







目录
1、mysql索引
1.1、索引的结构
MySQL的基本存储结构是页(记录都存在页里面),各个数据页可以组成一个双向链表,每个数据页都会为存储在它里面的记录生成一个页目录,每个数据页中的内容又可以组成一个单向链表。
在中InnoDB 1页 默认16kb
1.2、页结构:
如下图 真实结构

便于理解的结构
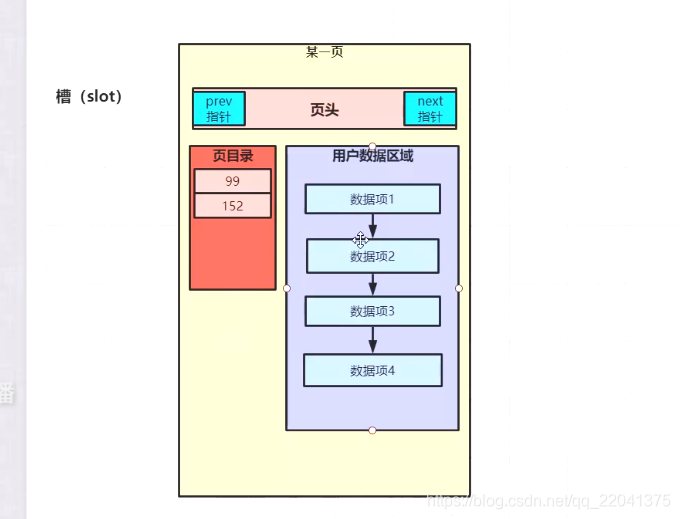
思考:1、一条数据 4字节 一页存多少记录?
4096条记录
2、页目录如何查找用户区域数据? 通过2分查找法找用户区域数据
3、每页(每个槽)存储几条记录?
