







文章目录
内置类型
定义在builtin/builtin.go
值类型
bool
int int8, int16, int32(rune), int64
uint uint8(byte), uint16, uint32, uint64
float32, float64
string
complex64, complex128
array //固定长度的数组
struct //结构体
内置常量
true //bool
false
iota //int 初始0
nil //nil类型值
引用类型
slice //切片
map //哈希映射
chan //通道
// 特殊 零值 nil
function //函数
pointer //指针
interface //接口
内置函数
append // 用来追加元素到数组、slice中,返回修改后的数组、slice
close // 主要用来关闭channel
delete // 从map中删除key对应的value
panic // 停止常规的goroutine (panic和recover:用来做错误处理)
recover // 允许程序定义goroutine的panic动作
real // 返回complex的实部 (complex、real imag:用于创建和操作复数)
imag // 返回complex的虚部
make // 用来分配内存,返回Type本身(只能应用于slice, map, channel)
new // 用来分配内存,主要用来分配值类型,比如int、struct。返回指向Type的指针
cap // capacity是容量的意思,用于返回某个类型的最大容量(只能用于切片和 map)
copy // 用于复制和连接slice,返回复制的数目
len // 来求长度,比如string、array、slice、map、channel ,返回长度
print、println // 底层打印函数,在部署环境中建议使用 fmt 包
内置接口
//error接口
type error interface {
Error() string
}
数据类型
基本类型
整型
| 类型 | 描述 |
|---|---|
| uint8 | 无符号 8 位整型 (0 到 255) |
| uint16 | 无符号 16 位整型 (0 到 65535) |
| uint32 | 无符号 32 位整型 (0 到 4294967295) |
| uint64 | 无符号 64 位整型 (0 到 18446744073709551615) |
| int8 | 有符号 8 位整型 (-128 到 127) |
| int16 | 有符号 16 位整型 (-32768 到 32767) |
| int32 | 有符号 32 位整型 (-2147483648 到 2147483647) |
| int64 | 有符号 64 位整型 (-9223372036854775808 到 9223372036854775807) |
| byte | uint8,存储字符时选用 |
| rune | int32,表示Unicode码 |
| uint | 32 或 64 位 |
| int | 与 uint 一样大小,整型没有声明具体类型时,默认的类型 |
| uintptr | 无符号整型,用于存放一个指针 |
浮点型
| 类型 | 描述 |
|---|---|
| float32 | 单精度,IEEE-754 32位浮点型数,有效bit位23个 浮点最精度小数点后15位 |
| float64 | 双精度,IEEE-754 64位浮点型数,默认的类型 浮点最精度小数点后15位 |
| complex64 | 32 位实数和虚数 |
| complex128 | 64 位实数和虚数 |
布尔型
- 常量true false,默认fasle
- 不可与整型计算,不可以强转
package main
import (
"fmt"
"math"
"unsafe"
)
func main() {
//-------------类型和所占字节----------------
num := 2
fmt.Printf("num is type %T, size %d\n",num,unsafe.Sizeof(num))
//------------超范围,循环显示----------------
var n1 int8 = 1
var n3 = n1 + 127
fmt.Println("n3:",n3)
//-----------不同类型,不能操作-------------
// var n4 = num + n1 invalid operation
//---------------浮点型----------------------
var f float64 = 1
f1 := 1.23
f2 := .23
f3 := 1.
fmt.Println("f:",f,"f1:",f1,"f2:",f2,"f3:",f3)
//-------------科学计数法-----------------
f4 := 1.23E2
f5 := 123E-2
fmt.Println("f4:",f4,"f5:",f5)
//---------------保留位数----------------
f6 := math.Pi
fmt.Printf("%.3f\n",f6)
//--------------四舍六入五看尾---------------
fmt.Printf("3.1249 => %0.2f(四舍)\n", 3.1249)
fmt.Printf("3.12671 => %0.2f(六入)\n", 3.12671)
fmt.Printf("3.1351 => %0.2f(五后非零就进一)\n", 3.1351)
fmt.Printf("3.12501 => %0.2f(五后非零就进一)\n", 3.12501)
fmt.Printf("3.1250 => %0.2f(五后为零看奇偶,五前为偶应舍去)\n", 3.1250)
fmt.Printf("9.8350 => %0.2f(五后为零看奇偶,五前为奇要进一)\n", 9.8350)
fmt.Printf("3.2250 => %0.2f(五后为零看奇偶,五前为偶应舍去???)\n", 3.2250)
fmt.Printf("9.7350 => %0.2f(五后为零看奇偶,五前为奇要进一???)\n", 9.7350)
// 布尔
b := false
// n3 = n1 + b invaliad operation
fmt.Printf("b的类型:%T,b的值:%v,b的大小:%d",b,b,unsafe.Sizeof(b))
}
字符和字符串
字符
-
没有字符类型。Ascii码使用byte,其他适合使用rune(UTF-8),使用’'包裹
a. 字母一个字节
b. 汉字三个字节 -
转义字符
转义 含义 \r 回车符(返回行首) \n 换行符(直接跳到下一行的同列位置) \t 制表符 ’ 单引号 " 双引号 \ 反斜杠
字符串
- 使用""包裹或者``包裹
- 如果只包含ascii码,为byte数组
- 如果包含中文,为rune数组。rune由1个或多个byte组成
转译
// 双引号支持转译字符
str3 := "我要换行\n换好啦:)\n"
// 反引号不支持转译字符
str4 := `我想换行\n换不了:(\n`
// 反引号支持多行
str5 := `line1
line2
`
切片
fmt.Println("1234567"[:3],"1234567"[3:]) // "123" "4567"
