







CIPS 2016 笔记整理
《中文信息处理发展报告(2016)》是中国中文信息学会召集专家对本领域学科方向和前沿技术的一次梳理,官方定位是深度科普,旨在向政府、企业、媒体等对中文 信息处理感兴趣的人士简要介绍相关领域的基本概念和应用方向,向高校、科研院所和 高技术企业中从事相关工作的专业人士介绍相关领域的前沿技术和发展趋势。
本专栏主要是针对《中文信息处理发展报告(2016)》做的笔记知识整理,方便日后查看。
注意:本笔记不涉及任何代码以及原理分析研究探讨,主要是对NLP的研究进展、现状以及发展趋势有一个清晰的了解,方便以后更加深入的研究。
ps:我已将思维导图以及Markdown版本、pdf版本上传到我的GitHub中,有需要的可以自行查看:
https://github.com/changliang5811/CIPS-2016.git
传送门:
CIPS 2016(1-3章)——词法、句法、语义、语篇分析
CIPS 2016(4-5章)——语言认知模型、语言表示以及深度学习
CIPS 2016(6-7章)——知识图谱、文本分类与聚类
CIPS 2016(8-10章)——信息抽取、情感分析&自动文摘
CIPS 2016(11-12章)——信息检索、信息推荐与过滤
前言
自动问答(Question Answering, QA)是指利用计算机自动回答用户所提出的问题以满足用户知识需求的任务。不同于现有搜索引擎,问答系统是信息服务的一种高级形式,系统返回用户的不再是基于关键词匹配排序的文档列表,而是精准的自然语言答案。近年来,随着人工智能的飞速发展,自动问答已经成为倍受关注且发展前景广泛的研究方向。自动问答的研究历史可以溯源到人工智能的原点。1950 年,人工智能之父阿兰图灵(Alan M. Turing)在《Mind》上发表文章《Computing Machinery and Intelligence》,文章开篇提出通过让机器参与一个模仿游戏(Imitation Game)来验证“机器”能否“思考”,进而提出了经典的图灵测试(Turing Test),用以检验机器是否具备智能。同样,在自然语言处理研究领域,问答系统被认为是验证机器是否具备自然语言理解能力的四个任务之一(其它三个是机器翻译、复述和文本摘要)。自动问答研究既有利于推动人工智能相关学科的发展,也具有非常重要的学术意义。
