






Hadoop集群环境搭建
1.环境准备
虚拟机:vm15pro
Linux系统:centos7.6
查看ip命令行命令: ifconig 如果没有此命令 需要安装插件 命令如下:yum install net-tools
jdk1.8.0_221 :
hadoop-2.9.2 :
zookeeper-3.4.10 :
hbase-1.2.4:
三台集群主机安装centos7.6系统(虚拟机环境安装一个之后 可以直接克隆另外两台)
ip分别为
主机master ip (master)
Slave1ip (slave1)
Slave2ip (slave2)
2.修改hosts文件
映射主机名和ip地址
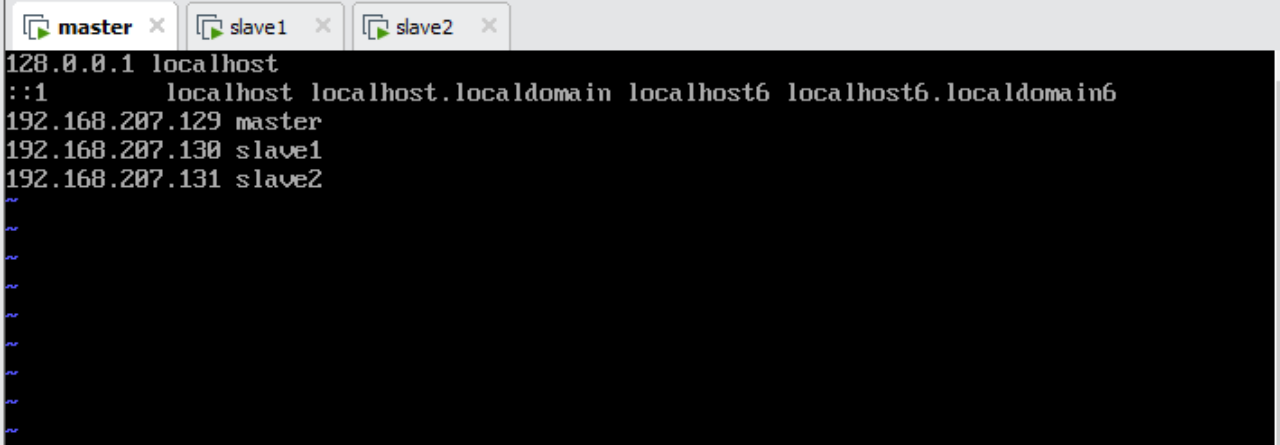
vi /etc/hosts
–加入如下内容(举例)
192.168.207.129 master
192.168.207.130 slave1
192.168.207.131 slave2
注意:每台主机都需要修改 三台主机都一样得修改
截图:
3. 安装jdk
–首先检查是否系统是否已集成自带openjdk
java -version
如果显示jdk版本先卸载openjdk
rpm -qa |grep java(查找安装位置)
–显示如下内容
java-1.8.0-openjdk-headless-1.8.0.101-3.b13.el7_2.x86_64
java-1.8.0-openjdk-1.8.0.101-3.b13.el7_2.x86_64
–卸载
rpm -e --nodeps java-1.8.0-openjdk-headless-1.8.0.101-3.b13.el7_2.x86_64
rpm -e --nodeps java-1.8.0-openjdk-1.8.0.101-3.b13.el7_2.x86_64
–安装jdk
–解压jdk安装包(需要上传jdk文件压缩包 可以选择用sftp连接虚拟机或者mobaxterm连接进行上传文件)
mkdir /usr/java
tar -zxvf jdk-8u221-linux-x64.tar.gz
–拷贝jdk至slave1和slave2
scp -r /usr/java slave1:/usr
scp –r /usr/java slave2:/usr
– 设置jdk环境变量 三台都需要修改
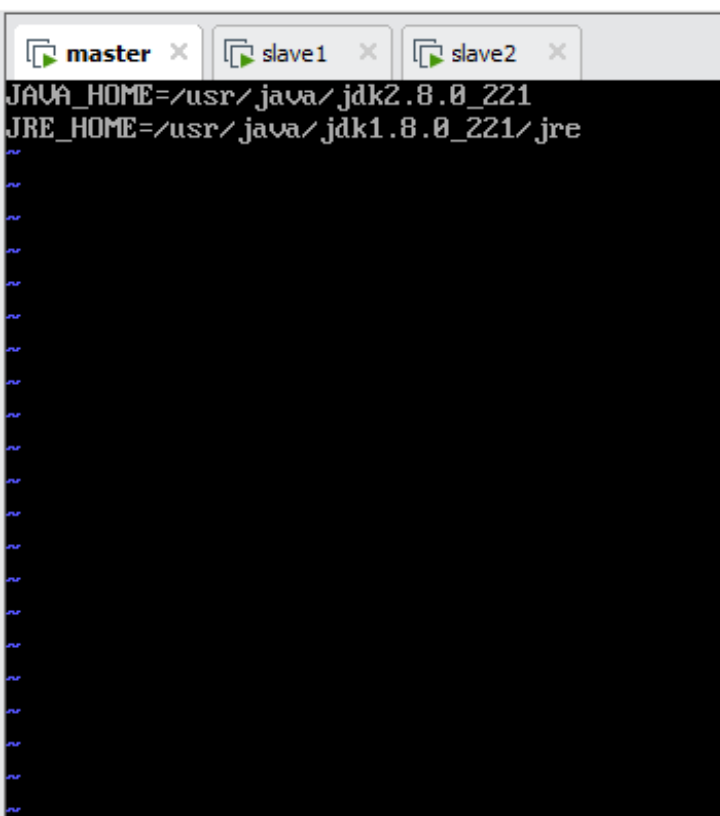
vi /etc/environment
JAVA_HOME=/usr/java/jdk1.8.0_221
JRE_HOME=/usr/java/jdk1.8.0_221/jre
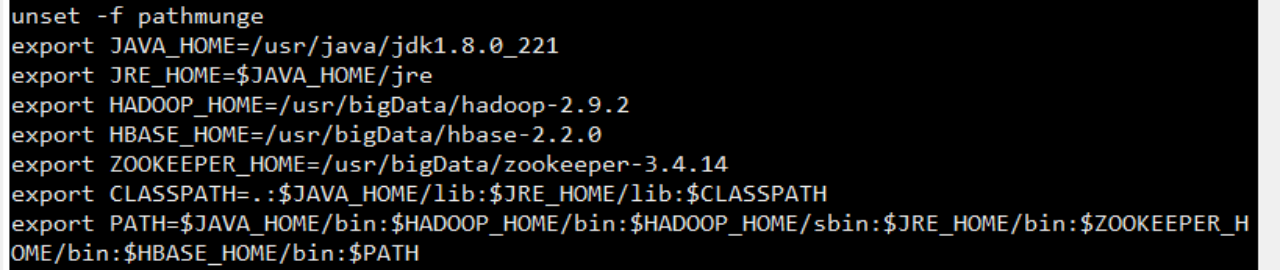
vi /etc/profile 三台都需要修改
–加入如下内容
export JAVA_HOME=/usr/java/jdk1.8.0_221
export JRE_HOME=
J
A
V
A
H
O
M
E
/
j
r
e
e
x
p
o
r
t
C
L
A
S
S
P
A
T
H
=
.
