







最近在学习嵩天老师在中国大学MOOC中开设的《Python网络爬虫与信息提取》网络课程。非常感谢嵩天老师精彩的讲解,嵩天讲课非常细致,辅以一定的实例,知识点讲解很透彻,一路跟下来,感觉学到不少东西 。
在《"中国大学排名定向爬虫"实例介绍》这节课程中,记录笔记如下:
1、程序总体设计
1)功能描述:
输入:大学排名URL链接
输出:大学排名信息的屏幕输出(排名,大学名称,总分)
技术路线:requests+bs4
定向爬虫:仅对输入URL进行爬取,不扩展爬取
2)程序结构设计:
步骤1:从网络上获取大学排名网页内容 getHTMLText()
步骤2:提取网页内容中信息到合适的数据结构 fillUnivList()
步骤3:利用数据结构展示输出结果 printUnivList()
通过查看url = 'http://www.zuihaodaxue.cn/zuihaodaxuepaiming2017.html' 网页源代码,可以发现如信息:
- <tbody>...</tbody>标签中包含了中国最好大学排名信息
- <tbody>...</tbody>标签的平行子节点<tr>...</tr>标签中包含了各大学信息
- <tr>...</tr>标签的平行子节点<td>...</td>标签中包含了各大学信息详尽信息,如大学排名、名称、地区、总分等信息。

<tbody class="hidden_zhpm" style="text-align:center;">
<tr class="alt">
<td>1
<td><div align="left">清华大学</div></td>
<td>北京</td>
<td>94.0 </td>
<td class="hidden-xs need-hidden indicator5">100.0 </td>
<td class="hidden-xs need-hidden indicator6" style="display:none;">97.70%</td>
<td class="hidden-xs need-hidden indicator7" style="display:none;">40938</td>
<td class="hidden-xs need-hidden indicator8" style="display:none;">1.381</td>
<td class="hidden-xs need-hidden indicator9" style="display:none;">1373</td>
<td class="hidden-xs need-hidden indicator10" style="display:none;">111</td>
<td class="hidden-xs need-hidden indicator11" style="display:none;">1263428</td>
<td class="hidden-xs need-hidden indicator12" style="display:none;">613524</td>
<td class="hidden-xs need-hidden indicator13" style="display:none;">7.04%</td>
</tr>
.
.
.
</tbody>2、程序代码编写
1)全代码如下:
import requests
from bs4 import BeautifulSoup
import bs4
# 获取网页信息的通用框架
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
#填充列表
def fillUnivList(ulist, html):
soup = BeautifulSoup(html, "html.parser")
for tr in soup.find('tbody').children:
# 检查网页代码可以发现数据都储存在tboyd标签中,这里需要对tbody的儿子节点进行遍历
if isinstance(tr, bs4.element.Tag):
# 检测标签类型,如果不是bs4库支持的Tag类型,就过滤掉,这里需要先导入bs4库
tds = tr('td') #等价于tr.find_all("td")
# 解析出tr标签中的td标签后,将其储存在列表tds中
ulist.append([tds[0].string, tds[1].string, tds[3].string])
# 我们需要的是排名、学校名称和总分
# 格式化后,输出列表数据
def printUnivList(ulist, num):
tplt = '{:^10}\t{:^10}\t{:^10}'
# 定义输出模板为变量tplt,\t为横向制表符,^为居中对齐,10为每列的宽度
print(tplt.format("排名","学校名称","总分"))
# format()方法做格式化输出
for i in range(num):
u=ulist[i]
print(tplt.format(u[0],u[1],u[2]))
def main():
uinfo = []
url = 'http://www.zuihaodaxue.cn/zuihaodaxuepaiming2017.html'
html = getHTMLText(url)
soup = BeautifulSoup(html, "html.parser")
fillUnivList(uinfo, html)
printUnivList(uinfo, 20) # 输出20个大学信息
main()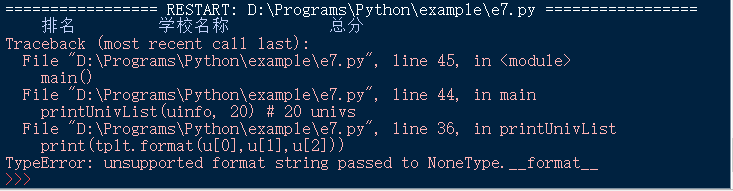
2)结果分析
我只是修改了URL链接,其他的都没变。查看url = 'http://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html' 网页源代码,发现相比2017,在大学排名处有稍微的改动。2016的把大学排名放在诸如<td>1</td>标签中,而2017的则改为<td>1<td>,这并不形成一个标签。