机器翻译(machine translation,MT)是指利用计算机实现从一种自然语言到另外一种自然语言的自动翻译。被翻译的语言称为源语言(source language),翻译到的语言称作目标语言(target language)。简单地讲,机器翻译研究的目标就是建立有效的自动翻译方法、模型和系统,打破语言壁垒,最终实现任意时间、任意地点和任意语言的自动翻译,完成人们无障碍自由交流的梦想。当然,机器翻译技术还不完美,它仍面临很多具体问题和困难。本文对机器翻译研究的主要内容、面临的科学问题和主要困难,以及当前采用的主要技术、现状和未来发展的趋势做简要介绍。
Chapter 13 自动问答
(研究进展、现状&趋势)
What is QA?
自动问答(Question Answering, QA)是指利用计算机自动回答用户所提出的问题以满足用户知识需求的任务
不同于现有搜索引擎,问答系统是信息服务的一种高级形式,系统返回用户的不再是基于关键词匹配排序的文档列表,而是精准的自然语言答案
问答系统被认为是验证机器是否具备自然语言理解能力的四个任务之一(其它三个是机器翻译、复述和文本摘要)。
主要研究任务
大体流程:自动问答系统在回答用户问题时,需要正确理解用户所提的自然语言问题,抽取其中的关键语义信息,然后在已有语料库、知识库或问答库中通过检索、匹配、推理的手段获取答案并返回给用户。
涉及词法分析、句法分析、语义分析、信息检索、逻辑推理、知识工程、语言生成等多项关键技术
传统QA:限定领域,限定类型的回答;
QA发展趋势:趋向于开放域、面向开放类型问题的QA
任务1:问句理解
- 给定用户问题,自动问答首先需要理解用户所提问题
- 用户问句的语义理解包含词法分析、句法分析、语义分析等多项关键技术,需要从文本的多个维度理解其中包含的语义内容
- 词语层面:命名实体识别(Named Entity Recognition)、术语识别(Term Extraction)、词汇化答案类型词识别(Lexical Answer Type Recognition)、实体消歧(Entity Disambiguation)、关键词权重计算(Keyword Weight Estimation)、答案集中词识别(Focused Word Detection)等关键问题
- 句法层面:解析句子中词与词之间、短语与短语之间的句法关系,分析句子句法结构
- 语义层面:根据词语层面、句法层面的分析结果,将自然语言问句解析成可计算、结构化的逻辑表达形式(如一阶谓词逻辑表达式)。
任务2:文本信息抽取
-
给定问句语义分析结果,自动问答系统需要在已有语料库、知识库或问答库中匹配相关的信息,并抽取出相应的答案
-
传统答案抽取构建
- 基于浅层语义分析,采用关键词匹配策略,但只能处理限定类型的答案,效果不佳
- 缺点:没有分析语义单元之间的语义关系,抽取文本中的结构化知识
-
开放域知识抽取技术
- 早期基于规则模板的知识抽取方法难以突破领域和问题类型的限制,远远不能满足开放领域自动问答的知识需求