fmt.Println("我是字符串"[:3],"我是字符串"[3:]) // "我" "是字符串"
拼接
"a"+"b"
+"c" ❌
"a"+"b"+
"c" ☑️
遍历
a:= "我是字符串"
//读取byte
for i:=0;i<len(a);i=i+3{
fmt.Print(a[i:i+3])
}
//读取rune 字符
for _,s := range "a"{
fmt.Printf("%c",s)
}
长度
a:= "我是字符串"
println(len(a)) // 15 byte
println(len([]rune(a))) // 5 rune
转换
a:= "我是字符串"
b:=[]byte(a)
c:=[]rune(a)
d:=string(b)
e:=string(c)
工具
//常见工具包
strings
bytes
unicode
类型转换
-
go不支持隐式转换
-
转换表达式
// 表达式 T(v) 将值 v 转换为类型 T // type_name 类型 // expression 表达式 type_name(expression)
| 原类型 | 目标类型 | 方法 | 备注 |
|---|---|---|---|
| 整型、浮点型 | 整型、浮点型 | T(v) | 大数转小数超范围,溢出; 浮点型转整型,小数丢失; 高精度转低精度,精度丢失 |
| 任何类型 | string | fmt.Sprintf() | 推荐 |
| bool | strconv.FormatBool(b bool) string | 根据b的值返回"true"或"false" | |
| int64 | strconv.FormatInt(i uint64, base int) string | base 必须在2到36之间,结果中会使用小写字母’a’到’z’表示大于10的数字 | |
| uint64 | strconv.FormatUint(i uint64, base int) string | 同上且为无符号 | |
| float64/32 | strconv.FormatFloat(f float64, fmt byte, prec, bitSize int) string | fmt表示格式: ‘f’(-ddd.dddd) ‘b’(-ddddp±ddd,指数为二进制) ‘e’(-d.dddde±dd,十进制指数) ‘E’(-d.ddddE±dd,十进制指数) ‘g’(指数很大时用’e’格式,否则’f’格式) ‘G’(指数很大时用’E’格式,否则’f’格式)。 prec控制精度(排除指数部分): 对’f’、‘e’、‘E’,它表示小数点后的数字个数; 对’g’、‘G’,它控制总的数字个数。 如果prec 为-1,则代表使用最少数量的、但又必需的数字来表示f。 bitSize表示f的来源类型(32:float32、64:float64),会据此进行舍入。 | |
| int | strconv.Itoa() | 相当于strcov.ParseInt(s string, 10,0) (i int64, err error) | |
| string | strconv.ParseBool(str string) (value bool, err error) | 返回字符串表示的bool值。它接受1、0、t、f、T、F、true、false、True、False、TRUE、FALSE;否则返回错误。 | |
| float64 | strcov.ParseFloat(s string, bitSize int) (f float64, err error) | bitSize指定了期望的接收类型, 32是float32(返回值可以不改变精确值的赋值给float32), 64是float64; 返回值err是*NumErr类型的,语法有误的,err.Error=ErrSyntax; 结果超出表示范围的,返回值f为±Inf,err.Error= ErrRange。 | |
| int64 | strcov.ParseInt(s string, base int, bitSize int) (i int64, err error) | 返回字符串表示的整数值,接受正负号。 base指定进制(2到36),如果base为0,则会从字符串前置判断,"0x"是16进制,"0"是8进制,否则是10进制; bitSize指定结果必须能无溢出赋值的整数类型,0、8、16、32、64 分别代表 int、int8、int16、int32、int64;返回的err是*NumErr类型的,如果语法有误,err.Error = ErrSyntax;如果结果超出类型范围err.Error = ErrRange。 | |
| uint64 | ParseFloat(s string, bitSize int) (f float64, err error) | 同上,无符号版本 |
派生类型
数组 array
-
值类型,声明时零值填。
-
固定长度,编译期决定。
- 类型不一致数组不一致
- 长度不一致数组不一致。
- 0~len-1下标访问 ,越界panic
-
占用内存连续
// cmd/compile/internal/types/type.go
// array结构
type Array struct {
Elem *Type // 类型指针
Bound int64 // 数组长度
}
// cmd/compile/internal/types/type.go
// 创建array
func NewArray(elem *Type, bound int64) *Type {
if bound < 0 {
Fatalf("NewArray: invalid bound %v", bound)
}
t := New(TARRAY)
t.Extra = &Array{Elem: elem, Bound: bound}
t.SetNotInHeap(elem.NotInHeap())
return t
}

//--------------声明---------------
//var variable_name [SIZE]variable_type
var arr [3]int
//--------------初始化---------------
//var variable_name [SIZE]variable_type = [SIZE]variable_type{elem...}
//variable_name:= [SIZE]variable_type{elem...}
//variable_name:= [...]variable_type{elem...}
//variable_name:= [SIZE]variable_type{index:elem ...}
var arr1 [3]int = [3]int{1,2,3} //无类型推导
var arr2 = [3]int{1:4,0:5,2:6} //类型推导
arr3 := [...]int{7,8,9} //长度推导
arr4 := [5]int{1:3,3:5} //使用索引初始化
arr5 := [...] struct{
name string
age int
}{
{"user1",1},
{"user2",2},
}
//--------------遍历---------------
n1 := len(arr1)
for i:=0;i<n1;i++{ // for
fmt.Println(i,arr1[i])
}
for index,n := range arr3{ // range
fmt.Println(index,n)
}
多维数组