:
JAVA_HOME/jre export CLASSPATH=.:
JAVAHOME/jreexportCLASSPATH=.:JAVA_HOME/lib:$JRE_HOME/lib:
C
L
A
S
S
P
A
T
H
e
x
p
o
r
t
P
A
T
H
=
CLASSPATH export PATH=
CLASSPATHexportPATH=JAVA_HOME/bin:
J
R
E
H
O
M
E
/
b
i
n
:
JRE_HOME/bin:
JREHOME/bin:PATH
截图为完整配置
source /etc/profile 使改动生效
4. 设置集群间无密码访问
slave1
–使用rsa加密
ssh-keygen -t rsa 之后一直回车就行
–拷贝公钥
cp ~/.ssh/id_rsa.pub ~/.ssh/slave1_id_rsa.pub
–传送到master
scp ~/.ssh/slave1_id_rsa.pub master:~/.ssh/
slave2上进行同样的操作
master
–使用rsa加密
ssh-keygen -t rsa
–拷贝master公钥到authorized_keys
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
–拷贝master公钥到authorized_keys
–拷贝slave1公钥到authorized_keys
cat ~/.ssh/slave1_id_rsa.pub >> ~/.ssh/authorized_keys
–拷贝slave2公钥到authorized_keys
cat ~/.ssh/slave2_id_rsa.pub >> ~/.ssh/authorized_keys
此时master的authorized_kyes里面有三台机器的公钥
–传送authorized_kyes到slave1和slave2
scp ~/.ssh/authorized_keys slave1:~/.ssh
scp ~/.ssh/authorized_keys slave2:~/.ssh
如果传送成功,命令行会显示传送成功得文件
5. 关闭防火墙及SELINUX
– 关闭防火墙
systemctl stop firewalld.service
systemctl disable firewalld.service
–关闭SELINUX
vi /etc/selinux/config
注释
#SELINUX=enforcing
#SELINUXTYPE=targeted
再加入
SELINUX=disable
6. Hadoop安装及配置
–解压缩安装包及创建基本目录 (我在usr文件夹下创建了bigData 文件夹 然后将hadoop解压到了里面,解压之前需要将压缩包传到文件夹中)
#mkdir /usr/bigData
tar -zxvf hadoop-2.9.2.tar.gz
cd /usr/hadoop-2.9.2
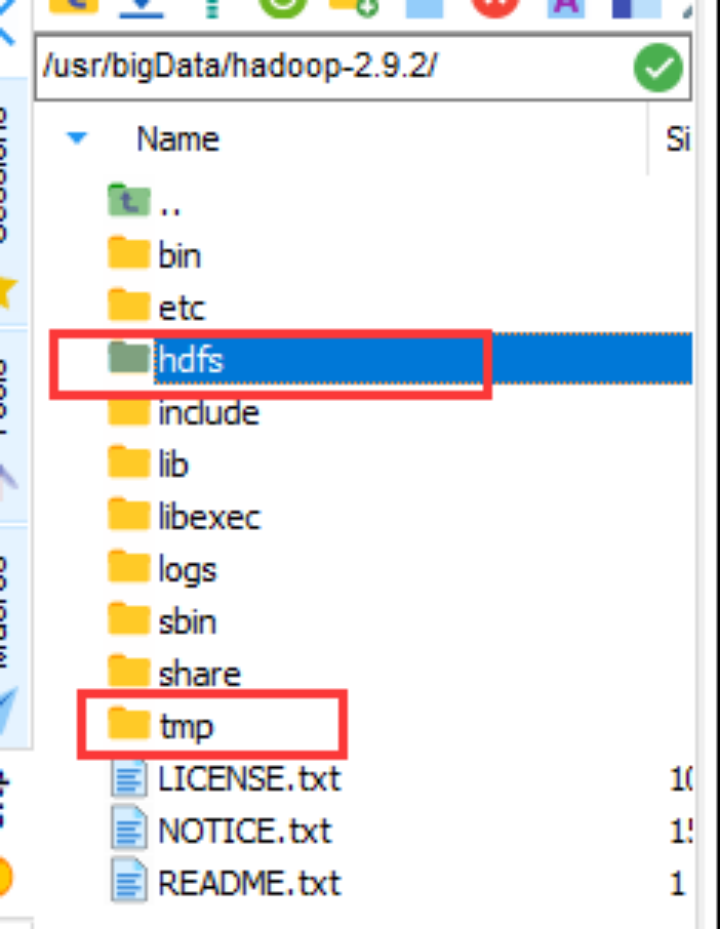
#mkdir hdfs
#mkdir tmp
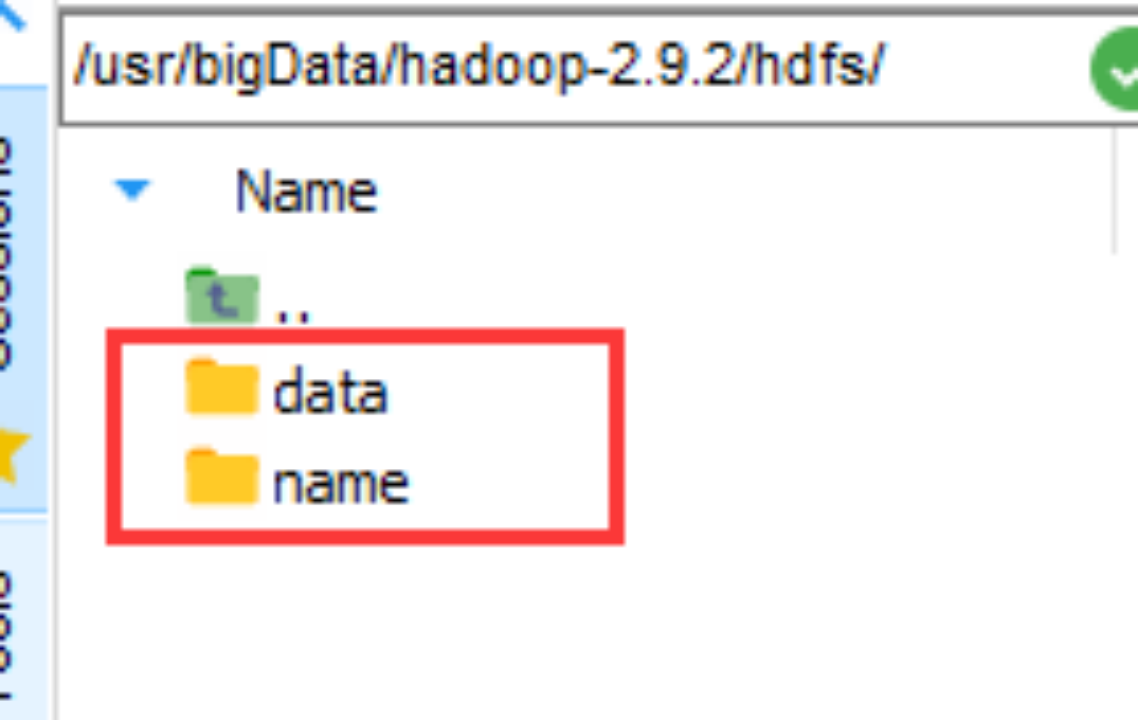
#cd /hdfs
#mkdir data
#mkdir name
然后创建文件夹hdfs和tmp 后续配置文件需要用到
–修改配置文件
–修改slaves文件
vi /usr/bigData/hadoop-2.9.2/etc/hadoop/slaves
删除localhost
加入
slave1
slave2

开始修改一系列配置文件,文件夹如下
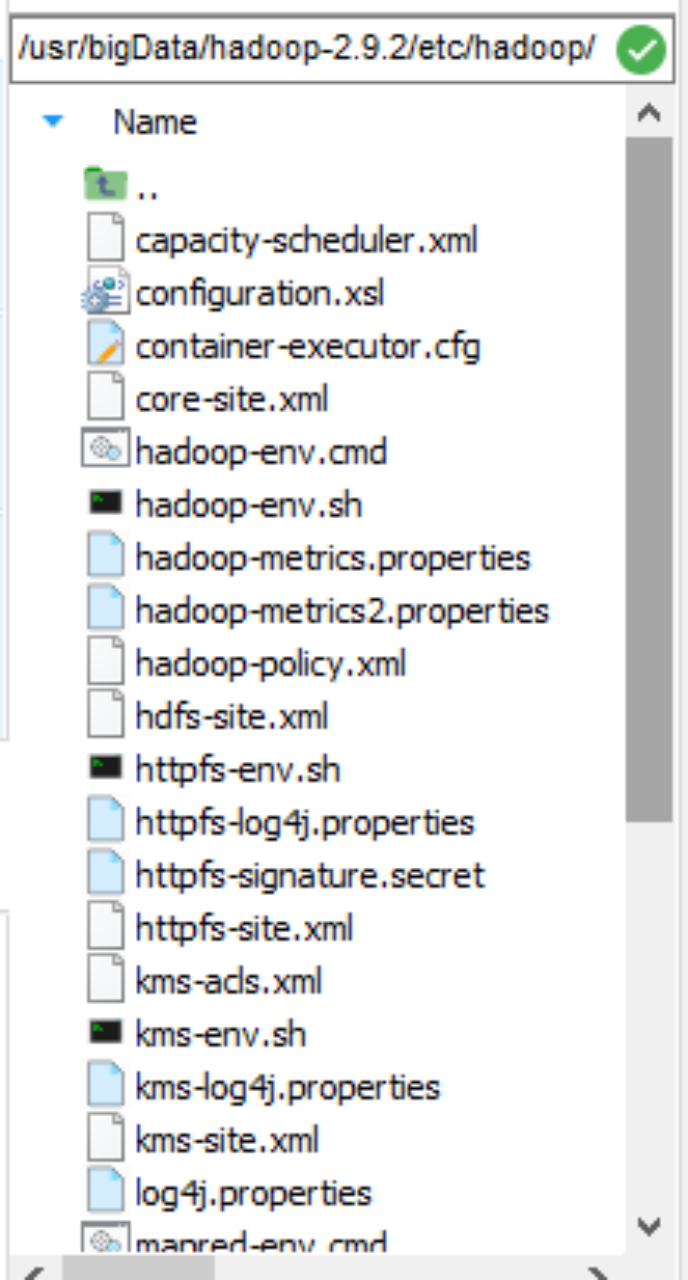
修改hadoop-env.sh文件 (为全路径,使用${JAVA_HOME}可能找不到)

为了避免集群启动后,用命令stop-all.sh无法停止的问题