- 1)文本领域开放:处理的文本是不限定领域的网络文本;
- 2)内容单元类型开放:不限定所抽取的内容单元类型,而是自动地从网络中挖掘内容单元的类型,例如实体类型、事件类型和关系类型等。
任务3:知识推理
-
由于语料库、知识库和问答库本身的覆盖度有限,并不是所有问题都能直接找到答案。这就需要在已有的知识体系中,通过知识推理的手段获取这些隐含的答案。
-
传统推理方法
- 基于符号的知识表示形式,通过人工构建的推理规则得到答案
- 面对大规模、开放域的问答场景,不能自动进行规则学习,不能解决规则冲突
-
改进:基于分布式表示的知识表示学习方法能够将实体、概念以及它们之间的语义关系表示为低维空间中的对象(向量、矩阵等),并通过低维空间中的数值计算完成知识推理任务。
-
关键问题:如何将已有的基于符号表示的逻辑推理与基于分布式表示的数值推理相结合,研究融合符号逻辑和表示学习的知识推理技术
自动问答技术
区分方式:根据目标数据源的不同
1.检索式问答
-
以检索和答案抽取为基本过程的问答系统,具体过程包括问题分析、篇章检索和答案抽取。
比如TREC QA (1999年)的任务是给定特定 WEB 数据集,从中找到能够回答问题的答案
-
根据抽取方法的不同,已有检索式问答可以分为基于模式匹配的问答方法和基于统计文本信息抽取的问答方法。
-
基于模式匹配的方法
- 先离线地获得各类提问答案的模式
- 系统首先判断当前提问属于哪一类,然后使用这类提问的模式来对抽取的候选答案进行验证
- 由于自然语言处理的技术还未成熟,现有(2016)大多数系统都基于浅层句子分析。
-
基于统计文本信息抽取的问答系统
- 典型代表是美国 Language Computer Corporation公司的 LCC 系统。
- LCC系统使用词汇链和逻辑形式转换技术,把提问句和答案句转化成统一的逻辑形式(Logic Form),通过词汇链,实现答案的推理验证
-
里程碑:Watson5(IBM)
- (1)强大的硬件平台
- (2)强大的知识资源,存储了大量已有的资料,便于检索
- (3)深层问答技术(DeepQA):涉及统计机器学习、句法分析、主题分析、信息抽取、知识库集成和知识推理等深层技术
- 本质:Watson 并没有突破传统问答式检索系统的局限性,使用的技术主要还是检索和匹配,回答的问题类型大多是简单的实体或词语类问题,而推理能力不强。
-
限定问题类型、限定答案类型,面对开放式的场景和环境,已有检索式问答系统还有很长的路要走
2.社区问答
-