每组 4-8条记录,到达8条拆分成2组、槽记录最后数据的位置
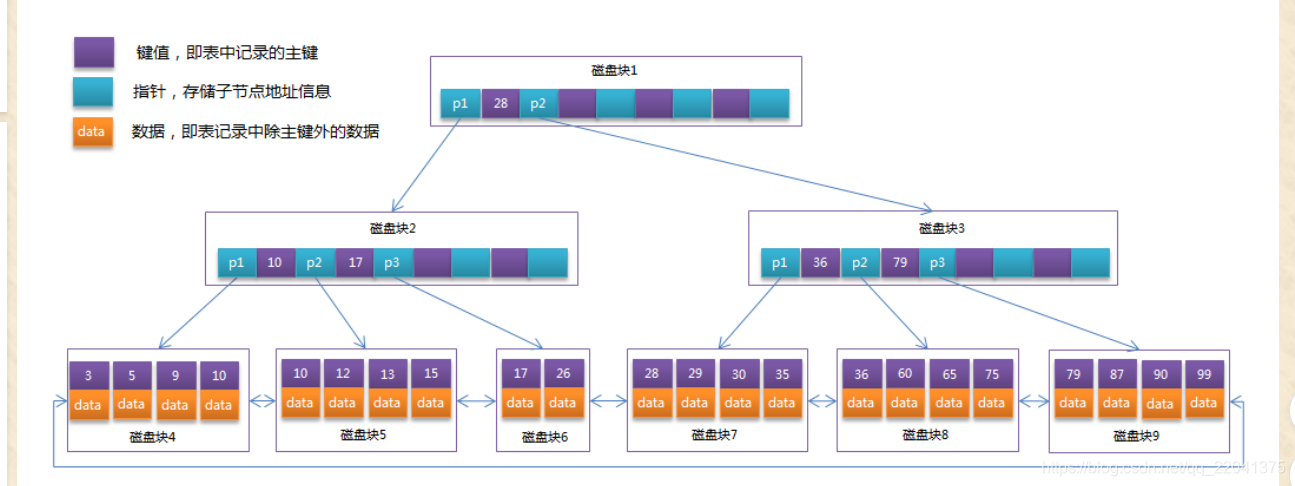
1.3 索引的结构b+tree
总体:数据块为双向链表、上层节点为页数的节点
结构图:
2、聚集索引与非聚集索引
聚集索引是指数据库表行中数据的物理顺序与键值的逻辑(索引)顺序相同。一个表只能有一个聚集索引,因为一个表的物理顺序只有一种情况,所以,对应的聚集索引只能有一个。如果某索引不是聚集索引,则表中的行物理顺序与索引顺序不匹配,与非聚集索引相比,聚集索引有着更快的检索速度。
非聚集索引是一种索引,该索引中索引的逻辑顺序与磁盘上行的物理存储顺序不同。