问 题的原因是:hadoop在stop的时候依据的是datanode上的mapred和dfs进程号。而默认的进程号保存在/tmp下,linux默认会每 隔一段时间(一般是一个月或者7天左右)去删除这个目录下的文件。因此删掉hadoop-hadoop-jobtracker.pid和hadoop- hadoop-namenode.pid两个文件后,namenode自然就找不到datanode上的这两个进程了。
因此为了避免出现这个问题,需要在里面新加

pids文件夹需要外面创建好
– 修改 core-site.xml 文件
#vi core-site.xml
在configuration节点中加入如下内容
fs.default.name hdfs://master:9000 hadoop.tmp.dir file:/usr/bigData/hadoop-2.9.2/tmp–修改hdfs-site.xml 文件
#vi hdfs-site.xml
在configuration节点中加入如下内容
dfs.namenode.name.dir file:/usr/bigData/hadoop-2.9.2/hdfs/name true dfs.datanode.data.dir file:/usr/bigData/hadoop-2.9.2/hdfs/data true–修改mapred-site.xml文件 这个文件是没有得 需要复制/mapred-site.xml.template 并重命名为mapred-site.xml文件
#cp mapred-site.xml.template mapred-site.xml
在configuration节点中加入如下内容
mapreduce.framework.name yarn mapreduce.jobhistory.address master:10020 mapreduce.jobhistory.webapp.address master:19888– 修改 yarn-site.xml 文件
#vi yarn-site.xml
– 在 configuration 节点添加以下内容
yarn.nodemanager.aux-services.mapreduce.shuffle.class org.apache.mapred.ShuffleHandler yarn.resourcemanager.address master:8032 yarn.resourcemanager.scheduler.address master:8030 yarn.resourcemanager.resource-tracker.address master:8031 yarn.resourcemanager.admin.address master:8033 yarn.resourcemanager.webapp.address master:8088–复制hadoop到slave1和slave2节点
#scp -r /usr/bigData/hadoop-2.9.2 slave1:/usr/bigData
#scp -r /usr/bigData/hadoop-2.9.2 slave2:/usr/bigData
–配置hadoop环境变量 每个节点都需要配置
#vi /etc/profile
添加hadoop如下内容
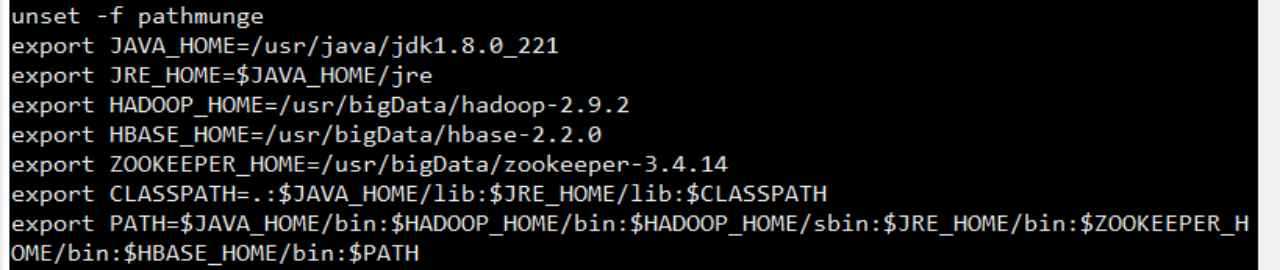
执行让配置文件生效
#source /etc/profile
#vi ~/.bashrc
添加如下内容
export HADOOP_PREFIX=/usr/bigData/hadoop-2.9.2/
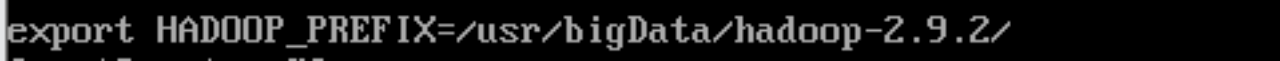
每个节点都要修改
查看hadoop是否安装成功命令
#hadoop version

查看hadoop是32位还是64位版本命令

–master节点格式化namenode (第一次要格式化)
/usr/bigData/hadoop-2.9.2/bin/hdfs namenode -format
Hadoop环境搭建成功!