契机:随着 Web2.0 的兴起,基于用户生成内容(User-Generated Content, UGC)的互联网服务越来越流行,社区问答系统应运而生,如:百度知道
-
社区问答数据覆盖了方方面面的用户知识和信息需求
-
社区问答与传统自动问答的一个显著区别是:社区问答系统有大量的用户参与,存在丰富的用户行为信息(投票、评价、采纳率、推荐、点击次数以及用户-问题-答案的相互关联信息等)
-
社区问答的核心问题是从大规模历史问答对数据中找出与用户提问问题语义相似的历史问题并将其答案返回提问用户
-
特点:用户问题和已有问句相对来说都非常短,用户问题和已有问句之间存在“词汇鸿沟”问题
-
解决方案1:引入单语言翻译概率模型,通过 IBM 翻译模型,从海量单语问答语料中获得同种语言中两个不同词语之间的语义转换概率,从而在一定程度上解决词汇语义鸿沟问题
例如和“减肥”对应的概率高的相关词有“瘦身”、“跑步”、“饮食”、“健康”、“远动”等等
-
解决方案2:问句检索中词重要性的研究和基于句法结构的问题匹配
-
3.知识库问答(重点)
-
检索式问答和社区问答尽管在某些特定领域或者商业领域有所应用,但是其核心还是关键词匹配和浅层语义分析技术,难以实现知识的深层逻辑推理,无法达到人工智能的高级目标。
-
逐步把注意力投向知识图谱或知识库(Knowledge Graph)
-
目标:把互联网文本内容组织成为以实体为基本语义单元(节点)的图结构,其中图上的边表示实体之间语义关系。
-
知识库多是以“实体-关系-实体”三元组为基本单元所组成的图结构,根据用户问题的语义直接在
知识库上查找、推理出相匹配的答案,这一任务称为面向知识库的问答系统或知识库问答。 -
如何把用户的自然语言问句转化为结构化的查询语句是知识库问答的核心所在,关键是对于自然语言问句进行语义理解(如图所示)
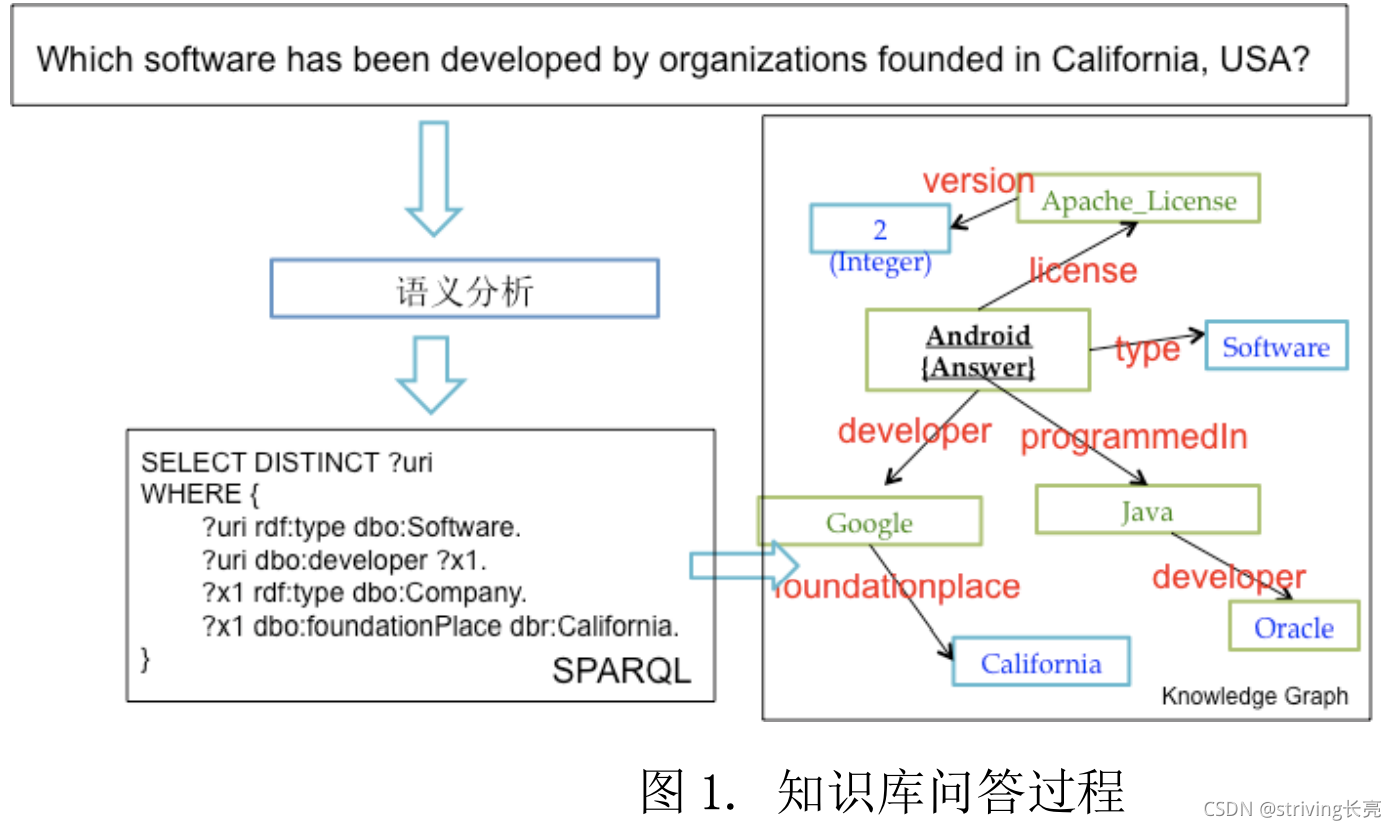
完成在结构化数据上的查询、匹配、推理等操作,最有效的方式是利用如SQL语句似的结构化查询语句,但是语句通常由专家编写,普通用户难以掌握并正确运用,对普通用户而言,自然语言依旧是最自然的交互方式 -
主流方法是通过语义分析,将用户的自然语言问句转化成结构化的语义表示,比如DCS-Tree。相对应的语义解析语法或方法包括组合范畴语法( Category Compositional Grammar, CCG ) 以 及 依 存 组 合 语 法 ( Dependency-based Compositional Semantics, DCS)等