print(tds[0].string)
type(tds[0].string)
print(tds[1].string+'+'+tds[2].string+'+'+tds[3].string)
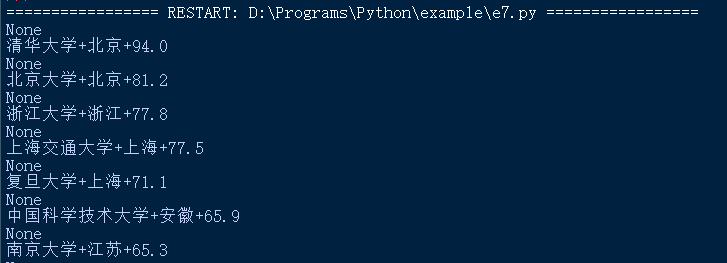
可以看出tds[0].string内容为空,并不是想要提取的大学排名信息,是 NoneType类型;tds[1].string、tds[2].string、tds[3].string中信息分别为大学名称、大学地区、大学总分。从这里就可以理解,修改URL后,程序运行报出错误:
TypeError: unsupported format string passed to NoneType.__format__
那么怎么对程序进行修改,能准确提取除大学排名信息呢?BeautifulSoup是遍历HTML标签的函数库,由于大学排名信息并不保存在标签中,因此不能使用BeautifulSoup提取出大学排名信息。
通过发现,大学排名信息都是在'<td>N<td>'字符串中,因此可以使用正则表达式 '<td>[0-9]+<td>' 匹配。导入re库
import redef fillUnivList(ulist, html):
soup = BeautifulSoup(html, "html.parser")
bank = re.findall(r'<td>[0-9]+<td>',html) #匹配所有包含大学排名信息的字符串
i = 0;
for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag):
tds = tr('td')
ulist.append([bank[i].split('<td>')[1],tds[1].string, tds[3].string])
i = i + 1;
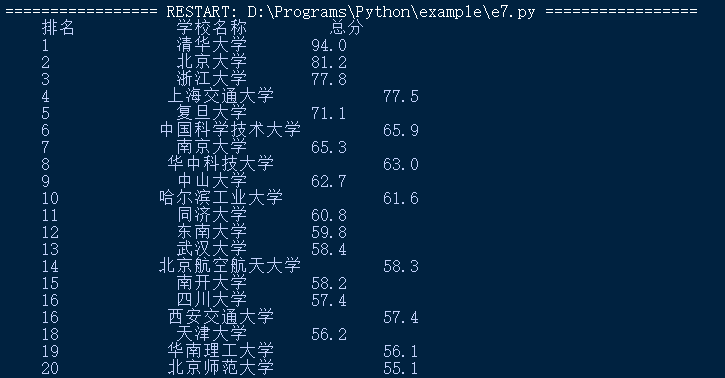
3、输入结果中文对齐问题
上述输出中,存在中文不对齐的情况。

解决办法:采用中文字符空格填充 chr(12288)
修改printUnivList()函数为如下:
# 格式化后,输出列表数据
def printUnivList(ulist, num):
tplt = '{0:^10}\t{1:{3}^10}\t{2:^10}'
# 定义输出模板为变量tplt,\t为横向制表符,^为居中对齐,10为每列的宽度
print(tplt.format("排名","学校名称","总分",chr(12288)))
# format()方法做格式化输出
for i in range(num):
u=ulist[i]
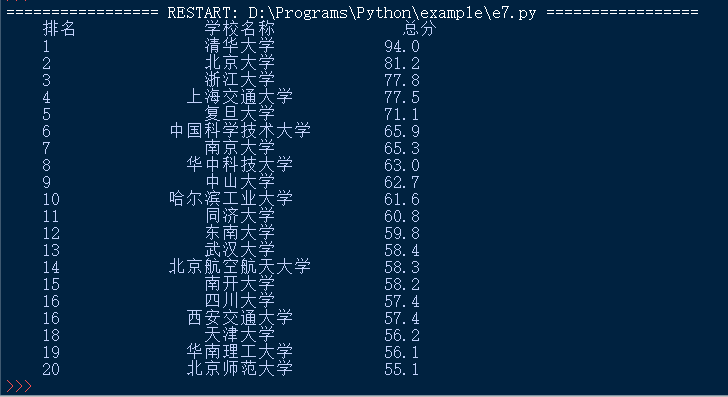
print(tplt.format(u[0],u[1],u[2],chr(12288)))程序运行结果如下。实现了中文居中对齐。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