//--------------声明---------------
//var variable_name [ROW][COL] variable_type
var arr7 [2][3]int
//--------------初始化---------------
//var variable_name [ROW][COL]variable_type = [...][COL]variable_typevariable_type{{elem...}...}
//variable_name:= [ROW][COL]variable_type{{elem...}...}
var arr8 = [...][2]int{{1,2},{2,3}}
arr9 := [1][2]int{{5,6}}
//--------------遍历---------------
for row:=0;row<len(arr8);row++{
for col:=0;col<len(arr8[0]);col++{
fmt.Println(row,col,arr8[row][col])
}
}
for row,rows := range arr8 {
for col,val:= range rows{
fmt.Println(row,col,arr8[row][col],val)
}
}
切片 slice
- 引用类型
- 长度可以变化,容量随长度变化
- 底层是数组
// cmd/compile/internal/types/type.go
// 编译时slice 结构体
type Slice struct {
Elem *Type // element type
}
// reflect/value.go
// 运行时slcie 结构体
type SliceHeader struct {
Data uintptr //指向底层数组指针
Len int //切片长度
Cap int //切片容量
}
// cmd/compile/internal/types/type.go
// 创建切片类型 返回切片指针
func NewSlice(elem *Type) *Type {
if t := elem.Cache.slice; t != nil {
if t.Elem() != elem {
Fatalf("elem mismatch")
}
return t
}
t := New(TSLICE)
t.Extra = Slice{Elem: elem}
elem.Cache.slice = t
return t
}
// runtime/slice.go
// 初始化切片时,如果切片内存逃逸或者太大会调用此方法分配内存
func makeslice(et *_type, len, cap int) unsafe.Pointer {
mem, overflow := math.MulUintptr(et.size, uintptr(cap)) //内存空间=切片中元素大小×切片容量
if overflow || mem > maxAlloc || len < 0 || len > cap {
mem, overflow := math.MulUintptr(et.size, uintptr(len))
if overflow || mem > maxAlloc || len < 0 {
panicmakeslicelen()
}
panicmakeslicecap()
}
return mallocgc(mem, et, true)
}
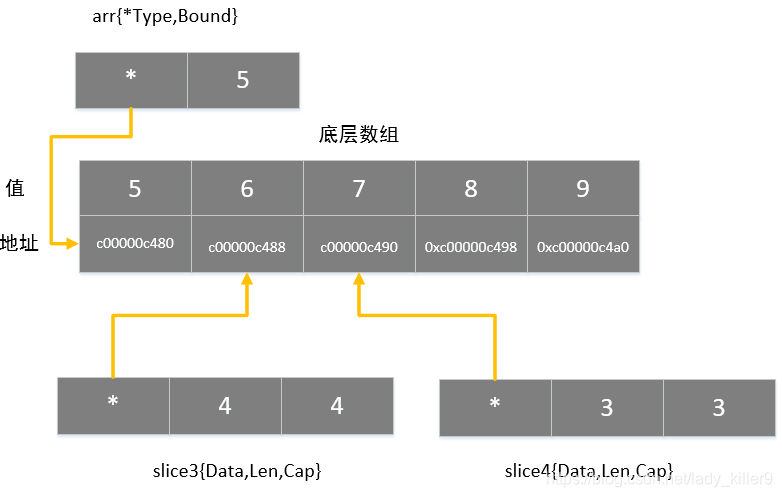
//--------------声明---------------
//var slicename []type
var slice []int // slice = nil len=0 cap=0
//--------------初始化---------------
// func make(Type, size ...IntegerType[,capacity]) Type
// capacity必须大雨size
// size 为切片初始长度
// capactity 为切片容量
// var slicename []type = make([]type,len[,cap])
// slicename := []type{elem...}
// slicename := slice[:end[:max]] start<=index<end max<=end<=len(slice) len=end-start cap=max-start
// slicename := slice[start:end[:max]] start<=index<end max<=end<=len(slice) len=end-start cap=max-start
// slicename := slice[start:[:max]] start<=index<len(slice) max<=end<=len(slice) len=end-start cap=max-start
slice1 := make([]int,1,2,3,4) // len=3 cap=4
slice2 := []int{6,7}
slice3 := slice1[1:]
//--------------遍历---------------
for i:=0;i<len(slice3);i++{
fmt.Print(slice3[i]," ")
}
for _,v := range slice3{
fmt.Print(v," ")
}
//--------------len/cap---------------
//获取切片长度
//获取切片容量
len(slice1) //3
cap(slice1) //4
//--------------追加---------------
// func append(slice []Type, elems ...Type) []Type
// slice 被添加的切片
// elems 可变元素
// []Type 新切片可能扩容
slice1=append(slice1,5) // append 追加当个元素
slice1=append(slice1,slice2...) // append 追加切片
//--------------拷贝---------------
// copy(taget,soure) 长度以len(soure)为准
s1 := []int{1, 2, 3, 4, 5}
fmt.Println( s1) // [1 2 3 4 5]
s2 := make([]int, 10)
fmt.Println(s2) // [0 0 0 0 0 0 0 0 0 0]
copy(s2, s1)
fmt.Println(s1) //[1 2 3 4 5]
fmt.Println(s2) //[1 2 3 4 5 0 0 0 0 0]
拷贝
//func copy(dst, src []Type) int
//内置函数copy编译时被改写如下
//cmd/compile/internal/gc/walk.go
/*
// Lower copy(a, b) to a memmove call or a runtime call.
//
// init {
// n := len(a)
// if n > len(b) { n = len(b) }
// if a.ptr != b.ptr { memmove(a.ptr, b.ptr, n*sizeof(elem(a))) }
// }
// n;
//
// Also works if b is a string.