很多语义解析方法在限定领域内能达到很好的效果,当面对大规模知识库时会遇到困难,如词汇表问题(在面对一个陌生的知识库时,不可能事先或者用人工方法得到这个词汇表)。并且上述方法的处理范式仍然是基于符号逻辑的,缺乏灵活性,在分析问句语义过程中,易受到符号间语义鸿沟影响。同时从自然语言问句到结构化语义表达需要多步操作,多步间的误差传递对于问答的准确度也有很大的影响。
-
趋势——>深度学习技术
- 优势:通过学习能够捕获文本(词、短语、句子、段落以及篇章)的语义信息,把目标文本投射到低维的语义空间中,这使得传统自然语言处理过程中很多语义鸿沟的现象通过低维空间中向量间数值计算得到一定程度的改善或解决。
- 通过表示学习,我们能够把用户的自然语言问题转换为一个低维空间中的数值向量(分布式语义表示),同时知识库中的实体、概念、类别以及关系也能够表示成同一语义空间的数值向量。那么传统知识库问答任务就可以看成问句语义向量与知识库中实体、边的语义向量之间的相似度计算过程。
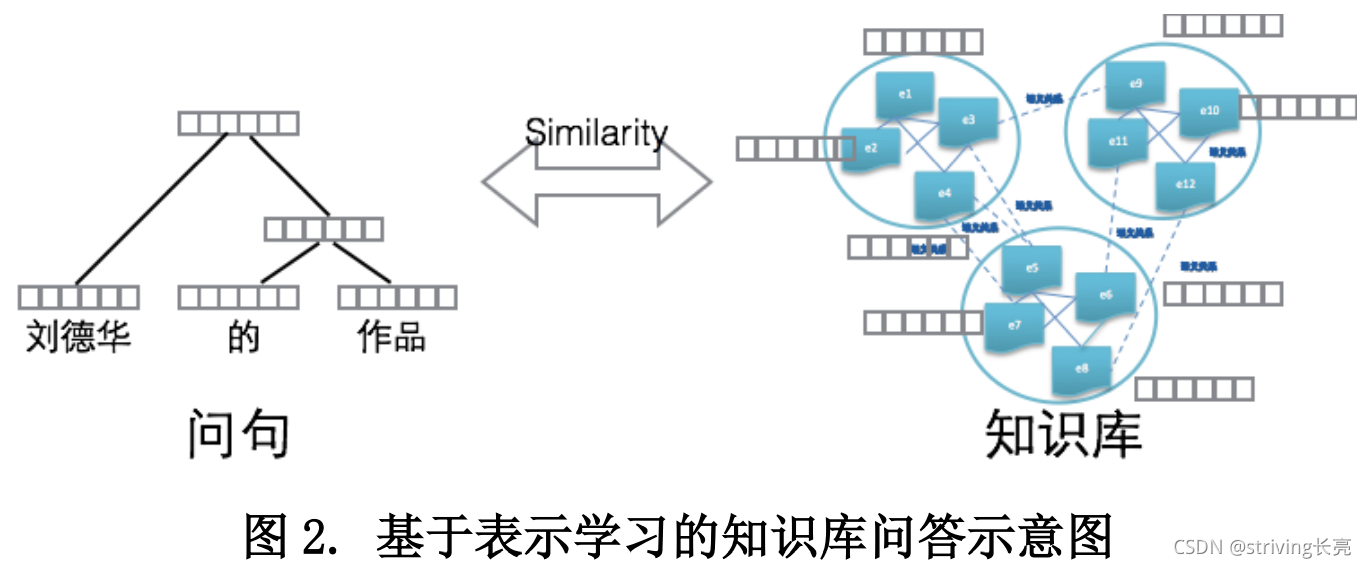
未来展望
基于深度学习的端到端自动问答
- 通过高质量的问题-答案语料建立联合学习模型,同时学习语料库、知识库和问句的语义表示及它们相互之间的语义映射关系,试图通过向量间的数值运算对于复杂的问答过程进行建模,把传统的问句语义解析、文本检索、答案抽取与生成的复杂步骤转变为一个可学习的过程
- 现状:(1)高质量问题-答案数据资源不足;(2)对于复杂问题的回答能力不足
多领域、多语言的自动问答
面向问答的深度推理
- 利用深度学习大规模、可学习的特点,在深度神经网络框架下,融入传统的逻辑推理规则,构建精准的大规模知识推理引擎
篇章阅读理解
- 传统问答任务多考察系统的文本匹配、信息抽取水平。而在阅读理解任务当中,系统被要求回答一些非事实性的、高度抽象的问题。虽然可以利用一些已有背景知识,但是问题的答案往往来源于当前给定篇章中的文本。特别考察系统对于文本的细致化的自然语言理解能力以及已有知识的运用能力和推理能力
对话
- 提问者和系统进行多轮对话交互,完成问答过程
Chapter 14 机器翻译
(研究进展、现状&趋势)
machine translation (MT)
利用计算机实现从一种自然语言到另外一种自然语言的自动翻译。被翻译的语言称为源语言(source language),翻译到的语言称作目标语言(target language)。
目标:建立有效的自动翻译方法、模型和系统,打破语言壁垒,最终实现任意时间、任意地点和任意语言的自动翻译,完成人们无障碍自由交流的梦想。
几乎自然语言处理中的所有问题都会在机器翻译中出现,包括:词法分析(或称形态分析)与词语切分、命名实体识别、句法分析、词义消歧与句子语义表示、自然语言句子生成等,当然在其中最重要的是翻译模型构建问题
MT基本步骤