master节点启动
#/usr/bigData/hadoop-2.9.2/sbin/start-all.sh 启动hadoop查看是否成功
Jps命令查看
#jps 三个节点得查看
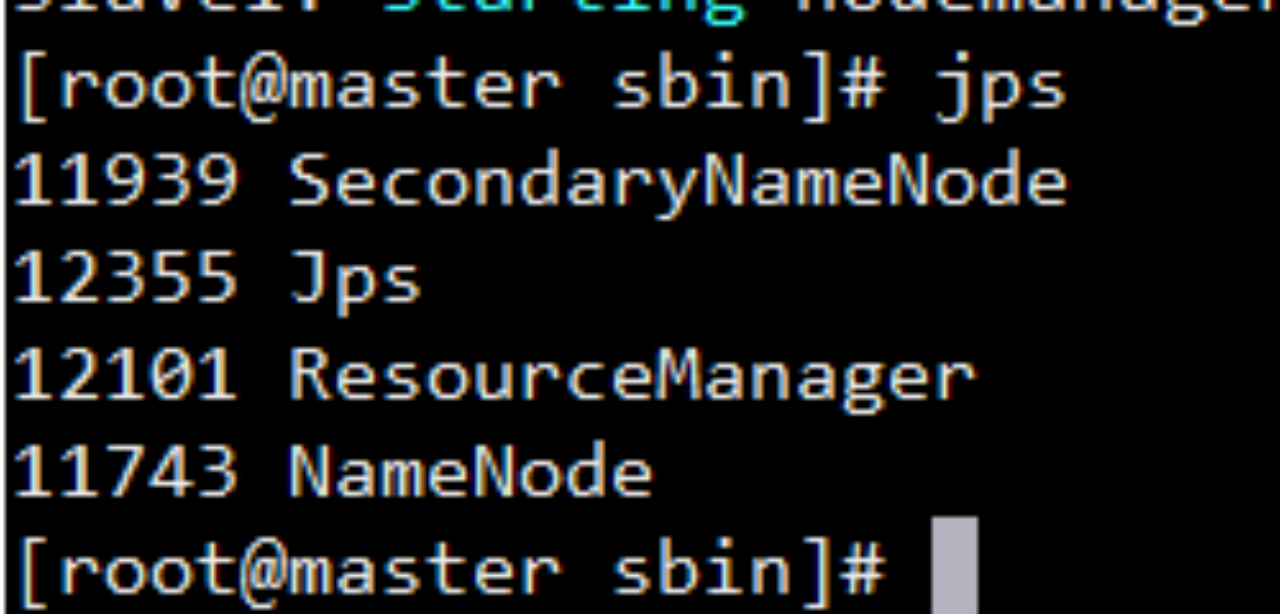
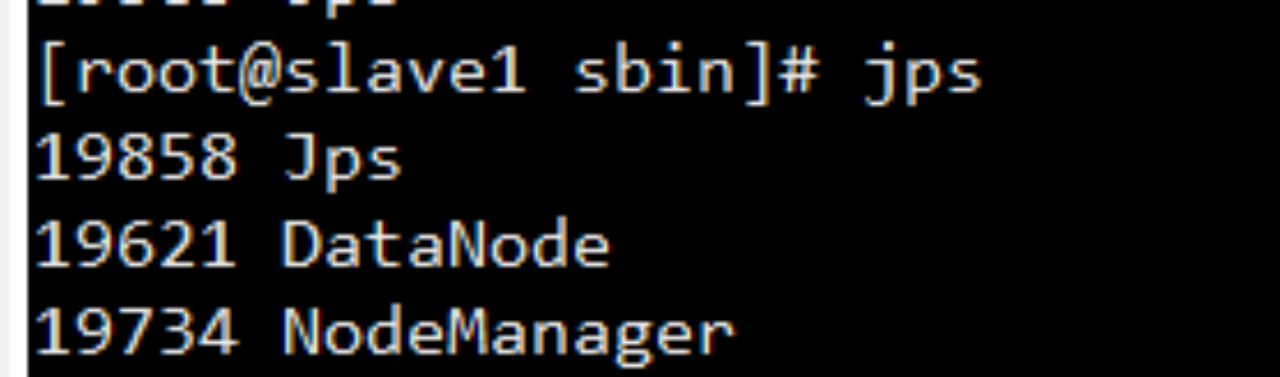
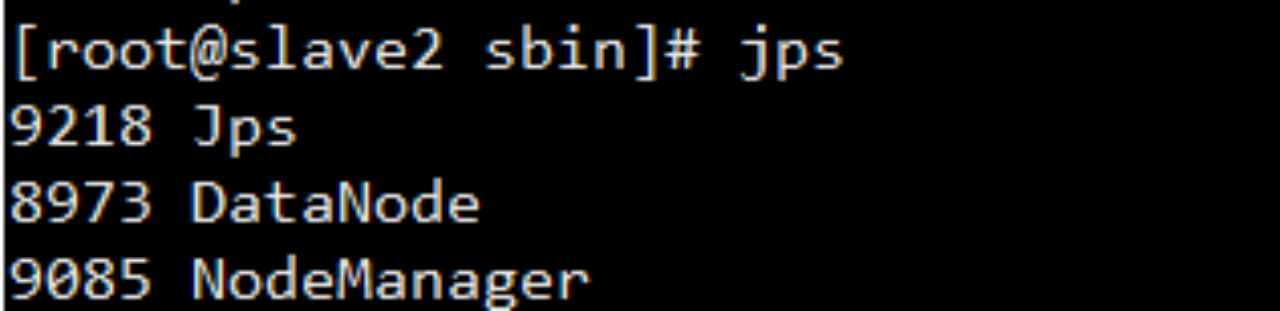
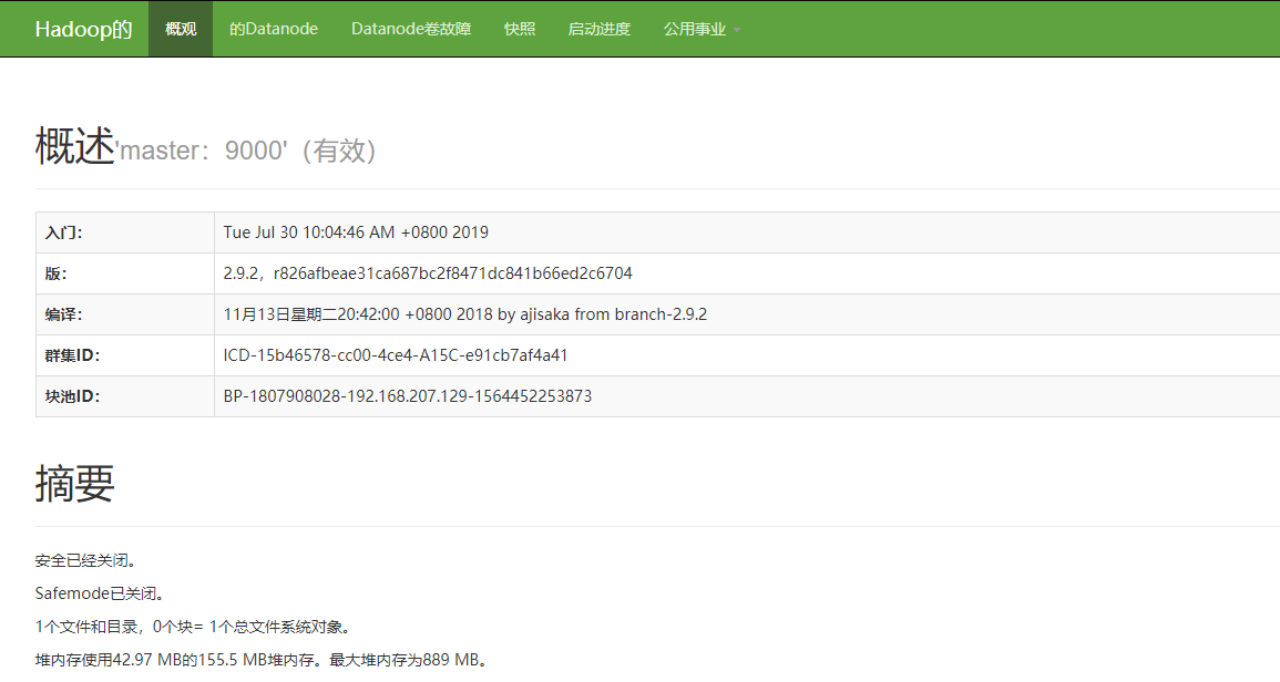
通过浏览器测试如下:
http://ip:50070/ 出现如下页面 代表成功
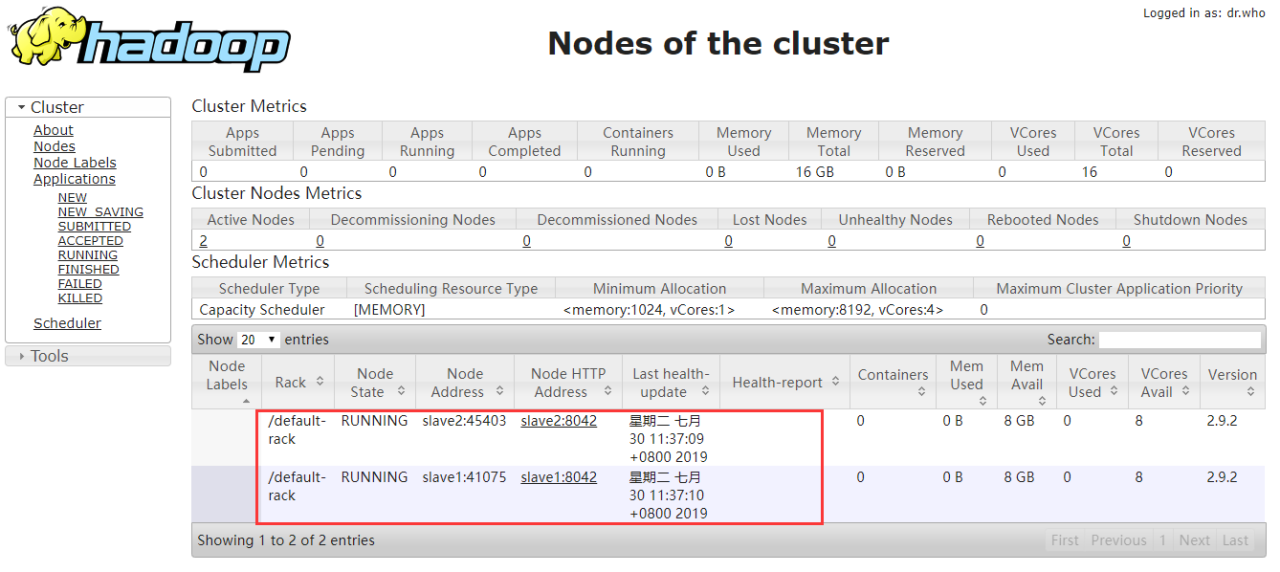
查看YARN的状态 可以看到有两个节点在运行
http://ip:8088/
Hadoop文件操作需要更改权限
更改dfs操作权限hadoop fs -chmod 777 /
7. Zookeeper 环境搭建

–解压缩 zookeeper安装包,并建立基本目录
#tar -zxvf zookeeper-3.4.14.tar.gz
#mkdir /usr/bigData/zookeeper-3.4.14/data
#mkdir /usr/bigData/zookeeper-3.4.14/log
–配置环境边量
#vi /etc/profile

然后使其生效
#source /etc/profile
–修改配置文件
–复制配置文件模版
#cd /usr/bigData/zookeeper-3.4.14/conf/
#cp zoo_sample.cfg zoo.cfg
–修改配置文件开始
#vim /usr/zookeeper-3.4.10/conf/zoo.cfg
添如下内容
dataDir=/usr/bigData/zookeeper-3.4.14/data
dataLogDir=/usr/bigData/zookeeper-3.4.14/log
server.1=master:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888