总结 :聚集索引:有索引存了所有数据
非聚集索引:有索引,只存了数据的id(主键) 查询可能存在回表
3、什么是回表

利用上了几个索引字段
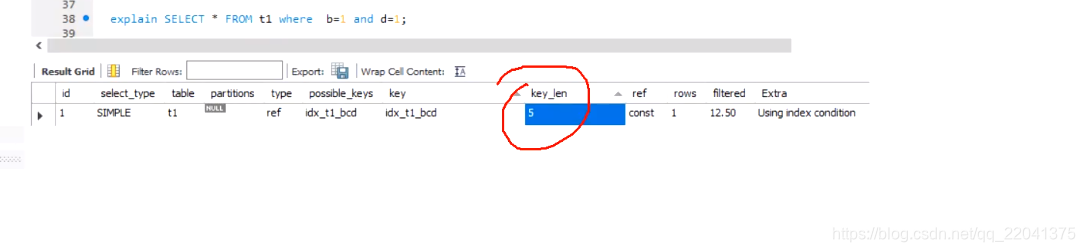
网上的图 表达的很明白
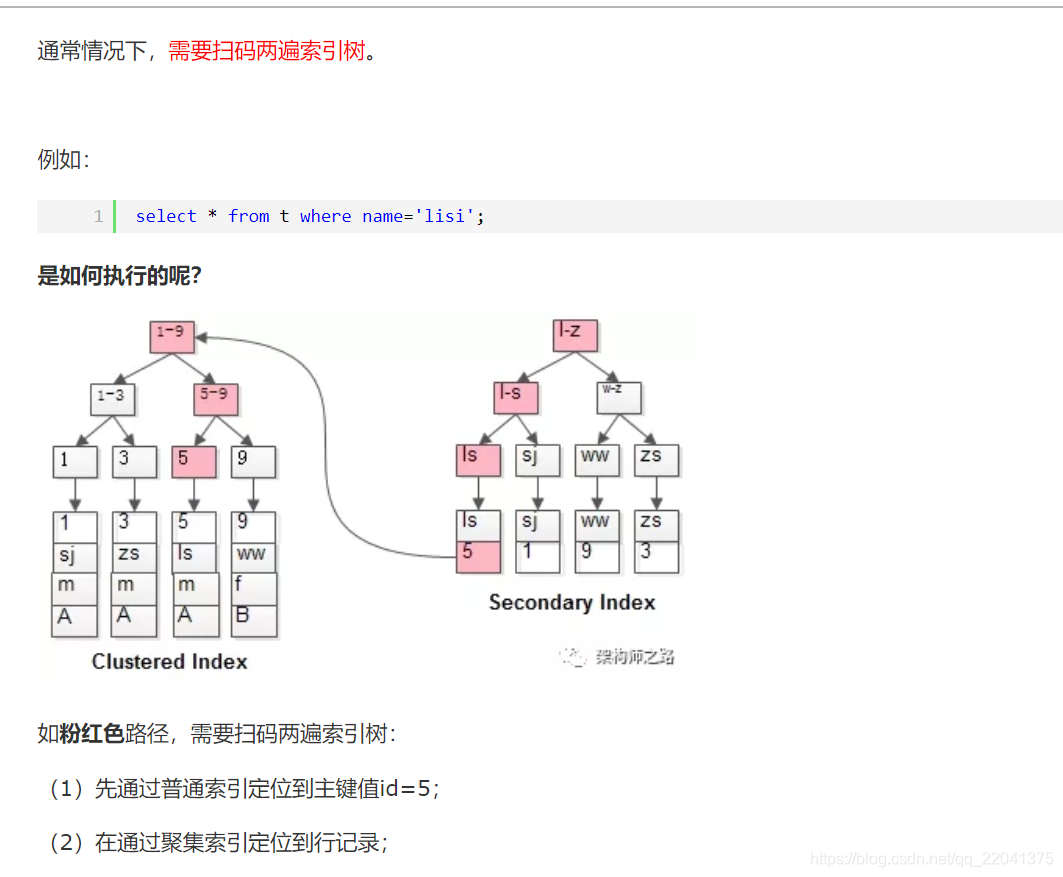
这就是所谓的回表查询,先定位主键值,再定位行记录,它的性能较扫一遍索引树更低。
4、什么是索引覆盖(解决回表的方法)
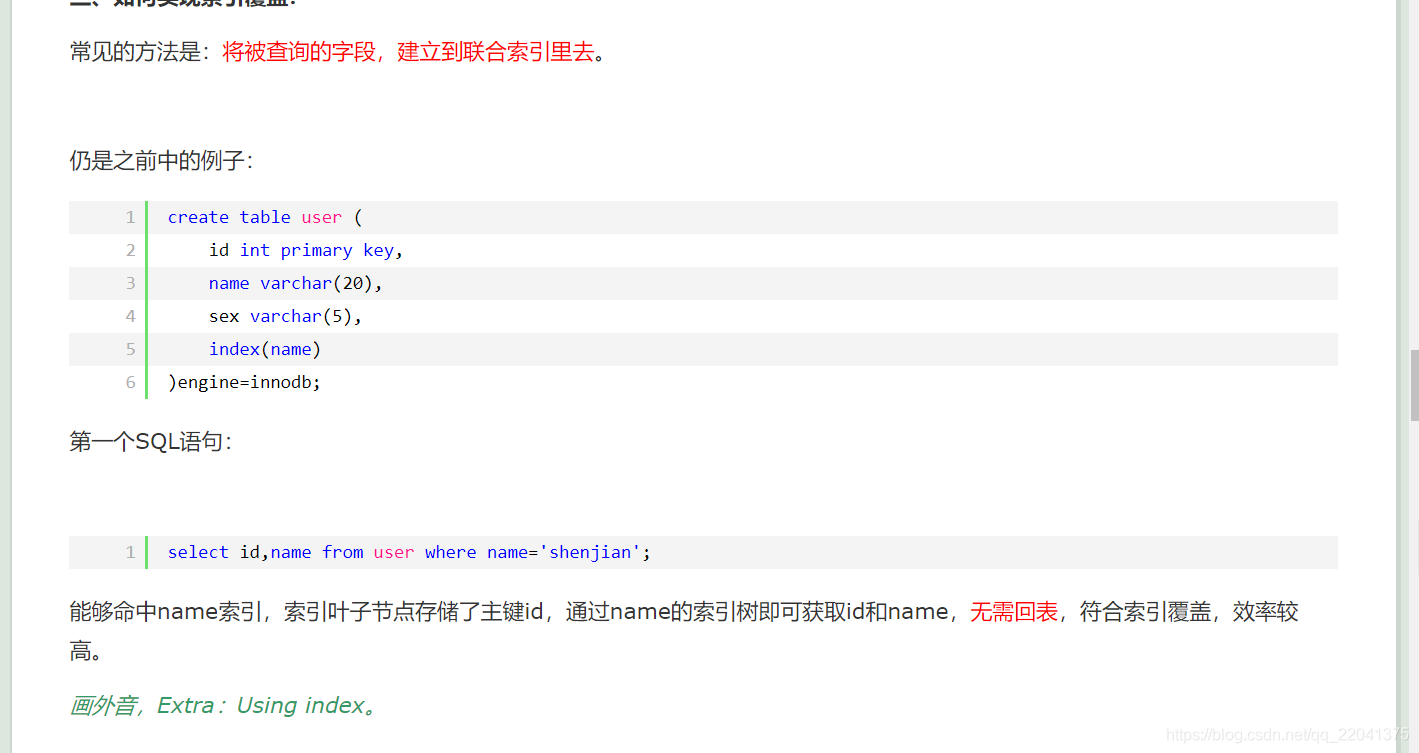