Step 1: 源语言语句的理解
- 包括词语、短语、句子和语篇(对话)等多层次语言单位的处理
- 词语层面:如何界定和切分适合机器翻译的基本语言单元(如汉语、日语、越南语、泰国语等语言的分词问题)、多义词的歧义消解问题以及指代、省略等语言现象的歧义消除等问题
- 短语和句子层面:需要解析句子中词与词之间、短语与短语之间的语义关系。语义理解得越深刻,越有利于机器翻译过程。
- 语篇层面:需要分析句子之间的结构和语义关系,如句子之间的连贯性、衔接性等
Step 2: 源语言到目标语言的转换
- 核心问题:转换规则(有时候我们称其为“翻译知识”)的表示和获取
- 翻译知识表示主要涉及翻译规则表达的知识层次(基于词、短语、句法子树、语义结构树等)和表示形式(基于离散符号和基于连续实数空间表示方法)
- 翻译知识的获取:一种是基于理性主义思路的专家经验总结和手工编写方式;另一种是基于经验主义思想的以数据驱动的自动获取方法。将翻译知识隐含在神经网络结构和参数中的方法实际上也是一种经验主义方法。
Step 3: 目标语言生成
- 译文片段的组合方式和目标语言句子的流畅性是目前译文生成中重点关注的两个问题
- 根据翻译系统所接受的输入类型和系统工作方式的不同,机器翻译又可分为文本机器翻译(text-to-text machine translation)、口语翻译(spoken language translation, SLT)和计算机辅助翻译(computer assisted machine translation)。默认情况下,一般指文本机器翻译或者泛指。
翻译方法
早期:理性主义方法
-
指以语言学理论为基础,由语言学家手工编写翻译规则和词典
-
代表:基于规则的翻译(rule-based machine translation)方法
- 所有规则几乎都是由通晓双语的语言学专家总结、编纂获得的
- 这种方法能够充分利用语言学家总结出来的语言规律,具有一定的通用性,因此,对于符合源语言语法规范的句子一旦翻译正确,往往能够获得较高质量的译文
- 缺点:一般只能处理规范的语言现象,获取规则的人工成本较高,而且维护大规模的规则库往往比较困难,新规则与已有规则易发兼容性问题等
经验主义方法
-
以信息论和数理统计为理论基础,以大规模语料库为驱动,通过机器学习技术自动获取翻译知识,这种方法又被称为基于语料库的翻译方法(corpus-based machine translation),或者数据驱动的翻译方法(data-driven machine translation)。
-
主张从已知的翻译实例中自动学习两种语言之间的转换规则
-