//
*/
func copyany(n *Node, init *Nodes, runtimecall bool) *Node {
//如果有指针调用 runtime/mbarrier.go typedslicecopy 拷贝
if n.Left.Type.Elem().HasPointers() {
...
fn := writebarrierfn("typedslicecopy", n.Left.Type.Elem(), n.Right.Type.Elem())
...
return mkcall1(fn, n.Type, init, typename(n.Left.Type.Elem()), ptrL, lenL, ptrR, lenR)
}
//如果时运行时调用 runtime/slice.go typedslicecopy 拷贝
if runtimecall {
...
fn := syslook("slicecopy")
fn = substArgTypes(fn, ptrL.Type.Elem(), ptrR.Type.Elem())
return mkcall1(fn, n.Type, init, ptrL, lenL, ptrR, lenR, nodintconst(n.Left.Type.Elem().Width))
}
....
}
// runtime/slice.go
// 无指针类型切片或者string copy到另一个切片
func slicecopy(toPtr unsafe.Pointer, toLen int, fromPtr unsafe.Pointer, fromLen int, width uintptr) int {
if fromLen == 0 || toLen == 0 {
return 0
}
n := fromLen
if toLen < n {
n = toLen
}
if width == 0 {
return n
}
size := uintptr(n) * width
//其他代码
....
if size == 1 {
*(*byte)(toPtr) = *(*byte)(fromPtr) // known to be a byte pointer
} else {
memmove(toPtr, fromPtr, size)
}
return n
}
//runtime/mbarrier.go
//go:nosplit 有指针类型切片copy到另一个切片
func typedslicecopy(typ *_type, dstPtr unsafe.Pointer, dstLen int, srcPtr unsafe.Pointer, srcLen int) int {
n := dstLen
if n > srcLen {
n = srcLen
}
if n == 0 {
return 0
}
// 其他代码
...
size := uintptr(n) * typ.size
if writeBarrier.needed {
pwsize := size - typ.size + typ.ptrdata
bulkBarrierPreWrite(uintptr(dstPtr), uintptr(srcPtr), pwsize)
}
memmove(dstPtr, srcPtr, size)
return n
}
追加与扩容
//func append(slice []Type, elems ...Type) []Type
//内置函数append编译时被改写
//cmd/compile/internal/gc/ssa.go
func (s *state) append(n *Node, inplace bool) *ssa.Value {
// If inplace is false, 不需要赋值变量 "append(s, e1, e2, e3)":
//
// ptr, len, cap := s
// newlen := len + 3
// if newlen > cap {
// ptr, len, cap = growslice(s, newlen) // 调用切片扩容
// newlen = len + 3 // recalculate to avoid a spill
// }
// // with write barriers, if needed:
// *(ptr+len) = e1
// *(ptr+len+1) = e2
// *(ptr+len+2) = e3
// return makeslice(ptr, newlen, cap)
//
//
// If inplace is true, 需要赋值变量 "s = append(s, e1, e2, e3)":
//
// a := &s
// ptr, len, cap := s
// newlen := len + 3
// if uint(newlen) > uint(cap) {
// newptr, len, newcap = growslice(ptr, len, cap, newlen) // 调用切片扩容
// vardef(a) // if necessary, advise liveness we are writing a new a
// *a.cap = newcap // write before ptr to avoid a spill
// *a.ptr = newptr // with write barrier
// }
// newlen = len + 3 // recalculate to avoid a spill
// *a.len = newlen
// // with write barriers, if needed:
// *(ptr+len) = e1
// *(ptr+len+1) = e2
// *(ptr+len+2) = e3
...
}
// runtime/slice.go
// 扩容核心代码
func growslice(et *_type, old slice, cap int) slice {
//1. 大致确定扩容容量
newcap := old.cap
doublecap := newcap + newcap
if cap > doublecap {
newcap = cap //a.如果期望容量大于当前容量的两倍就会使用期望容量
} else {
if old.len < 1024 {
newcap = doublecap //b.当前切片的长度小于 1024 就会将容量翻倍
} else {
for 0 < newcap && newcap < cap {
newcap += newcap / 4 //c.当前切片的长度大于 1024 就会每次增加 25% 的容量,直到新容量大于期望容量
}
if newcap <= 0 {
newcap = cap
}
}
}
//2. 根据元素大小做内存对齐
var overflow bool
var lenmem, newlenmem, capmem uintptr
switch {
case et.size == 1: // 1
lenmem = uintptr(old.len)
newlenmem = uintptr(cap)
capmem = roundupsize(uintptr(newcap))
overflow = uintptr(newcap) > maxAlloc
newcap = int(capmem)
case et.size == sys.PtrSize: // 8
lenmem = uintptr(old.len) * sys.PtrSize
newlenmem = uintptr(cap) * sys.PtrSize
capmem = roundupsize(uintptr(newcap) * sys.PtrSize)
overflow = uintptr(newcap) > maxAlloc/sys.PtrSize
newcap = int(capmem / sys.PtrSize)
case isPowerOfTwo(et.size): // 2的倍数
...
default:
...
