







基于SparkSQL的网站日志分析实战
用户行为日志概述
用户行为日志:用户每次访问网站时所有的行为数据(访问、浏览、搜索、点击...)
用户行为轨迹、流量日志
- 为什么要记录用户访问行为日志
- 网站页面的访问量
- 网站的黏性
- 推荐
2.用户行为日志生成渠道
- Nginx
- Ajax
3.用户行为日志内容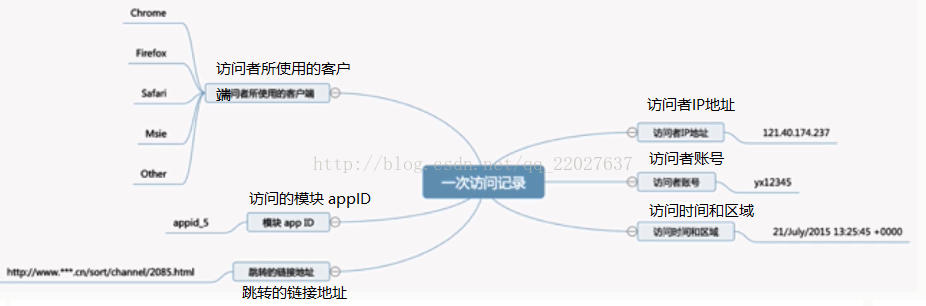
日志数据内容:
1)访问的系统属性: 操作系统、浏览器等等
2)访问特征:点击的url、从哪个url跳转过来的(referer)、页面上的停留时间等
3)访问信息:session_id、访问ip(访问城市)等
日志信息如下所示:4.用户行为日志分析的意义2013-05-19 13:00:00 http://www.taobao.com/17/?tracker_u=1624169&type=1 B58W48U4WKZCJ5D1T3Z9ZY88RU7QA7B1 http://hao.360.cn/ 1.196.34.243
- 网站的眼睛(访问者来自什么地方,找什么东西,那些页面最受欢迎,访问者的入口地址是什么等)
- 网站的神经(网站布局是否合理,导航层次是否清晰,功能是否存在问题,转换路径是否靠谱)
- 网站的大脑(如何分析目标,如何分配广告预算(广告推广))
离线数据处理架构
数据处理流程
1)数据采集
Flume: web日志写入到HDFS
2)数据清洗
脏数据
Spark、Hive、MapReduce 或者是其他的一些分布式计算框架
清洗完之后的数据可以存放在HDFS(Hive/Spark SQL)
3)数据处理
按照我们的需要进行相应业务的统计和分析
Spark、Hive、MapReduce 或者是其他的一些分布式计算框架
4)处理结果入库
结果可以存放到RDBMS、NoSQL
5)数据的可视化
通过图形化展示的方式展现出来:饼图、柱状图、地图、折线图
ECharts、HUE、Zeppelin
离线数据处理架构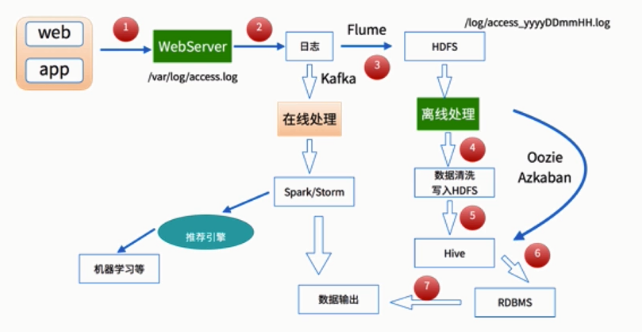
项目需求
- 需求一:统计imooc主站最受欢迎的课程/手记的Top N访问次数
- 需求二:按地市统计imooc主站最受欢迎的Top N课程
(1).根据IP地址提取出城市信息(2).窗口函数在Spark SQL中的使用
- 按流量统计imooc主站最受欢迎的Top N课程
功能实现
网站主站日志介绍
- 访问时间
- 访问URL
- 访问过程耗费流量
- 访问IP地址
数据清洗
原始日志
10.100.0.1 - - [10/Nov/2016:00:01:02 +0800] "HEAD / HTTP/1.1" 301 0 "117.121.101.40" "-" - "curl/7.19.7 (x86_64-redhat-linux-gnu) libcurl/7.19.7 NSS/3.16.2.3 Basic ECC zlib/1.2.3 libidn/1.18 libssh2/1.4.2" "-" - - - 0.000
第一次清洗后(访问时间 主站URL 耗费的流量 ip地址)代码实现参见gitee地址【https://gitee.com/robei/SparkSQLProject/blob/master/src/main/scala/com/imooc/log/SparkStatFormatJob.scala】2017-05-11 15:07:17 http://www.imooc.com/video/14322 245 202.96.134.133 2017-05-11 06:52:31 http://www.imooc.com/article/17891 535 222.129.235.182 2017-05-11 18:46:43 http://www.imooc.com/article/17898 807 218.75.35.226
第二次数据清洗
输入:访问时间、访问URL、耗费的流量、访问IP地址信息
输出:URL、cmsType(video/article)、cmsId(编号)、流量、ip、城市信息、访问时间、天
代码实现参见gitee地址【https://gitee.com/robei/SparkSQLProject/blob/master/src/main/scala/com/imooc/log/SparkStatCleanJob.scala】
根据ip地址解析城市信息
使用github上已有的开源项目
1)git clone https://github.com/wzhe06/ipdatabase.git
2)编译下载的项目:mvn clean package -DskipTests
3)安装jar包到自己的maven仓库
mvn install:install-file -Dfile=~/source/ipdatabase/target/ipdatabase-1.0-SNAPSHOT.jar -DgroupId=com.ggstar -DartifactId=ipdatabase -Dversion=1.0 -Dpackaging=jar
数据清洗存储到目标地址()
【https://gitee.com/robei/SparkSQLProject/blob/e60788c9e0f3c2ffc446d9aa8acaa5a66ac006fc/src/main/scala/com/imooc/log/SparkStatCleanJob.scala】需求一的实现:统计主站最受欢迎的课程/手记的Top N访问次数需求二:按地市统计主站最受欢迎的Top N课程/** * 需求一:主站最受欢迎的TopN课程统计 * * @param spark * @param cleanDF */ def videoAccessTopNStat(spark: SparkSession, cleanDF: DataFrame, day:String): Unit = { //------------------使用DataFrame API完成统计操作-------------------------------------------- /* import spark.implicits._ val videoAccessTopNDF = cleanDF.filter($"day" === day && $"cmsType" === "video") .groupBy("day","cmsId").agg(count("cmsId").as("times")).orderBy($"times".desc)*/ // videoAccessTopNDF.printSchema() /** * root * |-- day: string (nullable = true) * |-- cmsId: long (nullable = true) * |-- times: long (nullable = false) */ // videoAccessTopNDF.show(10,false) /** * +--------+-----+------+ * |day |cmsId|times | * +--------+-----+------+ * |20170511|14540|111027| * |20170511|4000 |55734 | * |20170511|14704|55701 | * |20170511|14390|55683 | * |20170511|14623|55621 | * |20170511|4600 |55501 | * |20170511|4500 |55366 | * |20170511|14322|55102 | * +--------+-----+------+ */ //-------------------------使用SQL API完成操作------------------------- cleanDF.createOrReplaceTempView("access_logs") //创建临时表 access_logs val videoAccessTopNDF = spark.sql("select day,cmsId,count(1) as times from access_logs" + " where day="+day+" and cmsType='video'" + " group by day,cmsId order by times desc") videoAccessTopNDF.show(10, false) /** * +--------+-----+------+ * |day |cmsId|times | * +--------+-----+------+ * |20170511|14540|111027| * |20170511|4000 |55734 | * |20170511|14704|55701 | * |20170511|14390|55683 | * |20170511|14623|55621 | * |20170511|4600 |55501 | * |20170511|4500 |55366 | * |20170511|14322|55102 | * +--------+-----+------+ */ //-------------------将统计结果写入数据库------------------- try { videoAccessTopNDF.foreachPartition(partitionOfRecords => { val list = new ListBuffer[DayVideoAccessStat] partitionOfRecords.foreach(info => { val day = info.getAs[String]("day") val cmsId = info.getAs[Long]("cmsId") val times = info.getAs[Long]("times") list.append(DayVideoAccessStat(day, cmsId, times)) }) StatDAO.insertDayVideoAccessTopN(list) }) }catch { case e:Exception => e.printStackTrace() } /** * 在mysql中创建day_video_access_topn_stat,主站最受欢迎的Top N课程 * create table day_video_access_topn_stat ( * day varchar(8) not null, * cms_id bigint(10) not null, * times bigint(10) not null, * primary key (day, cms_id) * ); */ }
需求三:按照流量统计主站最受欢迎的Top N课程/** * 需求二:按地市统计主站最受欢迎的Top N课程 * @param spark * @param cleanDF */ def cityAccessTopSata(spark: SparkSession, cleanDF: DataFrame, day:String): Unit = { //------------------使用DataFrame API完成统计操作-------------------------------------------- import spark.implicits._ val cityAccessTopNDF = cleanDF.filter($"day" === day && $"cmsType" === "video") .groupBy("day","city","cmsId").agg(count("cmsId").as("times")).orderBy($"times".desc) // cityAccessTopNDF.printSchema() /** * root * |-- day: string (nullable = true) * |-- city: string (nullable = true) * |-- cmsId: long (nullable = true) * |-- times: long (nullable = false) */ // cityAccessTopNDF.show(false) /** * +--------+----+-----+-----+ * |day |city|cmsId|times| * +--------+----+-----+-----+ * |20170511|浙江省 |14540|22435| * |20170511|北京市 |14540|22270| * |20170511|安徽省 |14540|22149| * |20170511|广东省 |14540|22115| * |20170511|上海市 |14540|22058| * |20170511|北京市 |4600 |11271| * |20170511|安徽省 |14390|11229| * |20170511|广东省 |14623|11226| * |20170511|上海市 |14704|11219| * |20170511|广东省 |14704|11216| * |20170511|广东省 |4600 |11215| * |20170511|上海市 |4000 |11182| * |20170511|北京市 |14390|11175| * |20170511|广东省 |4000 |11169| * |20170511|上海市 |4500 |11167| * |20170511|安徽省 |14704|11162| * |20170511|北京市 |4000 |11156| * |20170511|浙江省 |14322|11151| * |20170511|上海市 |14623|11149| * |20170511|广东省 |4500 |11136| * +--------+----+-----+-----+ */ //-----------Window函数在Spark SQL中的使用-------------------- val cityTop3DF = cityAccessTopNDF.select( cityAccessTopNDF("day"), cityAccessTopNDF("city"), cityAccessTopNDF("cmsId"), cityAccessTopNDF("times"), row_number().over(Window.partitionBy(cityAccessTopNDF("city")) .orderBy(cityAccessTopNDF("times").desc)).as("times_rank") ).filter("times_rank <= 3").orderBy($"city".desc,$"times_rank".asc) cityTop3DF.show(false)//展示每个地市的Top3 /** * +--------+----+-----+-----+----------+ * |day |city|cmsId|times|times_rank| * +--------+----+-----+-----+----------+ * |20170511|浙江省 |14540|22435|1 | * |20170511|浙江省 |14322|11151|2 | * |20170511|浙江省 |14390|11110|3 | * |20170511|广东省 |14540|22115|1 | * |20170511|广东省 |14623|11226|2 | * |20170511|广东省 |14704|11216|3 | * |20170511|安徽省 |14540|22149|1 | * |20170511|安徽省 |14390|11229|2 | * |20170511|安徽省 |14704|11162|3 | * |20170511|北京市 |14540|22270|1 | * |20170511|北京市 |4600 |11271|2 | * |20170511|北京市 |14390|11175|3 | * |20170511|上海市 |14540|22058|1 | * |20170511|上海市 |14704|11219|2 | * |20170511|上海市 |4000 |11182|3 | * +--------+----+-----+-----+----------+ */ //-------------------将统计结果写入数据库------------------- try { cityTop3DF.foreachPartition(partitionOfRecords => { val list = new ListBuffer[DayCityVideoAccessStat] partitionOfRecords.foreach(info => { val day = info.getAs[String]("day") val cmsId = info.getAs[Long]("cmsId") val city = info.getAs[String]("city") val times = info.getAs[Long]("times") val timesRank = info.getAs[Int]("times_rank") list.append(DayCityVideoAccessStat(day, cmsId,city, times,timesRank)) }) StatDAO.insertDayCityVideoAccessTopN(list) }) }catch { case e:Exception => e.printStackTrace() } /** * create table day_video_city_access_topn_stat ( * day varchar(8) not null, * cms_id bigint(10) not null, * city varchar(20) not null, * times bigint(10) not null, * times_rank int not null, * primary key (day, cms_id, city) * ); */ }
【https://gitee.com/robei/SparkSQLProject】/** * 需求三:按照流量统计主站最受欢迎的Top N课程 * @param spark * @param cleanDF */ def videoTraffsTopStat(spark: SparkSession, cleanDF: DataFrame, day:String): Unit = { //------------------使用DataFrame API完成统计操作-------------------------------------------- import spark.implicits._ val trafficsTopNDF = cleanDF.filter($"day" === day && $"cmsType" === "video") .groupBy("day","cmsId").agg(sum("traffic").as("traffics")).orderBy($"traffics".desc) trafficsTopNDF.show() /** * +--------+-----+--------+ * | day|cmsId|traffics| * +--------+-----+--------+ * |20170511|14540|55454898| * |20170511|14390|27895139| * |20170511| 4500|27877433| * |20170511| 4000|27847261| * |20170511|14623|27822312| * |20170511| 4600|27777838| * |20170511|14704|27737876| * |20170511|14322|27592386| * +--------+-----+--------+ */ //-------------------将统计结果写入数据库------------------- try { trafficsTopNDF.foreachPartition(partitionOfRecords => { val list = new ListBuffer[DayVideoTrafficsStat] partitionOfRecords.foreach(info => { val day = info.getAs[String]("day") val cmsId = info.getAs[Long]("cmsId") val traffics = info.getAs[Long]("traffics") list.append(DayVideoTrafficsStat(day, cmsId,traffics)) }) StatDAO.insertDayVideoTrafficsTopN(list) }) }catch { case e:Exception => e.printStackTrace() } /** * create table day_video_traffics_topn_stat ( * day varchar(8) not null, * cms_id bigint(10) not null, * traffics bigint(20) not null, * primary key (day, cms_id) * ); */ }















 5087
5087

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