早期:基于实例的翻译方法(example-based machine translation)
- 在事先构建的翻译实例库中找出与待翻译的源语言句子相似的实例(通常是句子),并根据待翻译句子的具体情况对实例对应的译文进行适当的替换、删除和插入等操作,实现翻译过程。
- 无需对源语言句子进行复杂的分析,可充分利用已经确认的翻译实例,实例一般是句子。
- 缺点:如何从大规模实例库中快速找到相似度很高的实例,尤其是语义高度相似的实例,始终是该方法面临的挑战
-
中期:统计翻译方法(statistical machine translation)
-
基本思想是利用机器学习技术从大规模双语平行语料中自动获取翻译规则和概率参数,然后利用翻译规则对源语言句子进行解码。
-
在统计翻译方法中有三个关键技术模块:语言模型(language model)、翻译模型(translation model)和解码器(decoder)
-
语言模型用于计算候选译文的句子概率,翻译模型用于计算给定候选译文时源语言句子的概率,解码器用于快速搜索语言模型概率与翻译模型概率相乘之后概率最大的候选译文。为了融入更多的翻译特征,噪声信道模型(IBM,1980-1990)逐渐被对数线性模型所取代。
-
在 20 多年的发展历程中,统计翻译方法经历了基于词、基于短语和基于句法树翻译模型的一系列转变,如图所示。
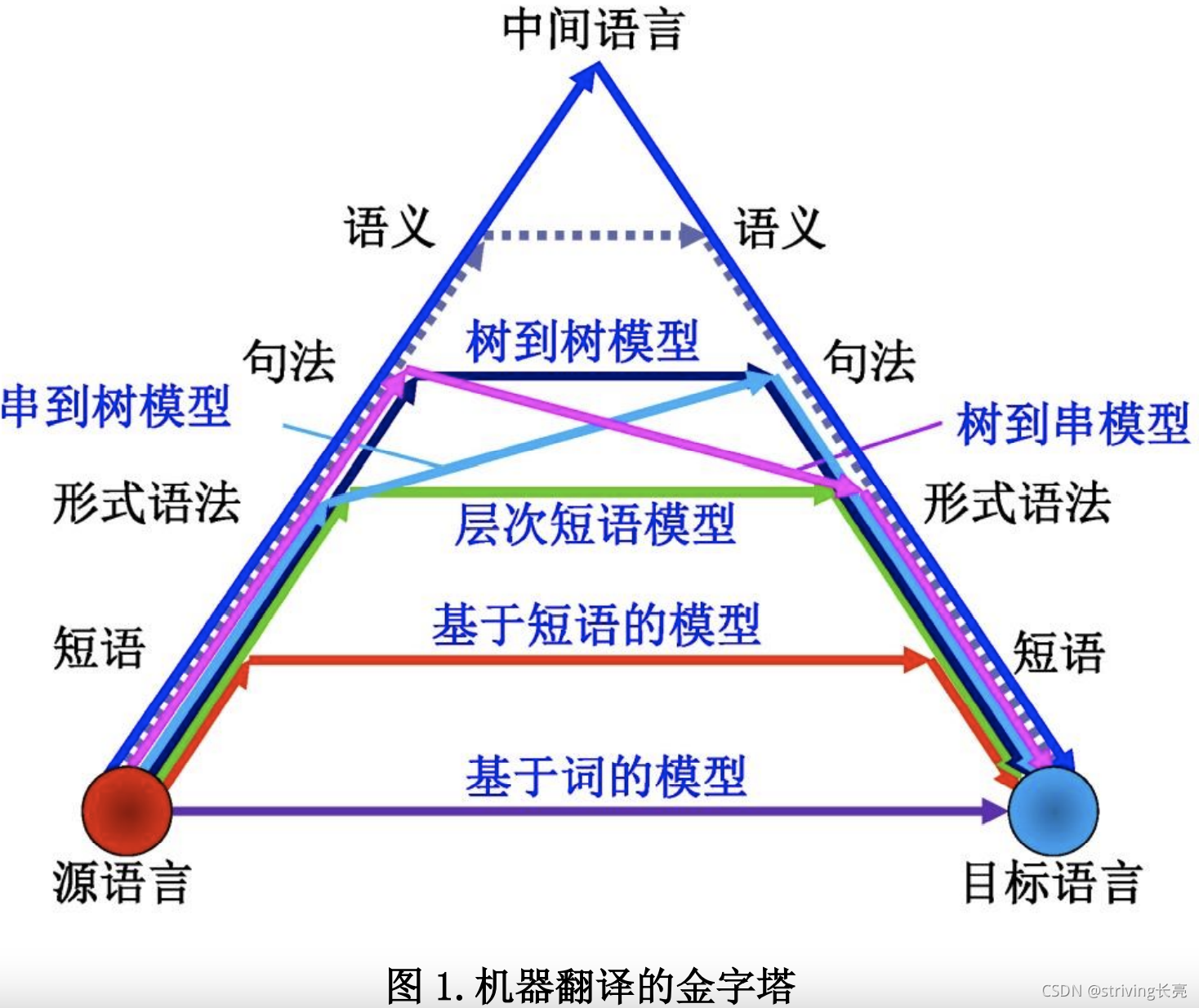
-
基于短语的翻译模型是相对成熟的模型。这里所说的“短语”指连续同现的词串,并非语言学上定义的短语。后续工作主要目的是解决候选译文的消岐问题和目标译文短语的重排序问题。
-
最近几年,句法翻译模型主要针对其中的两个问题开展研究:(1)句法结构树与词语对齐不兼容;(2)双语的句法知识很难同时被有效地利用。
-
-
研究热点:基于深度学习的翻译方法(deep-learning based machine translation)
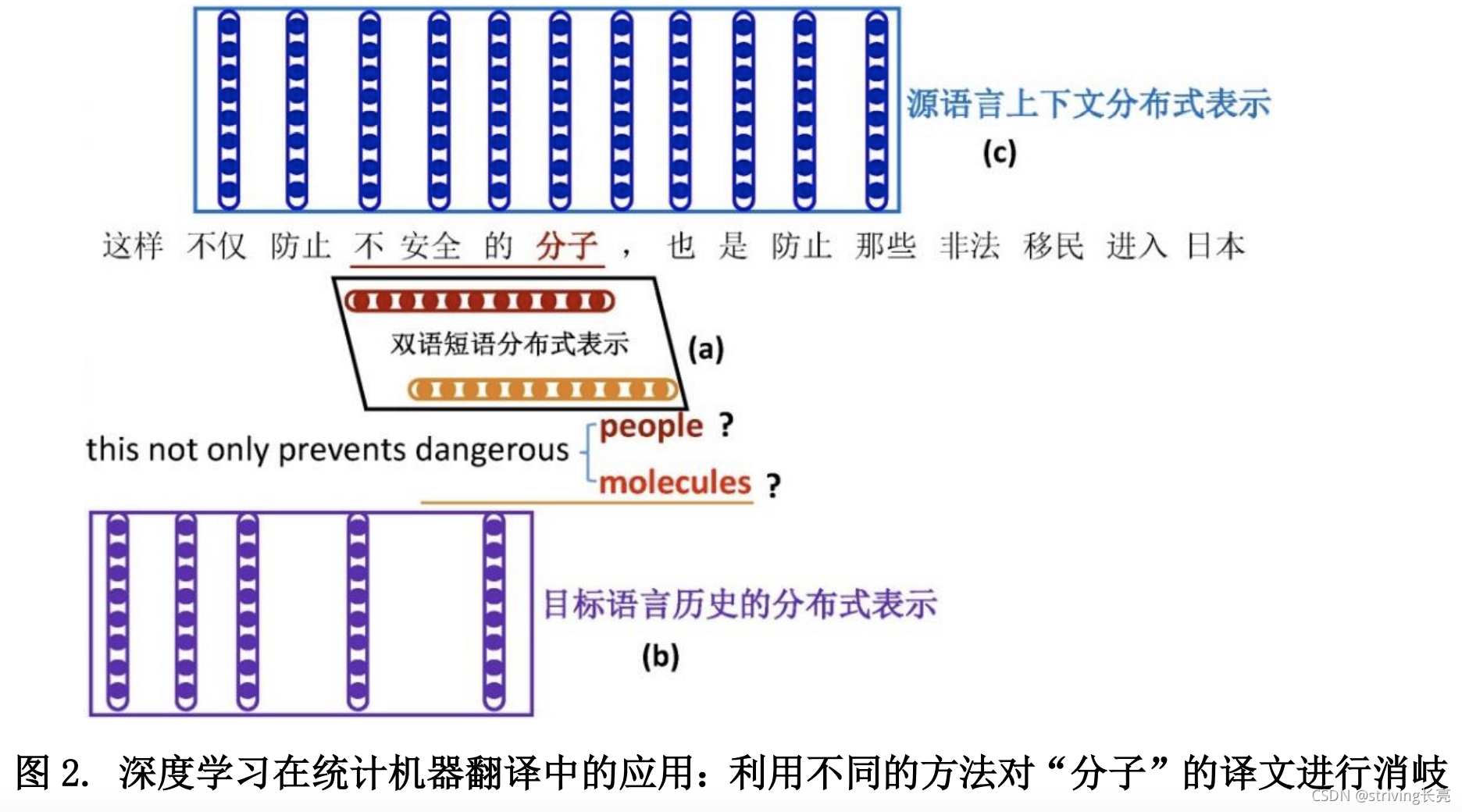
-
如上图,2015年之前,基于DL的MT模型主要以统计翻译为框架,旨在改进源语言句子解析、翻译转换和目标译文生成中的某些关键技术,如词语对齐、翻译概率估计、短语重排序和语言模型等。利用深度学习方法的分布式表示,解决统计翻译方法对全局上下文和深层语义信息建模难的问题
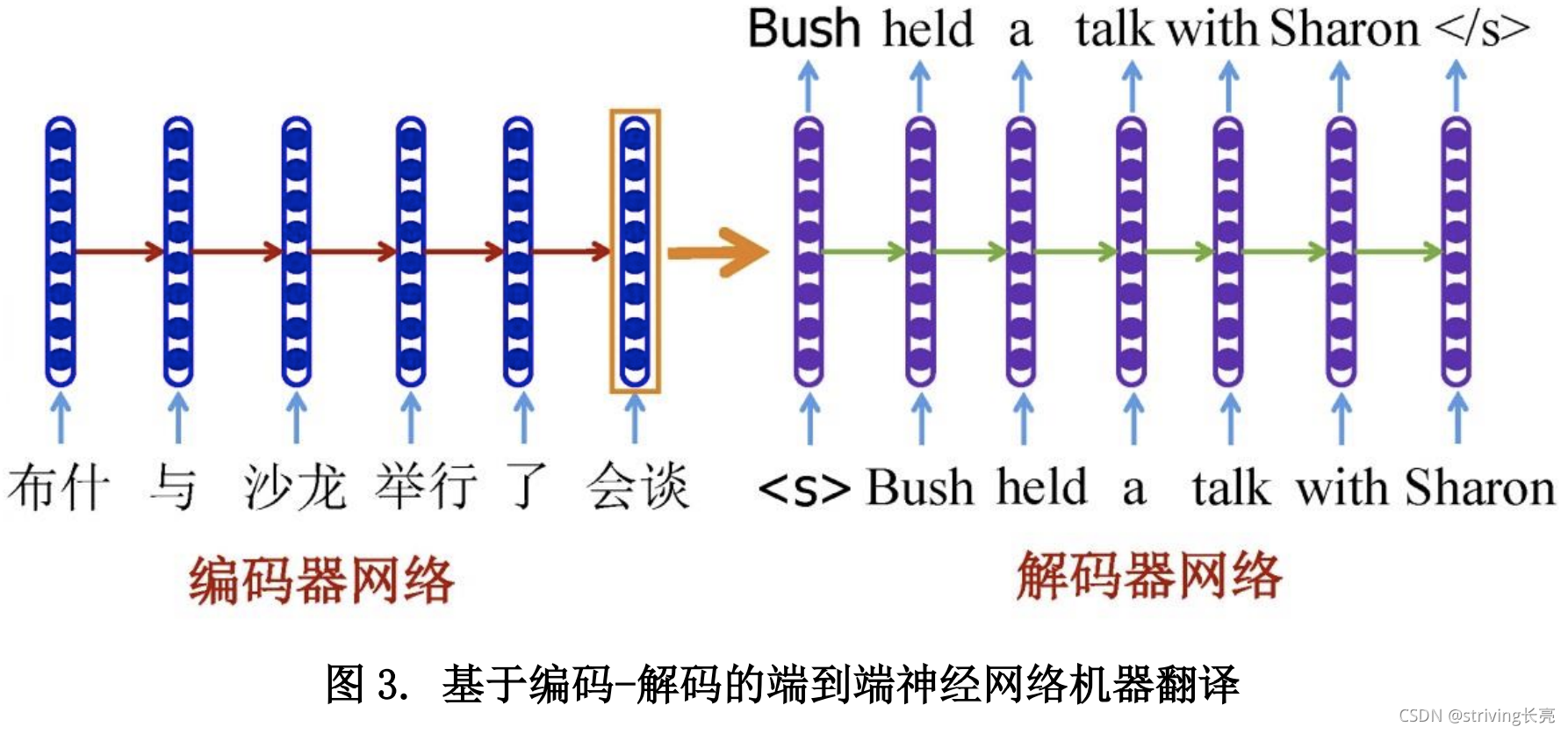
-
如上图所示,2015年之后,直到现在,Encoder- Decoder的MT模型更为热门,Encoder- Decoder模型包含两个神经网络:一个称为编码器(encoder),用于将源语言句子映射为一个(或一组)低维、连续的实数向量;另一个称为解码器(decoder),完成将源语言句子的向量表示转化为目标语言句子。
