







背景介绍
本文对多个平台的多个类型的新闻数据信息进行爬虫,并且进行数据分析提取出相关主题新闻的关键词,并进行可视化分析和机器学习,对新的新闻主题进行判定。
1、新闻爬虫
本文爬取了新浪新闻、微博、人民日报等多个平台的新闻数据,以新浪为例进行数据爬虫介绍:
爬虫主要是通过找到新闻控制的超链接,如:f'http://mil.news.sina.com.cn/roll/index.d.html?cid=57918&page={j}'该链接为新浪的军情新闻数据的链接,通过解析该链接的数据信息可以获得具体的新闻内容,最后,将爬取的数据保存到txt中,代码如下:
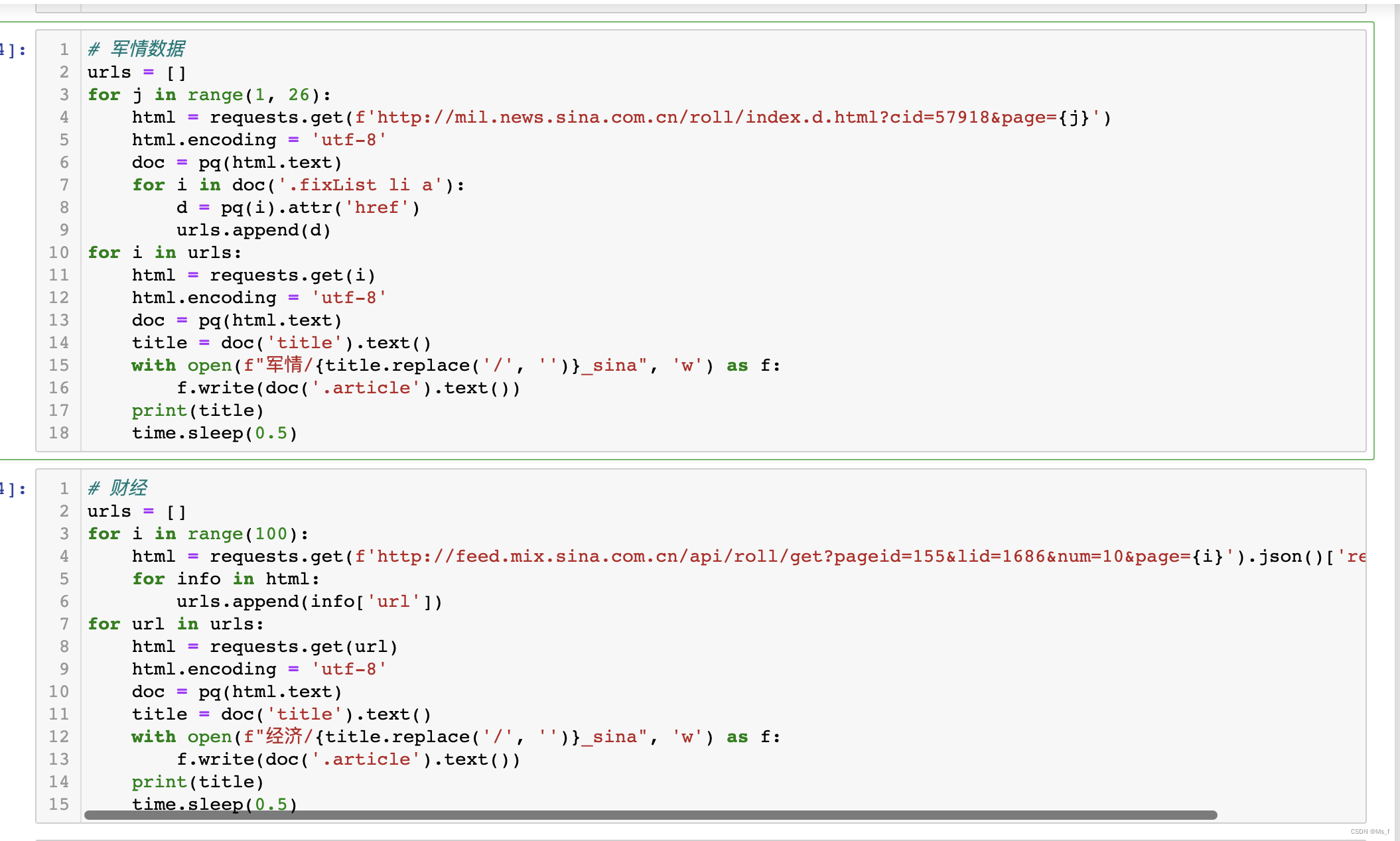
这样就可以批量获取多个平台的新闻数据,为之后的数据分析和机器学习提供数据基础。
2、机器学习建模分析
在对新闻文本进行机器学习建模分析的时候,最主要的是对中文进行词向量化处理,其中,关键为对中文进行中文分词。其中,中文分词如下:

中文分词后,使用tf-idf对中文分词结果进行词向量化处理,结果如下:

最后,使用处理完毕的向量矩阵进行机器学习建模分析:
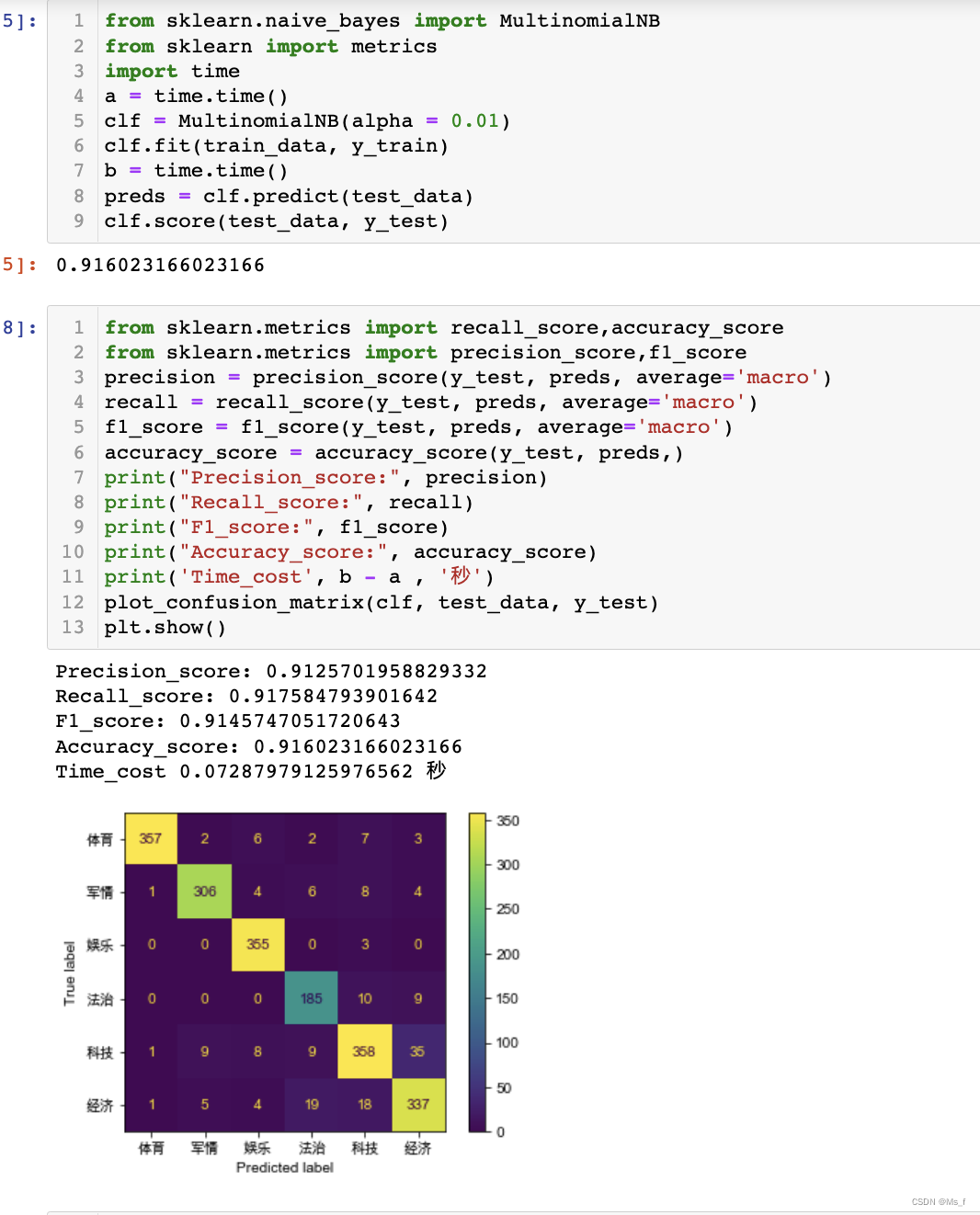
3、数据可视化分析
这里进行的数据可视化分析主要就是词云图分析,具体就是对所有的新闻进行中文分词,分词完毕后统计各个词语出现的频率,最后,使用pyecharts进行词云图绘制。
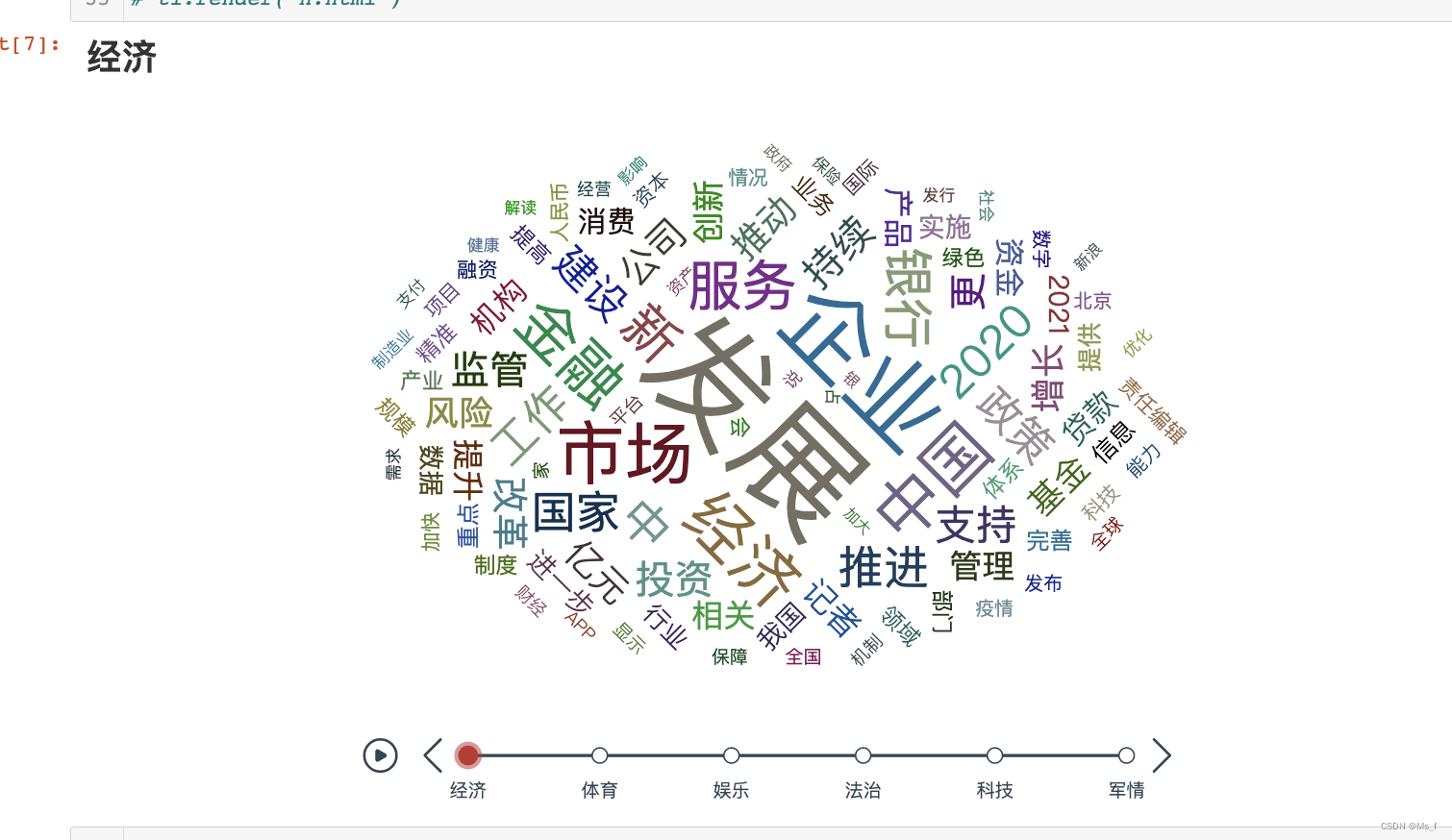
上图为分析结果。
源码 定制数据分析v:km_0224


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