}
//3. 内存申请,底层数组拷贝
var p unsafe.Pointer
if et.ptrdata == 0 { //指针类型
p = mallocgc(capmem, nil, false)
memclrNoHeapPointers(add(p, newlenmem), capmem-newlenmem) //清空超出当前长度的内存
} else { //非指针类型
p = mallocgc(capmem, et, true)
if lenmem > 0 && writeBarrier.enabled {
bulkBarrierPreWriteSrcOnly(uintptr(p), uintptr(old.array), lenmem-et.size+et.ptrdata)
}
}
memmove(p, old.array, lenmem) //原数组拷贝到新内存中
return slice{p, old.len, newcap}
}
https://www.jianshu.com/p/54be5b08a21c
https://blog.csdn.net/qq_35423190/article/details/112803978
https://www.topgoer.cn/docs/golang/chapter03-11
哈希表 map
- 引用类型
- Map 是 hash 表来实现的,一种无序的键值对的集合。
- key 类似于索引,指向数据的value,**key必须可以使用==运算符来比较,不能重复。**int、布尔、string、或包含前面的struct、数组等
- map自动扩容
//--------------声明---------------
// var mapname map[key_type]value_type
var m map[string]string
//--------------初始化---------------
// var mapname map[key_type]value_type = make(map[key_type]value_type,[size])
// mapname:=map[key_type]value_type{key:value...}
// func make(Type, size IntegerType) Type
// Type map[key_type]value_type
// size map容量预估
var m1 = make(map[string]string,5)
m2 := map[string]string{"野王":"赵云"}
m3 := make(map[string]string)
//--------------查找---------------
// m[key]返回值和是否存在(bool类型)
val,flag := m2["野王"]
if flag{
fmt.Println("野王:",val)
}
//--------------修改---------------
//map[key] = value 覆盖方式
m1["上官"] = "言为心声"
m1["婉儿"] = "字为心画"
m2["野王"] = "老虎"
m2["上单"] = "吕布"
//--------------删除---------------
//func delete(m map[Type]Type1, key Type)
delete(m1,"上官")
//--------------清空---------------
// make其他当前
m1 = make(map[string]string,0)
//--------------遍历---------------
// for range
// map无序
for key,value := range m2{
fmt.Println(key,value)
}
// 遍历keys
for key := range m2{
fmt.Println(key)
}
源码分析
const(
// flags
iterator = 1 // there may be an iterator using buckets
oldIterator = 2 // there may be an iterator using oldbuckets
hashWriting = 4 // a goroutine is writing to the map
sameSizeGrow = 8 // the current map growth is to a new map of the same size
)
// 哈希表结构体
// runtime/map.go
type hmap struct {
count int // 哈希表元素个数。len()可获取
flags uint8 // 扩容标志位
B uint8 // len(buckets) == 2^B
noverflow uint16 // 溢出的buckets数
hash0 uint32 // 哈希种子 创建哈希表时确定 提供随机性
buckets unsafe.Pointer // buckets数组指针
oldbuckets unsafe.Pointer // 哈希在扩容时用于复制的buckets数组指针,它的大小是当前buckets数组的一半
nevacuate uintptr // 搬迁进度(已经搬迁的buckets数量)
extra *mapextra
}
type mapextra struct {
overflow *[]*bmap //存储hamp.buckets 所有溢出桶
oldoverflow *[]*bmap //存储hamp.oldbuckets 所有溢出桶
nextOverflow *bmap //指向下一个overflow的bucket
}
// 哈希表结构体中的 bucket
// runtime/map.go
type bmap struct {
// tophash[0] < minTopHash为存储 bucket evacuation 状态.
tophash [bucketCnt]uint8
// 因为不支持动态类型,编译时推导内存大小
// cmd/compile/internal/gc/refect
// func bmap(t *types.Type) *types.Type {}
// topbits [8]uint8 //哈希高8位 减少全等对比提高效率
// keys [8]keytype //哈希表健
// elems [8]elemtype //哈希表值
// overflow uintptr //溢出桶指针
}
// 编译时生成hmap代码
// cmd/compile/internal/gc/refect
func hmap(t *types.Type) *types.Type {
//其他代码
...
// build a struct:
// type hmap struct {
// count int
// flags uint8
// B uint8
// noverflow uint16
// hash0 uint32
// buckets *bmap
// oldbuckets *bmap
// nevacuate uintptr
// extra unsafe.Pointer // *mapextra
// }
// must match runtime/map.go:hmap.
fields := []*types.Field{
makefield("count", types.Types[TINT]),
makefield("flags", types.Types[TUINT8]),
makefield("B", types.Types[TUINT8]),
makefield("noverflow", types.Types[TUINT16]),
makefield("hash0", types.Types[TUINT32]), // Used in walk.go for OMAKEMAP.
makefield("buckets", types.NewPtr(bmap)), // Used in walk.go for OMAKEMAP.
makefield("oldbuckets", types.NewPtr(bmap)),
makefield("nevacuate", types.Types[TUINTPTR]),
makefield("extra", types.Types[TUNSAFEPTR]),
}
//其他代码
...
return hmap
}
const(
bucketCntBits = 3
bucketCnt = 1 << bucketCntBits
minTopHash = 5 // minimum tophash for a normal filled cell.
)
// 编译时生成bmap代码
// cmd/compile/internal/gc/refect
func bmap(t *types.Type) *types.Type {
arr := types.NewArray(types.Types[TUINT8], BUCKETSIZE)
field = append(field, makefield("topbits", arr))
arr = types.NewArray(keytype, BUCKETSIZE)
arr.SetNoalg(true)
keys := makefield("keys", arr)
field = append(field, keys)
arr = types.NewArray(elemtype, BUCKETSIZE)
arr.SetNoalg(true)
elems := makefield("elems", arr)
field = append(field, elems)
otyp := types.NewPtr(bucket)
if !elemtype.HasPointers() && !keytype.HasPointers() {
otyp = types.Types[TUINTPTR]
}
overflow := makefield("overflow", otyp)
field = append(field, overflow)
bucket.SetNoalg(true)
bucket.SetFields(field[:])
//其他代码
...
return bucket
}
// 初始化编译时
// cmd/compile/internal/gc/sinit.go
func maplit(n *Node, m *Node, init *Nodes) {
// make the map var
a := nod(OMAKE, nil, nil)
a.Esc = n.Esc
a.List.Set2(typenod(n.Type), nodintconst(int64(n.List.Len())))
litas(m, a, init)
entries := n.List.Slice()
// 其他代码
...
