mark = FALSE $free += new_address.size scan += scan.size }
-
时间复杂度
- 标记阶段:遍历所有的存活对象,与活动对象数成正比
- 设置forwarding指针阶段:扫描整个堆
- 更改子对象指针阶段:扫描整个堆
- 移动阶段:扫描整个堆
优点
- 相比于标记清除与引用计数:没有内存碎片
- 相比于复制算法:有效利用堆
缺点
一次遍历活动对象+三次扫描整个堆,吞吐量较小。
小结
复制算法需要耗费的时间空间由什么决定?
存活对象的数量 和内存的总大小没关系
标记清除算法耗费的时间由什么决定?
内存的总大小,清除阶段需要遍历堆。
标记整理算法耗费的时间由什么决定?
1内存的总大小,整理阶段需要遍历三次堆。
2存活对象的数量
分代垃圾回收
分代收集理论建立在两个分代假说之上:
- 弱分代假说:大多数对象都是朝生夕灭的。这个假说已经在不同的编程语言和编程范式中得到证实;
- 强分代假说:越长寿的对象越不容易死亡。这个假说证据稍显不足,但是却依旧给大对象回收处理有一定的意义。
这两个假说共同奠定了多款常用的垃圾收集器的一致设计原则:收集器应该将堆划分出不同区域,然后将回收对象依据年龄分配到不同的区域之中。
除此之外新生代对象完全可以由老年代对象引用,如果产生这种引用,就需要遍历整个老年代来确定可达性分析的准确性,这样对内存回收带来极大的性能负担,所以引出了另一条假说
- 跨代引用假说:跨代引用对比与同代引用来说仅占极少数。
根据对象的存活周期的不同将内存划分为好几块。一般是把java堆分为新生代和老年代,这样就可以根据各个年代的特点采用最适合的收集算法。新生代中,每次垃圾收集时都发现大批对象死去,只有少量存活,那就选用复制算法。
新生代
复制算法
默认的,Edem : from : to = 8 : 1 : 1
为什么不需要上文说的同等大小的内存
1 大多数对象都是朝生夕灭
2老年代作担保当to Survivor区放不下直接晋升老年代
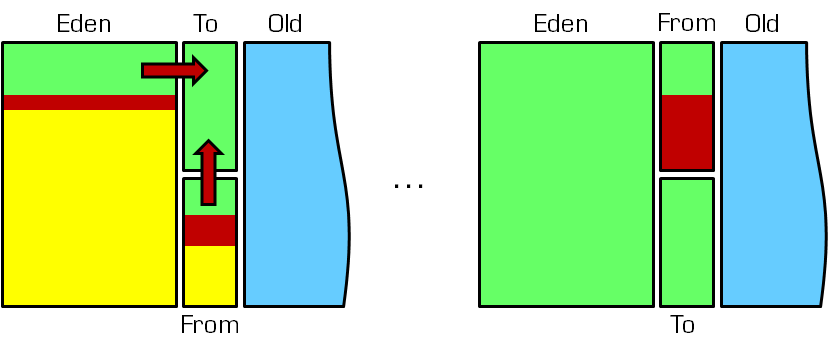
上图演示GC过程,黄色表示死对象,绿色表示剩余空间,红色表示幸存对象
新生代大小对于gc的影响
1消耗时间几乎不变。
2内存越小young gc越频繁,频繁也可能导致不会长期存活的对象进入老年代。
3如果Survivor空间小了,对象又多,且没被回收,空间又不够,那么就晋升老年代,这种堆的老年代会呈现持续增长的趋态。
大对象直接分配到老年代
1年轻带gc频率高,复制代价大
2Survivor 区有限可能导致别的对象晋升到老年代
老年代
标记清除 标记整理
老年代存储的对象比年轻代多得多,而且不乏大对象,对老年代进行内存清理时,如果使用停止-复制算法,则相当低效。一般,老年代用的算法是标记-清除算法,当碎片增多时在进行一次标记整理算法。
老年代大小对于gc的影响
1老年代越大一次gc时间越长需要遍历堆。
2老年代越大gc频率越低。
大内存将导致长暂停
跨代引用
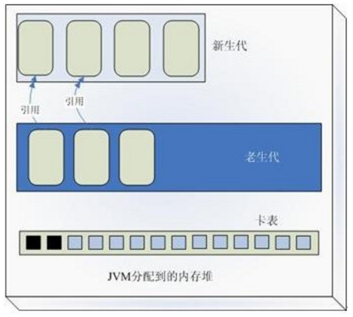
YGC时,为了找到年轻代中的存活对象,不得不遍历整个老年代;反之亦然。这种方案存在极大的性能浪费。因为跨代引用是极少的,为了找出那么一点点跨代引用,却得遍历整个老年代!
跨代引用带来的问题,采用CardTable很好的规避了遍历整个老年代的问题,HotSpot JVM的卡页(Card Page)大小为512字节,卡表(Card Table)被实现为一个简单的字节数组,即卡表的每个标记项为1个字节。
并发垃圾回收
GC线程与应用并发进行 cms g1
1 gc时需要预留空间给应用使用
2 并发模式可能失败回收速度赶不上应用的使用速度(concurrent mode failure),退化成full gc
将所有对象分为三种颜色
- 白色:没有检查 或者是垃圾
- 灰色:自身被检查了,成员没被检查完(可以认为访问到了,但是正在被检查,就是图的遍历里那些在队列中的节点)
- 黑色:自身和成员都被检查完了

浮动垃圾
对象B是“应该”被回收的。然而因为B已经变为灰色了,其仍会被当作存活对象继续遍历下去。最终的结果是:这部分对象仍会被标记为存活,即本轮GC不会回收这部分内存。
这部分本应该回收 但是 没有回收到的内存,被称之为“浮动垃圾”。浮动垃圾并不会影响应用程序的正确性,只是需要等到下一轮垃圾回收中才被清除。
另外,针对并发标记开始后的新对象,通常的做法是直接全部当成黑色,本轮不会进行清除。这部分对象期间可能会变为垃圾,这也算是浮动垃圾的一部分。
漏标
因为B已经没有对C的引用了,所以不会将C放到灰色集合;尽管因为A重新引用了C,但因为A已经是黑色了,不会再重新做遍历处理。
最终导致的结果是:C会一直停留在白色集合中,最后被当作垃圾进行清除。这直接影响到了应用程序的正确性,是不可接受的。
Incremental update 增量更新,关注引用的增加,如果发现黑色指向了白色,把黑色重新标记为灰色,remark过程将重新扫描属性。但是会造成重复扫描已扫描过的属性。(CMS对漏标的处理方式)
SATB snapshot at the beginning:关注引用的删除,当灰–>白消失时,要把这个 引用 推到GC的堆栈,保证白还能被GC扫描到。G1采用该方法。















 5949
5949











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