–创建myid文件(每个节点都需创建)
#cd /usr/bigData/zookeeper-3.4.14/data/
#touch myid
#vi myid
分别添加如下内容
1(master节点添加)
2(slave2节点添加)
3(slave3节点添加)
Zookeeper搭建成功
启动 查看 关闭 如下图
#cd /usr/bigData/zookeeper-3.4.14/bin/
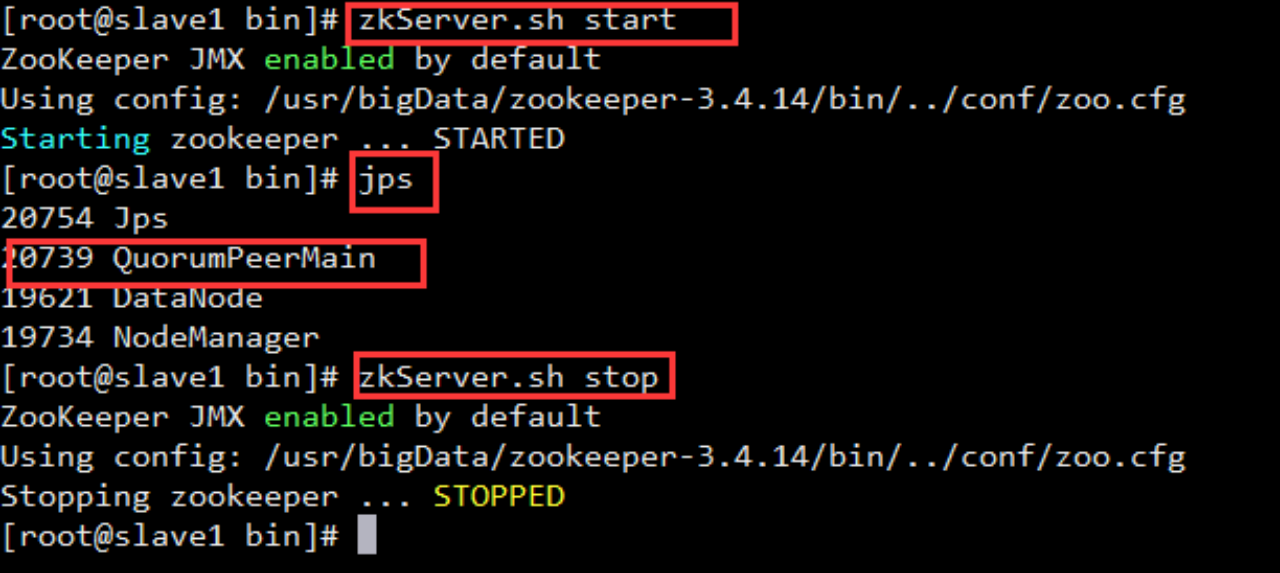
使用Shell命令查看zookeeper版本
echo stat|nc localhost 2181
启动zookeeper查看是否成功,每个节点都需分别启动
提供的shell命令启动关闭方法,只需在master运行一个命令即可
由于zookeeper启动需要每个节点分别启动 , 操作起来毕竟麻烦 , 提供一种通过shell命令启动 , 关闭 , 查看状态的方法
–新建shell文件夹
mkdir /usr/shell
–启动
vim /usr/shell/startzk.sh
输入如下内容
#!/bin/bash
echo “start zookeeper server…”
hosts=“master slave1 slave2”
for host in $hosts
do
ssh $host "source /etc/profile;/usr/zookeeper-3.4.10/bin/zkServer.sh start"
done
保存!
–关闭
vim /usr/shell/stopzk.sh
输入如下内容
#!/bin/bash
echo “stop zookeeper server…”
hosts=“master slave1 slave2”
for host in $hosts
do
ssh $host "source /etc/profile;/usr/zookeeper-3.4.10/bin/zkServer.sh stop"
done
保存!
