







要点1:驱动表的连接条件考虑建立索引
--Nested Loops Join访问次数前环境准备
DROP TABLE t1 CASCADE CONSTRAINTS PURGE;
DROP TABLE t2 CASCADE CONSTRAINTS PURGE;
CREATE TABLE t1 (
id NUMBER NOT NULL,
n NUMBER,
contents VARCHAR2(4000)
)
;
CREATE TABLE t2 (
id NUMBER NOT NULL,
t1_id NUMBER NOT NULL,
n NUMBER,
contents VARCHAR2(4000)
)
;
execute dbms_random.seed(0);
INSERT INTO t1
SELECT rownum, rownum, dbms_random.string('a', 50)
FROM dual
CONNECT BY level <= 100
ORDER BY dbms_random.random;
INSERT INTO t2 SELECT rownum, rownum, rownum, dbms_random.string('b', 50) FROM dual CONNECT BY level <= 100000
ORDER BY dbms_random.random;
COMMIT;
select count(*) from t1;
select count(*) from t2;
实验1、没有建立索引之前的执行计划。
alter session set statistics_level=all ;
SELECT /*+ leading(t1) use_nl(t2) */ * FROM t1, t2 WHERE t1.id = t2.t1_id AND t1.n = 19;
select * from table(dbms_xplan.display_cursor(null,null,'allstats last'));
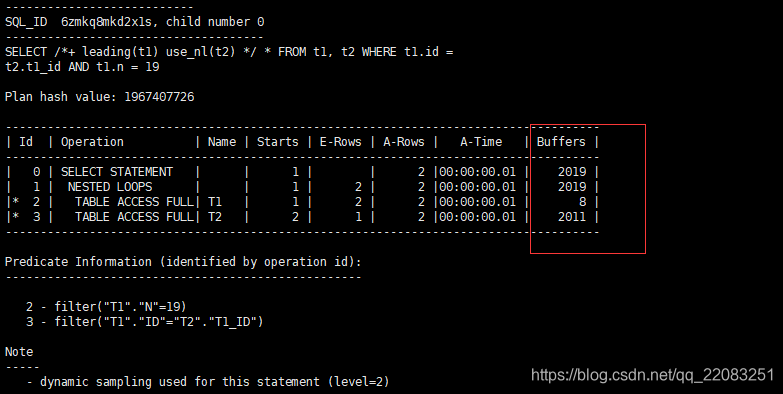
实验2、在驱动表的连接条件上建立索引后的执行计划
CREATE INDEX t1_n ON t1 (n);
alter session set statistics_level=all ;
SELECT /*+ leading(t1) use_nl(t2) */ * FROM t1, t2 WHERE t1.id = t2.t1_id AND t1.n = 19;
select * from table(dbms_xplan.display_cursor(null,null,'allstats last'));

结果,在驱动表的连接条件上建立索引之后,buffer从2019下降到了2015。
要点2:被驱动的限制条件(where)建立索引
实验3:在被驱动表的限制条件建立索引。
CREATE INDEX t2_t1_id ON t2(t1_id)
alter session set statistics_level=all ;
SELECT * FROM t1, t2 WHERE t1.id = t2.t1_id AND t1.n = 19;
select * from table(dbms_xplan.display_cursor(null,null,'allstats last'));

结果,buffer从2015下降到了11。
要点3:确保小结果集作为驱动表,大的结果集作为被驱动表。
构造实验环境:
ROP TABLE t1 CASCADE CONSTRAINTS PURGE;
DROP TABLE t2 CASCADE CONSTRAINTS PURGE;
CREATE TABLE t1 (
id NUMBER NOT NULL,
n NUMBER,
contents VARCHAR2(4000)
)
;
CREATE TABLE t2 (
id NUMBER NOT NULL,
t1_id NUMBER NOT NULL,
n NUMBER,
contents VARCHAR2(4000)
)
;
CREATE INDEX t1_n ON t1 (n);
CREATE INDEX t2_t1_id ON t2(t1_id);
--然后继续进入SESSION,执行
execute dbms_random.seed(0);
INSERT INTO t1
SELECT rownum, rownum, dbms_random.string('a', 50)
FROM dual
CONNECT BY level <= 10000
ORDER BY dbms_random.random;
INSERT INTO t2 SELECT rownum, rownum, rownum, dbms_random.string('b', 50) FROM dual CONNECT BY level <= 100000
ORDER BY dbms_random.random;
COMMIT;
实验1:驱动表的连接条件建立索引,被驱动表的限制条件建立索引
SELECT * FROM t1, t2 WHERE t1.id = t2.t1_id AND t1.n <= 19
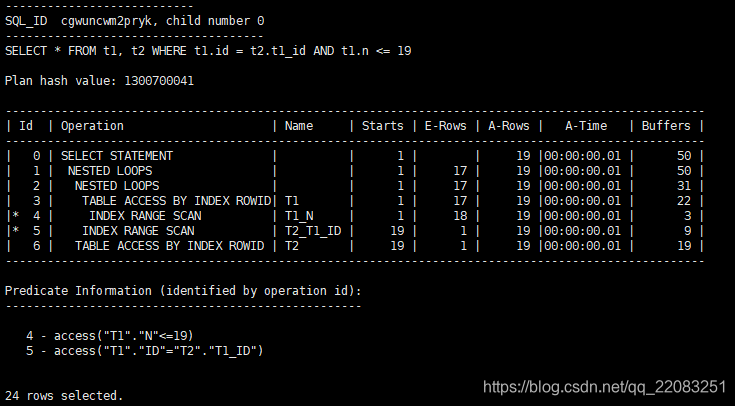
结论:oracle默认使用nl连接,驱动表访问一次,返回19行被驱动表被访问19次,返回了19行。
实验二:欺骗Oracle,更改Oracle的统计信息,使得Oracle误认为T1表是大表,T2表时小表。
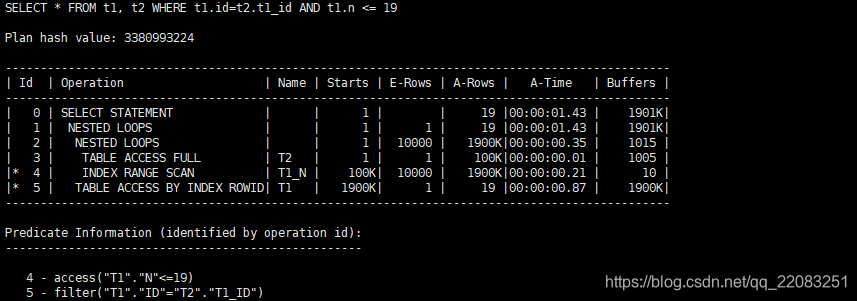
结论:由于将统计信息故意改错了,在实际执行的时候发现t2表访问了1次返回了100k条,t1表通过索引访问100k次返回了1900k条数据,然后从rowid中回表访问1900k次却返回了19条数据。导致buffers 达到原来的1000倍。在生产环境汇总经常出现的案例由于统计信息的错误导致执行计划的错误。














 7124
7124











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









