






答案参考:推荐系统中,双塔模型用于粗排和用于召回的区别有哪些? - 知乎
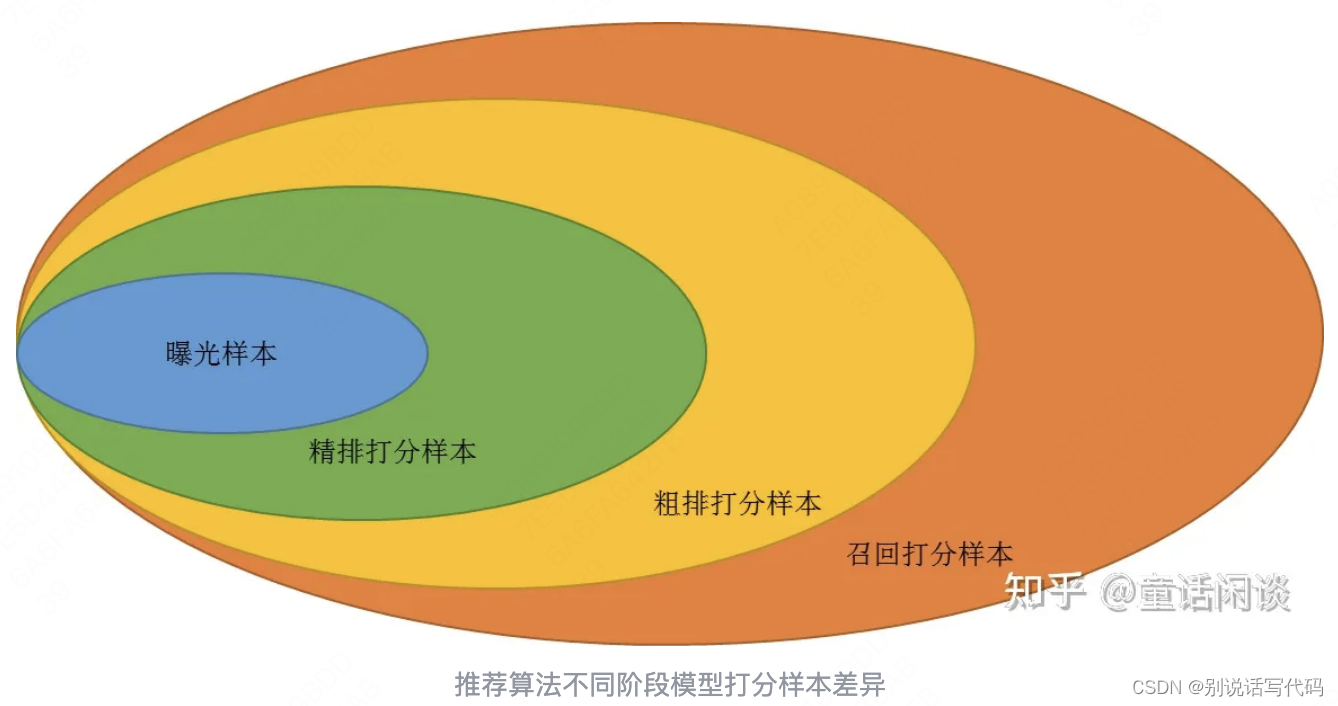
召回和粗排在不同阶段面临样本不一样,对双塔来说样本分布差异会使召回和粗排采取不一样的方式。召回打分空间是全部item空间,曝光只有很少一部分,同时双塔召回只是多路召回的一种,因此双塔会从几个方面优化:
召回负样本选择,会采用一些策略进行负样本采样。
粗排打分空间已经变小,曝光样本和打分样本差异相对较小,曝光对粗排来说是比较重要的样本,粗排采用精排打分扩充也是常见做法。粗排和精排一致性相对较高,因此粗排一般用多目标公式融合,同时有很多蒸馏方案加强与精排目标的一致性。
召回和粗排的双塔有以下区别:
- 样本
- 召回正例是真实正例,负例通过采样(全局采样、batch内采样等)得到。
- 粗排正负例都是从用户的真实正负例中选取。
- 特征:无区别
- 网络结构:粗排和召回在网络结构的区别是:双塔的交互时机不同。
- 召回一般是通过双塔分别得到user emb和feed emb,然后简单进行cos/mul计算;为了效率以及使用近邻搜索组件来进行线上召回,双塔之间的交互只能在最后的emb层来做。
- 粗排可以在双塔的底层就可以对不同塔的特征进行交互得到交叉特征。
- Loss
- 召回一般是单目标模型,通过pointwise(sigmoid)或者pairwise(sample softmax)来计算loss。如果需要达到多目标的效果。一般业内有两种做法,一种根据多个目标训练多个召回模型,然后线上多路召回/融合;一种是不同行为做加权生成label权重,通过调节label权重来达到多目标的效果。
- 粗排一般是多目标模型,不同目标得分进行融合得到粗排分。
- 评估
- 召回使用的评估指标是hit rate等指标
- 粗排一般使用排序的评估指标auc、uauc等


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