// 元素超过25个使用for循环加入hash表
if len(entries) > 25 {
tk := types.NewArray(n.Type.Key(), int64(len(entries)))
te := types.NewArray(n.Type.Elem(), int64(len(entries)))
// 其他代码
...
// make and initialize static arrays
vstatk := readonlystaticname(tk)
vstate := readonlystaticname(te)
// 其他代码
...
// loop adding structure elements to map
// for i = 0; i < len(vstatk); i++ {
// map[vstatk[i]] = vstate[i]
// }
// 其他代码
...
return
}
// 元素不超过25转换为所有键值对一次性加入哈希表
// Build list of var[c] = expr.
// Use temporaries so that mapassign1 can have addressable key, elem.
// 其他代码
...
}
//运行时初始化
// runtime/map.go
func makemap(t *maptype, hint int, h *hmap) *hmap {
mem, overflow := math.MulUintptr(uintptr(hint), t.bucket.size)
if overflow || mem > maxAlloc {
hint = 0
}
// initialize Hmap
if h == nil {
h = new(hmap)
}
h.hash0 = fastrand() // 获取hash种子
// hint为计算的最小需要同的数量
// Find the size parameter B which will hold the requested # of elements.
// For hint < 0 overLoadFactor returns false since hint < bucketCnt.
B := uint8(0)
for overLoadFactor(hint, B) {
B++
}
h.B = B
// 初始化桶
if h.B != 0 {
var nextOverflow *bmap
h.buckets, nextOverflow = makeBucketArray(t, h.B, nil)
if nextOverflow != nil {
h.extra = new(mapextra)
h.extra.nextOverflow = nextOverflow
}
}
return h
}
// runtime/map.go
// makeBucketArray 根据传入的B创建桶数量并分配连续内存存储数据.
func makeBucketArray(t *maptype, b uint8, dirtyalloc unsafe.Pointer) (buckets unsafe.Pointer, nextOverflow *bmap) {
base := bucketShift(b)
nbuckets := base
// 桶数量小于2^4,溢出桶使用可能较小,避免溢出桶创建
// 桶数量大于2^4,额外创建2^(b-4)个溢出桶
if b >= 4 {
nbuckets += bucketShift(b - 4)
sz := t.bucket.size * nbuckets
up := roundupsize(sz)
if up != sz {
nbuckets = up / t.bucket.size
}
}
if dirtyalloc == nil {
buckets = newarray(t.bucket, int(nbuckets))
} else {
// dirtyalloc was previously generated by
// the above newarray(t.bucket, int(nbuckets))
// but may not be empty.
buckets = dirtyalloc
size := t.bucket.size * nbuckets
if t.bucket.ptrdata != 0 {
memclrHasPointers(buckets, size)
} else {
memclrNoHeapPointers(buckets, size)
}
}
if base != nbuckets {
// We preallocated some overflow buckets.
// To keep the overhead of tracking these overflow buckets to a minimum,
// we use the convention that if a preallocated overflow bucket's overflow
// pointer is nil, then there are more available by bumping the pointer.
// We need a safe non-nil pointer for the last overflow bucket; just use buckets.
nextOverflow = (*bmap)(add(buckets, base*uintptr(t.bucketsize)))
last := (*bmap)(add(buckets, (nbuckets-1)*uintptr(t.bucketsize)))
last.setoverflow(t, (*bmap)(buckets))
}
return buckets, nextOverflow
}
// 访问
/* 编译时会进行如下中代码生成
v := hash[key] // => v := *mapaccess1(maptype, hash, &key)
v, ok := hash[key] // => v, ok := mapaccess2(maptype, hash, &key)
*/
// runtime/map.go
func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
if raceenabled && h != nil {
callerpc := getcallerpc()
pc := funcPC(mapaccess1)
racereadpc(unsafe.Pointer(h), callerpc, pc)
raceReadObjectPC(t.key, key, callerpc, pc)
}
if msanenabled && h != nil {
msanread(key, t.key.size)
}
if h == nil || h.count == 0 {
if t.hashMightPanic() {
t.hasher(key, 0) // see issue 23734
}
return unsafe.Pointer(&zeroVal[0])
}
if h.flags&hashWriting != 0 {
throw("concurrent map read and map write")
}
// 1. 获取当前key hash
hash := t.hasher(key, uintptr(h.hash0))
m := bucketMask(h.B)
// 2. 获取桶序号 hash取后B位表示在那个桶
b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.bucketsize)))
if c := h.oldbuckets; c != nil {
if !h.sameSizeGrow() {
// There used to be half as many buckets; mask down one more power of two.
m >>= 1
}
oldb := (*bmap)(add(c, (hash&m)*uintptr(t.bucketsize)))
if !evacuated(oldb) {
b = oldb
}
}
// 获取高8位hash
top := tophash(hash)
// 3.循环依次查找正常桶和溢出桶数据
bucketloop:
for ; b != nil; b = b.overflow(t) {
for i := uintptr(0); i < bucketCnt; i++ {
// 高8位比较(低概率)
if b.tophash[i] != top {
if b.tophash[i] == emptyRest {
break bucketloop
}
continue
}
// 获取对应k
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
if t.indirectkey() {
k = *((*unsafe.Pointer)(k))
}
// 比较k是否符合(低概率)
if t.key.equal(key, k) {
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))
if t.indirectelem() {
e = *((*unsafe.Pointer)(e))
}
return e
}
}
}
return unsafe.Pointer(&zeroVal[0])
}
// 写入与扩容
// runtime/map.go
// Like mapaccess, but allocates a slot for the key if it is not present in the map.