缺点:无论源语言句子的长短,编码器仅将其映射到一个维数固定的实数向量,很难准确地表示源语言句子的完整语义。 -
Bahdanau 等人将注意机制(attention)思想引入到了端到端的神经网络翻译模型:编码器生成并保留每个源语言词对应的上下文语义向量;解码器每次产生目标语言的单词时,首先利用注意机制模型计算当前译文应与源语言哪些位置的词语有关,然后加权得到源语言的上下文表示,最后用其预测当前译文的概率。
-
展望
端到端的神经网络机器翻译的优化
- 增强模型的可解释性、降低神经网络的计算复杂度(使之能在 CPU 上高效训练)、以及设计更加合理的编码和解码网络
面向小数据的机器翻译
- 基于深度学习强大的特征表示能力、采用半监督或弱监督的方法解决小数据机器翻译问题
非规范文本的机器翻译
- 互联网上使用的语言文本大多具有口语化、社交化等诸多新的特征,弱规范甚至不规范的现象比较严重。提高非规范文本的处理能力和翻译效果
篇章级机器翻译
- 现如今的MT模型大多数都是以句子为基本翻译单位进行的,忽略了指代消解、省略和译文句子之间衔接性和连贯性等深层次的语义表达问题。以更大粒度的语言单位(如段落甚至篇章)为翻译单位或上下文背景,对译文的篇章信息进行建模
融合离散符号表示与连续向量表示的机器翻译
- 建立于离散符号表示的统计翻译方法与建立于连续向量表示的神经翻译方法都各有其优势,同时各有弊端。设计新的方法融合两者的优势
总结
总之,自动问答作为人工智能技术的有效评价手段,已经研究了 60 余年。整体上,自动问答技术的发展趋势是从限定领域向开放领域、从单轮问答向多轮对话、从单个数据源向多个数据源、从浅层语义分析向深度逻辑推理不断推进。我们有理由相信,随着自然语言处理、深度学习、知识工程和知识推理等相关技术的飞速发展,自动问答在未来有可能得到相当程度的突破。伴随着 IBM Watson、Apple Siri 等实际应用的落地与演进,我们更有信心看到这一技术将在不远的未来得到更大、更广的应用。
纵观 20 余年来机器翻译研发的趋势和现状,我们有理由相信,随着机器学习、语义分析和篇章理解等相关技术的快速进展,这一人工智能中最具挑战的问题将在可预见的未来得到相当程度的解决,机器翻译系统的产业化应用前景将更加广阔。
彩蛋
Next blog:社会媒体处理(Chapter 15)& 语音技术(Chapter 16)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