–查看状态
vim /usr/shell/statuszk.sh
输入如下内容
#!/bin/bash
echo “status zookeeper server…”
hosts=“master slave1 slave2”
for host in $hosts
do
ssh $host "source /etc/profile;/usr/zookeeper-3.4.10/bin/zkServer.sh status"
done
注意:hosts = “” 里面有几个节点就写几个节点 , 我这里只有三个 , 故写了三个
ssh $host “” 注意zookeeper的安装路径 , 不要写错
最后分配权限
#chmod 777 ./startzk.sh
#chmod 777 ./stopzk.sh
chmod 777 ./statuszk.sh
eclipse配置
(1)将hadoop-eclipse-plugin-2.6.0.jar包复制到eclipse目录下的plugins目录下
(2)打开eclipse,配置hadoop路径
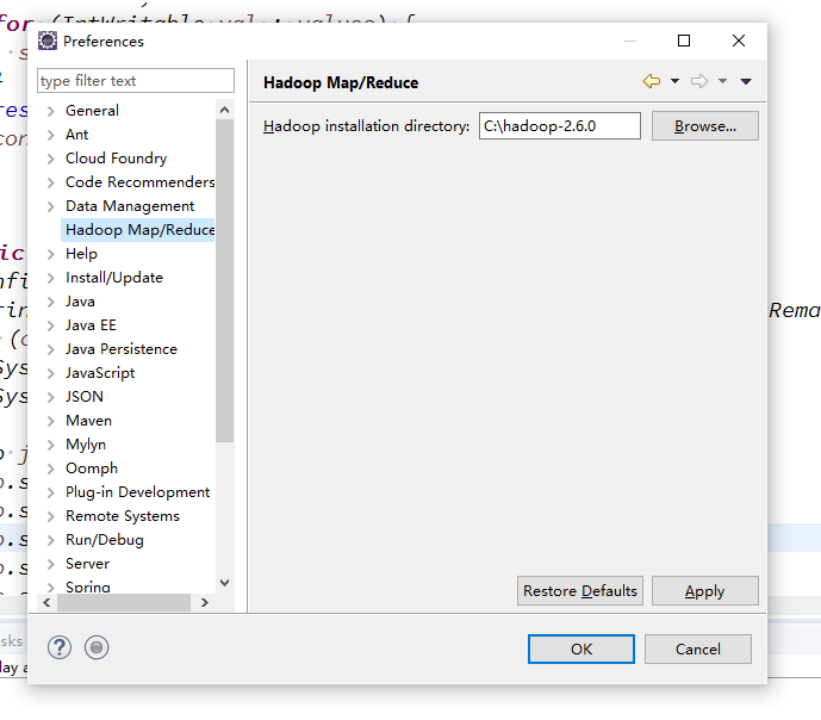
(3)开启Map/Reduce Locations视图
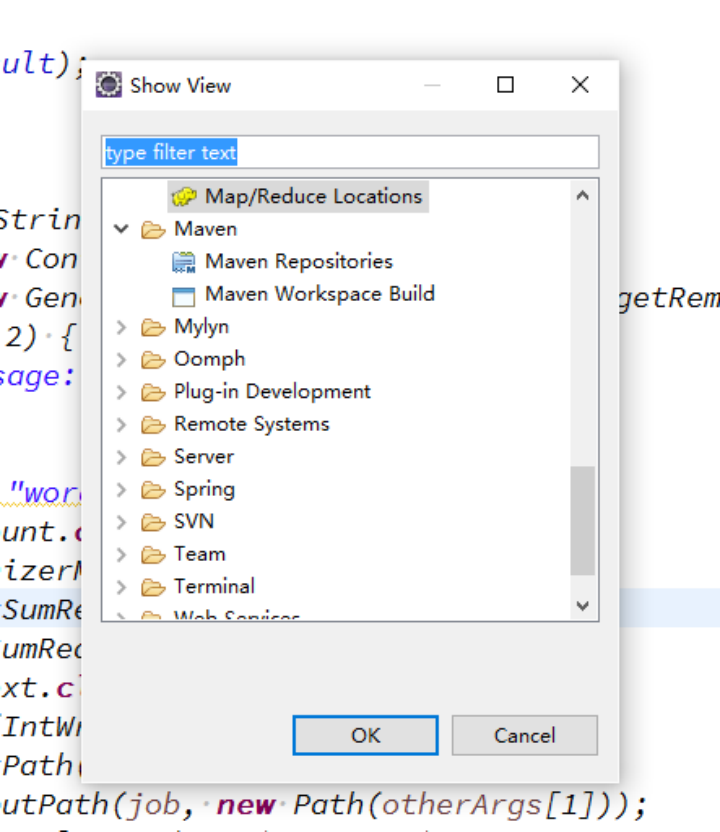
(4)连接hadoop集群(需事先启动集群)
新建hadoop location
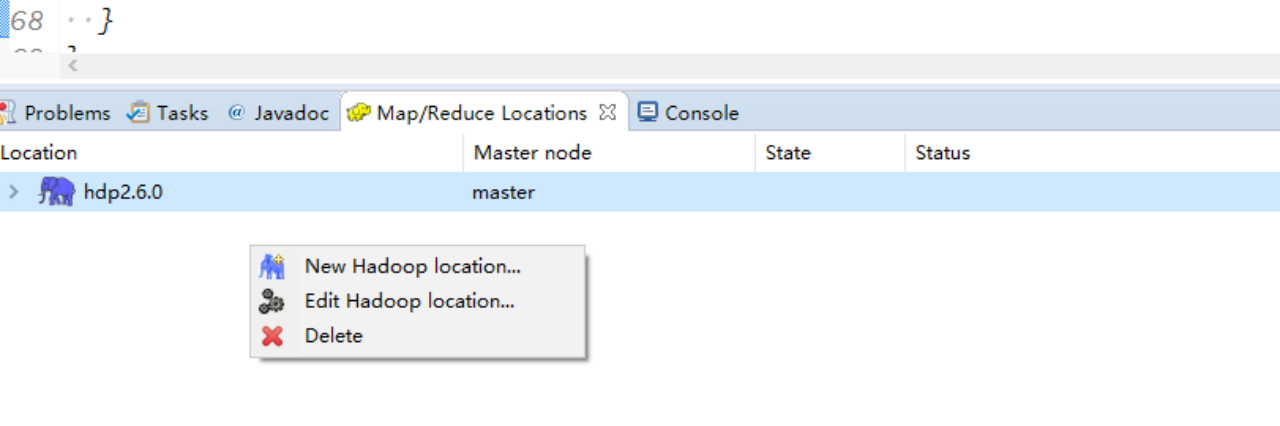
配置如下
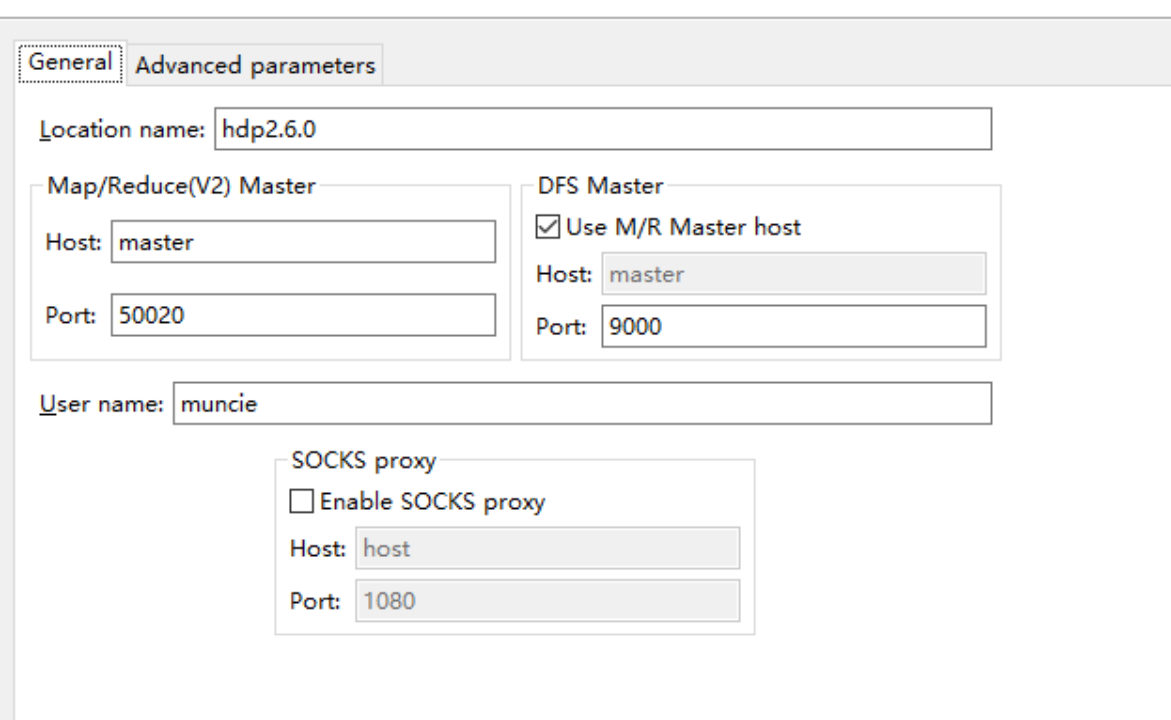
(5)在hadoop集群中新建几个文件夹,如果能在Project Explorer视图中的DFS Locations中看到相应目录结构,说明配置成功
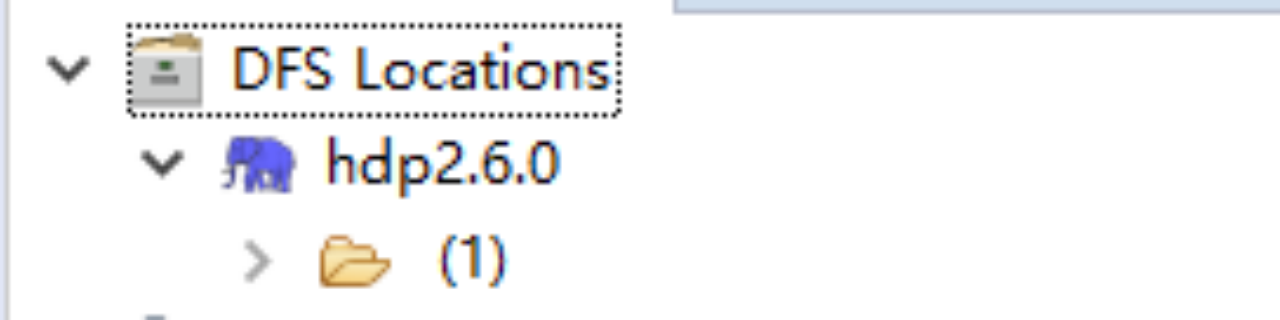
8. hbase环境搭建
–解压缩hbase安装包
#cd /usr/bigData/
#tar -zxvf hbase-2.0.5-bin.tar.gz
mkdir logs
–修改配置文件
vi /usr/bigData/hbase-2.0.5/conf/hbase-env.sh
添加如下内容
export JAVA_HOME=/usr/java/jdk1.8.0_221
export HBASE_LOG_DIR=KaTeX parse error: Expected 'EOF', got '#' at position 68: …改regionservers #̲vi /usr/bigData… jps