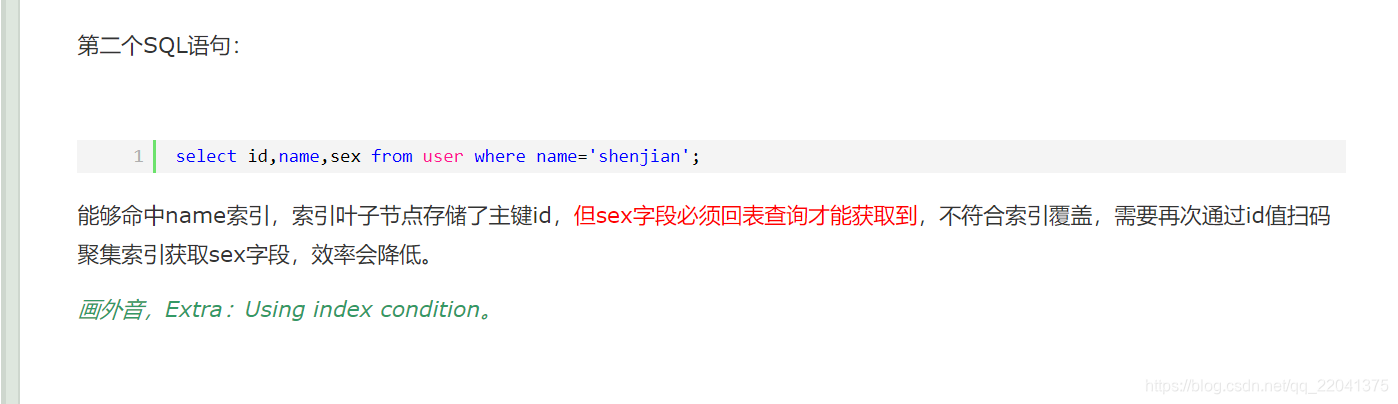
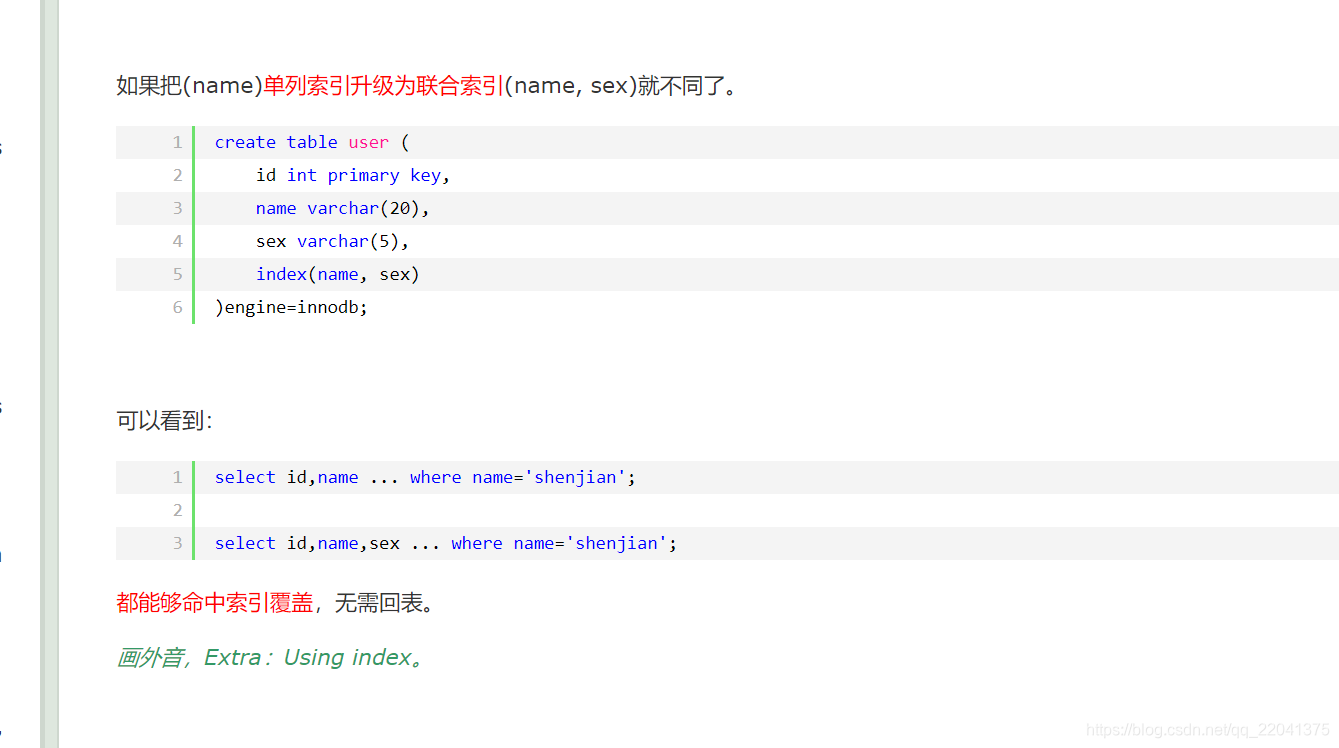
5、 uuid与自增int型id性能上对比
经过500W、1000W的单机表测试,自增ID相对UUID来说,自增ID主键性能高于UUID,磁盘存储费用比UUID节省一半的钱。所以在单实例上或者单节点组上,使用自增ID作为首选主键。














 850
850











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