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
if h == nil {
panic(plainError("assignment to entry in nil map"))
}
if raceenabled {
callerpc := getcallerpc()
pc := funcPC(mapassign)
racewritepc(unsafe.Pointer(h), callerpc, pc)
raceReadObjectPC(t.key, key, callerpc, pc)
}
if msanenabled {
msanread(key, t.key.size)
}
if h.flags&hashWriting != 0 {
throw("concurrent map writes")
}
// 1. 获取当前key hash
hash := t.hasher(key, uintptr(h.hash0))
// Set hashWriting after calling t.hasher, since t.hasher may panic,
// in which case we have not actually done a write.
h.flags ^= hashWriting
if h.buckets == nil {
h.buckets = newobject(t.bucket) // newarray(t.bucket, 1)
}
again:
bucket := hash & bucketMask(h.B)
// 如果在迁移
if h.growing() {
growWork(t, h, bucket)
}
// 2. 获取桶序号 获取桶序号 hash取后B位表示在那个桶
b := (*bmap)(add(h.buckets, bucket*uintptr(t.bucketsize)))
// 获取高8位hash
top := tophash(hash)
var inserti *uint8 //目标元素在桶中的索引
var insertk unsafe.Pointer //目标元素健
var elem unsafe.Pointer //目标元素值
bucketloop:
for {
for i := uintptr(0); i < bucketCnt; i++ {
// 匹配tophash
if b.tophash[i] != top {
if isEmpty(b.tophash[i]) && inserti == nil {
inserti = &b.tophash[i]
insertk = add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
elem = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))
}
if b.tophash[i] == emptyRest {
break bucketloop
}
continue
}
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
if t.indirectkey() {
k = *((*unsafe.Pointer)(k))
}
// 匹配key
if !t.key.equal(key, k) {
continue
}
if t.needkeyupdate() {
typedmemmove(t.key, k, key)
}
elem = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))
goto done
}
ovf := b.overflow(t)
if ovf == nil {
break
}
// 遍历溢出桶
b = ovf
}
// 桶溢出逻辑处理
// 扩容
// 1. 装载因子超过 count/bucket>6.5 (key多桶少,B+1 双倍扩容)
// 2. B<15 bucket=2^b overflow>bucket B>=15 overflow>2^16 (桶多key分散,等量扩容减少overflow,紧凑key)
if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
hashGrow(t, h)
goto again
}
// 当前桶满了
if inserti == nil {
// 创建或者使用之前的溢出桶保存数据
newb := h.newoverflow(t, b)
inserti = &newb.tophash[0]
insertk = add(unsafe.Pointer(newb), dataOffset)
elem = add(insertk, bucketCnt*uintptr(t.keysize))
}
// store new key/elem at insert position
if t.indirectkey() {
kmem := newobject(t.key)
*(*unsafe.Pointer)(insertk) = kmem
insertk = kmem
}
if t.indirectelem() {
vmem := newobject(t.elem)
*(*unsafe.Pointer)(elem) = vmem
}
typedmemmove(t.key, insertk, key)
*inserti = top
h.count++
done:
//其他代码
...
return elem
}
// 扩容
// runtime/map.go
func hashGrow(t *maptype, h *hmap) {
bigger := uint8(1)
if !overLoadFactor(h.count+1, h.B) {
// 溢出桶过多,等量扩容
bigger = 0
h.flags |= sameSizeGrow
}
oldbuckets := h.buckets // 保存旧桶引用
newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil) //创建新桶,溢出桶
// 标记 h.buckets 将挂在 h.oldbuckets
flags := h.flags &^ (iterator | oldIterator)
if h.flags&iterator != 0 {
flags |= oldIterator
}
h.B += bigger
h.flags = flags
h.oldbuckets = oldbuckets
h.buckets = newbuckets
h.nevacuate = 0 // 迁移进度 0
h.noverflow = 0 // 溢出桶 0
// extra更新
// overflow 指向 oldoverflow
// overflow 清空
// nextOverflow 更新
if h.extra != nil && h.extra.overflow != nil {
// Promote current overflow buckets to the old generation.
if h.extra.oldoverflow != nil {
throw("oldoverflow is not nil")
}
h.extra.oldoverflow = h.extra.overflow
h.extra.overflow = nil
}
if nextOverflow != nil {
if h.extra == nil {
h.extra = new(mapextra)
}
h.extra.nextOverflow = nextOverflow
}
// the actual copying of the hash table data is done incrementally
// by growWork() and evacuate().
