







 本文详细分析了LinkedHashMap的源码,解释了其如何通过可变长数组+单向链表+双向链表来实现元素的插入或访问有序。LinkedHashMap在HashMap的基础上增加了后继和前驱指针,以维持插入或访问顺序,同时重写了HashMap的相关方法以优化遍历和迭代器。双向链表的设计减少了空间使用,访问和更新操作会调整节点位置,确保最近访问的元素位于链表尾部。
本文详细分析了LinkedHashMap的源码,解释了其如何通过可变长数组+单向链表+双向链表来实现元素的插入或访问有序。LinkedHashMap在HashMap的基础上增加了后继和前驱指针,以维持插入或访问顺序,同时重写了HashMap的相关方法以优化遍历和迭代器。双向链表的设计减少了空间使用,访问和更新操作会调整节点位置,确保最近访问的元素位于链表尾部。
前面我们已经分析过了HashMap的源码, 我们已经知道了HashMap的底层的数据组织就是一个可变长的数组加一个单向链表来实现的,元素储存在hash表中的位置由其hash值和数组大小来确定,如果发生了hash冲突是使用拉链法(也就是单向链表)来解决的。因此HashMap里面储存的元素是无序的,但是有时候我们需要一个有序的集合,JDK提供的集合包中就提供了这样的类来满足我们的要求。它们分别是TreeMap与LinkedHashMap。TreeMap实现了hash表中按键有序,遍历TreeMap可以得到按键(key)的从小到大输出,TreeMap的底层是使用红黑树来实现的,它的源码我们以后在来分析。LinkHashMap是HashMap的子类,它保持了元素按插入或者访问有序。插入有序比较好理解,就是put操作对应的顺序,更改key对应的value值不会改变插入顺序。那么什么是访问顺序呢?所谓访问就是指get/put操作,对一个键执行get/put操作后,其对应的键值对会移到链表末尾。所以最后面的是最近访问的,最开始的是最久没被访问的,这种顺序就是访问顺序。
为了方便下面的解释,我们先给出LinkedHashMap的底层数据组织形式:可变长数组+单向链表+双向链表。其中可变长数组+单向链表的功能和HashMap的功能是一样的,用来实现O(1)时间内元素的put/get操作。双向链表用来记录元素的插入顺序或者访问顺序。
先看下面一个关于访问顺序的例子:
import java.util.LinkedHashMap;
import java.util.Map;
public class LinkedHashMapTest {
public static void main(String[] args) {
LinkedHashMap<Character, Integer> lm = new LinkedHashMap<>(16,0.75f,true);
lm.put('a',1);
lm.put('b',2);
lm.put('c',3);
lm.get('b');
lm.get('a');
for(Map.Entry<Character, Integer> entry : lm.entrySet()) {
System.out.println(entry.getKey() + " : " + entry.getValue());
}
}
}
对应的输出:
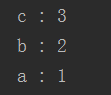
a是最后访问的,所以a输出在最后,b其次,c输出在最前面。通过这个例子,相信大家就明白什么是访问顺序了。
下面我们来看LinkedHashMap的源码:
先看构造函数:
// LinkedHashMap 继承自HashMap,并且实现了Map接口
public class LinkedHashMap<K,V> extends HashMap< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 653
653











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