若bgs-5p173-wangwenting如下所示:
22898 ResourceManager
20739 Jps
24383 JobHistoryServer
20286 HMaster
22722 SecondaryNameNode
22488 NameNode
[hadoop@bgs-5p174-wangwenting opt]$ jps
2141 NodeManager
3257 HRegionServer
25283 Jps
1841 DataNode
[hadoop@bgs-5p175-wangwenting opt]$ jps
2141 NodeManager
3257 HRegionServer
25283 Jps
1841 DataNode
显示有HMaster和HRegionServer,则说明启动成功
8).使用/opt/hadoop/hbase/bin/hbase shell命令测试安装结果:
[hadoop@bgs-5p173-wangwenting opt]$ /opt/hbase/bin/hbase shell
a.创建表test:
hbase(main):002:0> create “test”, “cf”
0 row(s) in 2.5840 seconds
=> Hbase::Table - test
b.列出全部表:
hbase(main):003:0> list
TABLE
test
1 row(s) in 0.0310 seconds
=> [“test”]
如果在输入list,有好几次,启动Hadoop和HBase之后,执行jps命令,已经看到有HMaster的进程,但是进入到HBase的shell,执行一个命令,会出现下面的错误:
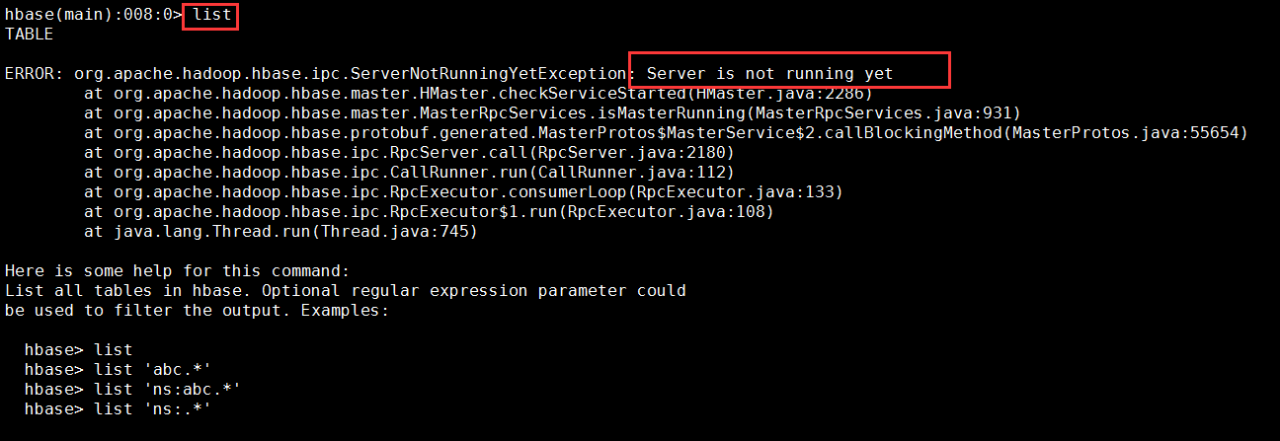
解决方法:
进入到logs目录查看master的日志:发现一直显示下面的内容:
vim hbase-hadoop-master-s1.log
2017-03-13 17:13:17,374 INFO org.apache.hadoop.hbase.util.FSUtils: Waiting for dfs to exit safe mode…
2017-03-13 17:13:27,377 INFO org.apache.hadoop.hbase.util.FSUtils: Waiting for dfs to exit safe mode…