}
// 搬迁bucket
// 迁移结构体
type evacDst struct {
b *bmap // 桶 指针
i int // 键值 索引
k unsafe.Pointer // 健 指针
e unsafe.Pointer // 值 指针
}
//迁移数据函数
func evacuate(t *maptype, h *hmap, oldbucket uintptr) {
// 定位老的bucket数组地址
b := (*bmap)(add(h.oldbuckets, oldbucket*uintptr(t.bucketsize)))
// 老的bucket桶数量
newbit := h.noldbuckets()
// 判断是否被搬迁过
if !evacuated(b) {
// xy contains the x and y (low and high) evacuation destinations.
var xy [2]evacDst
x := &xy[0]
x.b = (*bmap)(add(h.buckets, oldbucket*uintptr(t.bucketsize)))
x.k = add(unsafe.Pointer(x.b), dataOffset)
x.e = add(x.k, bucketCnt*uintptr(t.keysize))
if !h.sameSizeGrow() {
// 双倍扩容,初始化第二个evacDst扩容
y := &xy[1]
y.b = (*bmap)(add(h.buckets, (oldbucket+newbit)*uintptr(t.bucketsize)))
y.k = add(unsafe.Pointer(y.b), dataOffset)
y.e = add(y.k, bucketCnt*uintptr(t.keysize))
}
// 遍历所有溢出桶
for ; b != nil; b = b.overflow(t) {
k := add(unsafe.Pointer(b), dataOffset)
e := add(k, bucketCnt*uintptr(t.keysize))
for i := 0; i < bucketCnt; i, k, e = i+1, add(k, uintptr(t.keysize)), add(e, uintptr(t.elemsize)) {
top := b.tophash[i]
if isEmpty(top) { //被搬迁过
b.tophash[i] = evacuatedEmpty
continue
}
if top < minTopHash {
throw("bad map state")
}
k2 := k
if t.indirectkey() {
k2 = *((*unsafe.Pointer)(k2))
}
var useY uint8
if !h.sameSizeGrow() {
//双倍扩容
//计算hash rehash
hash := t.hasher(k2, uintptr(h.hash0))
if h.flags&iterator != 0 && !t.reflexivekey() && !t.key.equal(k2, k2) {
// 1/2概率使用新桶
useY = top & 1
top = tophash(hash)
} else {
// hash溢出桶全部迁移新桶
if hash&newbit != 0 {
useY = 1
}
}
}
if evacuatedX+1 != evacuatedY || evacuatedX^1 != evacuatedY {
throw("bad evacuatedN")
}
b.tophash[i] = evacuatedX + useY // evacuatedX + 1 == evacuatedY
dst := &xy[useY] // evacuation destination
if dst.i == bucketCnt {
dst.b = h.newoverflow(t, dst.b)
dst.i = 0
dst.k = add(unsafe.Pointer(dst.b), dataOffset)
dst.e = add(dst.k, bucketCnt*uintptr(t.keysize))
}
dst.b.tophash[dst.i&(bucketCnt-1)] = top // mask dst.i as an optimization, to avoid a bounds check
if t.indirectkey() {
*(*unsafe.Pointer)(dst.k) = k2 // copy pointer
} else {
typedmemmove(t.key, dst.k, k) // copy elem
}
if t.indirectelem() {
*(*unsafe.Pointer)(dst.e) = *(*unsafe.Pointer)(e)
} else {
typedmemmove(t.elem, dst.e, e)
}
dst.i++
dst.k = add(dst.k, uintptr(t.keysize))
dst.e = add(dst.e, uintptr(t.elemsize))
}
}
// 迁移完成 清理指针
if h.flags&oldIterator == 0 && t.bucket.ptrdata != 0 {
b := add(h.oldbuckets, oldbucket*uintptr(t.bucketsize))
// Preserve b.tophash because the evacuation
// state is maintained there.
ptr := add(b, dataOffset)
n := uintptr(t.bucketsize) - dataOffset
memclrHasPointers(ptr, n)
}
}ß
// 更新搬迁进度
if oldbucket == h.nevacuate {
advanceEvacuationMark(h, t, newbit)
}
}
| loadFactor | %overflow | bytes/entry | hitprobe | missprobe |
|---|---|---|---|---|
| 4.00 | 2.13 | 20.77 | 3.00 | 4.00 |
| 4.50 | 4.05 | 17.30 | 3.25 | 4.50 |
| 5.00 | 6.85 | 14.77ß | 3.50 | 5.00 |
| 5.50 | 10.55 | 12.94 | 3.75 | 5.50 |
| 6.00 | 15.27 | 11.67 | 4.00 | 6.00 |
| 6.50 | 20.90 | 10.79 | 4.25 | 6.50 |
| 7.00 | 27.14 | 10.15 | 4.50 | 7.00 |
- loadFactor:负载因子
- %overflow:溢出率,具有溢出桶 overflow buckets 的桶的百分比
- bytes/entry:每个键值对所的字节数开销
- hitprobe:查找存在的 key 时,平均需要检索的条目数量
- missprobe:查找不存在的 key 时,平均需要检索的条目数量
todo
// 总结
http://www.zzvips.com/article/194814.html
https://zhuanlan.zhihu.com/p/412581873
指针类型 pointer
- 引用类型
- 取地址符是&
- 指针保存的是地址,地址里的数据才是真正的值,使用*来获取值
int系列、float系列、bool、string、数组、结构体struct,一般在栈
指针、切片、管道、接口、Map是引用类型,一般在堆,GC回收
声明
//空指针 nil
var ptr *int
//零指针
ptr1 := new(int)
取指针
// 获取指针 i的地址
i:=1
ptr:=&i
// 获取指针的指针 ptr的地址
ptr2:=&ptr
内存

类型判断
任何类型都是实现了interface空接口,interface可以承接任何类型后进行类型断言
comma-ok断言
// value ,ok := interface{}[(container)].(fieldtype)
// value container值
// ok 类型断言是否正确
// fieldtype 断言类型
v,ok:=interface{}("我是string").(string)
println(v,ok) // "我是string" true
type - switch
/*
// data.(type) 获取类型
switch value := interface{}[(container)].(type) {
case int:
case string:
...
}
*/
switch value := interface{}("我是string").(type) {
case int:
case string:
println(value)
}
// string

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