2017-03-13 17:13:37,386 INFO org.apache.hadoop.hbase.util.FSUtils: Waiting for dfs to exit safe mode…
2017-03-13 17:13:47,393 INFO org.apache.hadoop.hbase.util.FSUtils: Waiting for dfs to exit safe mode…
2017-03-13 17:13:57,395 INFO org.apache.hadoop.hbase.util.FSUtils: Waiting for dfs to exit safe mode…
2017-03-13 17:14:07,409 INFO org.apache.hadoop.hbase.util.FSUtils: Waiting for dfs to exit safe mode…
原来是Hadoop在刚启动的时候,还处在安全模式造成的,手动退出Hadoop的安全模式.然后重新启动hbase服务。
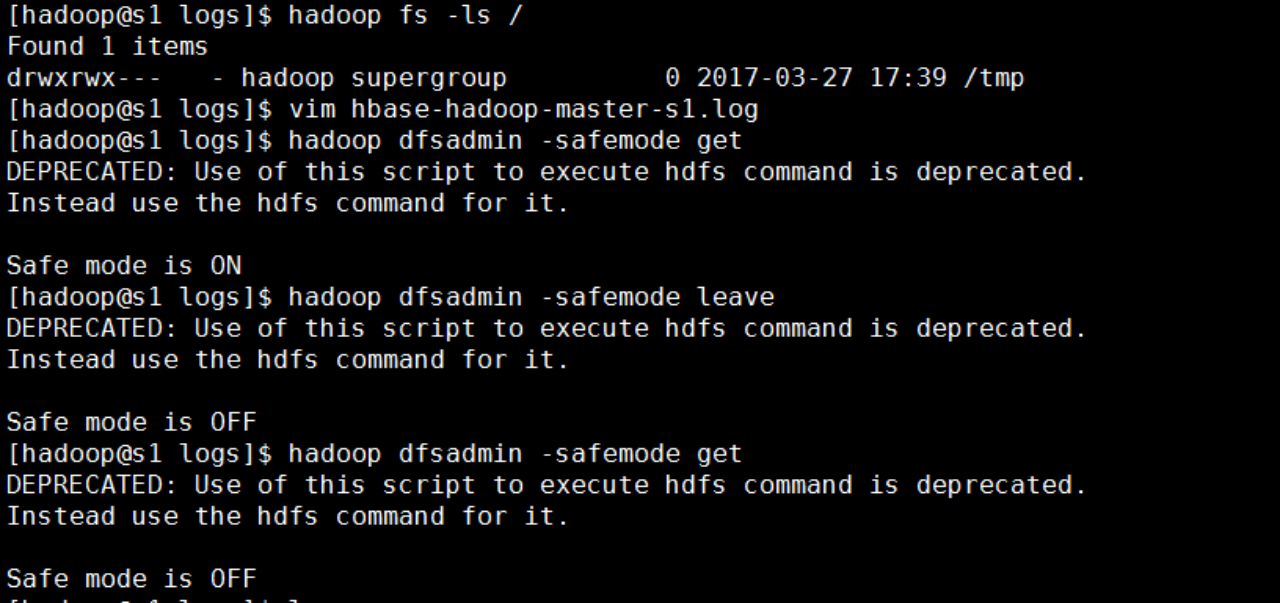
重启后输入list,便不再报错了。
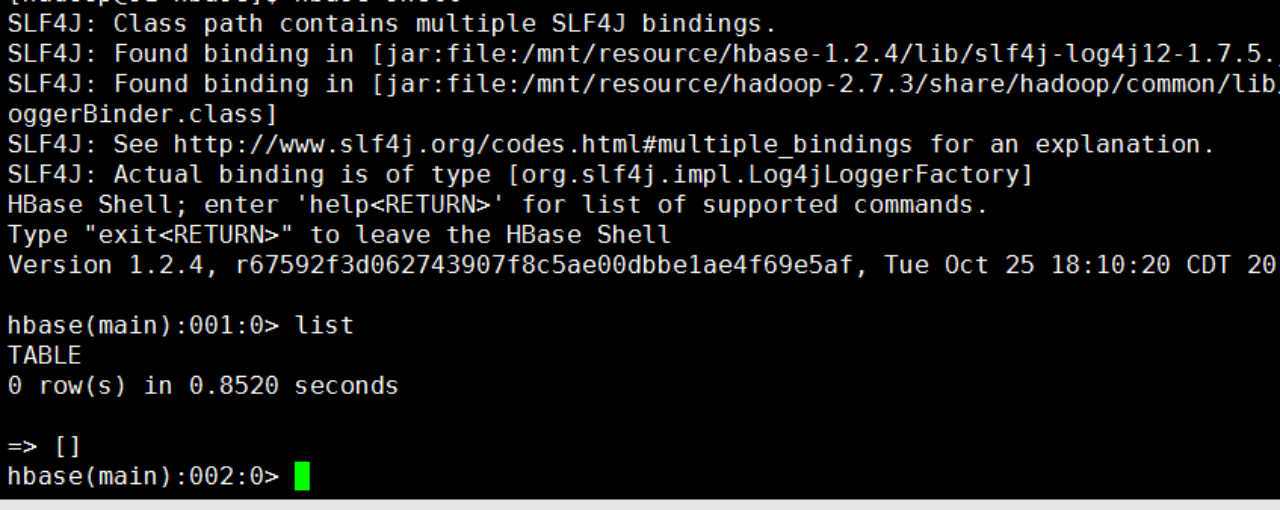
c.插入数据到test表:
hbase(main):001:0> put “test”,“row”,“cf:a”,“value”
0 row(s) in 0.4150 seconds
d.查看test表信息:
hbase(main):002:0> scan ‘test’
ROW COLUMN+CELL
row column=cf:a, timestamp=1447246157917, value=value
1 row(s) in 0.0270 seconds
若hbase shell测试成功,则进入浏览器访问以下网址:http://172.24.5.173:16010/,
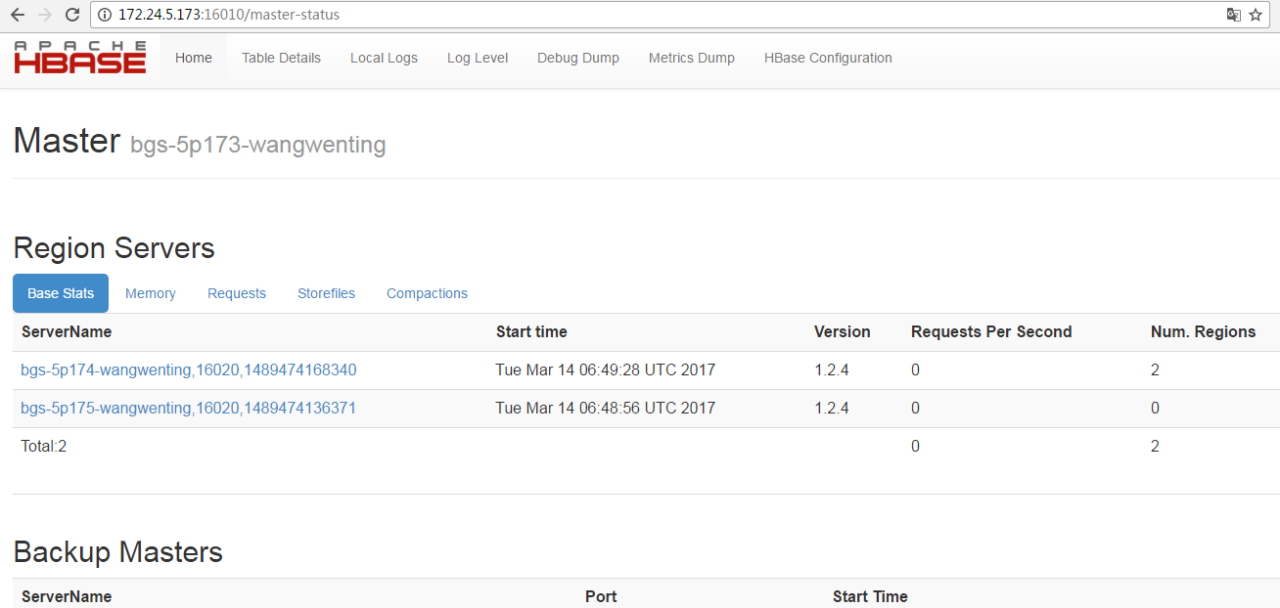
若正常显示,则hbase集群安装成功! 用ip保险一点,用域名首先要在自己的电脑host文件中配置。
9).启动thriftserver2服务
[hadoop@bgs-5p173-wangwenting opt]$ nohup /opt/hbase/bin/hbase-daemon.sh start thrift2 &

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











